O que são baldes de hash?
Uma técnica de engenharia de recursos que mapeia variáveis categóricas de alta cardinalidade em vetores de tamanho fixo usando funções hash para uso eficiente de memória em aprendizado de máquina.
- Aplica funções hash (como MurmurHash3) para converter recursos categóricos em buckets de tamanho fixo, evitando a explosão de memória da codificação one-hot para variáveis de alta cardinalidade.
- Aceita colisões de hash, onde múltiplos valores são mapeados para o mesmo bucket, trocando um pouco de precisão por uma eficiência drástica de memória e computação em streaming e aprendizado em larga escala.
- Comumente usado em filtragem de spam, sistemas de recomendação e previsão de CTR, onde os espaços de recursos podem ter milhões de valores únicos que tornam a codificação tradicional inviável.
Tabelas hash [HashMaps] na computação são estruturas de dados que efetivamente permitem acesso direto a objetos com base em suas chaves [strings ou integer exclusivos]. Uma tabela hash usa uma função hash para indexar em uma matriz de buckets ou slots para encontrar o valor desejado. As principais características das chaves utilizadas são:
- As chaves usadas podem ser números de previdência social (SSN, na sigla em inglês), números de telefone, números de contas etc.
- As chaves devem ser exclusivas.
- Cada chave é associada (mapeada) a um valor.
O manual de IA agêntica para empresas

Os buckets hash são usados para atribuir itens de dados para fins de classificação e pesquisa. O objetivo deste trabalho é enfraquecer a lista encadeada para que as buscas por itens específicos sejam acessíveis em um curto espaço de tempo. 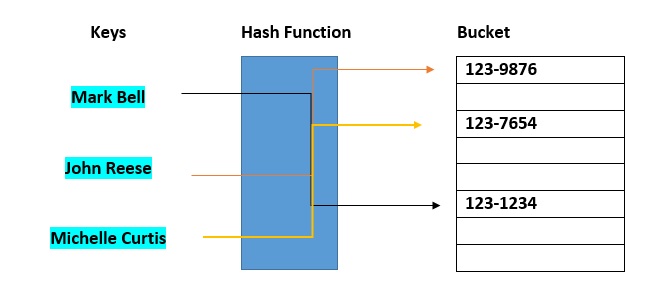 Uma tabela hash que usa buckets é, na verdade, uma combinação de uma matriz e uma lista encadeada. Cada elemento da matriz [tabela hash] é um cabeçalho de uma lista encadeada. Todos os elementos com hash para o mesmo local são armazenados na lista. A função hash atribui cada registro ao primeiro slot em um bucket. Se um slot estiver cheio, os slots de bucket serão pesquisados em ordem até que um slot vazio seja encontrado. Se o bucket estiver cheio, os registros serão armazenados em um bucket de overflow de capacidade infinita no final da tabela. Todos os buckets compartilham o mesmo bucket de overflow. No entanto, uma boa implementação usa uma função hash que distribui os registros de maneira uniforme pelos buckets para minimizar o máximo possível o número de registros no bucket de overflow.
Uma tabela hash que usa buckets é, na verdade, uma combinação de uma matriz e uma lista encadeada. Cada elemento da matriz [tabela hash] é um cabeçalho de uma lista encadeada. Todos os elementos com hash para o mesmo local são armazenados na lista. A função hash atribui cada registro ao primeiro slot em um bucket. Se um slot estiver cheio, os slots de bucket serão pesquisados em ordem até que um slot vazio seja encontrado. Se o bucket estiver cheio, os registros serão armazenados em um bucket de overflow de capacidade infinita no final da tabela. Todos os buckets compartilham o mesmo bucket de overflow. No entanto, uma boa implementação usa uma função hash que distribui os registros de maneira uniforme pelos buckets para minimizar o máximo possível o número de registros no bucket de overflow.
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.