6 Guiding Principles to Build an Effective Data Lakehouse
Learn some guiding principles for how to design a Lakehouse platform that delivers on your organisation’s Data & AI needs.
by Bernhard Walter, Amr Ali and Marcin Wojtyczka
In this blog post, we will discuss some guiding principles to help you build a highly-effective and efficient data lakehouse that delivers on modern data and AI needs to achieve your business goals. If you are not familiar with the data lakehouse, a new, open architecture, you can read more about it in this blog post.
Before we begin, it is beneficial to define what we mean by guiding principles. Guiding principles are level-zero rules that define and influence your architecture. They reflect a level of consensus among the various stakeholders of the enterprise and form the basis for making future data and AI architecture decisions. Let's explore six guiding principles we've established based on our own personal observations and direct insights from customers.
Principle 1: Curate Data and Offer Trusted Data-as-Products
Curating data by establishing a layered (or multi-hop) architecture is a critical best practice for the lakehouse, as it allows data teams to structure the data according to quality levels and define roles and responsibilities per layer. A common layering approach is:
- Raw Layer: Source data gets ingested into the Lakehouse into the first layer and should be persisted there. When all downstream data is created from the Raw Layer, rebuilding the subsequent layers from this layer is possible, if needed.
- Curated layer: The purpose of the second layer is to hold cleansed, refined, filtered and aggregated data. The goal of this layer is to provide a sound, reliable foundation for analyses and reports across all roles and functions.
- Final Layer: The third layer is created around business or project needs; it provides a different view as data products to other business units or projects, preparing data around security needs (e.g. anonymized data) or optimizing for performance (e.g. pre-aggregated views). The data products in this layer are seen as the truth for the business.
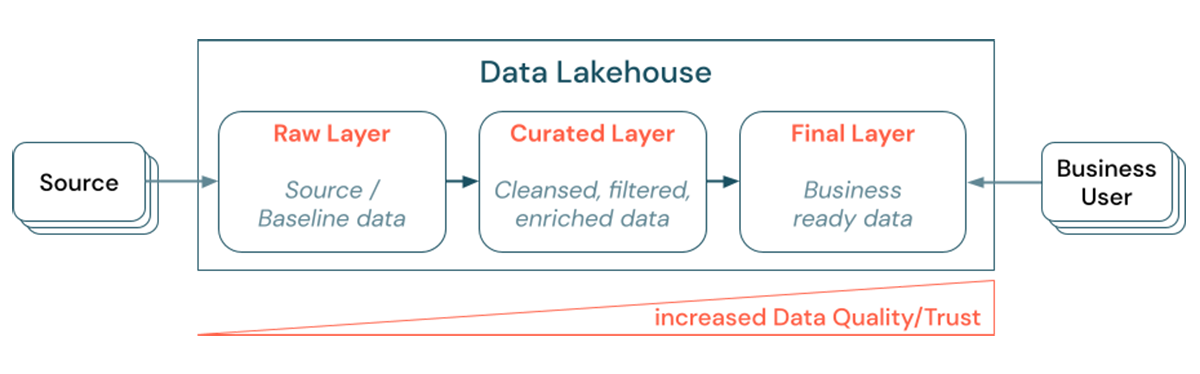
Pipelines across all layers need to ensure that data quality constraints are met (i.e data is accurate, complete, accessible and consistent at all times), even during concurrent reads and writes. The validation of new data happens at the time of data entry into the Curated Layer, and the following ETL steps work to improve the quality of this data.
It is important to note that data quality needs to increase as data progresses through the layers and, as such, the trust in the data will subsequently rise from a business point of view.
Principle 2: Remove Data Silos and Minimize Data Movement
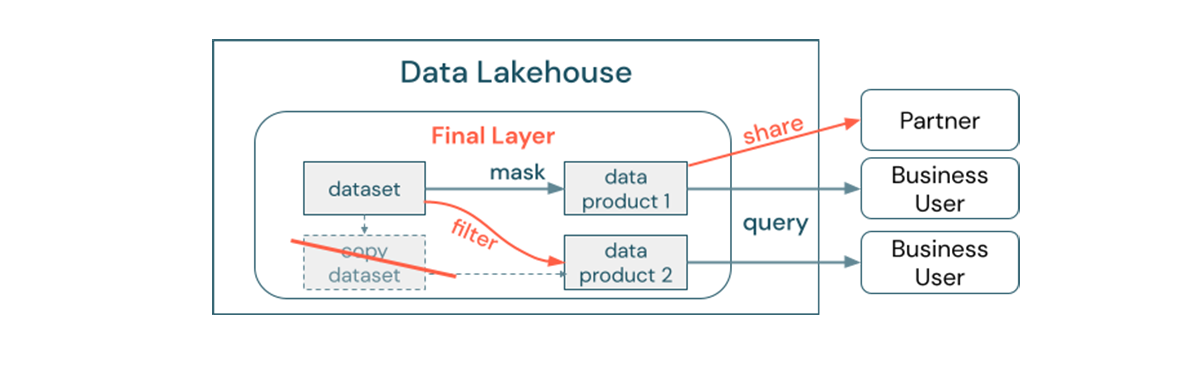
Data movement, copy, and duplication take time and may decrease the quality of the data in the Lakehouse, especially when it leads to data silos. To make the distinction clear between data copy vs data silo, a standalone or throwaway copy of data is not harmful on its own. It is sometimes necessary for boosting agility, experimentation and innovation. When these copies become operational with downstream business data products dependant on them, they become data silos.
To prevent data silos, data teams usually attempt to build a mechanism or data pipeline to keep all copies in sync with the original. Since this will likely not happen consistently, data quality will eventually degrade. And this finally leads to higher costs and a significant loss of trust by the users. On the other hand, several business use cases require data sharing, for example, with partners or suppliers. An important aspect is to securely and reliably share the latest version of the data. Copies of the data are often not sufficient since they become for example out of sync quickly. Instead, data should be shared via enterprise data sharing tools.
Principle 3: Democratize Value Creation through Self-Service Experience
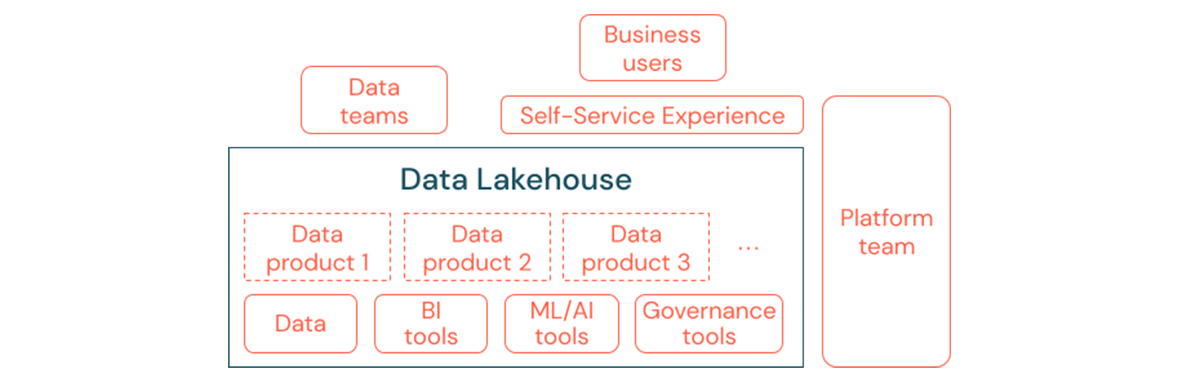
Now, and even more in the future, businesses that have successfully moved to a data-driven culture will thrive. This means every business unit derives its decisions from analytical models or from analyzing its own or centrally provided data. For consumers, data has to be easily discoverable and securely accessible. A good concept for data producers is "data as a product"; the data will be offered and maintained by one business unit or business partner like a product and consumed by other parties - with proper permission control. Instead of relying on a central team and potentially slow request processes, these data products need to be created, offered, discovered and consumed in a self-service experience.
However, it's not just the data that matters. The democratization of data requires the right tools to enable everyone to produce or consume and understand the data. At the core of this is the Data Lakehouse as the modern Data and AI platform that provides the infrastructure and tooling for building data products without duplicating the effort of setting up another tool stack.
Principle 4: Adopt an Organization-wide Data Governance Strategy
Data Governance is a wide field that deserves a separate blog post. However, the dimensions Data Quality, Data Catalog and Access Control play an important role. Let's dive into each of these.
Data Quality
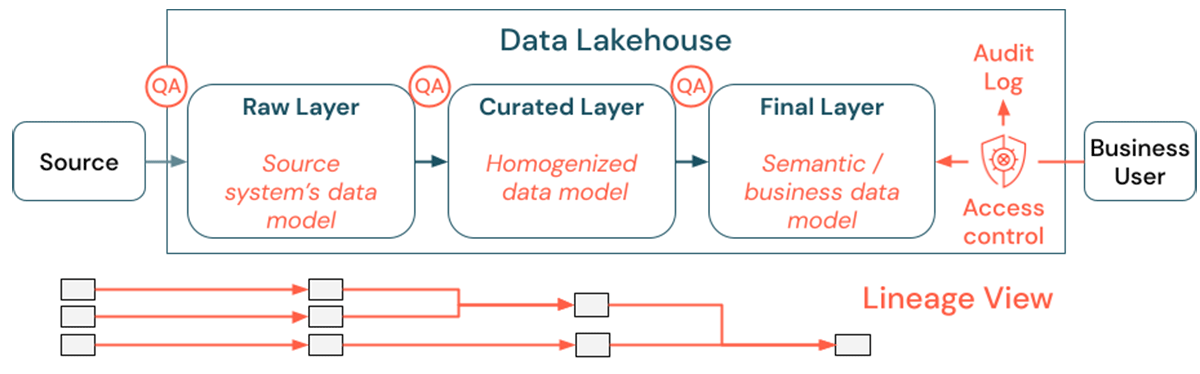
The most important prerequisite for correct and meaningful reports, analysis results and models is high quality data. Quality assurance (QA) needs to exist around all pipeline steps. Examples of how to execute on this include having data contracts, meeting SLAs and keeping schemas stable and evolving them in a controlled way.
Data Catalog
Another important aspect is data discovery: Users of all business areas, especially in a self-service model, need to be able to discover relevant data easily. Therefore, a Lakehouse needs a data catalog that covers all business-relevant data. The primary goals of a data catalog are as follows:
- Ensure the same business concept is uniformly called and declared across the business. You might think of it as a semantic model in the Curated and the Final layer.
- Track the data lineage precisely so that users can explain how these data arrived at their current shape and form.
- Maintain high-quality metadata, which is as important as the data itself for proper use of the data.
Access Control
As the value creation from the data in the Lakehouse happens across all business areas, the Lakehouse needs to be built with security as a first-class citizen. Companies might have a more open data access policy or strictly follow the principle of least privileges. Independent of that, data access controls need to be in place in every layer. It is important to implement fine-grade permission schemes from the very beginning (column- and row-level access control, role-based or attribute-based access control). Companies can still start with less strict rules. But as the Lakehouse platform grows, all mechanisms and processes to move to a more sophisticated security regime should already be in place. Additionally, all access to the data in the Lakehouse needs to be governed by audit logs from the get-go.
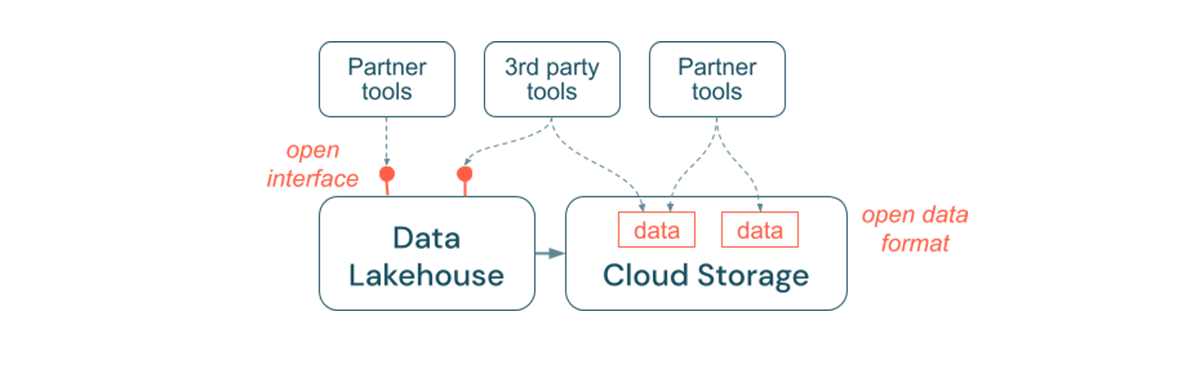
Principle 5: Encourage the Use of Open Interfaces and Open Formats
Open interfaces are critical to enabling interoperability and preventing dependency on any single vendor. Traditionally, vendors built proprietary technologies and closed interfaces that limited enterprises in the way they can store, process and share data.
Building upon open interfaces helps you build for the future: (i) It increases the longevity and portability of the data so that you can use it with more applications and for more use cases. (ii) It opens an ecosystem of partners who can quickly leverage the open interfaces to integrate their tools into the Lakehouse platform. Finally, by standardizing on open formats for data, total costs will be significantly lower; one can access the data directly on the cloud storage without the need to pipe it through a proprietary platform that can incur high egress and computation costs.
Principle 6: Build to Scale and Optimize for Performance & Cost
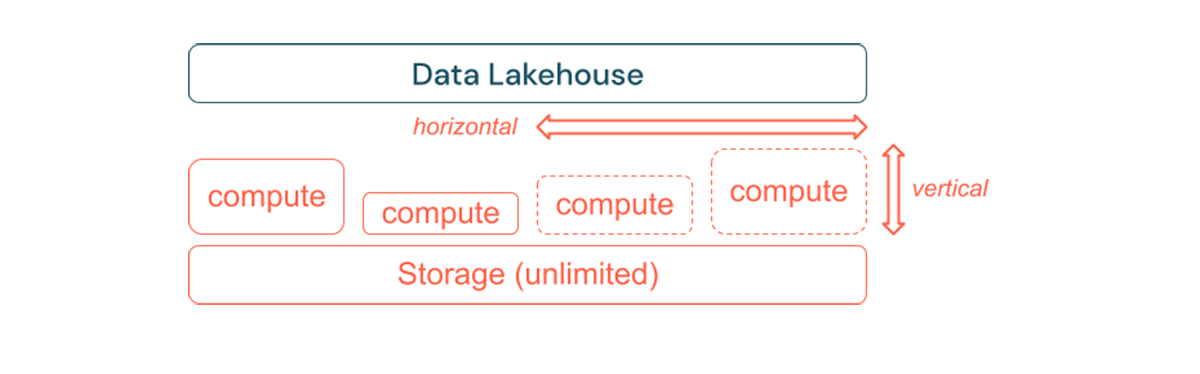
Standard ETL processes, business reports and dashboards often have a predictable resource need from a memory and computation perspective. However, new projects, seasonal tasks or modern approaches like model training (churn, forecast, maintenance) will generate peaks of resource need. To enable a business to perform all these workloads, a scalable platform for memory and computation is necessary. New resources need to be added easily on demand, and only the actual consumption should generate costs. As soon as the peak is over, resources can be freed up again and costs reduced accordingly. Often, this is referred to as horizontal scaling (fewer or more nodes) and vertical scaling (larger or smaller nodes).
Scaling also enables businesses to improve the performance of queries by selecting nodes with more resources or clusters with more nodes. But instead of permanently providing large machines and clusters they can be provisioned on demand only for the time needed to optimize the overall performance to cost ratio. Another aspect for optimization is storage versus compute resources. Since there is no clear relation between volume of the data and workloads using this data (e.g. only using parts of the data or doing intensive calculations on small data), it is a good practice to settle on an infrastructure platform that decouples storage and compute resources
Why Databricks Lakehouse
The Databricks platform is a native Data Lakehouse platform that was built from ground up to deliver all the required capabilities to make data teams efficient at delivering self-service data products. It combines the best features of data warehouses and data lakes as a single solution for all major data workloads. Supported use cases range from stream analytics to BI, data science and AI. The Databricks Lakehouse aim for three main goals:
- Simple - unify your data, analytics, and AI use cases on a single platform
- Open - build on open source and open standards
- Multi-cloud - One consistent data platform across clouds
It enables teams to easily collaborate and comes with integrated capabilities that touch the complete lifecycle of your data products, including data ingestion, data processing, data governance and data publishing/sharing. You can read more about Databricks Lakehouse here.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.