O que é um Conjunto de Dados Distribuído Resiliente (RDD)?
Entenda a estrutura de dados fundamental do Spark para processamento paralelo distribuído e tolerante a falhas.
- Entenda o que são RDDs e como eles funcionam como coleções de dados imutáveis e particionadas para processamento paralelo no Apache Spark.
- Aprenda os cinco principais cenários em que os RDDs são a escolha certa, incluindo dados não estruturados e controle de transformação de baixo nível.
- Explore como os RDDs se relacionam com DataFrames e Datasets e quando usar cada API.
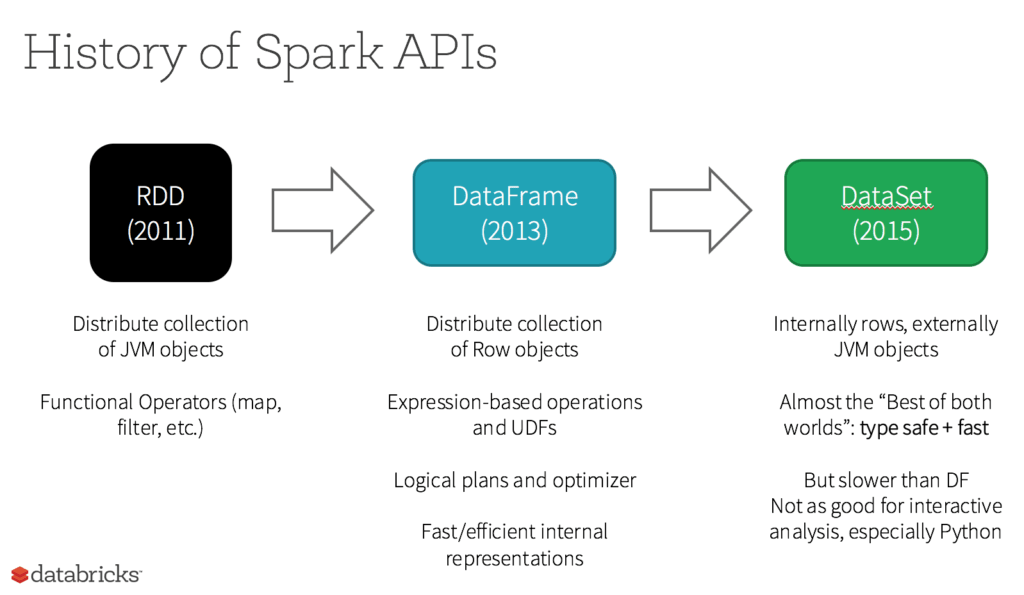
Os conjuntos de dados distribuídos resilientes (RDDs) têm sido a principal API voltada para o usuário do Spark desde seu lançamento. Um RDD é uma coleção imutável de elementos de dados localizados em vários nós em um cluster e pode ser usado juntamente com APIs subjacentes para transformações e outras operações.
Cinco motivos para usar RDDs
- Para executar transformações, ações e controle de baixo nível em conjuntos de dados;
- Quando seus dados não são estruturados, como streams de mídia ou de texto;
- Para trabalhar com dados em programação funcional em vez de linguagens específicas de domínio;
- Se você não se importar em especificar um esquema, como um formato em colunas, ao manipular ou acessar atributos de dados por nome ou coluna; e
- Se você não precisa dos recursos de otimização e desempenho de DataFrames e conjunto de dados para dados estruturados e semiestruturados.
O manual de IA agêntica para empresas

Qual é a função dos RDDs no Apache Spark 2.0?
Os RDDs são considerados menos importantes? Eles estão ficando obsoletos? A resposta é um NÃO bem enfático! Além disso, você pode alternar perfeitamente entre DataFrames/conjunto de dados e RDDs chamando métodos simples de API, e DataFrames/conjunto de dados são baseados em RDDs.
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.