O que é o ajuste de faísca?
Otimização sistemática das configurações do Apache Spark, uso de memória e estratégias de execução para maximizar o desempenho e, ao mesmo tempo, evitar gargalos de recursos.
- O ajuste do Spark otimiza a alocação de memória entre armazenamento e execução, gerencia a serialização de dados para melhor desempenho de rede e otimiza partições de shuffle para evitar o desperdício de espaço em disco.
- A Execução Adaptativa de Consultas (AQE) encontra automaticamente partições de shuffle ideais e resolve a distorção de dados, enquanto o Otimizador Baseado em Custo (CBO) usa estatísticas da tabela para selecionar estratégias de junção eficientes.
- Técnicas avançadas incluem junções de broadcast para tabelas pequenas, pushdown de predicados para reduzir a transferência de dados e gerenciamento cuidadoso do cache versus armazenamento em disco para acesso repetido aos dados.
O que é ajuste de desempenho do Spark?
O ajuste de desempenho do Spark é o processo de ajuste das configurações para registro de memória, núcleos e instâncias usadas pelo sistema. Esse processo oferece excelente desempenho ao Spark e também ajuda a evitar gargalos de recursos. 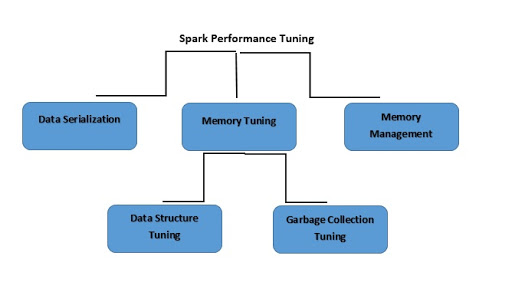
O que é serialização de dados?
Para reduzir o uso de memória, talvez seja necessário armazenar RDDs Spark serializados. A serialização de dados também afeta o desempenho da rede. Aqui estão algumas coisas que você pode fazer para melhorar o desempenho do Spark:
- Encerrar jobs de execução longa;
- Executar jobs com o mecanismo de execução apropriado;
- Usar todos os recursos de forma eficiente;
- Melhorar o tempo de desempenho do seu sistema.
O Spark é compatível com duas bibliotecas de serialização:
- Serialização Java;
- Serialização Kryo.
O que é ajuste de memória?
Há três aspectos a serem destacados ao ajustar o uso da memória:
- A consideração da quantidade de memória usada por um objeto se torna essencial, pois todos os conjuntos de dados devem caber na memória.
- O aumento da rotatividade de objetos requer sobrecarga de coleta de lixo.
- O custo de acesso a esses objetos.
O manual de IA agêntica para empresas

O que é ajuste da estrutura de dados?
Para reduzir o consumo de memória, você tem a opção de evitar funções Java que podem sobrecarregar. Aqui estão algumas maneiras de fazer isso:
- Se o tamanho da RAM for inferior a 32 GB, defina sinalizadores JVM como –xx:+ UseCompressedOops. Essa operação criará um ponteiro de quatro bytes em vez de oito.
- Use vários objetos pequenos e ponteiros para evitar estruturas aninhadas.
- Use IDs numéricos ou objetos enumerados em vez de usar strings para chaves.
O que é o ajuste da coleta de lixo?
Para evitar a grande “rotatividade” relacionada aos RDDs anteriormente armazenados pelo programa, o Java exclui objetos antigos e aloca espaço para novos objetos. Por outro lado, usar uma estrutura de dados com menos objetos reduz muito o custo. Um exemplo seria usar um array de Ints em vez de um LinkedList. Como alternativa, você pode usar objetos serializados para ter apenas um objeto por partição RDD.
O que é gerenciamento de memória?
O uso eficaz da memória é essencial para um bom desempenho. O Spark usa a memória principalmente para armazenamento e execução. A memória de armazenamento é usada para armazenar dados em cache para reutilização posterior. A memória de execução, por outro lado, é usada para cálculos como shuffle, ordenar, juntar e agregar. Existem três desafios de contenção de memória que o Apache Spark deve resolver:
- Arbitrar memória entre execução e armazenamento;
- Arbitrar memória para tarefas simultâneas;
- Arbitrar memória para operadores em execução na mesma tarefa.
Em vez de evitar a alocação de memória estática antecipadamente, você pode forçar a liberação dos dados da memória e reagir à contenção de memória à medida que ela surgir.
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.