O que é Sparklyr?
Um pacote R que fornece sintaxe no estilo dplyr para o Apache Spark, permitindo que usuários do R realizem manipulação de dados distribuída e aprendizado de máquina em conjuntos de dados massivos.
- Oferece a sintaxe familiar do tidyverse dplyr (select, filter, mutate, group_by) que se traduz perfeitamente em operações distribuídas do Spark em conjuntos de dados grandes demais para processamento local em R.
- Integra-se com o Spark MLlib e o H2O SparkingWater para aprendizado de máquina distribuído, além de suportar funções definidas pelo usuário por meio do spark_apply para computações personalizadas em R em grande escala.
- Conecta-se a clusters Databricks por meio do método 'databricks' em spark_connect, funcionando em conjunto com o SparkR e compatível com o RStudio para desenvolvimento e depuração interativos.
O que é o Sparklyr?
O Sparklyr é um pacote de código aberto que fornece uma interface entre R e Apache Spark. Agora, você pode aproveitar os recursos do Spark em um ambiente R moderno, graças à capacidade do Spark de interagir com dados distribuídos com pouca latência. O Sparklyr é uma ferramenta eficaz para interface com grandes conjuntos de dados em um ambiente interativo. Dessa forma, você pode se beneficiar das ferramentas familiares do R para analisar dados no Spark, obtendo o melhor dos dois mundos. 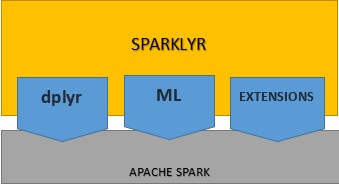 Com o Sparklyr, você pode usar o Spark como backend do dplyr, um pacote popular de manipulação de dados. O Sparklyr fornece uma série de funções que permitem acessar as ferramentas do Spark para transformar/pré-processar dados. Além disso, ele oferece interfaces para os algoritmos de machine learning distribuídos do Spark e muito mais. O Sparklyr também é extensível. É possível criar pacotes R que dependem do Sparklyr para chamar a API Spark completa. Uma dessas extensões é o Rsparkling do H2O, um pacote R compatível com o algoritmo de machine learning do H2O.
Com o Sparklyr, você pode usar o Spark como backend do dplyr, um pacote popular de manipulação de dados. O Sparklyr fornece uma série de funções que permitem acessar as ferramentas do Spark para transformar/pré-processar dados. Além disso, ele oferece interfaces para os algoritmos de machine learning distribuídos do Spark e muito mais. O Sparklyr também é extensível. É possível criar pacotes R que dependem do Sparklyr para chamar a API Spark completa. Uma dessas extensões é o Rsparkling do H2O, um pacote R compatível com o algoritmo de machine learning do H2O.
O manual de IA agêntica para empresas

Destaques principais do Sparklyr:
- Os usuários podem manipular interativamente os dados do Spark usando dplyr e SQL (via DBI).
- Os conjuntos de dados do Spark podem ser filtrados, agregados e depois trazidos para R para serem analisados.
- Você poderá orquestrar o machine learning distribuído a partir do R usando o Spark MLLib ou o H2O SparkingWater.
- Os usuários do Sparklyr podem gerar extensões que chamam a API Spark completa e fornecer interfaces para pacotes do Spark.
- A ferramenta Sparklyr oferece um backend exaustivo do dplyr, útil em caso de manipulação, análise e visualização de dados
- Carrega dados em DataFrames Spark de vários locais, como quadros de dados R locais, tabelas Hive, CSV, JSON e arquivos Parquet.
- O Sparklyr consegue se conectar a instâncias locais do Spark, bem como a clusters remotos do Spark
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.