solução de data warehouse

O que é um data warehouse?
Data warehouse é um sistema de gerenciamento de dados que armazena dados atuais e históricos de várias fontes para as empresas obterem facilmente insights e relatórios. Os data warehouses são normalmente usados para business intelligence (BI), analítica, relatórios, aplicativos de dados, preparação de dados para machine learning (ML) e análise de dados.
Os data warehouses possibilitam a análise rápida e fácil de dados empresariais carregados de sistemas operacionais, como sistemas de ponto de venda, sistemas de gerenciamento de estoque ou bancos de dados de vendas ou marketing. Os dados podem passar por um armazenamento de dados operacional e exigir limpeza de dados para garantir a qualidade antes de serem usados no data warehouse para geração de relatórios.
Here’s more to explore


Para que são usados os data warehouses?
Os data warehouses são usados em BI, analítica, relatórios, aplicativos de dados, preparação de dados para machine learning e análise de dados para extrair e resumir dados de bancos de dados operacionais. Informações que são difíceis de analisar diretamente de bancos de dados transacionais podem ser analisadas por meio de data warehouses. Por exemplo, a gerência quer saber as receitas totais geradas mensalmente por vendedor para cada categoria de produto. Os bancos de dados transacionais podem não conseguir capturar esses dados, mas o data warehouse consegue.
Quais são os tipos de data warehouse?
- Data warehouse tradicional: armazena apenas dados estruturados. A estrutura de um data warehouse permite que os usuários acessem dados de forma rápida e fácil para relatórios e analítica.
- Data warehouse inteligente: tipo moderno de data warehouse construído em uma arquitetura de lakehouse e que possui uma plataforma inteligente e de otimização automática. Um data warehouse inteligente não apenas fornece acesso aos modelos de AI e ML, mas também usa a AI para auxiliar nas queries, na criação de dashboards e na otimização de desempenho e dimensionamento.
Arquitetura de data warehouse
Um modelo comum para arquitetura de data warehouse é o de várias camadas. Essa arquitetura foi criada por Bill Inmon, o cientista da computação considerado o pai do data warehouse.
Camada inferior
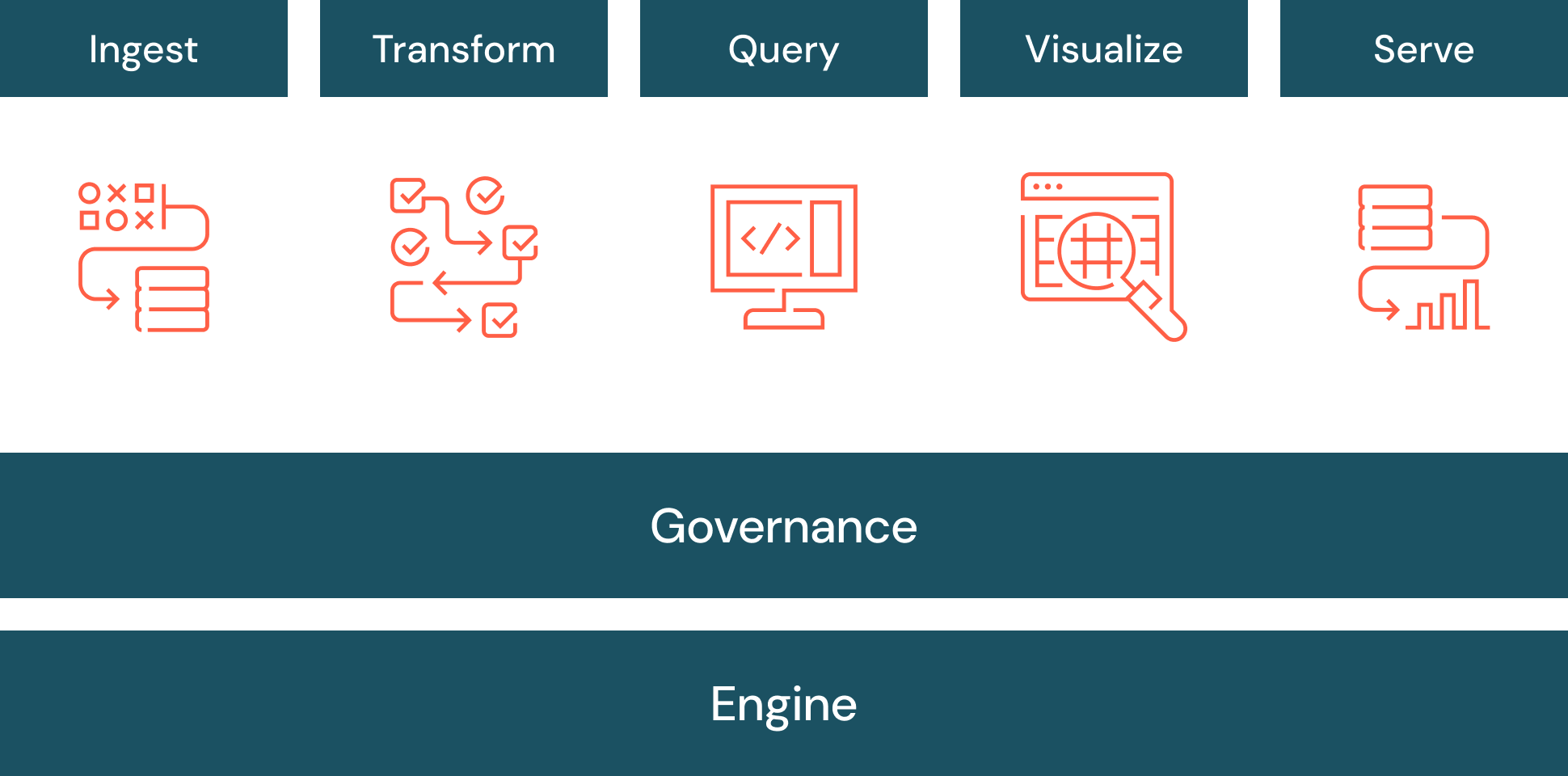
A camada inferior de uma arquitetura de data warehouse é composta por fontes de dados e armazenamento de dados. Essa camada inclui métodos de acesso a dados, como APIs, gateways, ODBC, JDBC e OLE-DB. A ingestão de dados ou ETL também está incluída na camada inferior.
Camada intermediária
A camada intermediária de uma arquitetura de data warehouse é composta por um servidor OLAP, que pode ser relacional (ROLAP) ou multidimensional (MOLAP). Esses dois tipos podem ser combinados em um OLAP híbrido (HOLAP).
Camada superior
A camada superior de uma arquitetura de data warehouse é composta pelos clientes front-end para queries, BI, dashboards, relatórios e análises.
Quais são as três variações de um data warehouse?
- Data warehouse corporativo (EDW): um data warehouse centralizado que é usado por muitas equipes diferentes em uma organização. Muitas vezes, é a única fonte de verdade para BI, analítica e relatórios.
- Armazenamento de dados operacionais (ODS): um tipo de data warehouse que se concentra nos dados operacionais ou transacionais mais recentes.
- Data mart: uma versão simplificada do data warehouse que atende a uma única linha de negócios (LOB) ou a um único projeto. Um data mart é menor do que um EDW, mas o número de data marts normalmente aumenta à medida que a organização cresce e os LOBs querem fazer o autoatendimento.
Data lake, banco de dados e data warehouse
Qual é a diferença entre data lake e data warehouse?
Data lakes e data warehouses são duas abordagens diferentes para gerenciar e armazenar dados.
Data lake é um repositório de dados não estruturados ou semiestruturados que permite o armazenamento de grandes quantidades de dados brutos em seu formato original. Os data lakes são projetados para ingerir e armazenar todos os tipos de dados — estruturados, semiestruturados ou não estruturados — sem qualquer esquema predefinido. Geralmente, os dados são armazenados em seu formato nativo e não são limpos, transformados ou integrados, facilitando o armazenamento e o acesso a grandes quantidades de dados.
Um data warehouse tradicional, por outro lado, é um repositório estruturado que armazena dados de várias fontes de maneira bem organizada, com o objetivo de fornecer uma única fonte da verdade para business intelligence e análise de dados. Os dados são limpos, transformados e integrados em um esquema otimizado para consulta e análise.
Um data warehouse inteligente, que usa a arquitetura lakehouse, também fornece uma fonte única de verdade para analítica e inteligência de negócios. Ele estende um data warehouse tradicional armazenando dados estruturados, semiestruturados ou não estruturados. Os recursos de gerenciamento de dados, como qualidade de dados e alertas de threshold, estão incluídos.
Qual é a diferença entre data warehouse e banco de dados?
Banco de dados é uma coleção de dados estruturados, que se estende além de texto e números para imagens, vídeos e muito mais. Muitos se referem a esse sistema de gerenciamento de banco de dados por sua sigla: DBMS. Um DBMS é o sistema de armazenamento de dados que alimenta aplicativos e analítica.
Um data warehouse tradicional, por outro lado, é um repositório estruturado que fornece dados para business intelligence e analítica. Os dados são limpos, transformados e integrados em um esquema otimizado para consulta e análise, incluindo a adição de agregações comuns.
Qual a diferença entre data lake, data warehouse e data lakehouse?
Data lakehouse é uma abordagem híbrida que combina o melhor dos dois mundos. É uma arquitetura de dados moderna que integra os recursos de um data warehouse tradicional e um data lake em uma plataforma unificada. Ele permite o armazenamento de dados brutos em seu formato original, como um data lake, além de fornecer recursos de processamento e análise de dados, como um data warehouse.
Em resumo, a principal diferença entre data lake, data warehouse tradicional e data lakehouse é a abordagem para gerenciar e armazenar dados. O data warehouse tradicional armazena dados estruturados em um esquema predefinido, o data lake armazena dados brutos em seu formato original e o data lakehouse é uma abordagem híbrida que combina os recursos de ambos.
Data lake | Data lakehouse | Data warehouse tradicional | |
|---|---|---|---|
Tipos de dados | Todos os tipos: dados estruturados, dados semiestruturados, dados não estruturados (brutos) | Todos os tipos: dados estruturados, dados semiestruturados, dados não estruturados (brutos) | Somente dados estruturados |
Custo | $ | $ | $$$ |
Formato | Formato aberto | Formato aberto | Formato fechado e proprietário |
Escalabilidade | Pode ser dimensionado para armazenar qualquer quantidade de dados a baixo custo, independentemente do tipo | Pode ser dimensionado para armazenar qualquer quantidade de dados a baixo custo, independentemente do tipo | A expansão torna-se exponencialmente mais cara devido aos custos do fornecedor |
Público-alvo | Limitado: cientistas de dados | Unificado: analistas de dados, cientistas de dados, engenheiros de machine learning | Limitado: analistas de dados |
Confiabilidade | Baixa qualidade, data swamp | Dados confiáveis e de alta qualidade | Dados confiáveis e de alta qualidade |
Facilidade de uso | Dificuldade: pode ser difícil explorar grandes quantidades de dados brutos sem ferramentas para organizar e catalogar os dados | Simples: oferece simplicidade e a estrutura de um data warehouse com os casos de uso mais amplos de um data lake | Simples: a estrutura de um data warehouse permite que os usuários acessem dados de forma rápida e fácil para relatórios e análises |
Desempenho | Fraco | Alta | Alta |
Um data lake pode substituir um data warehouse?
Na verdade, não. Data lake e data warehouse são duas abordagens diferentes para gerenciar e armazenar dados, cada uma com seus próprios pontos fortes e fracos. Embora um data lake possa complementar um data warehouse, fornecendo dados brutos para análises avançadas, ele não pode, em seu sentido tradicional, substituir totalmente um data warehouse. Em vez disso, o data lake e o data warehouse podem se complementar, com o data lake servindo como fonte de dados brutos para análises avançadas e o data warehouse fornecendo uma fonte estruturada, organizada e confiável de dados comerciais para relatórios e análises.
Um data lake é fundamental para um data lakehouse, que pode substituir um data warehouse tradicional, com confiabilidade e desempenho em formatos de dados abertos, como Delta Lake e Apache Iceberg™.
Um data lakehouse pode substituir um data warehouse tradicional?
Sim. Um data lakehouse é uma arquitetura de dados moderna que combina os benefícios de um data warehouse e de um data lake em uma plataforma unificada. Um data lakehouse é construído em um data lake aberto e pode servir como um substituto para um data warehouse tradicional, pois fornece os recursos de um data lake e de um data warehouse em uma única plataforma.
Um data lakehouse permite o armazenamento de dados brutos em seu formato original, como um data lake, além de fornecer recursos de processamento e análise de dados, como um data warehouse. Ele também oferece uma abordagem de schema-on-read, o que permite flexibilidade no processamento e na consulta de dados. A combinação de um data lake e um data warehouse em uma única plataforma proporciona maior flexibilidade, escalabilidade e economia.
O que é um data warehouse moderno?
O armazenamento de dados continua a evoluir. Um data warehouse moderno também é conhecido como data warehouse inteligente porque usa tecnologias mais recentes, como IA. Um data warehouse inteligente aproveita a arquitetura de data lakehouse aberto em vez da arquitetura tradicional de data warehouse. Um data warehouse inteligente entende a exclusividade de seus dados e otimiza automaticamente a plataforma para escalar para baixa latência e alta simultaneidade. Um data warehouse inteligente também precisa de governança unificada para segurança, controles e fluxo de trabalho. Um data warehouse inteligente usa IA para gerar queries, corrigir erros, sugerir visualizações e muito mais.
O que é ETL em um data warehouse?
Um data warehouse requer dados. Esses dados devem ser carregados no data warehouse (ou referenciados, com um conceito chamado federação de lakehouse). O processo de extração de dados dos sistemas de origem, transformação dos dados e carregamento dos dados no data warehouse é chamado de ETL (extrair, transformar, carregar). O ETL é normalmente usado para integrar dados estruturados de várias fontes em um esquema predefinido.
A federação de queries é um estilo de ETL usado para executar queries em fontes de dados de várias fontes e em várias nuvens. Você pode ver e consultar todos os dados em um único local sem precisar migrar todos eles para um sistema unificado. Às vezes, esse conceito também é chamado de virtualização de dados.
O que é dimensão em um data warehouse?
Uma dimensão de data warehouse é usada para descrever os dados com informações de rótulos estruturados. Uma dimensão usa as informações para filtrar, agrupar e rotular. Por exemplo, uma dimensão pode ser entidades de negócios, como um cliente ou um produto.
O que é fato em um data warehouse?
Um fato de data warehouse é usado para quantificar os dados com números. Por exemplo, um fato pode ser pedidos de clientes ou dados financeiros.
O que é modelagem dimensional em um data warehouse?
A modelagem dimensional é uma técnica de data warehousing que organiza os dados em dimensões e fatos. A modelagem de dimensões identifica processos comerciais importantes e, em seguida, modela o data warehouse para dar suporte a esses processos comerciais.
O que é esquema em estrela em um data warehouse?
Um esquema em estrela é um modelo multidimensional que organiza os dados em um banco de dados para torná-los mais fáceis de entender e analisar. Pode ser aplicado a data warehouses, bancos de dados, data marts e outras ferramentas. O design do esquema em estrela é otimizado para consultar grandes conjuntos de dados.
Introduzido por Ralph Kimball na década de 90, os esquemas em estrela armazenam dados, gerenciam o histórico e atualizam os dados com eficiência, reduzindo a duplicação de definições de negócios repetitivas e agregando e filtrando dados em data warehouses em alta velocidade.
Quais benefícios do data warehouse as empresas podem esperar?
- A consolidação de dados obtidos de muitas fontes. Um data warehouse pode se tornar um ponto de acesso único para todos os dados, em vez de exigir que os usuários se conectem a dezenas ou mesmo centenas de armazenamentos de dados individuais.
- Inteligência histórica. Um data warehouse integra dados de muitas fontes para mostrar tendências históricas.
- Separar o processamento analítico dos bancos de dados transacionais, melhorando o desempenho de ambos os sistemas.
- Qualidade, consistência e precisão dos dados. Um data warehouse bem formado usa um conjunto padrão de semântica em torno dos dados, incluindo consistência em convenções de nomenclatura, códigos para vários tipos de produtos, idiomas, moedas etc.
- Qualquer pessoa pode descobrir respostas a partir dos dados, inclusive usuários sem conhecimento de SQL
Desafios dos data warehouses
Não importa o tipo de data warehouse que você usa, os desafios permanecem:
- Ferramentas desarticuladas entre dados e ativos de AI criam uma abordagem fragmentada, que compromete a governança de dados
- Os usuários precisam de habilidades e treinamento especializados para escrever queries, entender estruturas de dados, encontrar e se conectar às melhores fontes de dados e assim por diante
- À medida que os data warehouses crescem, eles ficam mais lentos e, na nuvem, isso fica caro rapidamente com os custos de compute em nuvem
Escalabilidade e desempenho
Com volumes crescentes de dados, uma arquitetura de lakehouse distribui recursos de compute, independentemente do armazenamento, com o objetivo de manter um desempenho consistente a custos ideais. Você precisa de uma plataforma projetada para elasticidade, permitindo que as organizações dimensionem suas operações de dados conforme necessário. A escalabilidade se estende por várias dimensões:
- Serverless: a plataforma deve permitir que as cargas de trabalho se ajustem e sejam dimensionadas elasticamente com base na capacidade de compute necessária. Essa alocação dinâmica de recursos garante processamento e análise rápidos de dados, mesmo durante picos de demanda.
- Simultaneidade: a plataforma deve aproveitar o compute serverless e as otimizações orientadas por AI para facilitar o processamento simultâneo de dados e a execução de queries. Isso garante que vários usuários e equipes possam realizar tarefas analíticas ao mesmo tempo sem restrições de desempenho.
- Armazenamento: a plataforma deve se integrar perfeitamente aos data lakes, facilitando o armazenamento econômico de grandes volumes de dados e, ao mesmo tempo, garantindo a disponibilidade e a confiabilidade dos dados. Ele também deve otimizar o armazenamento de dados para melhorar o desempenho, reduzindo as despesas de armazenamento.
A escalabilidade, embora essencial, é complementada pelo desempenho. A plataforma deve usar uma variedade de otimizações orientadas por AI para otimizar o desempenho:
- Query otimizada: a plataforma deve usar técnicas de otimização de machine learning para acelerar a execução da query. Ele aproveita a indexação automática, o armazenamento em cache e o envio automático de predicados para garantir que as queries sejam processadas com eficiência, resultando em insights rápidos.
- Dimensionamento automático: a plataforma deve dimensionar de forma inteligente os recursos serverless para corresponder às suas cargas de trabalho, garantindo que você pague apenas pelo compute que usar, mantendo o desempenho ideal das queries.
- Desempenho rápido de queries: a plataforma deve fornecer desempenho de query extremamente rápido a baixo custo — da ingestão de dados, ETL, streaming, ciência de dados e queries interativas — diretamente no seu data lake.
- Delta Lake: a plataforma deve usar modelos de AI para resolver desafios comuns com o armazenamento de dados, para que você obtenha um desempenho mais rápido sem precisar gerenciar manualmente as tabelas, mesmo que elas mudem com o tempo.
- Otimização preditiva: otimiza automaticamente seus dados para obter o melhor desempenho e preço. Ela aprende com seus padrões de uso de dados, cria um plano para as otimizações corretas a serem realizadas e, em seguida, executa essas otimizações em uma infraestrutura serverless hiperotimizada.
Desafios dos data warehouses tradicionais
Os data warehouses tradicionais têm um conjunto adicional de desafios:
- Suporte limitado ou nenhum suporte para dados não estruturados, como imagens, texto, dados de IoT ou frameworks de mensagens, como HL7, JSON e XML. Os data warehouses tradicionais só conseguem armazenar dados limpos e altamente estruturados, embora a Gartner estime que até 80% dos dados de uma organização não sejam estruturados. As organizações que desejam usar seus dados não estruturados para desbloquear o poder da AI precisam procurar outra solução.
- Sem suporte para AI e machine learning: os data warehouses são criados e otimizados especificamente para cargas de trabalho comuns de data warehouse, incluindo relatórios históricos, BI e queries; eles nunca foram projetados nem tiveram como finalidade dar suporte a cargas de trabalho de machine learning.
- Apenas SQL: os data warehouses normalmente não oferecem suporte para Python ou R, as linguagens de escolha para desenvolvedores de aplicativos, cientistas de dados e engenheiros de machine learning.
- Dados duplicados: muitas empresas têm data warehouses e data marts temáticos (departamentais), além de um data lake, o que resulta em dados duplicados, muito ETL redundante e nenhuma fonte de verdade única.
- Difícil de manter sincronizado: manter duas cópias dos dados sincronizadas entre o lake e o warehouse adiciona complexidade e fragilidade que são difíceis de gerenciar. O desvio de dados pode levar a relatórios inconsistentes e análises incorretas.
- Formatos fechados e proprietários aumentam a dependência do provedor: a maioria dos data warehouses corporativos usa seu próprio formato de dados proprietário, em vez de formatos baseados em código aberto e padrões abertos. Isso aumenta a dependência do provedor, dificulta ou impossibilita a análise de seus dados com outras ferramentas e dificulta a migração dos dados.
- Alto custo: os data warehouses comerciais cobram tanto pelo armazenamento quanto pela análise de seus dados. Assim, os custos de armazenamento e compute ainda estão fortemente interligados. A separação de compute e armazenamento com um lakehouse significa que você pode escalar de forma independente, conforme necessário.
- Soluções de relatórios separadas: muitas vezes você precisa fazer perguntas simples sobre seus dados sem os recursos completos de uma solução de relatórios separada, como “Qual é a receita de vendas no terceiro trimestre?”.
- Bloqueio de formato de tabela: você precisa de flexibilidade em todas as linhas de negócios e casos de uso, mas os data warehouses às vezes o prendem a um formato de tabela específico (por exemplo, Apache Iceberg).
Formatos de tabela proprietários
O formato de tabela é a principal tecnologia que traz as vantagens dos data warehouses para os data lakes. Os formatos de tabela organizam dados e metadados de uma forma que representa o estado de uma tabela ao longo do tempo.
Os formatos de tabela proprietários geralmente são usados em ambientes de nuvem, onde o acesso eficiente a grandes conjuntos de dados é crucial para tarefas como analítica, relatórios e machine learning. Provedores específicos criam formatos ou estruturas de arquivo para resolver problemas específicos, como reduzir o tamanho do armazenamento, reduzir as velocidades de leitura/gravação ou adicionar controle de versão.
O formato proprietário da Databricks, o Delta Lake, é uma camada de governança e gerenciamento de dados em formato aberto e de código aberto que combina o melhor dos data lakes e data warehouses. Alguns dos principais recursos incluem:
- Transações ACID: o Delta Lake permite dados consistentes mesmo ao executar operações simultâneas, como atualizações, exclusões e inserções. Isso garante que seus dados estejam sempre atualizados e consistentes.
- Metadados escalonáveis: à medida que os conjuntos de dados crescem, o Delta Lake é dimensionado com eles e permite que os usuários armazenem metadados em tabelas. Isso resulta em alterações nos dados que são mais fáceis de rastrear e compartilhar.
- Imposição do esquema: o Delta Lake garante que todos os seus dados sigam um formato específico em uma tabela.
- Compatibilidade com o Apache Spark™: como o Delta Lake é de código aberto, ele é compatível com as APIs do Apache Spark. Você pode usar o Delta Lake em seus aplicativos Spark existentes sem modificar seu código.
Multicloud
Sua organização pode ter dados espalhados por dois ou mais provedores de nuvem para otimizar custos ou atender às necessidades específicas do seu conjunto de dados. Isso pode criar problemas se os dados forem gerenciados em redes diferentes e com esquemas diferentes de armazenamento de dados.
Uma arquitetura moderna de lakehouse pode gerenciar dados em vários provedores de serviços em nuvem, em vez de estar vinculada a um único sistema em nuvem. Isso permite que sua organização:
- Distribua dados: com dados em diferentes plataformas de nuvem, sua empresa pode encontrar o conjunto de serviços que melhor atende ao seu orçamento ou às suas preocupações com conformidade.
- Aumente a resiliência: os ambientes multicloud melhoram a disponibilidade dos dados distribuindo cargas de trabalho e backups entre vários provedores. Isso pode ser crucial se algum serviço de nuvem sofrer uma interrupção ou tempo de inatividade inesperado.
- Integração de dados: um data warehouse compatível com multicloud também pode integrar dados dessas fontes em tempo real, dando acesso a dados de qualidade e melhores decisões.
- Conformidade: a arquitetura multicloud pode ajudar você a atender a requisitos legais e normativos específicos que podem determinar onde seus dados são armazenados geograficamente ou como são armazenados em vários serviços em nuvem.
Desafios dos data warehouses inteligentes
Os data warehouses inteligentes têm um conjunto diferente de desafios:
- Essa abordagem moderna ainda está evoluindo, então você precisa de uma organização disposta a desenvolver sua estratégia
- Políticas de IA: sua organização deve definir políticas que regem quais pessoas e sistemas devem ser capazes de usar os recursos de IA em um data warehouse inteligente
Quais soluções o Databricks tem para armazenamento de dados?
A Databricks fornece um data warehouse inteligente, o Databricks SQL, que se baseia na arquitetura lakehouse de dados abertos. O Databricks SQL faz parte de uma plataforma integrada, a Data Intelligence Platform, que inclui ML, governança de dados, fluxos de trabalho e muito mais. Ao usar uma base aberta e unificada para todos os seus dados, você obtém ML/AI, streaming, orquestração, ETL e análise em tempo real, armazenamento de dados, segurança unificada, governança e catalogação, bem como armazenamento unificado de dados para confiabilidade e compartilhamento na mesma plataforma. Além disso, como a Databricks Data Intelligence Platform é construída em uma arquitetura de lakehouse de dados abertos, você pode armazenar todos os dados brutos, como logs, textos, áudio, vídeo e imagens.
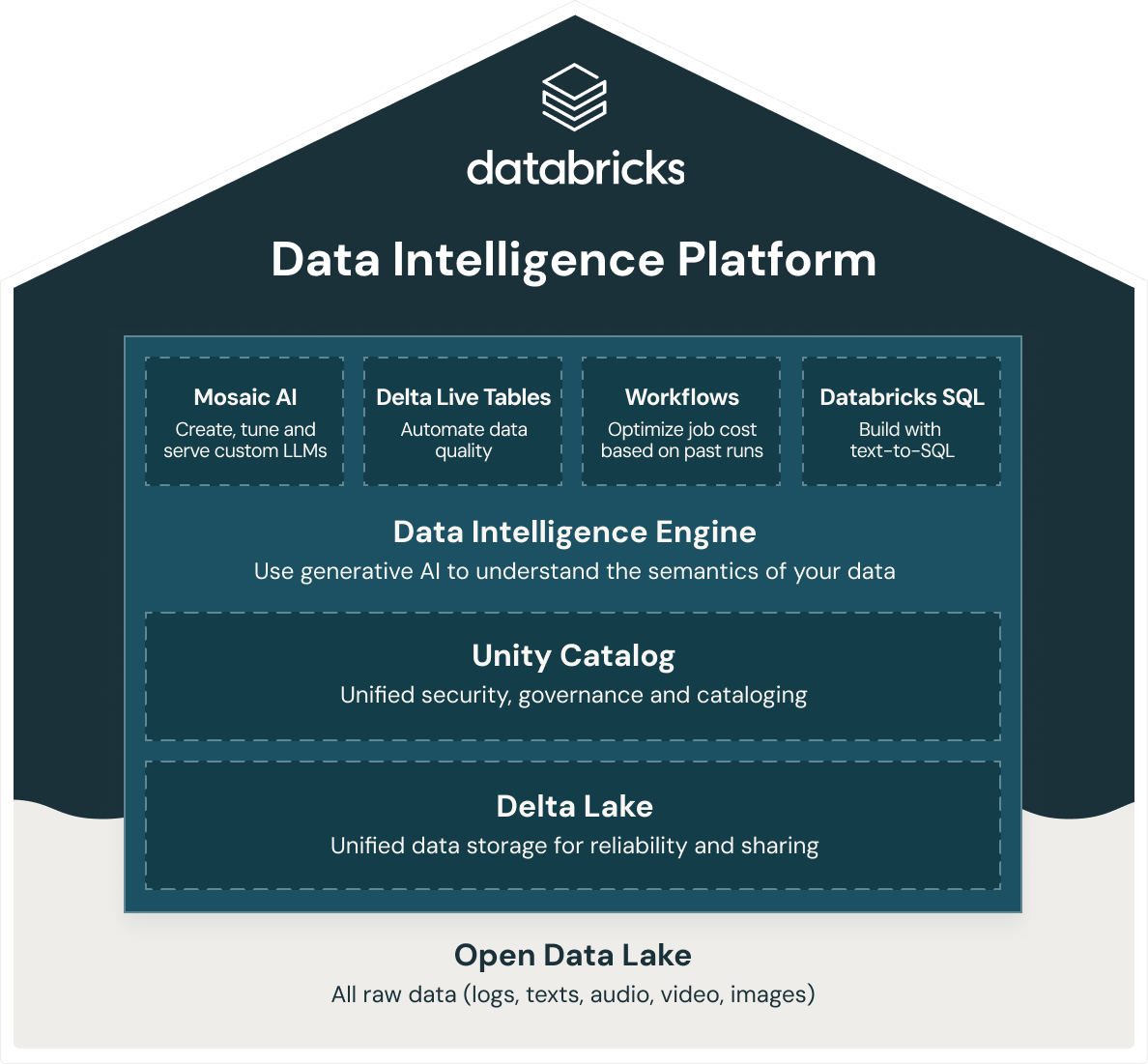
Para construir um lakehouse de sucesso, as organizações recorrem ao Delta Lake, uma camada de governança e gerenciamento de dados em formato aberto e de código aberto que combina o melhor dos data lakes e data warehouses. A Databricks Data Intelligence Platform usa o Delta Lake para oferecer:
- Melhor desempenho global de data warehouse na economia de data lake.
- Serverless SQL compute que elimina a necessidade de gerenciamento de infraestrutura.
- Integração perfeita com a pilha de dados moderna, como dbt, Tableau, Power BI e Fivetran, para ingerir, consultar e transformar dados no local.
- Uma experiência de desenvolvimento SQL de primeira classe para todos os profissionais de dados em sua organização com suporte aos padrões ANSI-SQL.
- Governança refinada com linhagem de dados, tags em nível de tabela/linha, controles de acesso baseados em funções e muito mais.
- Mecanismo de inteligência de dados com tecnologia de IA para entender a semântica de seus dados.