iFood, a maior plataforma de delivery do Brasil, opera em uma escala impressionante: são 300 mil entregadores, 55 milhões de usuários e 350 mil restaurantes parceiros. Esse ecossistema gera um enorme volume de dados em tempo real todos os dias, abrangendo pedidos de clientes, logística de entrega e interações no app. Com diversos produtos e plataformas coletando dados em toda a empresa, o iFood processa bilhões de registros diariamente para análise e modelagem, garantindo suporte a decisões estratégicas de negócios. Para sustentar sua expansão e aprimorar seus serviços, a empresa precisava de uma plataforma de dados mais confiável, escalável e eficiente, capaz de atender à crescente demanda por insights em tempo real e inovação.
Arquitetura fragmentada e silos de dados comprometiam agilidade e precisão
Antes de adotar a Databricks Platform, o iFood enfrentava desafios significativos devido a uma arquitetura de dados fragmentada, que dificultava a escalabilidade e a eficiência operacional. A empresa dependia de uma infraestrutura complexa, com múltiplos sistemas para gerenciar um volume massivo de dados sobre a jornada dos usuários — bilhões de registros provenientes de diversas fontes, como o sistema de gestão de pedidos, o aplicativo do consumidor e o app dos entregadores. Com o crescimento do ecossistema e a diversificação dos modelos de negócio, o volume e a variedade de dados aumentaram exponencialmente, tornando o processamento de informações ainda mais desafiador.
Com esses dados dispersos em sistemas distintos, consolidar e acessar informações críticas de forma rápida e confiável tornou-se uma tarefa árdua. A fragmentação gerava ineficiências operacionais significativas, dificultando o rastreamento de eventos e tornando a governança de dados um processo demorado e suscetível a erros. A equipe de engenharia de dados do iFood precisava dedicar um grande esforço para codificar, otimizar e manter fluxos de dados complexos manualmente. Além disso, a resolução de problemas exigia inúmeras horas, demandando alinhamento com múltiplas equipes até mesmo para implementar pequenas mudanças.
Essa realidade consumia recursos, limitava a inovação e deixava pouco espaço para iniciativas estratégicas. O desafio se agravava com o crescimento exponencial da base de dados. O que antes era uma arquitetura legada capaz de processar 100 milhões de eventos por dia tornou-se insuficiente diante do salto para um volume diário de 8 a 10 bilhões de eventos. Com a necessidade de treinar modelos em tempo real para analisar a jornada dos usuários e fornecer insights acionáveis, a baixa latência em grande escala tornou-se um requisito essencial.
Streamlining pipelines, reducing maintenance and enabling real-time insights
Spark Declarative Pipelines proved to be a game changer for iFood. Spark Declarative Pipelines enabled iFood to shift to a declarative approach for pipeline development. Engineers could now describe their desired transformations in simple code, allowing Spark Declarative Pipelines to automatically handle the operational complexity behind these pipelines, including execution, scaling and monitoring. “So far we’ve reduced coding time by approximately 30% using the declarative approach, allowing us to build pipelines significantly faster than before,” said Thiago Julião, Data Architecture Specialist at iFood. This transition also simplified and consolidated iFood’s data architecture, reducing the number of tables from nearly 4,000 to just 100. This reduction also made governance more manageable and laid the foundation for improved data quality.
Before Spark Declarative Pipelines, iFood’s pipelines were hindered by out-of-memory errors during high-volume event ingestions, leading to frequent driver shutdowns and operational disruptions. These recurring failures required constant attention from the data engineering team. However, since implementing Spark Declarative Pipelines in production, the transformation has been remarkable.
“With Spark Declarative Pipelines, we gained greater ease in tracking the user’s journey in the application while ensuring high performance in data usage by consumer teams — this was a game changer in our process,” said Maristela Albuquerque, Data Manager, at iFood.
iFood’s unified data architecture
iFood’s technical architecture is now designed to process streaming data at an immense scale, ensuring efficiency, governance and scalability. Here’s a detailed breakdown of the architecture and how its components work together to handle 10 billion daily events while delivering real-time insights.
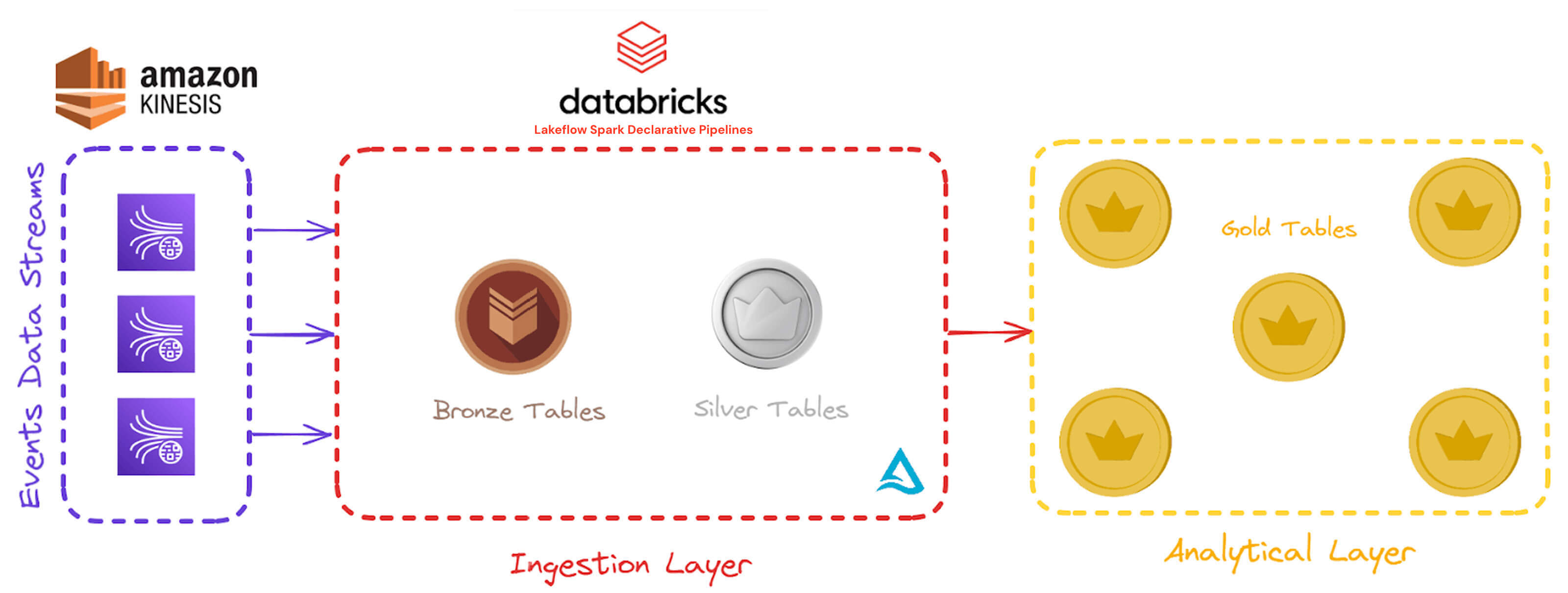
The data pipeline starts with real-time ingestion of events from iFood’s ecosystem, including the consumer app, delivery driver app and partner portal. These events flow through Amazon Kinesis queues, where approximately 10 billion records are ingested daily.
The ingestion pipeline, powered by Spark Declarative Pipelines, enables real-time data ingestion with scalability, resilience and quality. By adopting Spark Declarative Pipelines, iFood reduced ingestion latency from hours to seconds — ensuring low-latency data availability critical for real-time analytics, such as training models and extracting insights during the user journey without delays. “Pipelines now run error-free, delivering reliable performance even under the heaviest workloads,” said Julião. “The shift from frequent errors to near-zero issues moving to Spark Declarative Pipelines has not only improved operational efficiency but also freed up our team to focus on strategic initiatives instead of firefighting. We’ve reduced data pipeline maintenance efforts by about 70% by consolidating all pipelines to Spark Declarative Pipelines.”
iFood’s architecture leverages a structured medallion approach to manage massive data volumes effectively. The Bronze layer consolidates data from various platforms into a single table per product, using a predefined schema partitioned by processing date. Acting as a staging zone, it ensures extended data retention compared to the message queues.
In the Silver layer, iFood applies Spark Declarative Pipelines expectations and quality rules to validate the data. By replacing traditional partitioning with Liquid Clustering, all events for a product are consolidated into a single table, significantly improving performance and usability. This optimization allows iFood to manage massive datasets — such as their largest table, which spans 210TB and 800 billion records — while maintaining high data quality and governance. “Previously, managing two separate environments required constant communication across teams, making even small changes challenging. Now, with everything under our control, the process is streamlined and more efficient,” said Gabriel Campos, Head of Data and AI at iFood.
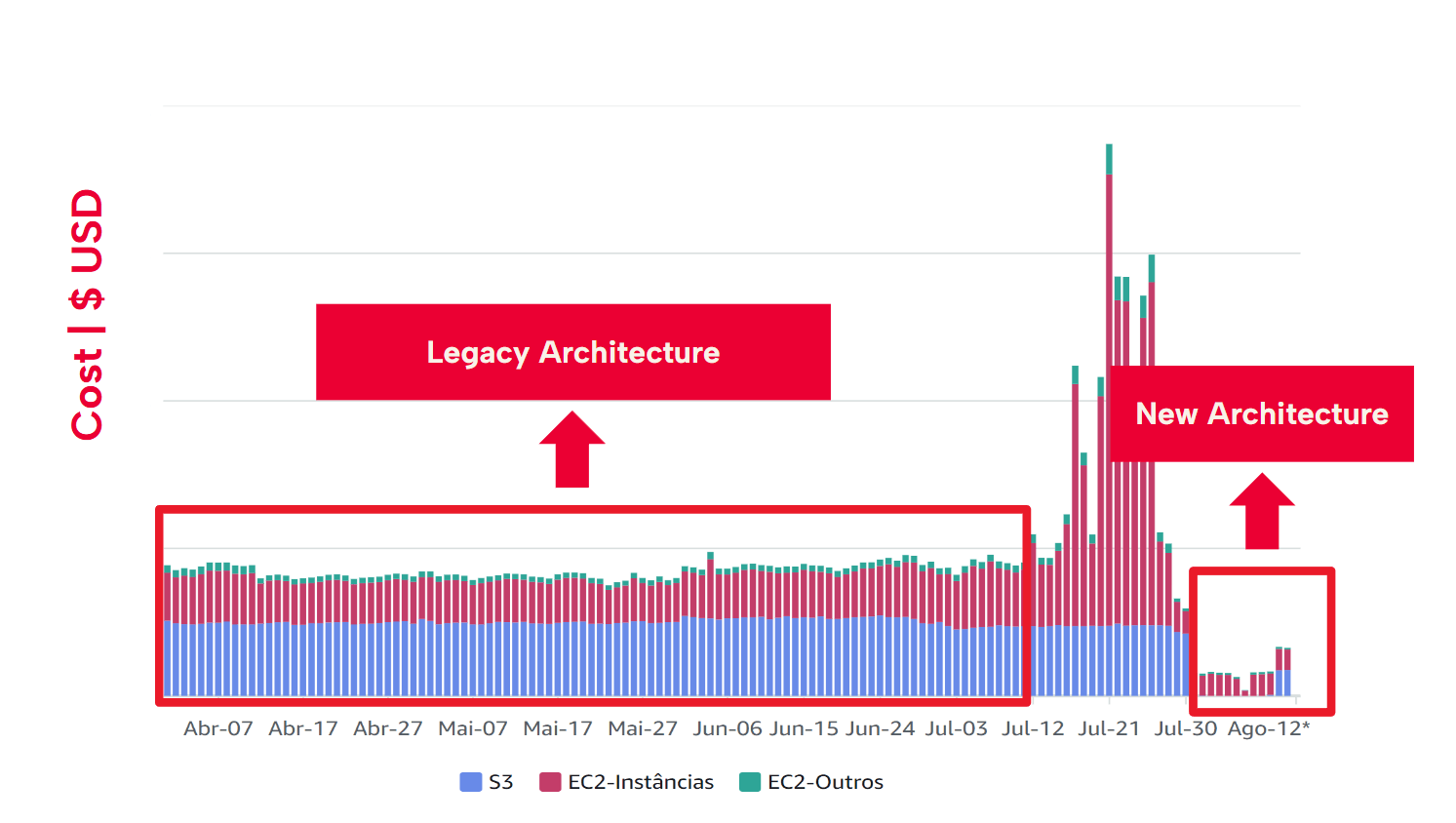
The new architecture has enabled iFood to centralize data governance and enhance data quality without compromising performance or usability. Additionally, it has significantly reduced processing and storage costs, achieving a 67% cost reduction — cutting expenses from tens of thousands to just thousands of dollars per month.
With Spark Declarative Pipelines automating and streamlining data pipeline management, iFood’s business analysts from the growth and product teams can now effortlessly access data from the Silver layer to create analytical Gold tables, empowering them to generate business-critical insights with ease. This supports user journey analysis and A/B testing on consumer behavior at various stages of their journey, enabling the creation of data-driven strategies to enhance the customer experience across iFood’s ecosystem. For example, the driver app provides critical insights to the logistics team, helping them understand how drivers interact with the app and optimize its usability. These insights allow iFood to fine-tune both consumer-facing and operational processes, ensuring a seamless experience for customers and efficiency for drivers.
iFood plans to further enhance their Databricks implementation by leveraging Databricks Asset Bundles (DABs) for streamlined development and serverless computing for greater flexibility. Upcoming initiatives include implementing column masking for sensitive data in the consumption layer and optimizing table performance with variant type handling for complex data structures like structs and maps.
iFood’s transformation to a modern, unified data architecture has redefined how the company processes and leverages their vast data ecosystem. And by adopting Spark Declarative Pipelines, iFood streamlined their operations, eliminated inefficiencies and established a foundation for real-time insights and enhanced governance. This shift has not only improved the reliability and agility of the company’s data pipelines but also freed up their teams to focus on innovation and delivering value to the business. With a scalable, efficient and future-ready architecture, iFood is now equipped to respond to the demands of a dynamic market while continuing to elevate the customer experience.