Photon
The next generation engine for the Lakehouse
Photon is the next generation engine on the Databricks Lakehouse Platform that provides extremely fast query performance at low cost – from data ingestion, ETL, streaming, data science and interactive queries – directly on your data lake. Photon is compatible with Apache Spark™ APIs, so getting started is as easy as turning it on – no code changes and no lock-in.
Cheaper and faster
Built from the ground up for the fastest performance at lower cost, Photon provides up to 80% TCO savings while accelerating data and analytics workloads — up to 12x speedups.
Built for all use cases
Photon is the first engine that enables data teams to standardize on one set of APIs for all workloads — ETL, analytics and data science — in batch or streaming.
No code changes
Photon is an ANSI-compliant engine designed to be compatible with modern Apache Spark APIs and just works with your existing code — SQL, Python, R, Scala and Java — no rewrite required.
Why Photon?
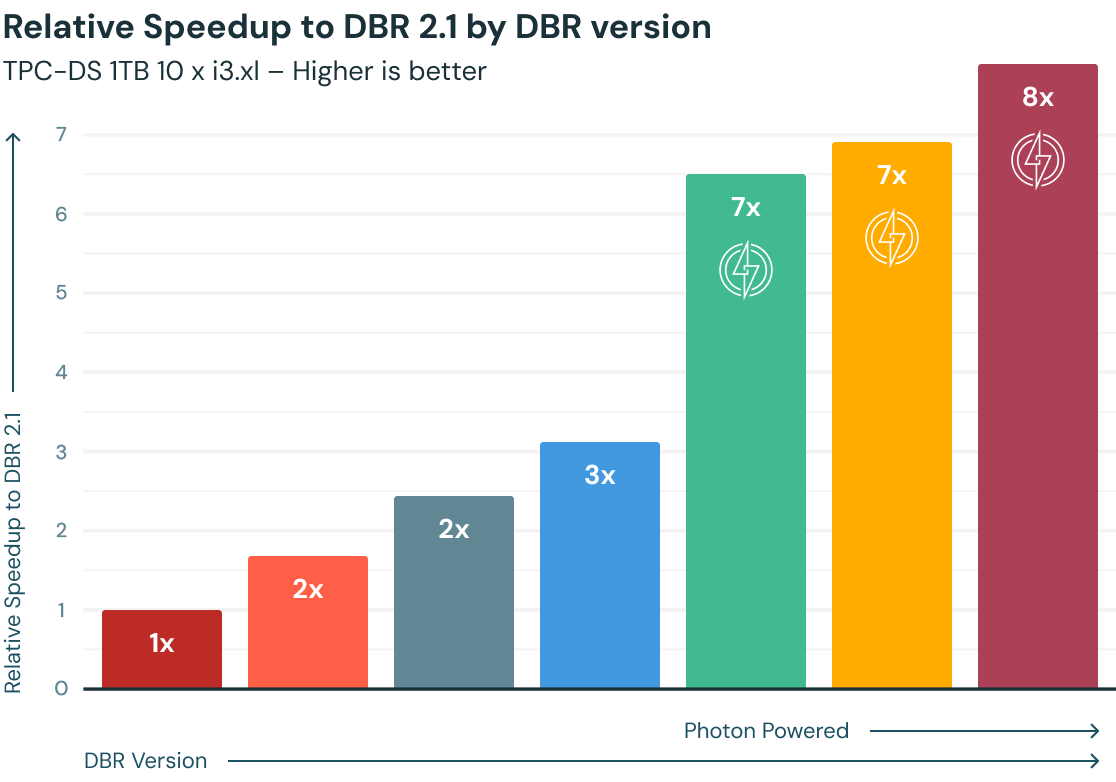
Query performance on Databricks has steadily increased over the years, powered by Apache Spark and thousands of optimizations packaged as part of the Databricks Runtimes (DBR). Photon — a new native vectorized engine entirely written in C++ — provides an additional 2x speedup per the TPC-DS 1TB benchmark, and customers have observed 3x–8x speedups on average, based on their workloads, compared to the latest DBR versions.
Use cases

Production jobs
Accelerate large-scale production jobs on SQL and Spark DataFrames

IoT applications
Faster time-series analysis using Photon compared to Spark and traditional Databricks Runtime

Data privacy and compliance
Query petabyte-scale data sets to identify and delete records without duplicating data with Delta Lake, production jobs and Photon

Loading data into Delta Lake and Parquet
Photon’s vectorized I/O speeds up data loads for Delta Lake and Parquet tables, lowering overall runtime and the cost of data engineering jobs
How does it work?
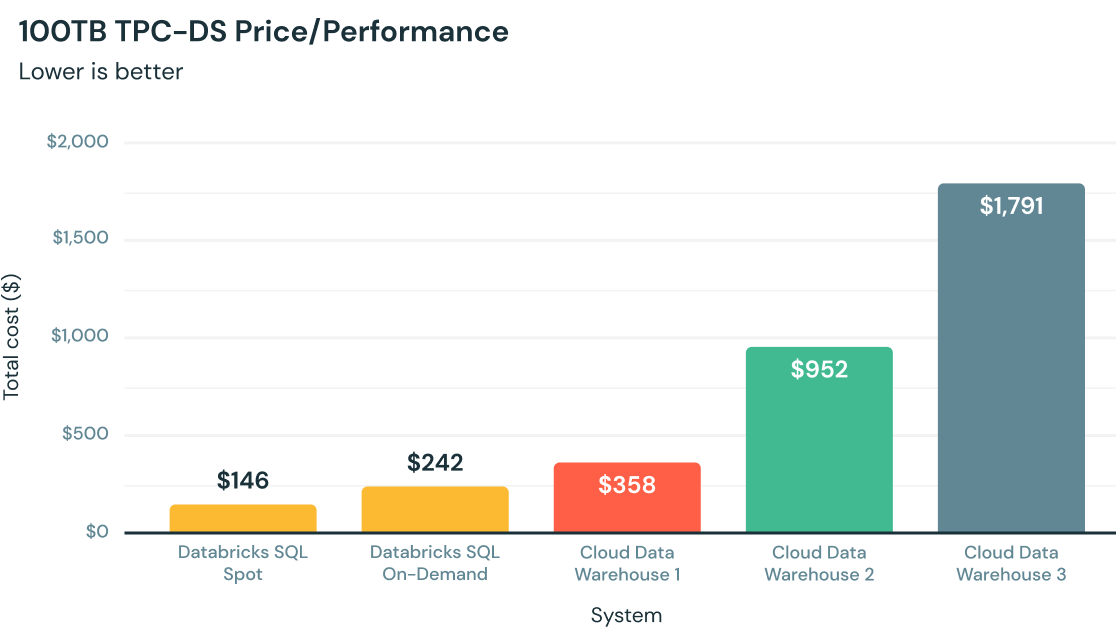
Best price/performance for analytics in the cloud
Written from the ground up in C++, Photon takes advantage of modern hardware for faster queries, providing up to 12x better price/performance compared to other cloud data warehouses — all natively on your data lake.
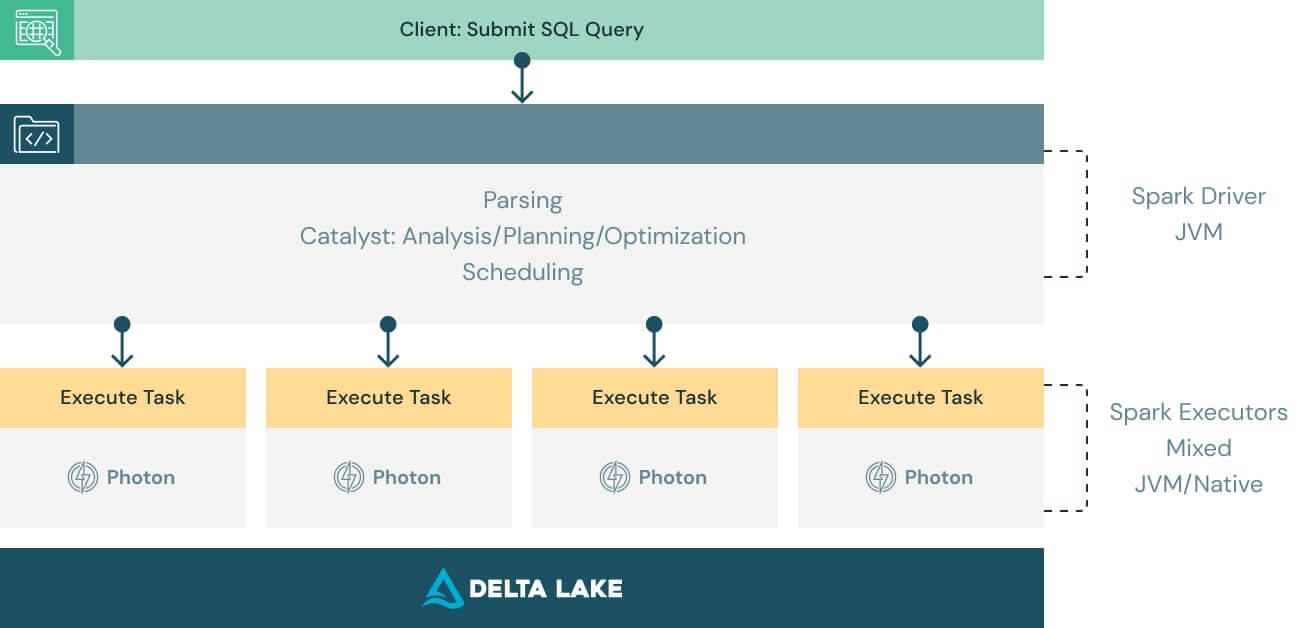
Works with your existing code and avoids vendor lock-in
Photon is designed to be compatible with the Apache Spark DataFrame and SQL APIs to ensure workloads run seamlessly without code changes. All you have to do to benefit from Photon is turn it on. Photon will seamlessly coordinate work and resources and transparently accelerate portions of your SQL and Spark queries. No tuning or user intervention required.

Optimizing for all data use cases and workloads
While we started Photon primarily focused on SQL to provide customers with world-class data warehousing performance on their data lakes, we’ve significantly increased the scope of ingestion sources, formats, APIs and methods supported by Photon since then. As a result, customers have seen dramatic infrastructure cost savings and speedups on Photon across all their modern Spark workloads (e.g., Spark SQL and DataFrame).
Discover more
Resources
Papers
Events
Blogs
Ready to get started?