Usando MemAlign para Melhorar a Avaliação de Machine Learning Tradicional em Genie Code
Fechando a lacuna entre juízes de LLM e especialistas humanos com MemAlign e MLflow.
por Stepan Nosov, Pavle Martinović, Tejas Sundaresan, Alkis Polyzotis e Nemanja Petrovic
- Genie Code gera notebooks de ML completos a partir de prompts em linguagem natural — criamos nove juízes de LLM para avaliar a qualidade deles em dimensões como treinamento de modelo, imputação de dados e engenharia de features.
- A anotação humana revelou que os juízes discordavam dos especialistas em até 0,68 MAE em uma escala de 3 pontos. MemAlign, um framework de alinhamento open-source no MLflow, fechou essa lacuna usando apenas ~50 exemplos rotulados.
- Nas três dimensões com pior alinhamento, MemAlign reduziu o erro do juiz em 74-89%, e um estudo de acompanhamento mostrou que a memória semântica e episódica são essenciais para o resultado.
O Genie Code, anunciado recentemente, é o parceiro de IA autônomo da Databricks, projetado especificamente para o trabalho com dados. Ele substituiu o Databricks Assistant, ao mesmo tempo que incorporou vários agentes e forneceu novos pontos de integração e capacidades. O Genie Code possui integração profunda com o Unity Catalog, o que significa que ele entende suas tabelas, colunas, linhagem, visualizações de métricas e definições de negócios (semântica). Essa consciência contextual torna o Genie Code muito mais útil para profissionais de dados do que os chatbots genéricos.
Quando o Genie Code gera um notebook para tarefas de ML tradicionais, como "construir um modelo de previsão de churn", esperamos que ele produza um fluxo de trabalho pronto para produção que inclua a instalação das bibliotecas Python apropriadas, exploração e pré-processamento dos dados, treinamento, ajuste, registro e implantação do modelo, e avaliação de seu desempenho. Também esperamos que cada etapa seja verdadeiramente informada pelos dados: por exemplo, o Genie Code deve entender que classes desbalanceadas em um problema de classificação binária resultam em fluxos de trabalho e métricas de sucesso drasticamente diferentes.
Para garantir que o Genie Code siga consistentemente as melhores práticas nativas da Databricks e evite, por exemplo, pular a validação cruzada, não notar vazamento de dados ou imputação inadequada de dados, precisávamos de uma maneira rigorosa de responder a uma pergunta: Como saber se o código gerado é realmente bom? O notebook gerado dependerá muito do problema que o cliente está tentando resolver, e isso pode variar enormemente entre diferentes clientes, então esta é uma pergunta muito não trivial.
Neste post, detalharemos como construímos um pipeline de avaliação para as capacidades de ML tradicionais do Genie Code e como usamos o MemAlign (um novo framework de alinhamento open-source no MLflow) para fechar a enorme lacuna que encontramos entre os juízes de LLM e os especialistas humanos. Os juízes aprimorados nos ajudaram a identificar e corrigir lacunas na orientação de ML do Genie Code que teríamos perdido de outra forma.
Construindo o Framework de Avaliação
Um framework de avaliação robusto é necessário para:
- Hillclimbing: quantificar como prompts, ferramentas, habilidades e mudanças de arquitetura afetam a saída.
- Proteção contra regressões: Garantir que a melhoria do "Treinamento de Modelo" não degrade acidentalmente a "Exploração de Dados".
- Benchmarking: Medir como diferentes modelos de fundação (backends de LLM) impactam a qualidade do notebook.
- CI: Monitorar como as mudanças no loop agêntico subjacente se refletem nas tarefas finais de ML.
Avaliar notebooks de ML tradicionais é uma das tarefas de avaliação mais complexas, pois abrange a avaliação da qualidade do código, melhores práticas de ML e adaptações/personalizações informadas por dados. Para lidar com uma tarefa tão ampla e complexa quanto a avaliação de notebooks de ML, usamos um LLM-como-juiz - um "especialista" LLM ensinado por humanos sobre como exatamente um bom notebook se parece. Criamos nove juízes que são instruídos a avaliar os notebooks de ML em nove dimensões que aparecem na maioria dos fluxos de trabalho de ML:
| Dimensões | O que avaliamos |
|---|---|
| Instalação de Biblioteca | Dependências adequadas |
| Análise Exploratória de Dados | EDA completa e |
| Imputação de Dados | Tempo Médio para Conter |
| Tratamento de valores ausentes sem vazamento. | Engenharia de Atributos |
| Seleção/transformação de atributos. | Treinamento de Modelo |
| Seleção de modelo, Validação Cruzada, Ajuste de Hiperparâmetros | Reutilização do modelo treinado para inferência. |
| Avaliação de Métricas | Lógica de inferência e métricas apropriadas à tarefa (por exemplo, MAPE para previsão, MAE para regressão, Precisão para classificação). |
| MLflow Logging | Configuração de rastreamento de experimentos. |
| Organização de Células | Divisão do código em células, limpeza do código, legibilidade, cabeçalhos markdown, logging apropriado. |
Para cada dimensão, escrevemos rubricas de pontuação (reutilizadas entre avaliadores humanos e juízes de LLM) que atribuem uma pontuação de 1 a 3, e 0 para "não aplicável":
- 3 (Bom): O notebook atende a um alto padrão para uma dimensão. Ele demonstra melhores práticas, cobre o escopo esperado e lida adequadamente com casos extremos.
- 2 (Médio): Aceitável, mas com lacunas. O básico está presente, mas o notebook perde refinamentos que um profissional experiente esperaria.
- 1 (Ruim): Problemas fundamentais. Etapas chave estão faltando, incorretas ou aplicadas de forma que levariam a conclusões erradas.
- N/A (Não Aplicável): Esta dimensão não é aplicável para este prompt (por exemplo, a dimensão imputação de dados não pode ser aplicada se o conjunto de dados não tiver valores ausentes).
Para dar uma ideia da granularidade, aqui está a rubrica específica que usamos para a dimensão "imputação de dados":
Junto com os juízes, mantemos um conjunto de casos de teste de avaliação que abrangem uma variedade de tarefas de ML (classificação, regressão, previsão), em diferentes tamanhos de dataset, domínios e níveis de complexidade. Cada caso de teste inclui um prompt do usuário que informa ao Genie Code a tarefa de ML que ele deve resolver no dataset especificado ("Tenho dados de passageiros nas tabelas titanic_train_table e titanic_test_table. Você pode descobrir quem sobreviveu?"). O loop de avaliação consiste em usar o Genie Code para gerar um notebook (ou vários) para cada caso de teste e, em seguida, pontuar cada notebook em todas as dimensões aplicáveis.
Avaliando o sistema de avaliação
Ao usar juízes de LLM, em vez de humanos, para avaliar artefatos do Genie Code, essencialmente trocamos um problema difícil por outro: o juiz pronto para uso é inexperiente na tarefa em questão e desalinhado com as avaliações humanas. Nosso problema é fazer com que as pontuações dos juízes de LLM se alinhem com as dos avaliadores humanos.
O conjunto de avaliação para avaliação de juízes de LLM contém 50 notebooks gerados pelo Genie Code ("casos de teste") onde especialistas humanos avaliaram cada dimensão aplicável, fornecendo tanto uma pontuação quanto uma breve justificativa para servir como nosso ground truth. Nas áreas cinzentas entre duas pontuações, os avaliadores podiam expressar seu próprio julgamento, mas os esquemas foram escritos de forma que isso raramente acontecesse.
A medida de alinhamento humano-máquina é o erro absoluto médio (MAE) entre as pontuações em cada dimensão. Os resultados foram mistos, algumas dimensões mostraram forte alinhamento (4 dimensões tiveram um MAE de <= 0,10), enquanto outras revelaram desacordo significativo:
- Treinamento de Modelo: MAE de 0,680
- Uso do Modelo: MAE de 0,562
- Imputação de Dados: MAE de 0,474
- Exploração de Dados: MAE de 0,407
Essa lacuna existe porque humanos e LLMs não interpretam a mesma rubrica da mesma maneira. Enquanto um avaliador humano pode identificar uma estratégia de imputação sutilmente falha ou um loop de treinamento que 'funciona', mas é logicamente falho, um juiz de LLM muitas vezes perde essa nuance técnica. Também descobrimos que o juiz sofria de um viés de positividade clássico - era simplesmente muito 'educado' e isso atrapalhava a obtenção de resultados objetivos.
Tornou-se absolutamente claro que, dada a mesma rubrica, juízes de LLM e humanos não produziriam os mesmos resultados - um desalinhamento. Este é exatamente o cenário para o qual o MemAlign foi projetado para corrigir.
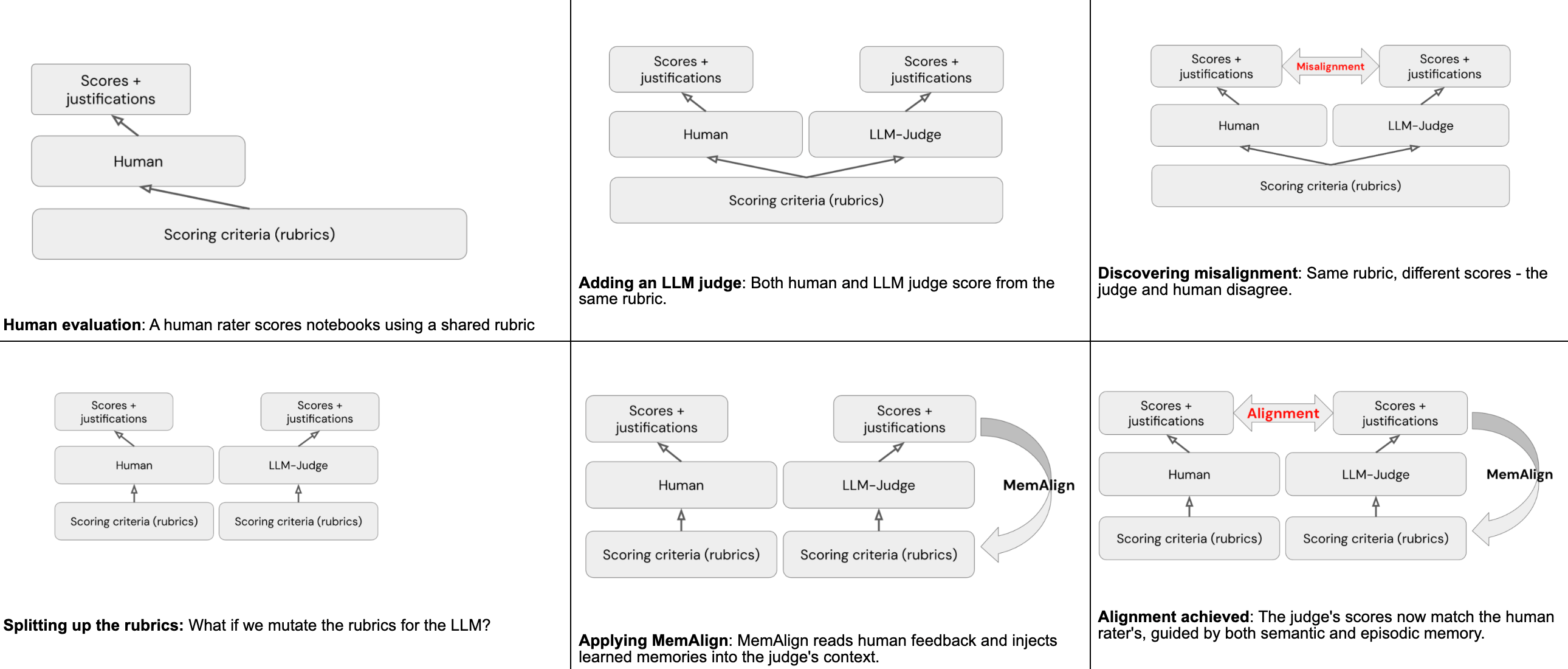
Usando MemAlign para alinhamento
MemAlign é um framework dentro do MLflow que pode, dada uma quantidade muito pequena de feedback em linguagem natural humana, realizar o alinhamento entre os avaliadores humanos e os juízes de LLM. Isso é alcançado através de dois tipos de "memórias" formadas a partir da leitura do feedback humano:
- Memória semântica armazena diretrizes generalizadas - regras extraídas do feedback que se aplicam amplamente
- Memória episódica armazena exemplos específicos - casos em que o juiz errou, preservados como âncoras para decisões futuras
No tempo de inferência, o MemAlign constrói um contexto de trabalho extraindo todas as diretrizes semânticas e recuperando os exemplos episódicos mais relevantes para a entrada atual. O juiz carrega tudo isso em seu contexto, juntamente com a rubrica original, e usa o conhecimento acumulado para dar uma pontuação mais precisa a todos os notebooks futuros.
A propriedade chave que fez o MemAlign se destacar foi o alto desempenho usando apenas um pequeno número de exemplos. Isso ocorre porque o MemAlign extrai efetivamente o aprendizado de sinais de aprendizado ricos em feedback de linguagem natural e os incorpora ao sistema de memória dupla.
Aqui está um exemplo de alguns dos trechos de memória semântica gerados para a dimensão “imputação de dados”, preenchendo as lacunas na rubrica que definimos anteriormente, fornecendo geralmente pontos de ancoragem, exemplos e contraexemplos:
Além disso, como mencionado anteriormente, a memória semântica refletida no prompt é complementada com exemplos relevantes da memória episódica do juiz no momento da pontuação, dando assim ao juiz ainda mais contexto para interpretar as instruções otimizadas.
Design do Experimento
Validação Cruzada K-Fold
Seguindo o paradigma de treinamento-teste de ML, aplicamos validação cruzada K-fold (K=4) em 50 casos de teste (notebooks), evitando assim vazamento de dados e a necessidade de rotular um conjunto de teste separado. Para cada fold, fizemos o seguinte:
- Fase de treinamento: O MemAlign alinhou o juiz usando traces de outros folds para obter o juiz.
- Fase de avaliação: Avaliamos os notebooks no fold i com o juiz.
Intervalos de Confiança de Bootstrapping
Para calcular os intervalos de confiança sem dados rotulados adicionais, geramos 100 amostras bootstrap com reposição a partir das 50 originais. Repetindo isso 10.000 vezes e rastreando o MAE entre as pontuações humanas e de máquina, calculamos os intervalos de confiança para o alinhamento humano-máquina com um IC de 95% definindo uma mudança estatisticamente significativa.
Implementação
O pipeline de avaliação é implementado como um único trecho de MLflow que orquestra todo o processo:
O otimizador MemAlign é capaz de alinhar juízes LLM com base nos traces dos casos de teste em apenas algumas linhas de código. Usamos este novo juiz “alinhado” para calcular o novo MAE. Alinhar um juiz em uma única dimensão leva aproximadamente 25 segundos por fold, então o alinhamento em si não é um gargalo.
Resultados
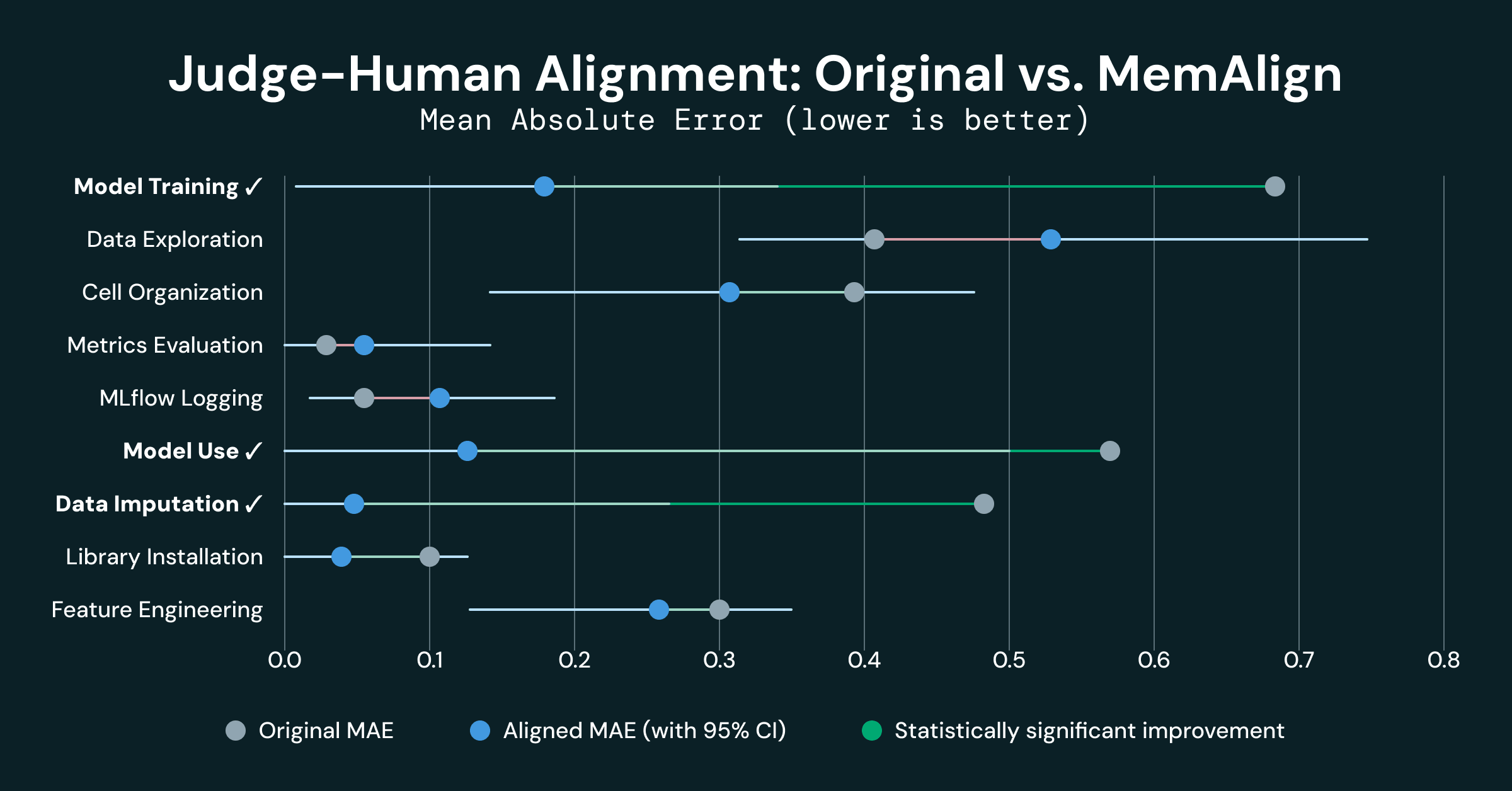
Três das 9 dimensões mostraram melhoria estatisticamente significativa:
- Treinamento de modelo melhorou em 0,500 MAE (0,680 → 0,180), uma redução de 74%
- Uso do modelo melhorou em 0,438 MAE (0,562 → 0,125), uma redução de 78%
- Imputação de dados melhorou em 0,421 MAE (0,474 → 0,053), uma redução de 89%
Essas 3 dimensões estão entre as 4 dimensões iniciais que estavam fortemente desalinhadas. Um alinhamento inicial fraco é indicativo de que os LLMs e os humanos têm uma compreensão fundamentalmente diferente das rubricas compartilhadas, e a memória injetada pelo MemAlign parece fornecer contexto suficiente para colocá-los “na mesma página”.
- Avaliação de métricas e logging de MLflow já estavam bem alinhados (MAE < 0,10 originalmente), e sua degradação não é estatisticamente significativa (ruído experimental)
- Exploração de dados mostrou uma leve regressão (-0,130), mas não estatisticamente significativa dado seu intervalo de confiança [-0,33, +0,09]. Essa dimensão apresentou a maior variância interavaliador, e esse ruído impediu o MemAlign de melhorar (e pode até ter prejudicado).
Experimento Apenas com Memória Semântica
A estrutura de memória dupla do MemAlign nos levou a questionar se ambos estão realmente contribuindo para o alinhamento do juiz. Em particular, a memória episódica deve ajudar o juiz, fornecendo um conjunto dos notebooks anotados mais semelhantes como ponto de referência (utilizando a busca pelo vizinho mais próximo). Mas e se os notebooks recuperados (vizinhos mais próximos) não forem realmente semelhantes ao atual - apenas os menos dissimilares? Carregá-los no contexto do juiz pode confundir em vez de ajudar. O espaço de problemas que estamos avaliando (notebooks de ML) é muito amplo, e inicialmente hipotetizamos que um conjunto de 50 notebooks simplesmente não seria suficiente para obter um conjunto de memórias suficientemente denso para o juiz recordar.
Sem memória episódica, o quadro se degrada substancialmente:
- Treinamento de modelo ainda melhora (+0,420), mas o ganho é menor do que o +0,500 com MemAlign completo, e o MAE alinhado é 0,260 vs. 0,180.
- Uso do modelo perde completamente a significância estatística - a melhoria cai de +0,438 para +0,294, com o intervalo de confiança agora cruzando zero.
- Imputação de dados passa de uma redução de erro de 89% para nenhuma melhoria - o MAE alinhado é igual ao MAE original (0,455).
- Logging de MLflow e avaliação de métricas na verdade regridem significativamente. Sem exemplos episódicos para ancorar o juiz, as diretrizes extraídas sozinhas introduzem ruído em dimensões que já estavam bem calibradas, elevando o logging de MLflow de 0,062 para 0,396 MAE.
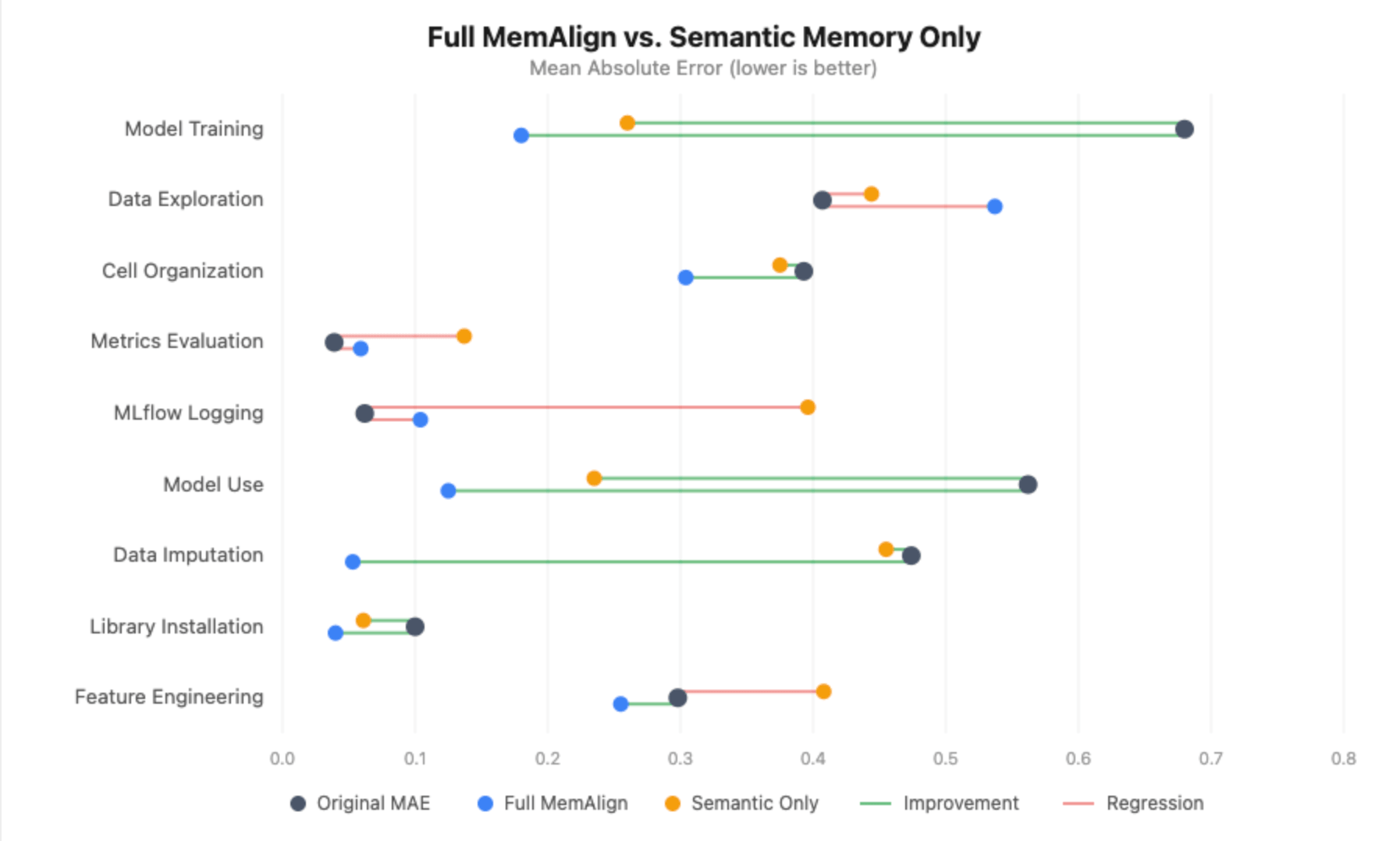
Isso foi o oposto do que esperávamos. Inicialmente, hipotetizamos que nosso conjunto esparso anotado acabaria confundindo o juiz, mas quase todas as dimensões pioraram sem memória episódica. A única exceção foi a Exploração de Dados, onde a remoção dos exemplos episódicos pode ter realmente ajudado - sem os notebooks específicos sobre os quais nossos anotadores discordaram, o juiz tinha apenas as diretrizes extraídas e um sinal menos ruidoso para trabalhar.
A lição: mesmo quando suas entradas são grandes e confusas, a memória episódica ainda melhora drasticamente o desempenho do juiz. Tanto as memórias semânticas quanto as episódicas são integrais ao funcionamento do MemAlign.
Conclusão: Fechando a Lacuna de Especialistas
Julgar se um agente de codificação está fazendo seu trabalho é difícil o suficiente, enquanto avaliar um parceiro de IA autônomo na construção e execução de fluxos de trabalho de ML tradicionais é outro nível de complexidade. Devido à rápida iteração em produtos de IA, não há tempo suficiente para que especialistas monitorem a “integração contínua” do agente. A única solução escalável viável são os juízes LLM - mas ainda precisamos de um júri de humanos para manter o juiz LLM sob controle.
Ao aplicar o MemAlign, reduzimos o erro do juiz em 74–89% nas dimensões onde isso era mais importante. Mas, como em qualquer trabalho de ML/LLM, o resultado é tão bom quanto a informação que você coloca, portanto, certifique-se de que a rotulagem seja competente.
Lições:
- Meça seu sistema de medição: Um sistema ruidoso não é bom para avaliação e, até investirmos tempo e recursos para validar e melhorar os juízes, não poderíamos confiar em nosso sistema de avaliação.
- Rubricas não são suficientes por si só: Existem diferenças sutis entre como um humano percebe as instruções e como um LLM percebe as instruções. Essas diferenças devem ser consideradas, e ferramentas de alinhamento como MemAlign são uma forma eficaz de preencher a lacuna.
- Qualidade de rotulagem > quantidade: Quando os anotadores humanos discordam uns dos outros (como vimos em nossa regressão de Exploração de Dados), o alinhamento não tem um sinal coerente para aprender.
MemAlign é enviado com MLflow e funcionou para nós com apenas ~50 exemplos rotulados. Se os seus juízes de LLM não estiverem correspondendo aos seus especialistas, vale a pena uma tarde.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.