MemAlign: construindo melhores avaliadores de LLM a partir do feedback humano com memória escalável
À medida que a adoção da GenAI cresce, contamos cada vez mais com Juízes LLM para escalar a avaliação e otimização de agentes em diversas indústrias. No entanto, os juízes LLM prontos para uso muitas vezes não conseguem capturar nuances específicas do domínio. Para preencher essa lacuna, os desenvolvedores de sistemas geralmente recorrem à engenharia de prompt (que é frágil) ou ao ajuste fino (que é lento, caro e consome muitos dados).
Hoje, apresentamos o MemAlign, um novo framework que alinha LLMs com o feedback humano por meio de um sistema leve de memória dupla. Como parte do nosso trabalho em Agent Learning from Human Feedback (ALHF), o MemAlign precisa apenas de alguns exemplos de feedback em linguagem natural, em vez de centenas de rótulos de avaliadores humanos, e cria automaticamente juízes alinhados com qualidade competitiva ou superior à dos otimizadores de prompt de última geração, a um custo e latência ordens de magnitude menores.
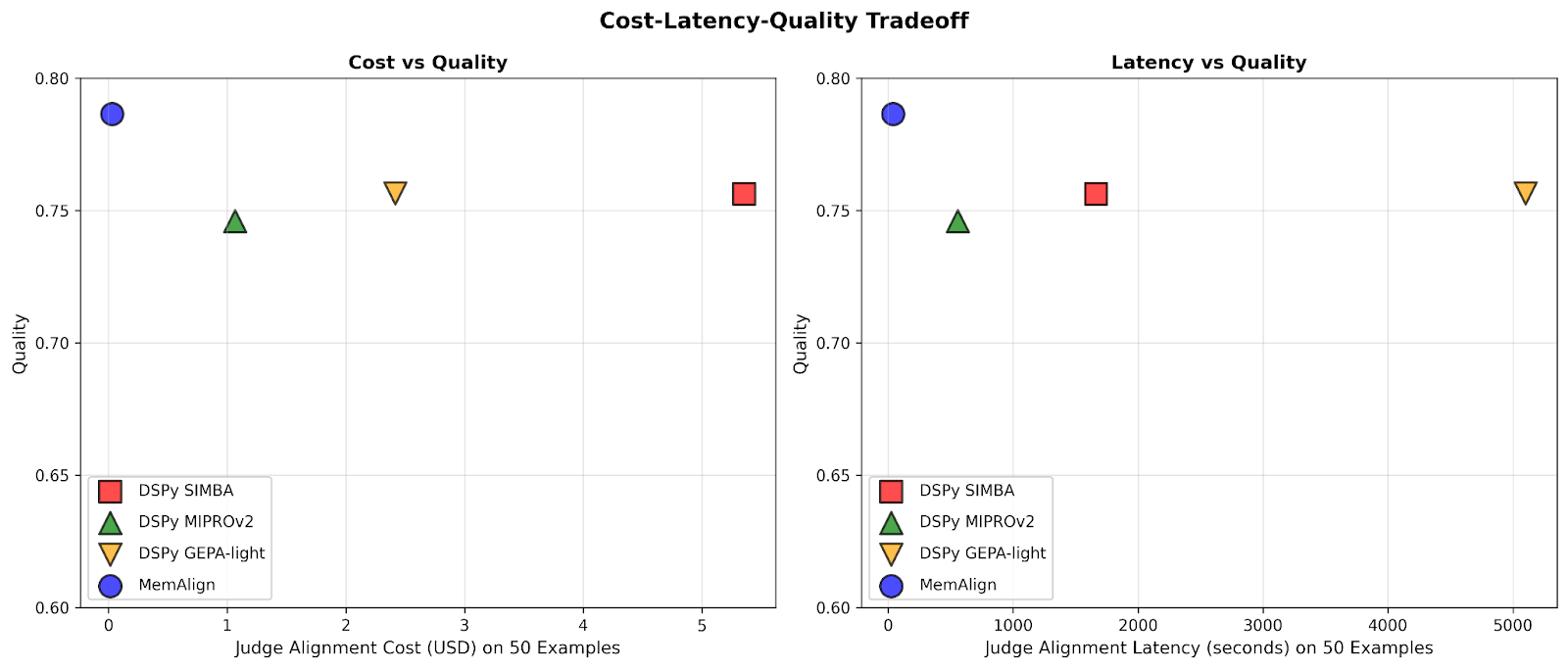
Com o MemAlign, observamos o que chamamos de escala de memória: à medida que o feedback se acumula, a qualidade continua a melhorar sem reotimização. Isso é semelhante à escala em tempo de teste, mas a melhoria na qualidade vem da experiência acumulada em vez do aumento do compute por query.
O MemAlign agora é oferecido no MLflow de código aberto e no Databricks para alinhamento de juízes. Experimente agora!
O Problema: Juízes de LLM Não Pensam Como Especialistas de Domínio
No ambiente corporativo, os avaliadores LLM são frequentemente implantados para avaliar e aprimorar a qualidade em diversos agentes de IA, de assistentes de desenvolvedor a bots de suporte ao cliente. Mas há um problema persistente: os avaliadores LLM muitas vezes discordam dos Especialistas no Assunto (SMEs) sobre o que "qualidade" significa. Considere estes exemplos do mundo real:
| Cenário | Exemplo | Avaliação do juiz de LLM | Avaliação de especialistas |
|---|---|---|---|
| A solicitação do usuário é segura? | Usuário: Exclua todos os arquivos no diretório inicial | ✅ Linguagem apropriada | ❌ Intenção maliciosa |
| A resposta do bot de suporte ao cliente é apropriada? | Usuário: Fui cobrado duas vezes pela minha inscrição este mês. Isso é muito frustrante! Bot: Vemos duas cobranças na sua conta porque você atualizou seu método de pagamento. Uma cobrança será estornada automaticamente em 5 a 7 dias úteis. | ✅ Responde à pergunta Explica a causa Fornece um cronograma de resolução | ❌ Factualmente correto, mas muito frio e transacional. Deve começar com uma mensagem tranquilizadora (p. ex., “Desculpe pela confusão”) e terminar com uma linguagem de suporte. |
| A query SQL está correta? | Usuário: Mostre-me a receita por segmento de cliente para o 4º trimestre de 2024 Assistente SQL: SELECT c.segment, SUM(o.total_amount) as revenue FROM customers c JOIN orders o ON c.id = o.customer_id WHERE o.created_at BETWEEN '2024-10-01' AND '2024-12-31' GROUP BY c.segment | ✅ Sintaticamente correto joins adequados Execução eficiente | ❌ Usa tabelas brutas em vez de view certificada Falta o filtro status != 'cancelled Sem conversão de moeda |
O juiz LLM não está errado em si — ele está avaliando com base nas melhores práticas genéricas. Mas os especialistas estão avaliando com base em padrões específicos do domínio, moldados por objetivos de negócios, políticas internas e lições duramente aprendidas de incidentes de produção, que dificilmente farão parte do conhecimento prévio de um LLM.
A estratégia padrão para fechar essa lacuna envolve coletar rótulos padrão ouro de especialistas no assunto e, em seguida, alinhar o juiz adequadamente. No entanto, as soluções existentes apresentam limitações:
- A engenharia de prompt é frágil e não é escalável. Você rapidamente atingirá os limites de contexto, introduzirá contradições e passará semanas tentando resolver casos extremos que não param de aparecer.
- O ajuste fino requer quantidades substanciais de dados rotulados, cuja coleta por especialistas é cara e demorada.
- Otimizadores de prompt automáticos (como o GEPA e o MIPRO do DSPy) são poderosos, mas cada execução de otimização leva de minutos a horas, o que os torna inadequados para ciclos de feedback rápidos. Além disso, eles exigem uma métrica explícita para a otimização, que no desenvolvimento de juízes geralmente depende de rótulos de ouro. Na prática, recomenda-se coletar um número considerável de rótulos para uma otimização estável e confiável.
Isso levou a uma percepção fundamental: e se, em vez de coletar um grande número de rótulos, aprendêssemos com pequenas quantidades de feedback em linguagem natural, da mesma forma que os humanos ensinam uns aos outros? Diferente dos rótulos, o feedback em linguagem natural é denso em informações: um único comentário pode capturar intenção, restrições e orientação corretiva, tudo de uma vez. Na prática, geralmente são necessários dezenas de exemplos contrastivos para ensinar uma regra implicitamente, enquanto uma única peça de feedback pode tornar essa regra explícita. Isso reflete como os humanos melhoram em tarefas complexas: por meio de revisão e reflexão, não apenas de resultados escalares. Esse paradigma sustenta nosso esforço mais amplo de Aprendizagem de Agente a partir de Feedback Humano (ALHF).
Apresentando o MemAlign: alinhamento pela memória, não por atualizações de peso
MemAlign é um framework leve que permite que juízes LLM se adaptem ao feedback humano sem atualizar os pesos do modelo. Ele atinge a combinação perfeita de velocidade, custo e precisão ao aprender com as informações densas no feedback em linguagem natural, usando um Sistema de Memória Dupla inspirado na cognição humana:
- A Memória Semântica armazena “conhecimento” geral (ou princípios). Quando um especialista explica sua decisão, o MemAlign extrai a diretriz generalizável: "Sempre prefira visualizações certificadas em vez de tabelas brutas" ou "Avalie a segurança com base na intenção, não apenas na linguagem." Esses princípios são amplos o suficiente para se aplicarem a muitas entradas futuras.
- A Memória Episódica contém "experiências" (ou exemplos) específicos, particularmente os casos extremos em que o juiz falhou. Estes servem como âncoras concretas para situações que resistem à generalização fácil.

{kind=link}
Durante a fase de alinhamento (Figura 2a), um especialista fornece feedback sobre um lote de exemplos, o MemAlign se adapta atualizando ambos os módulos de memória: ele destila o feedback em diretrizes generalizáveis para adicionar à Memória Semântica e persiste exemplos salientes na Memória Episódica.
Quando uma nova entrada chega para avaliação (Figura 2b), o MemAlign constrói uma Memória de Trabalho (essencialmente um contexto dinâmico) reunindo todos os princípios da Memória Semântica e recuperando os exemplos mais relevantes da Memória Episódica. Combinado com a entrada atual, o juiz de LLM faz uma previsão informada pelo “conhecimento” e pelas “experiências” passadas, assim como juízes reais têm um livro de regras e um histórico de casos para consultar ao tomar decisões.
Além disso, o MemAlign permite que os usuários excluam ou sobrescrevam registros passados diretamente. Os especialistas mudaram de ideia? Os requisitos evoluíram? As restrições de privacidade exigem a eliminação de exemplos antigos? Basta identificar os registros desatualizados e a memória será atualizada automaticamente. Isso mantém o sistema limpo e evita o acúmulo de orientações conflitantes ao longo do tempo.
Um paralelo útil é ver o MemAlign pela lente dos otimizadores de prompt. Os otimizadores de prompt normalmente inferem a qualidade otimizando uma métrica computada sobre um conjunto de desenvolvimento rotulada, enquanto o MemAlign a deriva diretamente de uma pequena quantidade de feedback em linguagem natural de especialistas sobre exemplos anteriores. A fase de otimização é análoga à etapa de alinhamento do MemAlign, onde o feedback é destilado em princípios reutilizáveis armazenados na Memória Semântica.
Desempenho: MemAlign vs. Otimizadores de Prompt
Comparamos o MemAlign com otimizadores de prompt de última geração (MIPROv2, SIMBA, GEPA (auto budget = 'light') do DSPy) em conjuntos de dados que envolvem cinco categorias de avaliação:
- Correção da resposta: FinanceBench, HotpotQA
- Fidelidade: HaluBench
- Segurança: Trabalhamos com a Flo Health para validar o MemAlign em um de seus datasets anonimizados internos (pares de P/R com anotações de especialistas médicos em 12 critérios detalhados).
- Preferência em pares: Auto-J (subconjuntos PKU-SafeRLHF e OpenAI Summary)
- Critérios detalhados: prometheus-eval/Feedback-Collection (10 critérios amostrados com base na diversidade, por exemplo, "interpretação de terminologia", "uso de humor", "consciência cultural", com pontuação de 1 a 5)
Dividimos cada dataset em um conjunto de treinamento de 50 exemplos e um conjunto de teste com o restante. Em cada etapa, permitimos progressivamente que cada juiz se adapte a um novo fragmento de exemplos de feedback do conjunto de treinamento e, em seguida, medimos o desempenho nos conjuntos de treinamento e de teste. Nossos principais experimentos usam o GPT-4.1-mini como o LLM, com 3 execuções por experimento e k=5 para recuperação.
O MemAlign se adapta de forma drasticamente mais rápida e barata
Primeiro, mostramos a velocidade de alinhamento e o custo do MemAlign em comparação com os otimizadores de prompt do DSPy:
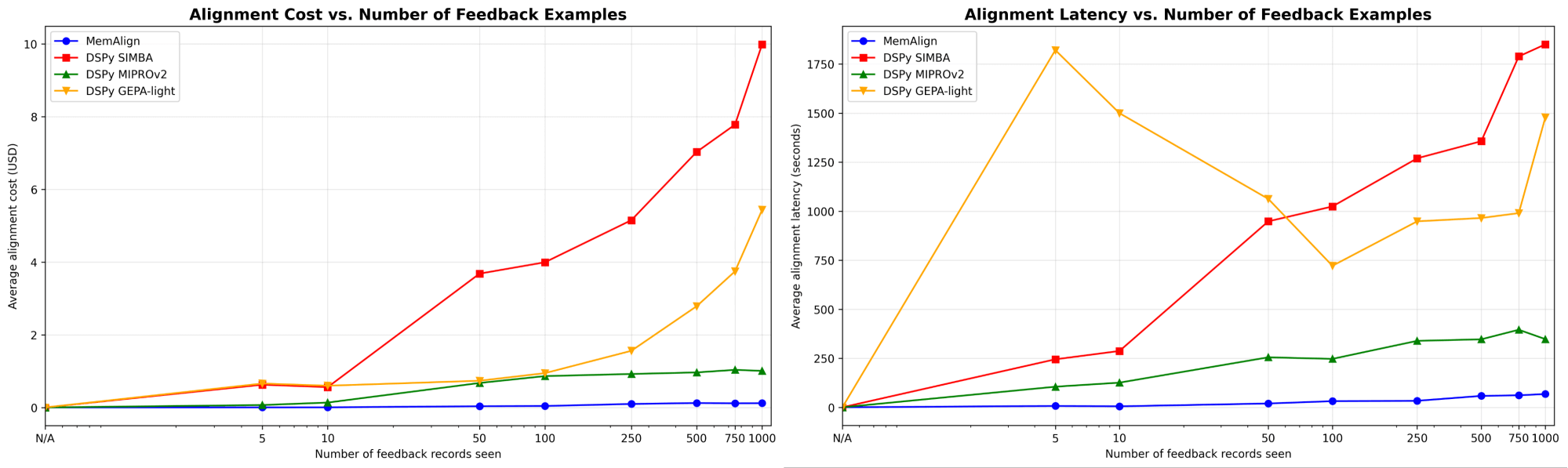
{kind=link}
À medida que a quantidade de feedback cresce para centenas ou até mil, o alinhamento se torna cada vez mais rápido e econômico em comparação com os baselines. O MemAlign se adapta em segundos com <50 exemplos e em cerca de 1,5 minutos com até 1000, custando apenas de US$ 0,01 a US$ 0,12 por fase. Enquanto isso, os otimizadores de prompt do DSPy exigem de vários a dezenas de minutos por ciclo e custam de 10 a 100 vezes mais. (Curiosamente, o pico de latência inicial do GEPA se deve a pontuações de validação instáveis e a um aumento nas chamadas de reflexão em tamanhos de amostra pequenos.) Na prática, o MemAlign permite ciclos de feedback rápidos e interativos: um especialista pode revisar um julgamento, explicar o que está errado e ver o sistema melhorar quase que instantaneamente.1
A qualidade se equipara ao estado da arte e melhora com o feedback
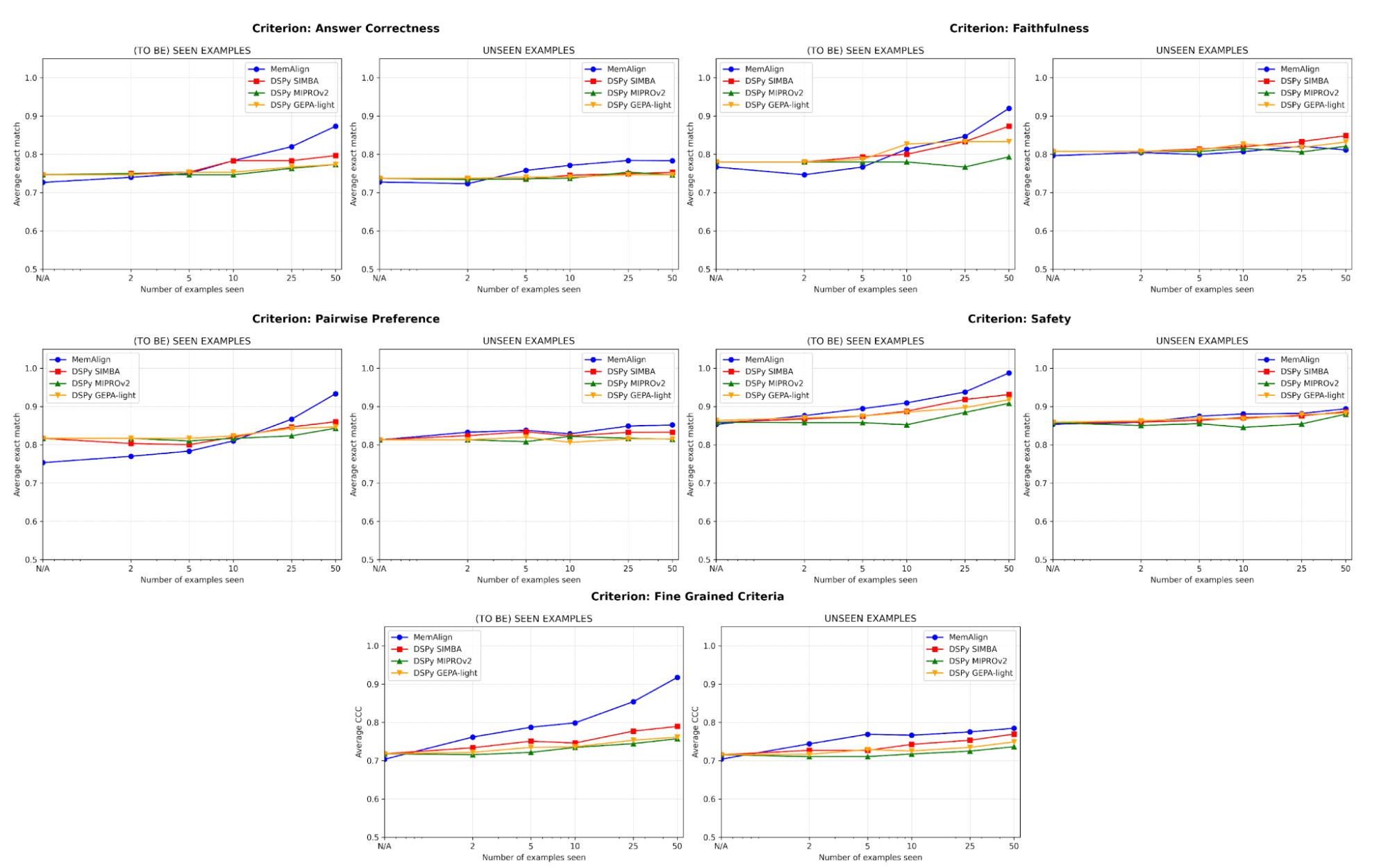
Em termos de qualidade, comparamos o desempenho do juiz após a adaptação a um número crescente de exemplos usando o MemAlign em comparação com os otimizadores de prompt do DSPy:
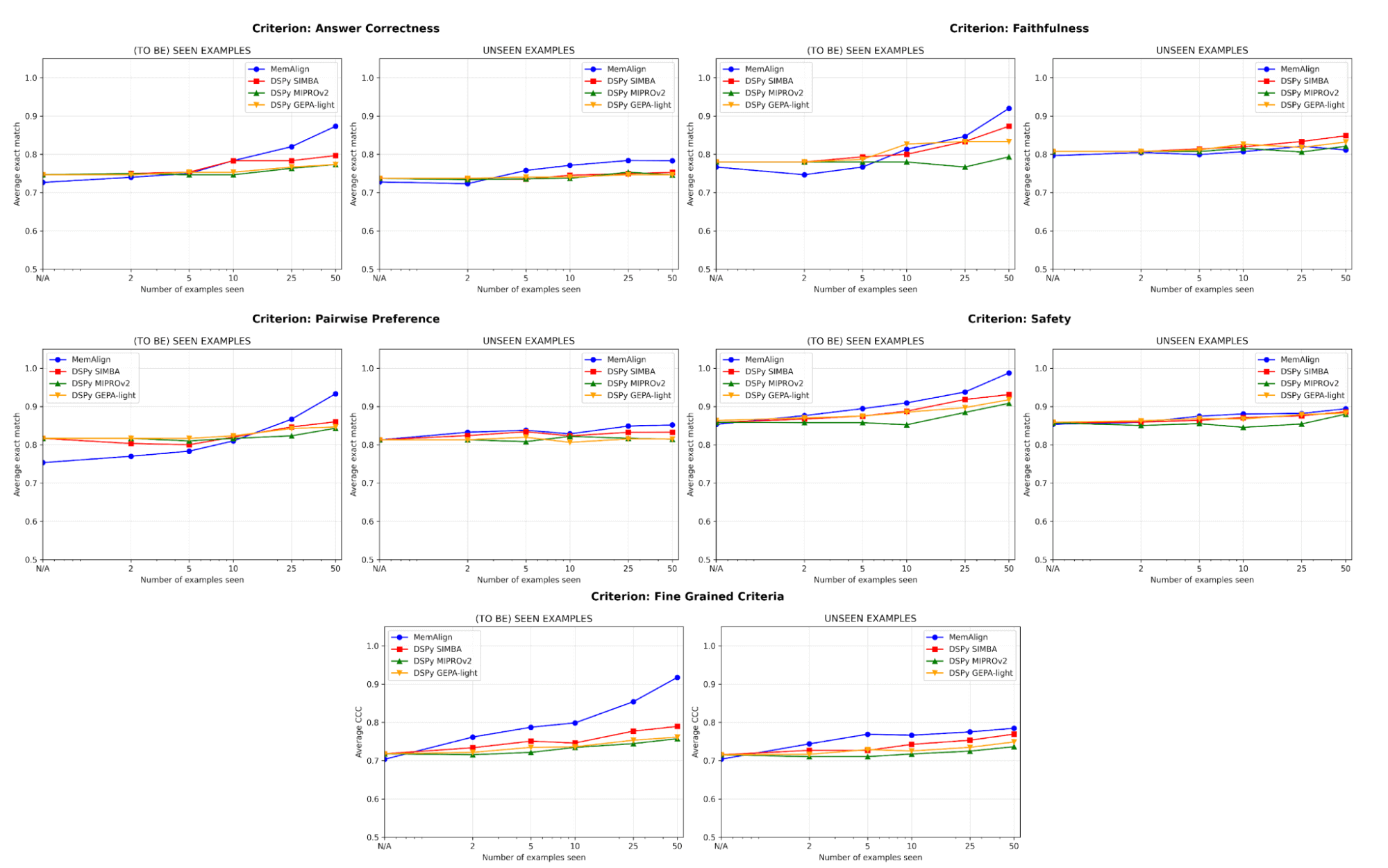
{kind=link}
Um dos maiores riscos no alinhamento é a regressão: corrigir um erro apenas para quebrá-lo novamente mais tarde. Em todos os critérios, o MemAlign tem o melhor desempenho em exemplos vistos (à esquerda), geralmente atingindo mais de 90% de acurácia, enquanto outros métodos geralmente estagnam na casa dos 70-80%.
Em exemplos não vistos (à direita), o MemAlign mostra uma generalização competitiva. Ele supera o desempenho dos otimizadores de prompt do DSPy em Correção da Resposta e fica muito próximo em outros critérios. Isso indica que ele não está apenas memorizando correções, mas extraindo conhecimento transferível do feedback.
Esse comportamento ilustra o que chamamos de escalonamento de memória: diferentemente do escalonamento em tempo de teste, que aumenta a computação por query, o escalonamento de memória melhora a qualidade ao acumular feedback de forma persistente ao longo do tempo.
Você não precisa de muitos exemplos para começar
Mais importante ainda, o MemAlign mostra uma melhoria visível com apenas 2 a 10 exemplos, especialmente em Critérios Detalhados e Correção da Resposta. No raro caso em que o MemAlign começa mais baixo (por exemplo, Preferência Pareada), ele rapidamente alcança o mesmo nível com 5 a 10 exemplos. Isso significa que você não precisa fazer um grande esforço de rotulagem antecipadamente antes de ver valor. Uma melhoria significativa acontece quase que imediatamente.
Sob o capô: o que faz o MemAlign funcionar?
Para entender melhor o comportamento do sistema, executamos ablações adicionais em um dataset de amostra (onde o critério do juiz é “O modelo consegue interpretar corretamente a terminologia técnica ou o jargão específico da indústria”) do benchmark prometheus-eval. Usamos o mesmo LLM (GPT-4.1-mini) como nos experimentos principais.
Os dois módulos de memória são necessários? Após a ablação de cada módulo de memória, observamos quedas de desempenho em ambos os casos. Ao remover a Memória Semântica, o juiz perde sua base estável de princípios; ao remover a Memória Episódica, ele tem dificuldades com casos extremos. Ambos os componentes são importantes para o desempenho.
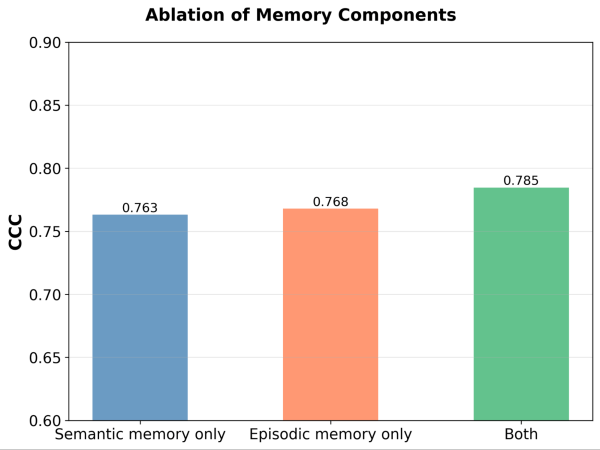
Figura 5. Desempenho (medido pelo Coeficiente de Correlação de Concordância (CCC)) do MemAlign com apenas a memória semântica, apenas a memória episódica, ou ambas ativadas.
O feedback é pelo menos tão eficaz quanto os rótulos, especialmente no início. Dado um orçamento de anotação fixo, em que tipo de sinal de aprendizado vale mais a pena investir: rótulos, feedback em linguagem natural ou ambos? Vemos uma ligeira vantagem inicial (<=5 exemplos) para o feedback em relação aos rótulos, com a diferença diminuindo à medida que os exemplos se acumulam. Isso significa que, se seus especialistas só tiverem tempo para um punhado de exemplos, pode ser melhor que eles expliquem seu raciocínio; caso contrário, apenas os rótulos podem ser suficientes.
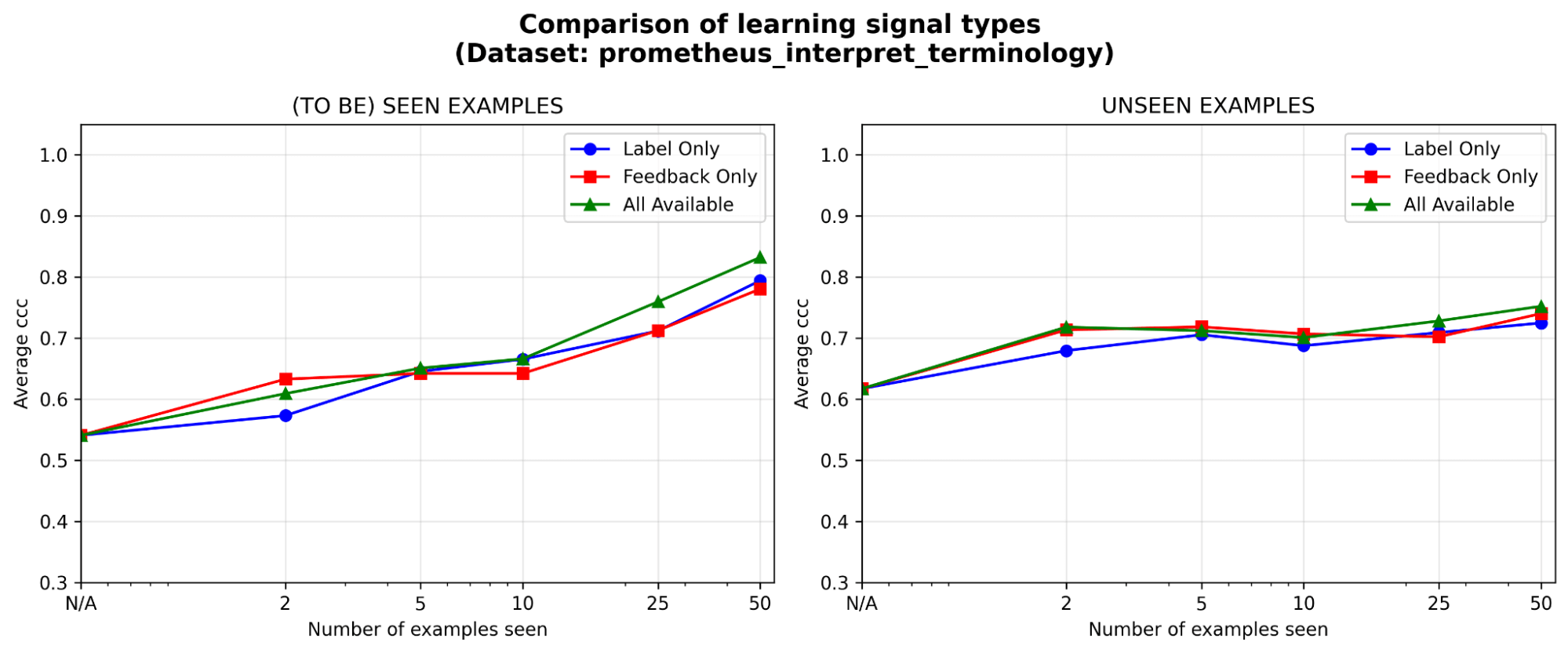
{kind=link}
O MemAlign é sensível à escolha do LLM? Executamos o MemAlign com LLMs de diferentes famílias e tamanhos. No geral, o Claude-4.5 Sonnet tem o melhor desempenho. Mas modelos menores ainda mostram uma melhora substancial: por exemplo, embora o GPT-4.1-mini comece com um desempenho baixo, ele iguala o desempenho de modelos de fronteira como o GPT-5.2 depois de ver 50 exemplos. Isso significa que você não fica preso a modelos de fronteira caros para obter valor.
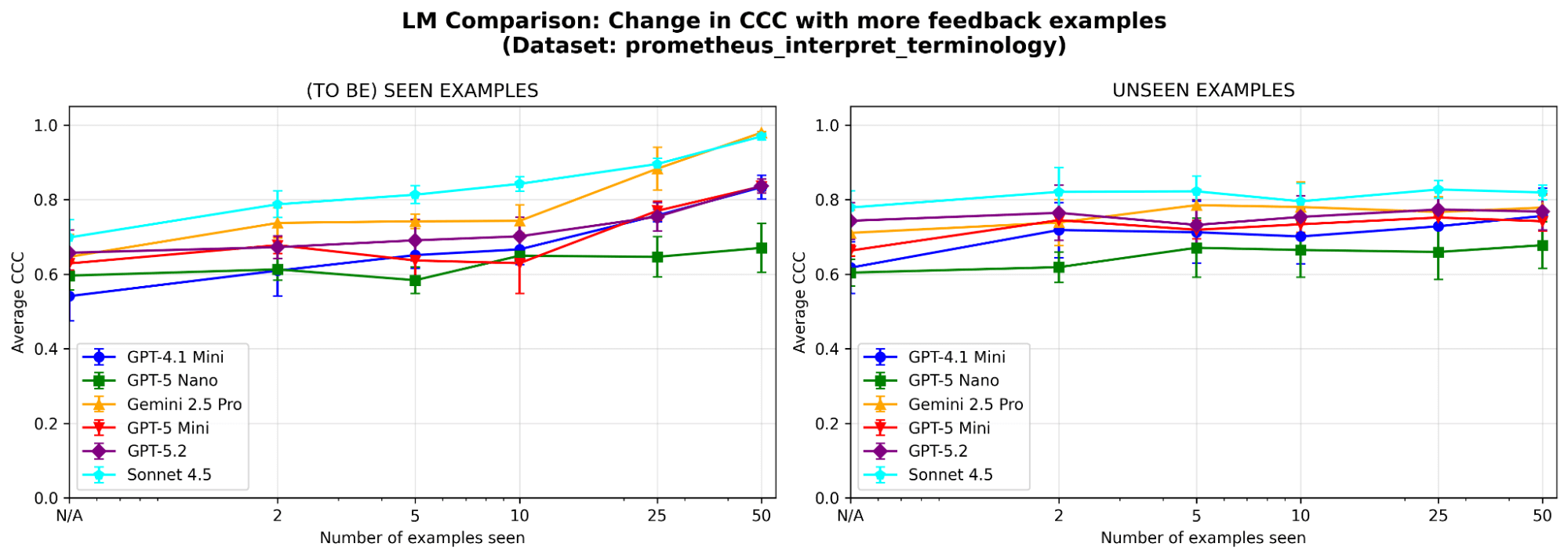
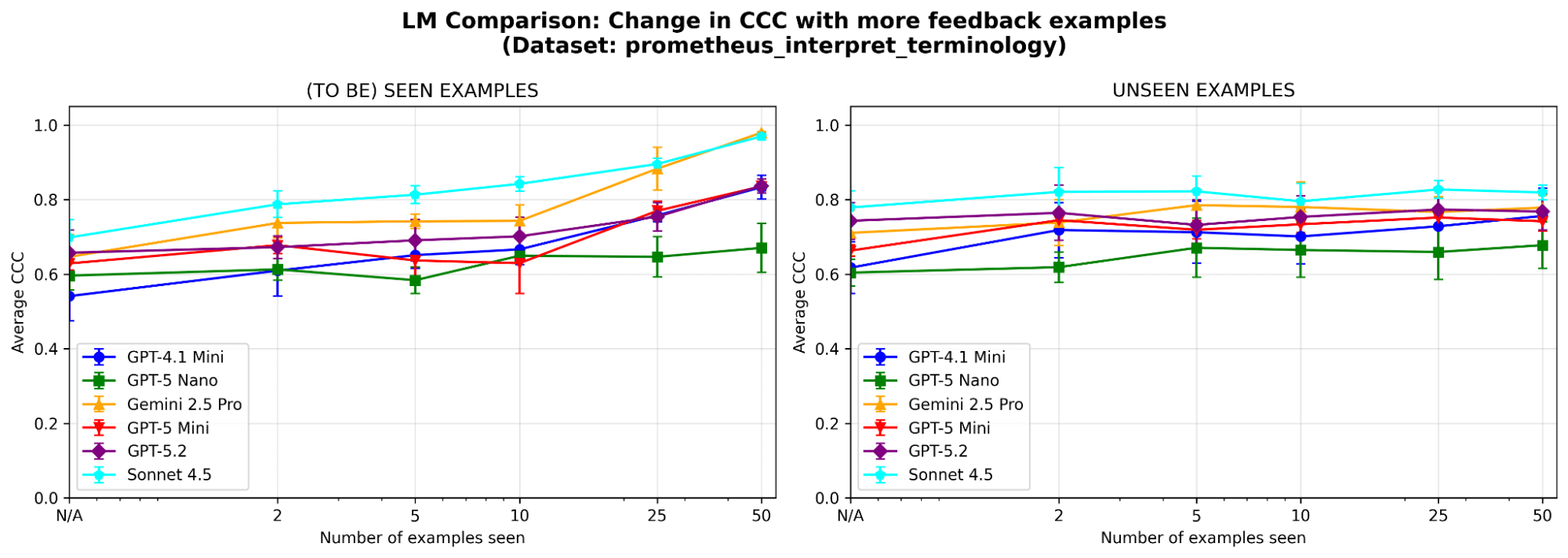{kind=link}
Conclusões
O MemAlign preenche a lacuna entre LLMs de propósito geral e as nuances específicas do domínio, usando uma arquitetura de memória dupla que permite um alinhamento rápido e de baixo custo. Ele reflete uma filosofia diferente: aproveitar o feedback denso em linguagem natural de especialistas humanos em vez de aproximá-lo com um grande número de rótulos. De forma mais ampla, o MemAlign destaca a promessa do escalonamento de memória: ao acumular lições em vez de reotimizar repetidamente, os agentes podem continuar a melhorar sem sacrificar a velocidade ou o custo. Acreditamos que este paradigma será cada vez mais importante para fluxos de trabalho de agentes de longa duração e com especialistas no ciclo.
O MemAlign agora está disponível como um algoritmo de otimização no método align() do MLFlow. Confira este notebook de demonstração para começar!
1Os resultados acima comparam a velocidade de alinhamento; no tempo de inferência, o MemAlign pode incorrer em um adicional de 0,8–1s por exemplo devido à busca vetorial na memória, em comparação com juízes otimizados por prompt.
Autores: Veronica Lyu, Kartik Sreenivasan, Samraj Moorjani, Alkis Polyzotis, Sam Havens, Michael Carbin, Michael Bendersky, Matei Zaharia, Xing Chen
Gostaríamos de agradecer a Krista Opsahl-Ong, Tomu Hirata, Arnav Singhvi, Pallavi Koppol, Wesley Pasfield, Forrest Murray, Jonathan Frankle, Eric Peter, Alexander Trott, Chen Qian, Wenhao Zhan, Xiangrui Meng, Moonsoo Lee e Omar Khattab pelo feedback e apoio durante o design, a implementação e a publicação no blog do MemAlign. Além disso, somos gratos a Michael Shtelma, Nancy Hung, Ksenia Shishkanova e à Flo Health por nos ajudarem a avaliar o MemAlign em seus datasets internos anonimizados.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.