O que é Engenharia de Funcionalidades?
Transformar dados brutos em características informativas para modelos de aprendizado de máquina por meio de técnicas de seleção, extração, construção e transformação.
- A seleção identifica as variáveis mais relevantes a partir dos dados disponíveis, utilizando análise de correlação, informação mútua, eliminação recursiva de características ou conhecimento do domínio, removendo características redundantes, irrelevantes ou ruidosas.
- A extração deriva novas características a partir das existentes por meio de redução de dimensionalidade (PCA, t-SNE), vetorização de texto (TF-IDF, word embeddings) ou aprendizado automático de características (representações de aprendizado profundo).
- A construção cria características projetadas, combinando variáveis por meio de conhecimento do domínio, como proporções, agregações, interações, agrupamento, características polinomiais e características temporais (janelas deslizantes, defasagens), capturando relações complexas.
Engenharia de recursos para machine learning
A engenharia de recursos, também chamada de pré-processamento de dados, é o processo de conversão de dados brutos em recursos que podem ser usados para desenvolver modelos de machine learning. Este tópico descreve os principais conceitos da engenharia de recursos e o papel que desempenha na gestão do ciclo de vida do ML.
Recursos, no contexto do machine learning, são os dados de entrada usados para treinar um modelo. Eles são os atributos de alguma entidade sobre a qual o modelo aprenderá. Os dados brutos normalmente são ser processados antes de ser usados como entrada para um modelo de ML. Uma engenharia de recursos bem feita torna o processo de desenvolvimento de modelos mais eficiente e leva a modelos mais simples, flexíveis e precisos.
O que é engenharia de recursos?
Engenharia de recursos é o processo de transformação e enriquecimento de dados para melhorar o desempenho de algoritmos de machine learning usados para treinar modelos usando esses dados.
A engenharia de recursos inclui etapas como dimensionamento ou normalização de dados, codificação de dados não numéricos (como texto ou imagens), agregação de dados por tempo ou entidade, união de dados de diferentes fontes ou até transferência de conhecimento de outros modelos. O objetivo dessas transformações é aumentar a capacidade dos algoritmos de machine learning de aprender com o conjunto de dados e, assim, fazer previsões mais precisas.
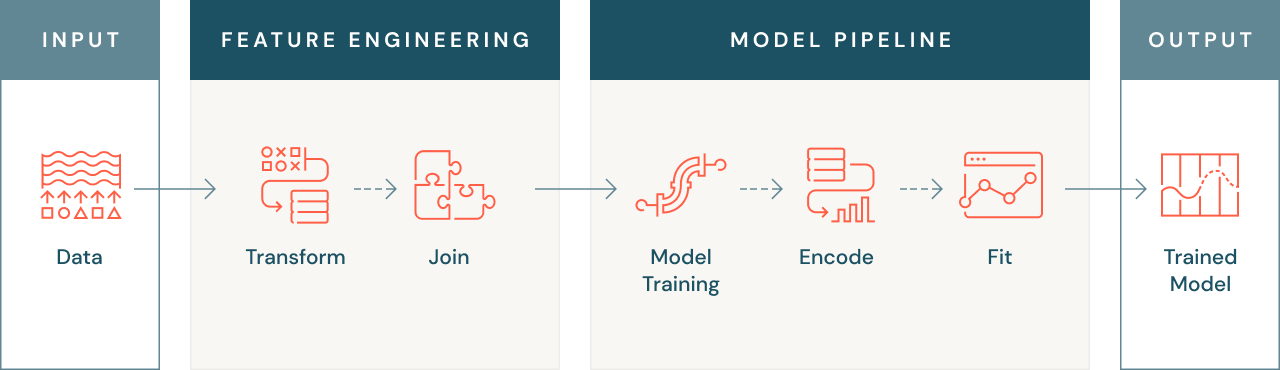
Por que a engenharia de recursos é importante?
A engenharia de recursos é importante por vários motivos. Em primeiro lugar, como mencionado anteriormente, os modelos de machine learning às vezes não podem operar com dados brutos e, portanto, os dados devem ser transformados em uma forma numérica que o modelo possa entender. Isso pode envolver a conversão de dados de texto ou imagem em formato numérico ou a criação de recursos agregados, como valores médios de transações para um cliente.
Às vezes, recursos relevantes para um problema de machine learning podem existir em várias fontes de dados e, por isso, a engenharia de recursos eficaz envolve a união dessas fontes de dados para criar um único conjunto de dados utilizável. Isso permite usar todos os dados disponíveis para treinar seu modelo, o que pode melhorar a precisão e o desempenho.
Outro cenário comum é que o resultado e a aprendizagem de outros modelos podem, às vezes, ser reutilizados na forma de recursos para um novo problema, usando um processo conhecido como aprendizagem de transferência. Isso permite aproveitar o conhecimento adquirido de modelos anteriores para melhorar o desempenho de um novo modelo. A aprendizagem por transferência pode ser particularmente útil ao lidar com conjuntos de dados grandes e complexos, em que é impraticável ensinar um modelo do zero.
A engenharia de recursos eficaz também permite recursos confiáveis no momento da inferência, quando o modelo está sendo usado para fazer previsões sobre novos dados. Isso é importante porque os recursos usados no tempo de inferência devem ser os mesmas usados no momento do treinamento, a fim de evitar "assimetria online/offline", na qual os recursos usados no momento da previsão são calculados de forma diferente daqueles usados para treinamento.
Como a engenharia de recursos é diferente de outras transformações de dados?
O objetivo da engenharia de recursos é criar um conjunto de dados que possa ser treinado para construir um modelo de machine learning. Muitas das ferramentas e técnicas usadas para transformações de dados também são usadas para engenharia de recursos.
Como a ênfase da engenharia de recursos é desenvolver um modelo, há vários requisitos que não estão presentes em todas as transformações de recursos. Por exemplo, você pode usar recursos em vários modelos ou entre equipes na sua organização. Isso requer um método robusto para descobrir recursos.
Além disso, assim que os recursos forem reutilizados, você precisará rastrear onde e como os recursos são computados. Isso é chamado de linhagem de recursos. Cálculos de recursos reproduzíveis são de particular importância para machine learning, uma vez que o recurso não apenas deve ser computado para treinar o modelo, mas também deve ser recalculado exatamente da mesma maneira quando o modelo é usado para inferência.
O manual de IA agêntica para empresas

Quais são os benefícios de uma engenharia de recursos eficaz?
Ter um pipeline de engenharia de recursos eficaz significa ter pipelines de modelagem mais robustos e, por fim, modelos mais confiáveis e de melhor desempenho. Melhorar os recursos usados tanto para treinamento quanto para inferência pode ter um impacto incrível na qualidade do modelo, portanto, recursos melhores significam modelos melhores.
De uma perspectiva diferente, a engenharia de recursos eficaz também incentiva a reutilização, não apenas economizando tempo dos profissionais, mas também melhorando a qualidade de seus modelos. Essa reutilização de recursos é importante por duas razões: economizar tempo e ter recursos robustamente definidos ajuda a evitar que seus modelos usem dados de recursos diferentes entre treinamento e inferência, o que normalmente leva à assimetria "online/offline".
Quais ferramentas são necessárias para a engenharia de recursos?
Geralmente, as mesmas ferramentas usadas para a engenharia de dados podem ser usadas para a engenharia de recursos, pois a maioria das transformações são comuns entre as duas. Isso costuma envolver algum armazenamento de dados e sistema de gerenciamento, acesso a linguagens de transformação aberta padrão (SQL, Python, Spark etc.) e acesso a algum tipo de compute para executar as transformações.
No entanto, é possível implementar algumas ferramentas adicionais para engenharia de recursos na forma de bibliotecas específicas do Python que podem ajudar com transformações de dados específicas de machine learning — como incorporar texto ou imagens, ou variáveis categóricas de codificação de um único ativo. Há também alguns projetos de código aberto que ajudam no rastreamento de recursos que um modelo utiliza.
O controle de versões é uma ferramenta importante para a engenharia de recursos, pois os modelos muitas vezes podem ser treinados em um conjunto de dados que já foi modificado. Ter um controle de versões adequado permite reproduzir um determinado modelo, enquanto seus dados evoluem naturalmente ao longo do tempo.
O que é uma Feature Store?
Feature Store é uma ferramenta projetada para enfrentar os desafios da engenharia de recursos. Uma Feature Store é um repositório centralizado de recursos em uma organização. Os data scientists podem usar uma Feature Store para descobrir e compartilhar recursos e rastrear a linhagem de recursos. Ela também garante que os mesmos valores do recurso sejam usados em momentos de treinamento e inferência. Esses cálculos de recursos reproduzíveis são de particular importância para machine learning, uma vez que o recurso não apenas deve ser computado para treinar o modelo, mas também deve ser recalculado exatamente da mesma maneira quando o modelo é usado para inferência.
Por que usar o Databricks Feature Store?
A Databricks Feature Store está totalmente integrada com outros componentes da Databricks. Você pode usar os notebooks da Databricks para desenvolver código para criar recursos e construir modelos com base nesses recursos. Quando você disponibiliza modelos com a Databricks, o modelo consulta automaticamente os valores dos recursos na Feature Store para inferência. A Databricks Feature Store também oferece os benefícios das Feature Stores descritas neste artigo:
- Possibilidade de descoberta. A UI da Feature Store, acessível a partir do workspace da Databricks, permite navegar e pesquisar recursos existentes.
- Linhagem. Quando você cria uma tabela de recursos com a Databricks Feature Store, as fontes de dados usadas para criar a tabela de recursos são salvas e ficam acessíveis. Para cada recurso em uma tabela de recursos, você também pode acessar os modelos, notebooks, jobs e endpoints que usam o recurso.
Além disso, o Databricks Feature Store fornece:
- Integração com classificação e disponibilização de modelos. Quando você usa recursos da Databricks Feature Store para treinar um modelo, o modelo é empacotado com metadados de recursos. Quando você usa o modelo para classificação em lote ou inferência online, ele recupera automaticamente os recursos da Databricks Feature Store. O chamador não precisa saber sobre eles nem incluir lógica para pesquisar ou unir recursos para obter novos dados. Isso facilita muito a implantação e as atualizações do modelo.
- Pesquisas pontuais. O Databricks Feature Store é compatível com séries temporais e casos de uso baseados em eventos que exigem correção pontual.
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.