O que é um Hadoop Distributed File System (HDFS)?
Armazenamento distribuído que divide arquivos em blocos replicados entre nós do cluster, fornecendo tolerância a falhas, capacidade escalável e acesso de alto rendimento
- O Hadoop Distributed File System (HDFS) é um sistema de armazenamento que divide arquivos em blocos e os distribui por várias máquinas para escalabilidade e tolerância a falhas.
- O HDFS foi projetado para armazenar conjuntos de dados muito grandes em clusters de hardware comum e manter os dados disponíveis mesmo quando nós individuais falham.
- Embora muitas organizações agora usem armazenamento de objetos na nuvem com arquiteturas lakehouse, entender o HDFS ajuda a explicar a base dos primeiros sistemas de big data.
HDFS
O HDFS (Hadoop Distributed File System) é o principal sistema de armazenamento usado por aplicações Hadoop. Este framework de código aberto funciona transferindo rapidamente dados entre nós. É frequentemente usado por empresas que precisam lidar e armazenar big data. O HDFS é um componente chave de muitos sistemas Hadoop, pois fornece um meio para gerenciar big data, além de suportar análises de big data.
Existem muitas empresas em todo o mundo que usam HDFS, então o que exatamente é e por que é necessário? Vamos mergulhar fundo no que é HDFS e por que ele pode ser útil para empresas.
O que é HDFS?
HDFS significa Hadoop Distributed File System. O HDFS opera como um sistema de arquivos distribuído projetado para rodar em hardware comum.
O HDFS é tolerante a falhas e projetado para ser implantado em hardware comum e de baixo custo. O HDFS fornece acesso a dados de alto rendimento aos dados da aplicação e é adequado para aplicações que possuem grandes conjuntos de dados e permite acesso via streaming aos dados do sistema de arquivos em Apache Hadoop.
Então, o que é Hadoop? E como ele difere do HDFS? Uma diferença central entre Hadoop e HDFS é que Hadoop é o framework de código aberto que pode armazenar, processar e analisar dados, enquanto HDFS é o sistema de arquivos do Hadoop que fornece acesso aos dados. Isso essencialmente significa que HDFS é um módulo do Hadoop.
Vamos dar uma olhada na arquitetura do HDFS:
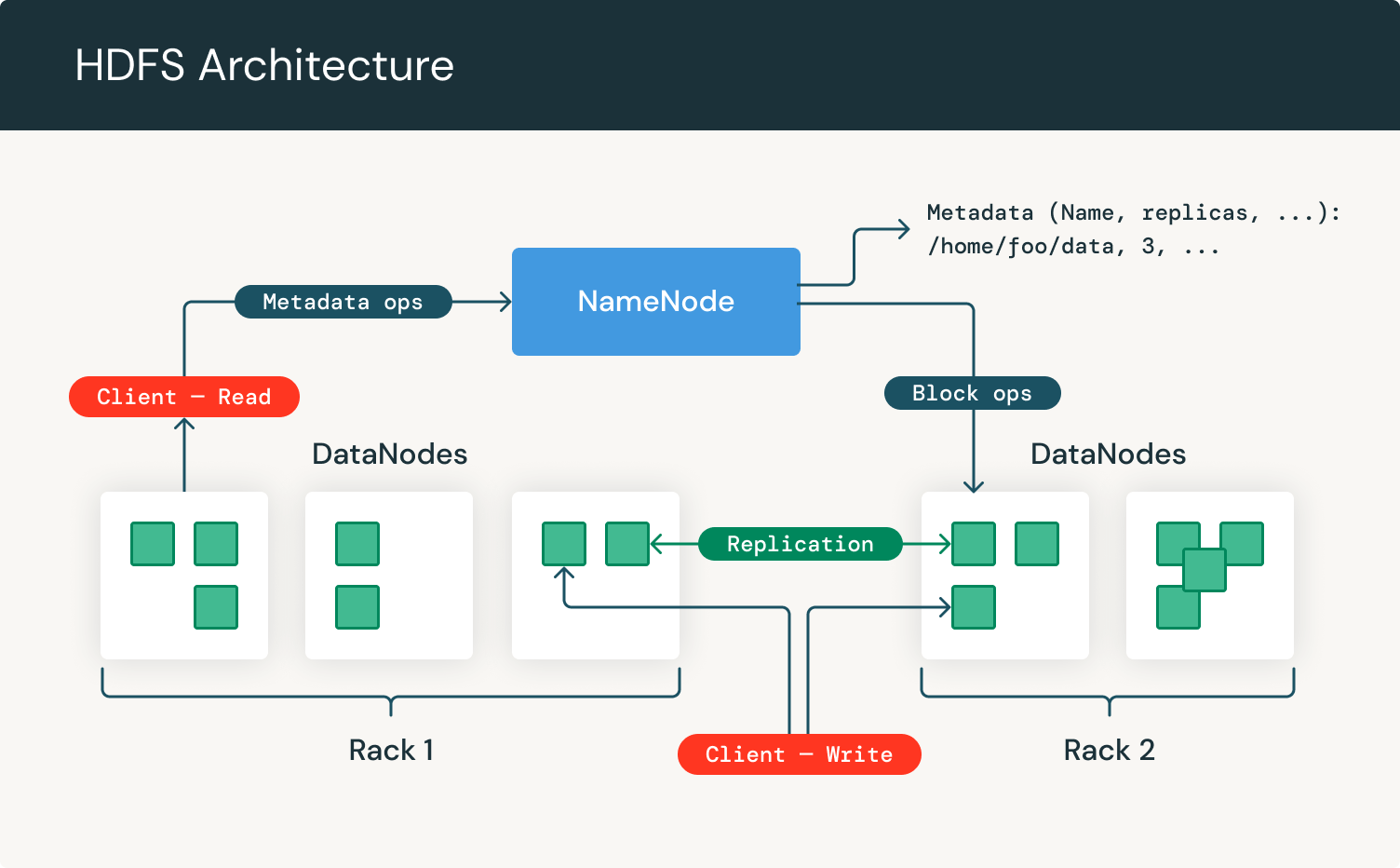
Como podemos ver, ele se concentra em NameNodes e DataNodes. O NameNode é o hardware que contém o sistema operacional GNU/Linux e o software. O sistema de arquivos distribuído Hadoop atua como o servidor mestre e pode gerenciar os arquivos, controlar o acesso de um cliente aos arquivos e supervisionar processos de operação de arquivos, como renomear, abrir e fechar arquivos.
Um DataNode é um hardware que possui o sistema operacional GNU/Linux e o software DataNode. Para cada nó em um cluster HDFS, você encontrará um DataNode. Esses nós ajudam a controlar o armazenamento de dados de seu sistema, pois podem executar operações nos sistemas de arquivos se o cliente solicitar, e também criar, replicar e bloquear arquivos quando o NameNode instruir.
O significado e o propósito do HDFS são atingir os seguintes objetivos:
- Gerenciar grandes conjuntos de dados - Organizar e armazenar conjuntos de dados pode ser uma tarefa difícil de lidar. O HDFS é usado para gerenciar as aplicações que precisam lidar com enormes conjuntos de dados. Para fazer isso, o HDFS deve ter centenas de nós por cluster.
- Detectar falhas - O HDFS deve ter tecnologia implementada para escanear e detectar falhas de forma rápida e eficaz, pois inclui um grande número de hardware comum. A falha de componentes é um problema comum.
- Eficiência de hardware - Quando grandes conjuntos de dados estão envolvidos, pode reduzir o tráfego de rede e aumentar a velocidade de processamento.
A história do HDFS
Quais são as origens do Hadoop? O design do HDFS foi baseado no Google File System. Foi originalmente construído como infraestrutura para o projeto de mecanismo de busca da web Apache Nutch, mas desde então se tornou um membro do Ecossistema Hadoop.
Nos primeiros anos da internet, os web crawlers começaram a surgir como uma forma de as pessoas pesquisarem informações em páginas da web. Isso criou vários mecanismos de busca, como Yahoo e Google.
Também criou outro mecanismo de busca chamado Nutch, que queria distribuir dados e cálculos entre vários computadores simultaneamente. Nutch então mudou para o Yahoo e foi dividido em dois. Apache Spark e Hadoop agora são suas próprias entidades separadas. Onde o Hadoop foi projetado para lidar com processamento em lote, o Spark foi feito para lidar com dados em tempo real de forma eficiente.
Hoje em dia, a estrutura e o framework do Hadoop são gerenciados pela Apache Software Foundation, que é uma comunidade global de desenvolvedores de software e contribuidores.
O HDFS nasceu disso e foi projetado para substituir as soluções de armazenamento de hardware por um método melhor e mais eficiente - um sistema de arquivos virtual. Quando surgiu, o MapReduce era o único mecanismo de processamento distribuído que podia usar HDFS. Mais recentemente, componentes alternativos de serviços de dados Hadoop, como HBase e Solr, também utilizam HDFS para armazenar dados.
O que é HDFS no mundo do big data?
Então, o que é big data e como o HDFS entra nisso? O termo "big data" refere-se a todos os dados que são difíceis de armazenar, processar e analisar. Big data HDFS são dados organizados no sistema de arquivos HDFS.
Como agora sabemos, Hadoop é um framework que funciona usando processamento paralelo e armazenamento distribuído. Isso pode ser usado para classificar e armazenar big data, pois não pode ser armazenado de maneiras tradicionais.
Na verdade, é o software mais comumente usado para lidar com big data, e é usado por empresas como Netflix, Expedia e British Airways, que têm um relacionamento positivo com o Hadoop para armazenamento de dados. O HDFS em big data é vital, pois é assim que muitas empresas agora escolhem armazenar seus dados.
Existem cinco elementos centrais de big data organizados pelos serviços HDFS:
- Velocidade - Quão rápido os dados são gerados, coletados e analisados.
- Volume - A quantidade de dados gerados.
- Variedade - O tipo de dados, que pode ser estruturado, não estruturado, etc.
- Veracidade - A qualidade e precisão dos dados.
- Valor - Como você pode usar esses dados para obter insights em seus processos de negócios.
Vantagens do Hadoop Distributed File System
Como um subprojeto de código aberto dentro do Hadoop, o HDFS oferece cinco benefícios centrais ao lidar com big data:
- Tolerância a falhas. O HDFS foi projetado para detectar falhas e se recuperar automaticamente rapidamente, garantindo continuidade e confiabilidade.
- Velocidade, devido à sua arquitetura de cluster, ele pode manter 2 GB de dados por segundo.
- Acesso a mais tipos de dados, especificamente dados de streaming. Devido ao seu design para lidar com grandes quantidades de dados para processamento em lote, ele permite altas taxas de transferência de dados, tornando-o ideal para suportar dados de streaming.
Compatibilidade e portabilidade. O HDFS foi projetado para ser portátil em uma variedade de configurações de hardware e compatível com vários sistemas operacionais subjacentes, fornecendo aos usuários a opção de usar o HDFS com sua própria configuração personalizada. Essas vantagens são especialmente significativas ao lidar com big data e foram possíveis com a maneira particular como o HDFS lida com os dados.
Este gráfico demonstra a diferença entre um sistema de arquivos local e o HDFS.
- Escalável. Você pode dimensionar recursos de acordo com o tamanho do seu sistema de arquivos. O HDFS inclui mecanismos de escalabilidade vertical e horizontal.
- Localidade de dados. Quando se trata do sistema de arquivos Hadoop, os dados residem em data nodes, em vez de os dados se moverem para onde a unidade computacional está. Ao encurtar a distância entre os dados e o processo de computação, ele diminui o congestionamento da rede e torna o sistema mais eficaz e eficiente.
- Custo-benefício. Inicialmente, quando pensamos em dados, podemos pensar em hardware caro e largura de banda consumida. Quando a falha de hardware ocorre, pode ser muito caro para corrigir. Com o HDFS, os dados são armazenados de forma barata, pois são virtuais, o que pode reduzir drasticamente os custos de armazenamento de metadados do sistema de arquivos e dados do namespace do sistema de arquivos. Além disso, como o HDFS é de código aberto, as empresas não precisam se preocupar em pagar uma taxa de licenciamento.
- Armazena grandes quantidades de dados. O armazenamento de dados é o que o HDFS representa - significando dados de todas as variedades e tamanhos - mas particularmente grandes quantidades de dados de corporações que estão lutando para armazená-los. Isso inclui dados estruturados e não estruturados.
- Flexível. Ao contrário de alguns outros bancos de dados de armazenamento mais tradicionais, não há necessidade de processar os dados coletados antes de armazená-los. Você pode armazenar o quanto quiser, com a oportunidade de decidir exatamente o que deseja fazer com eles e como usá-los mais tarde. Isso também inclui dados não estruturados como textos, vídeos e imagens.
Como usar HDFS
Então, como você usa o HDFS? Bem, o HDFS funciona com um NameNode principal e vários outros datanodes, todos em um cluster de hardware comum. Esses nós são organizados no mesmo local dentro do data center. Em seguida, ele é dividido em blocos que são distribuídos entre os vários DataNodes para armazenamento. Para reduzir as chances de perda de dados, os blocos são frequentemente replicados entre os nós. É um sistema de backup caso os dados sejam perdidos.
Vamos analisar os NameNodes. O NameNode é o nó dentro do cluster que sabe o que os dados contêm, a qual bloco pertencem, o tamanho do bloco e para onde devem ir. Os NameNodes também são usados para controlar o acesso aos arquivos, incluindo quando alguém pode escrever, ler, criar, remover e replicar dados entre os vários DataNodes.
O cluster também pode ser adaptado em tempo real, conforme necessário, dependendo da capacidade do servidor - o que pode ser útil quando há um aumento repentino de dados. Os nós podem ser adicionados ou removidos quando necessário.
Agora, vamos aos DataNodes. Os DataNodes estão em comunicação constante com os NameNodes para identificar se precisam iniciar e concluir uma tarefa. Esse fluxo de colaboração consistente significa que o NameNode está ciente do status de cada DataNode.
Quando um DataNode é identificado como não operando como deveria, o NameNode é capaz de reatribuir automaticamente essa tarefa para outro nó em funcionamento no mesmo datablock. Da mesma forma, os DataNodes também são capazes de se comunicar entre si, o que significa que eles podem colaborar durante operações de arquivo padrão. Como o NameNode está ciente dos DataNodes e de seu desempenho, eles são cruciais para a manutenção do sistema.
Os Datablocks são replicados em vários DataNodes e acessados pelo NameNode.
Para usar o HDFS, você precisa instalar e configurar um cluster Hadoop. Isso pode ser uma configuração de nó único, mais adequada para usuários iniciantes, ou uma configuração de cluster para clusters grandes e distribuídos. Em seguida, você precisa se familiarizar com os comandos HDFS, como os abaixo, para operar e gerenciar seu sistema.
| Comando | Descrição |
| -rm | Remove arquivo ou diretório |
| -ls | Lista arquivos com permissões e outros detalhes |
| -mkdir | Cria um diretório chamado path no HDFS |
| -cat | Mostra o conteúdo do arquivo |
| -rmdir | Exclui um diretório |
| -put | Envia um arquivo ou pasta de um disco local para o HDFS |
| -rmr | Exclui o arquivo identificado por path ou pasta e subpastas |
| -get | Move arquivo ou pasta do HDFS para o arquivo local |
| -count | Conta o número de arquivos, o número de diretórios e o tamanho do arquivo |
| -df | Mostra espaço livre |
| -getmerge | Mescla vários arquivos no HDFS |
| -chmod | Altera permissões de arquivo |
| -copyToLocal | Copia arquivos para o sistema local |
| -Stat | Exibe estatísticas sobre o arquivo ou diretório |
| -head | Exibe o primeiro kilobyte de um arquivo |
| -usage | Retorna a ajuda para um comando individual |
| -chown | Aloca um novo proprietário e grupo de um arquivo |
Como o HDFS funciona?
Como mencionado anteriormente, o HDFS usa NameNodes e DataNodes. O HDFS permite a transferência rápida de dados entre nós de computação. Quando o HDFS recebe dados, ele é capaz de quebrar as informações em blocos, distribuindo-os para diferentes nós em um cluster.
Os dados são divididos em blocos e distribuídos entre os DataNodes para armazenamento; esses blocos também podem ser replicados entre nós, o que permite o processamento paralelo eficiente. Você pode acessar, mover e visualizar dados por meio de vários comandos. Opções do HDFS DFS, como "-get" e "-put", permitem que você recupere e mova dados conforme necessário.
Além disso, o HDFS foi projetado para ser altamente responsivo e pode detectar falhas rapidamente. O sistema de arquivos usa replicação de dados para garantir que cada pedaço de dado seja salvo várias vezes e, em seguida, o distribui entre nós individuais, garantindo que pelo menos uma cópia esteja em um rack diferente das outras cópias.
Isso significa que, quando um DataNode não está mais enviando sinais para o NameNode, ele o remove do cluster e opera sem ele. Se esse DataNode retornar, ele poderá ser alocado para um novo cluster. Além disso, como os datablocks são replicados em vários DataNodes, a remoção de um não levará a nenhuma corrupção de arquivo de qualquer tipo.
Componentes do HDFS
É importante saber que existem três componentes principais do Hadoop. Hadoop HDFS, Hadoop MapReduce e Hadoop YARN. Vamos dar uma olhada no que esses componentes trazem para o Hadoop:
- Hadoop HDFS - Hadoop Distributed File System (HDFS) é a unidade de armazenamento do Hadoop.
- Hadoop MapReduce - Hadoop MapReduce é a unidade de processamento do Hadoop. Este framework de software é usado para escrever aplicativos para processar grandes quantidades de dados.
- Hadoop YARN - Hadoop YARN é um componente de gerenciamento de recursos do Hadoop. Ele processa e executa dados para processamento em lote, streaming, interativo e gráfico - todos armazenados no HDFS.
Como criar um sistema de arquivos HDFS
Quer saber como criar um sistema de arquivos HDFS? Siga as etapas abaixo que o guiarão sobre como criar o sistema, editá-lo e removê-lo, se necessário.
Listando seu HDFS
Sua listagem HDFS deve ser /user/seuNomeDeUsuário. Para visualizar o conteúdo do seu diretório inicial do HDFS, digite:
Como você está apenas começando, não conseguirá ver nada neste estágio. Quando quiser ver o conteúdo de um diretório não vazio, insira:
Você poderá ver os nomes dos diretórios iniciais de todos os outros usuários do Hadoop.
Criando um diretório no HDFS
Agora você pode criar um diretório de teste, vamos chamá-lo de testHDFS. Ele aparecerá dentro do seu HDFS. Basta digitar o comando abaixo:
Agora você deve verificar se o diretório existe usando o comando que você digitou ao listar seu HDFS. Você deverá ver o diretório testHDFS listado.
Verifique novamente usando o caminho completo do HDFS para o seu HDFS. Digite:
Verifique novamente se isso está funcionando antes de seguir para os próximos passos.
Copiando um arquivo
Para copiar um arquivo do seu sistema de arquivos local para o HDFS, comece criando um arquivo que você deseja copiar. Para fazer isso, digite:
Isso criará um novo arquivo chamado testFile, incluindo os caracteres HDFS test file. Para verificar isso, digite:
ls
E então, para verificar se o arquivo foi criado, digite:
Em seguida, você precisará copiar o arquivo para o HDFS. Para copiar arquivos do Linux para o HDFS, você precisa usar:
Observe que você precisa usar o comando "-copyFromLocal" porque o comando "-cp" é usado para copiar arquivos dentro do HDFS.
Agora você só precisa confirmar se o arquivo foi copiado corretamente. Faça isso digitando o seguinte:
Movendo e copiando arquivos
Ao copiar o testfile, ele foi colocado no diretório inicial base. Agora você pode movê-lo para o diretório testHDFS que você já criou. Use o seguinte:
A primeira parte moveu seu testFile do diretório inicial do HDFS para o diretório de teste que você criou. A segunda parte deste comando mostra que ele não está mais no diretório inicial do HDFS, e a terceira parte confirma que ele foi movido para o diretório test HDFS.
Para copiar um arquivo, digite:
Verificando o uso do disco
Verificar o espaço em disco é útil ao usar o HDFS. Para fazer isso, você pode digitar o seguinte comando:
Isso permitirá que você veja quanto espaço está usando em seu HDFS. Você também pode ver quanto espaço está disponível no HDFS em todo o cluster digitando:
Removendo um arquivo/diretório
Pode haver um momento em que você precise excluir um arquivo ou diretório no HDFS. Isso pode ser feito com o comando:
Você verá que ainda tem o diretório testHDFS e o testFile2 que você criou. Remova o diretório digitando:
Ele exibirá uma mensagem de erro - mas não se preocupe. Ela dirá algo como "rmdir: testhdfs: Directory is not empty". O diretório precisa estar vazio antes de poder ser excluído. Você pode usar o comando "rm" para ignorar isso e remover um diretório, incluindo todos os arquivos que ele contém. Digite:
O manual de IA agêntica para empresas

Como instalar o HDFS
Para instalar o Hadoop, você precisa lembrar que existe o nó único (singlenode) e o multinode. Dependendo do que você precisa, você pode usar um cluster de nó único ou multinodo.
Um cluster de nó único significa que apenas um DataNode está em execução. Ele incluirá o NameNode, DataNode, gerenciador de recursos e gerenciador de nós em uma única máquina.
Para algumas indústrias, isso é tudo que é necessário. Por exemplo, na área médica, se você estiver conduzindo estudos e precisar coletar, classificar e processar dados em sequência, você pode usar um cluster de nó único. Isso pode lidar facilmente com os dados em menor escala, em comparação com dados distribuídos em muitas centenas de máquinas. Para instalar um cluster de nó único, siga estas etapas:
- Baixe o Pacote Java 8. Salve este arquivo em seu diretório pessoal.
- Extraia o Arquivo Tar do Java.
- Baixe o Pacote Hadoop 2.7.3.
- Extraia o Arquivo Tar do Hadoop.
- Adicione os caminhos do Hadoop e do Java no arquivo bash (.bashrc).
- Edite os arquivos de configuração do Hadoop.
- Abra o core-site.xml e edite a propriedade.
- Edite o hdfs-site.xml e edite a propriedade.
- Edite o arquivo mapred-site.xml e edite a propriedade.
- Edite o yarn-site.xml e edite a propriedade.
- Edite o hadoop-env.sh e adicione o caminho do Java.
- Vá para o diretório home do Hadoop e formate o NameNode.
- Vá para o diretório hadoop-2.7.3/sbin e inicie todos os daemons.
- Verifique se todos os serviços do Hadoop estão em execução.
E aí está, você agora deve ter um HDFS instalado com sucesso.
Como acessar arquivos HDFS
Não será surpresa que a segurança é rigorosa quando se trata de HDFS, dado que estamos lidando com dados. Como o HDFS é tecnicamente um armazenamento virtual, ele abrange todo o cluster, então você só pode ver os metadados em seu sistema de arquivos, você não poderá visualizar os dados específicos reais.
Para acessar arquivos HDFS, você pode baixar o arquivo "jar" do HDFS para o seu sistema de arquivos local. Você também pode acessar o HDFS usando sua interface de usuário web. Simplesmente abra seu navegador e digite "localhost:50070" na barra de pesquisa. A partir daí, você pode ver a interface de usuário web do HDFS e ir para a aba de utilitários no lado direito. Em seguida, clique em "navegar no sistema de arquivos", isso mostra uma lista completa de arquivos localizados em seu HDFS.
Exemplos de HDFS DFS
Aqui estão alguns dos exemplos de comandos Hadoop mais comuns.
Exemplo A
Para excluir um diretório, você precisa aplicar o seguinte (observação: isso só pode ser feito se os arquivos estiverem vazios):
Ou
Exemplo B
Quando você tem vários arquivos em um HDFS, você pode usar um comando "-getmerge". Isso mesclará vários arquivos em um único arquivo, que você poderá então baixar para o seu sistema de arquivos local. Você pode fazer isso com o seguinte:
Ou
Exemplo C
Quando você deseja carregar um arquivo do HDFS para o local, você pode usar o comando "-put". Você especifica de onde copiar e qual arquivo copiar para o HDFS. Use o abaixo:
Ou
Exemplo D
O comando count é usado para rastrear o número de diretórios, arquivos e o tamanho do arquivo no HDFS. Você pode usar o seguinte:
Ou
Exemplo E
O comando "chown" pode ser usado para alterar o proprietário e o grupo de um arquivo. Para ativar isso, use o abaixo:
Ou
O que é armazenamento HDFS?
Como agora sabemos, os dados do HDFS são armazenados em algo chamado blocos. Esses blocos são a menor unidade de dados que o sistema de arquivos pode armazenar. Os arquivos são processados e divididos nesses blocos, que são então distribuídos pelo cluster - e também replicados para segurança. Normalmente, cada bloco pode ser replicado três vezes. Este diagrama mostra big data e como ele pode ser armazenado com HDFS.
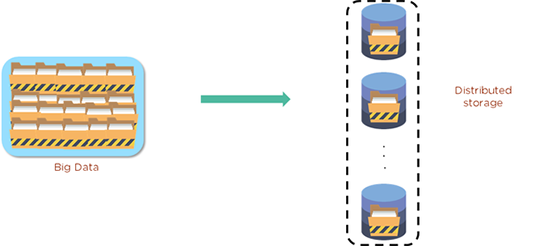
O primeiro você encontrará no DataNode, o segundo é armazenado em um DataNode separado dentro do cluster, e um terceiro é armazenado em um DataNode em um cluster diferente. Isso é como uma etapa de segurança de proteção tripla. Assim, se o pior acontecer e uma réplica falhar, os dados não serão perdidos para sempre.
O NameNode mantém informações importantes, como o número de blocos e onde as réplicas são armazenadas. Em comparação, um DataNode está armazenando os dados reais e pode criar blocos, remover blocos e replicar blocos sob comando. Parece isto:
Isso determina onde os DataNodes devem armazenar seus blocos.
Como o HDFS armazena dados?
O sistema de arquivos HDFS consiste em um conjunto de serviços Master (NameNode, secondary NameNode e DataNodes). O NameNode e o secondary NameNode gerenciam os metadados do HDFS. Os DataNodes hospedam os dados subjacentes do HDFS.
O NameNode rastreia quais DataNodes contêm o conteúdo de um determinado arquivo no HDFS. O HDFS divide os arquivos em blocos e armazena cada bloco em um DataNode. Vários DataNodes são ligados ao cluster. O NameNode, então, distribui réplicas desses blocos de dados pelo cluster. Ele também instrui o usuário ou aplicativo onde localizar as informações desejadas.
Para que o sistema de arquivos distribuído Hadoop (HDFS) foi projetado?
Simplificando, ao perguntar "para que o sistema de arquivos distribuído Hadoop foi projetado?", a resposta é, antes de tudo, big data. Isso pode ser inestimável para grandes corporações que, de outra forma, teriam dificuldade em gerenciar e armazenar dados de seus negócios e clientes.
Com o Hadoop, você pode armazenar e unificar dados, sejam eles transacionais, científicos, de mídias sociais, de publicidade e de machine learning. Isso também significa que você pode retornar a esses dados e obter insights valiosos sobre o desempenho e a análise de negócios.
Como foi projetado para armazenar dados, o HDFS também pode lidar com dados brutos que são comumente usados por cientistas ou pessoas da área médica que buscam analisar tais dados. Estes são chamados de data lakes. Isso permite que eles combatam questões mais difíceis sem restrições.
Além disso, como o Hadoop foi projetado principalmente para lidar com volumes enormes de dados de várias maneiras, ele também pode ser usado para executar algoritmos para fins analíticos. Isso significa que ajuda as empresas a processar e analisar dados de forma mais eficiente, permitindo-lhes descobrir novas tendências e anomalias. Certos conjuntos de dados estão até sendo removidos de data warehouses e movidos para o Hadoop. Isso apenas facilita o armazenamento de tudo em um local de fácil acesso.
Quando se trata de dados transacionais, o Hadoop também está equipado para lidar com milhões de transações. Graças às suas capacidades de armazenamento e processamento, ele pode ser usado para armazenar e analisar dados de clientes. Você também pode mergulhar nos dados para descobrir tendências e padrões emergentes para ajudar com os objetivos de negócios. Não se esqueça, o Hadoop está constantemente sendo atualizado com novos dados, e você pode comparar dados novos e antigos para ver o que mudou e por quê.
Considerações sobre HDFS
Por padrão, o HDFS é configurado com replicação 3x, o que significa que os conjuntos de dados terão duas cópias adicionais. Embora isso melhore a probabilidade de dados localizados durante o processamento, introduz custos de armazenamento adicionais.
- O HDFS funciona melhor quando configurado com armazenamento conectado localmente. Isso garante o melhor desempenho para o sistema de arquivos.
- Aumentar a capacidade do HDFS requer a adição de novos servidores (computação, memória, disco), não apenas mídia de armazenamento.
HDFS vs. Armazenamento de Objetos na Nuvem
Como mencionado acima, a capacidade do HDFS está intimamente ligada aos recursos de computação. Aumentar a capacidade de armazenamento implica aumentar os recursos de CPU, mesmo que este último não seja necessário. Ao adicionar mais nós de dados ao HDFS, uma operação de rebalanceamento é necessária para distribuir os dados existentes para os servidores recém-adicionados.
Essa operação pode levar algum tempo. Dimensionar um cluster Hadoop em um ambiente on-premises também pode ser difícil em termos de custo e espaço. O HDFS usa armazenamento conectado localmente, o que pode fornecer benefícios de desempenho de IO, assumindo que o YARN possa provisionar o processamento nos servidores que armazenam os dados a serem processados.
Com ambientes altamente utilizados, é possível que a maioria das operações de leitura/escrita de dados ocorra pela rede em vez de localmente. O armazenamento de objetos na nuvem inclui tecnologias como Azure Data Lake Storage, AWS S3 ou Google Cloud Storage. Ele é independente dos recursos de computação que o acessam e, portanto, os clientes podem armazenar uma quantidade muito maior de dados na nuvem.
Clientes que desejam armazenar Petabytes de dados podem fazer isso facilmente em armazenamento de objetos na nuvem. No entanto, todas as operações de leitura e gravação contra o armazenamento em nuvem ocorrerão pela rede. Portanto, é importante que os aplicativos que acessarão seus dados aproveitem o cache sempre que possível ou incluam lógica para minimizar as operações de IO.
Recursos Adicionais
- Guia de migração do Hadoop para o Lakehouse
- Central de migração
- Ebook de Modernização na Nuvem: Um guia de negócios sobre o valor oculto da migração do Hadoop
- Demonstrações rápidas sob demanda da Plataforma Databricks Lakehouse
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.