Polares vs Pandas
Compare o processamento paralelo de alto desempenho do Polars com a API versátil do Pandas para manipulação de dados baseada em DataFrames.
- Compreenda as diferenças entre Polars e Pandas para operações com DataFrames e fluxos de trabalho de análise de dados.
- Aprenda como o Polars utiliza processamento paralelo baseado em Rust e avaliação preguiçosa para obter desempenho superior em grandes conjuntos de dados.
- Descubra quando escolher o amplo ecossistema e a flexibilidade do Pandas em vez da velocidade e eficiência de memória do Polars.
Introdução: Compreendendo as Opções da Biblioteca DataFrame
DataFrames são estruturas de dados bidimensionais, geralmente tabelas semelhantes a planilhas, que permitem armazenar e manipular dados tabulares em linhas de observações e colunas de variáveis, além de extrair informações valiosas de um determinado dataset. Bibliotecas de DataFrame são conjuntos de ferramentas de software que fornecem uma estrutura no estilo de planilha para trabalhar com dados em código. Elas são um componente essencial de uma plataforma de análise de dados porque oferecem a abstração central que torna os dados fáceis de carregar, manipular, analisar e compreender, fazendo a ponte entre o armazenamento bruto de dados e ferramentas de nível mais alto de analítica, machine learning e visualização.
Polars e Pandas são as principais bibliotecas de DataFrame em Python para análise e manipulação de dados, mas são otimizadas para casos de uso e escalas de trabalho diferentes.
Pandas é uma biblioteca de código aberto escrita para a linguagem de programação Python que fornece estruturas de dados rápidas e adaptáveis e ferramentas de análise de dados. É a biblioteca de DataFrame mais usada em Python. Trata-se de uma biblioteca madura, rica em recursos e com um ecossistema extenso, com muitas integrações. O Pandas conta com documentação ampla, forte suporte da comunidade e bibliotecas de visualização consolidadas. É amplamente utilizado para datasets pequenos a médios e para análises exploratórias.
Polars é uma biblioteca de DataFrame colunar, rápida e baseada em Rust, com uma API em Python. Ela foi projetada para desempenho, com paralelismo integrado e execução “lazy” (não executada imediatamente), o que a torna adequada para cargas de trabalho maiores do que a memória disponível.
Dependendo dos seus requisitos de processamento de dados, o Pandas funciona bem para ciência de dados em datasets de até alguns milhões de linhas. Se você estiver fazendo ETL, analítica ou trabalhando com tabelas grandes, o Polars geralmente é mais eficiente.
Quando usar Pandas no seu fluxo de trabalho
O Pandas se destaca quando flexibilidade, velocidade de iteração e compatibilidade com o ecossistema são mais importantes do que escala extrema. Ele é o padrão de fato para bibliotecas de DataFrame. O Pandas prioriza flexibilidade e oferece integrações profundas com scikit-learn, NumPy, Matplotlib, statsmodels e diversas ferramentas de machine learning.
Ele funciona bem com bases de código legadas e é familiar para equipes de processamento de dados que o utilizam para análises interativas e trabalho exploratório, nos quais a flexibilidade é essencial. Seu formato orientado a linhas é especialmente eficaz para datasets pequenos a médios, análises ad hoc, fluxos de trabalho baseados em notebooks e prototipagem rápida.
Com Pandas, é possível executar qualquer função Python, enquanto o Polars desencoraja fortemente a execução arbitrária de código Python. No Pandas, alterações in-place e edições passo a passo são comuns, permitindo que os usuários modifiquem o estado ao longo do tempo. No Polars, os DataFrames são efetivamente imutáveis.
Você pode executar a API do Pandas no Apache Spark 3.2. Isso permite distribuir uniformemente as cargas de trabalho do Pandas, garantindo que tudo seja feito da maneira certa.
Para análise exploratória de dados, o Pandas oferece operações rápidas e interativas, facilidade para recortar, filtrar e agrupar dados, além de inspeções visuais rápidas. Ele é frequentemente usado para validação e auditoria de dados, bem como para limpeza de dados brutos, tratando valores ausentes, formatos inconsistentes, duplicatas ou tipos de dados mistos.
Em analítica de negócios e relatórios, quando equipes de dados precisam gerar métricas em uma escala de tempo definida, o Pandas simplifica operações de groupby e agregação, facilita o reshaping dos dados e permite exportar resultados diretamente para CSV ou Excel.
Quando equipes de ciência de dados preparam dados para modelos de ML, o Pandas facilita a experimentação com criação natural de recursos baseados em colunas e integração estreita com scikit-learn. Ele é bastante usado para prototipagem rápida e provas de conceito antes que a lógica seja implementada em SQL, Spark ou pipelines de produção.
Até mesmo equipes financeiras e áreas de negócio não técnicas usam Pandas para automatizar fluxos de trabalho baseados em Excel.
Saiba mais:
Trabalhando com DataFrames do Pandas
Aprenda análise de dados com Pandas
Quando usar Polars no seu fluxo de trabalho
O Polars se destaca quando desempenho, escalabilidade e confiabilidade são mais importantes do que flexibilidade ad hoc. Graças ao seu mecanismo em Rust, ao multithreading, ao modelo de memória colunar e ao mecanismo de execução lazy, o Polars consegue lidar com cargas de trabalho de ETL surpreendentemente grandes em uma única máquina, especialmente quando a eficiência de memória é crítica. Execução lazy significa que as operações não são executadas imediatamente, mas registradas, otimizadas e executadas apenas quando a saída é solicitada explicitamente. Isso pode resultar em ganhos significativos de desempenho, pois o sistema cria um único plano de execução otimizado, em vez de executar cada operação passo a passo. As transformações de dados são planejadas primeiro e executadas depois, permitindo otimizar todo o pipeline para máxima velocidade e eficiência.
Em pipelines de dados de produção que exigem alto desempenho consistente e fluxos de trabalho sensíveis à velocidade, o Polars utiliza multithreading por padrão para aproveitar todos os núcleos de CPU disponíveis, processando cada bloco do DataFrame em uma thread diferente. Isso o torna significativamente mais rápido do que bibliotecas de DataFrame tradicionais de thread única, como o Pandas.
Ao realizar joins em dezenas de milhões de linhas, como a junção de logs de clickstream com metadados de usuários, os joins do Polars são multithreaded, e o uso de dados colunares reduz cópias desnecessárias de memória.
Em cenários de uso que envolvem datasets grandes, transformações complexas ou pipelines de várias etapas, o Polars se beneficia do processamento paralelo, no qual cada linha pode ser processada de forma independente. Para pipelines de queries com várias etapas e muitas transformações, o Polars consegue otimizar e executar todo o pipeline em paralelo. O uso combinado de streaming paralelo e avaliação lazy permite que o Polars processe datasets maiores do que a memória disponível. O processamento paralelo e a avaliação lazy também beneficiam operações de leitura de arquivos grandes, como arquivos CSV e Parquet.
O Polars também obtém vantagens expressivas de desempenho ao utilizar armazenamento colunar baseado no Apache Arrow para otimização de queries. No armazenamento colunar, os dados são armazenados coluna por coluna, e não linha por linha. Isso permite que o Polars leia apenas as colunas necessárias, reduzindo o I/O de disco e o acesso à memória, o que o torna mais eficiente para processamento analítico. Além disso, ele pode operar diretamente sobre os buffers de memória contínuos do Apache Arrow, sem a necessidade de copiar dados.
Se você estiver realizando engenharia de recursos para ML e exploração em datasets extremamente grandes, juntando grandes tabelas de fatos, executando agregações pesadas e analítica OLAP, cargas de trabalho de séries temporais, leitura massiva de arquivos, processamento maior do que a memória disponível ou processamento em batch com SLAs rigorosos, o Polars pode ser a melhor escolha.
- Link Interno: Apache Spark (âncora: processamento de dados distribuído)
- Link interno: pipelines de dados (âncora: criação de pipelines de dados escaláveis)
Representação de dados e arquitetura
Os modelos de representação de dados e as arquiteturas do Pandas e do Polars diferem intencionalmente. O armazenamento orientado a linhas usado pelo Pandas mantém linhas completas de forma contínua na memória, enquanto o armazenamento colunar adotado pelo Polars mantém cada coluna armazenada de forma contígua. Cada método pode impactar o desempenho, dependendo dos tipos de query que você executa.
Para queries analíticas, o armazenamento colunar normalmente apresenta melhor desempenho, porque a query precisa acessar apenas as colunas necessárias, enquanto modelos orientados a linhas precisam ler linhas completas.
As colunas têm tipos uniformes, o que resulta em melhores taxas de compressão, e a vetorização permite processamento em batch de alta velocidade.
Para queries transacionais, como cargas de trabalho de OLTP, o armazenamento orientado a linhas é preferível, já que uma linha inteira é armazenada em conjunto. Assim, buscar um registro completo exige uma única leitura, e atualizar uma linha modifica apenas uma região compacta da memória.
Os gráficos abaixo mostram as médias de desempenho comparando bibliotecas de DataFrame orientadas a linhas e colunares, neste caso, Koalas e Dask.
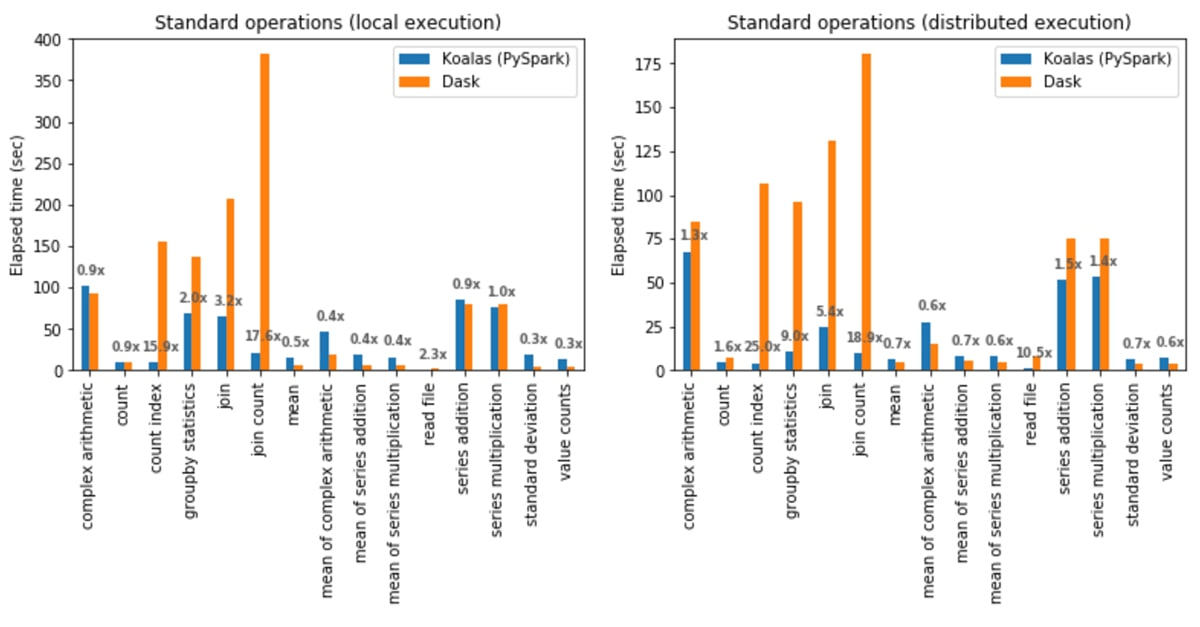
O formato colunar do Polars permite agregações mais rápidas. Como cada coluna é armazenada de forma contígua na memória, o sistema pode percorrer uma única coluna sem escanear dados não relacionados e paralelizar agregações entre os núcleos da CPU. Para datasets grandes, o armazenamento colunar reduz a pressão sobre a RAM porque lê apenas as colunas exigidas pela query.
O layout colunar do Polars também viabiliza execução vetorizada usando Apache Arrow, permitindo compartilhamento de dados sem cópia. O Polars consegue realizar filtragem e corte sem copiar os buffers de dados subjacentes.
O modelo de armazenamento orientado a linhas usado pelo Pandas significa que cada linha de um DataFrame é armazenada como um conjunto de objetos Python agrupados. Esse modelo é otimizado para operações que recuperam ou modificam registros completos. Ele consegue buscar todos os dados de um registro em uma única operação, o que o torna mais adequado para muitas operações pequenas com cargas de trabalho mistas, em vez de grandes vetores. O Pandas oferece suporte a tipos de dados heterogêneos, como objetos Python, strings, números, listas e dados aninhados. Essa flexibilidade é útil para dados reais desorganizados, JSON embutido em registros CSV e conjuntos de recursos com tipos mistos.
Para queries que exigem acesso a muitas ou a todas as colunas de uma única linha, como a recuperação de registros em nível de usuário e a serialização de dados em nível de linha para APIs, o Pandas não precisa reconstruir a linha acessando múltiplos buffers de colunas. Ele também é mais rápido para cargas de trabalho com mutações frequentes, pois permite alterações in-place nas células do DataFrame.
Quando os dados cabem confortavelmente na memória, o Pandas é muito conveniente e oferece desempenho suficiente para datasets pequenos a médios.
Desempenho: avaliando velocidade e uso de recursos
O Polars é, em geral, mais rápido e mais eficiente no uso de recursos do que o Pandas, especialmente em trabalhos de engenharia de dados e à medida que o volume de dados e a complexidade aumentam. O Polars é colunar, utiliza multithreading por padrão e pode executar planos de query lazy e otimizados. O Pandas é majoritariamente de thread única para operações de DataFrame e usa avaliação eager, em que cada linha é executada imediatamente e materializa DataFrames intermediários. O Pandas pode ser mais rápido em dados pequenos e em algumas operações vetorizadas simples, além de ser mais flexível, mas essa flexibilidade pode ter custo em CPU e memória.
O gráfico abaixo mostra como a contagem de threads pode impactar o desempenho.
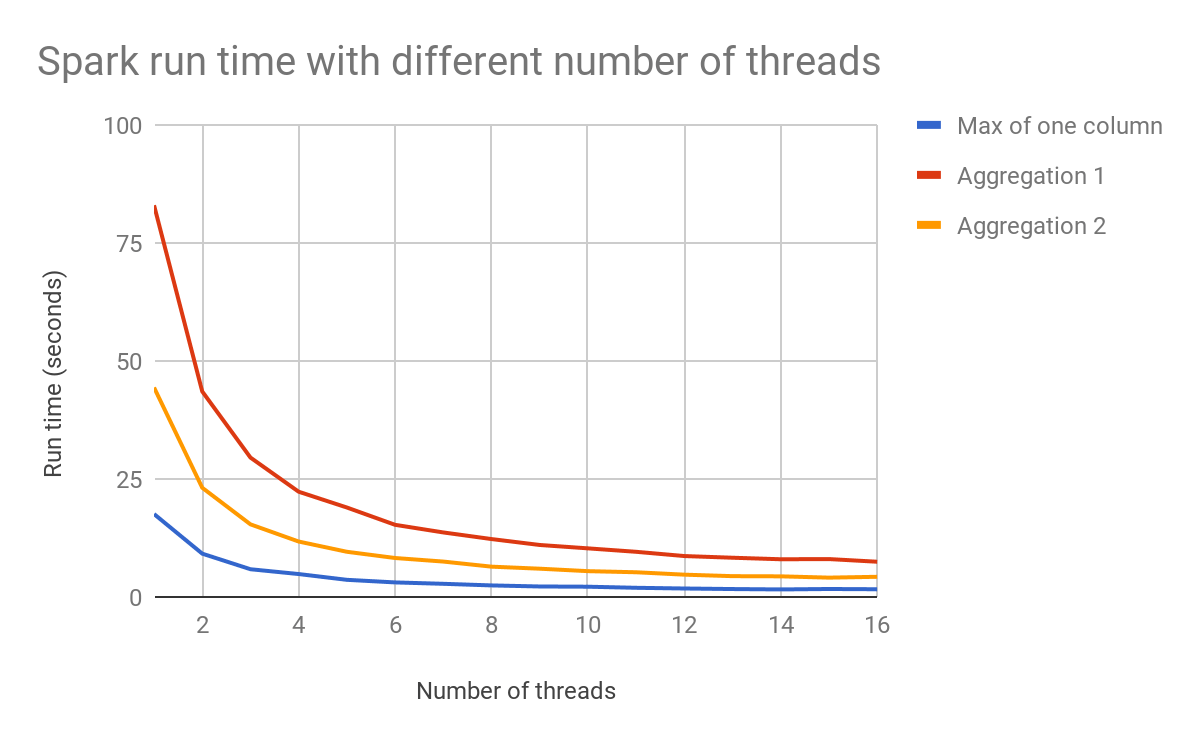
Com o planejamento de query do LazyFrame do Polars e seu otimizador, o código constrói primeiro um plano de query, e o Polars o otimiza e executa apenas quando você solicita. Só isso já responde por grande parte da vantagem do Polars em velocidade e uso de memória.
No Pandas, a avaliação eager significa que os cálculos são feitos imediatamente, um objeto intermediário é criado na memória e, em seguida, esse intermediário é passado para a próxima etapa. Isso implica perda de desempenho devido a múltiplas passagens sobre os dados, muitas vezes criando vários intermediários de tamanho completo. Como o Pandas não enxerga o pipeline inteiro, ele não consegue otimizar globalmente. Ainda assim, o Pandas é forte quando os dados cabem confortavelmente na memória, quando as operações são pequenas e interativas e quando você quer feedback imediato após cada linha. Como regra geral, escolha Pandas quando:
- você está fazendo EDA rápida
- os datasets são pequenos ou médios
- você quer inspeção e depuração passo a passo
- sua lógica é altamente customizada em Python, linha a linha
Escolha Polars quando:
- você está criando pipelines repetíveis de ETL ou analítica
- os datasets são grandes ou largos
- você lê muitos arquivos Parquet ou Arrow
- você se preocupa com velocidade, uso de memória e menos cópias intermediárias
Devido às diferenças filosóficas entre as bibliotecas, com o Pandas focado em flexibilidade e o Polars em desempenho, elas lidam de forma diferente com dados ausentes e valores nulos, o que também pode impactar o desempenho.
O Pandas pode tratar vários valores diferentes como “ausentes”, o que mantém flexibilidade, mas às vezes gera inconsistências e pode tornar as operações mais lentas devido ao uso intensivo de objetos Python. O Polars utiliza “null” como o único valor ausente em todos os tipos de dados, alinhando-se mais de perto à semântica de SQL, o que é mais rápido e mais eficiente em memória em escala.
Como mostrado no gráfico abaixo, que compara tempos de execução em fluxos de trabalho representativos, quando o Pandas é forçado a executar lógica em nível de Python, linha a linha, em datasets grandes, ele cria muitas cópias intermediárias e as operações ficam mais lentas.
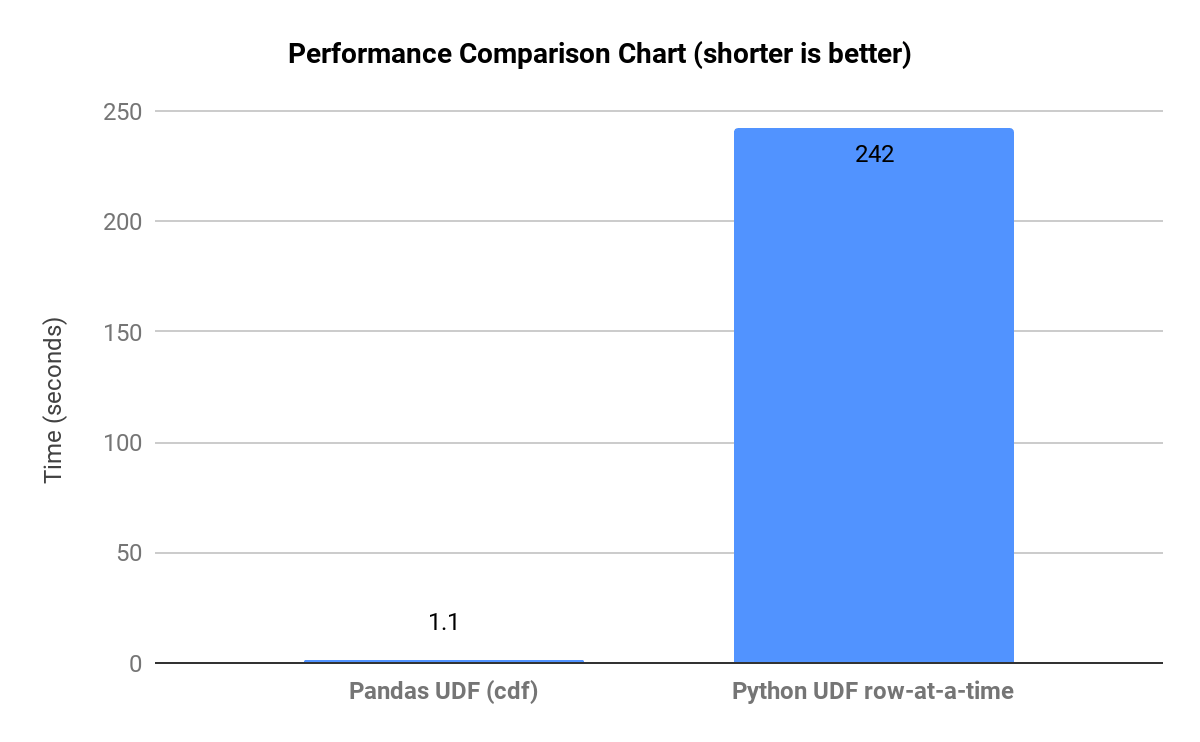
O Polars também pode apresentar gargalos de desempenho quando a vetorização é quebrada e a otimização de query é impedida, ou quando o modo lazy não é usado em pipelines grandes. A otimização do Polars também pode se degradar em joins muito grandes de muitos para muitos.
O gráfico abaixo mostra o consumo de memória do Pandas aumentando linearmente conforme o tamanho dos dados cresce.
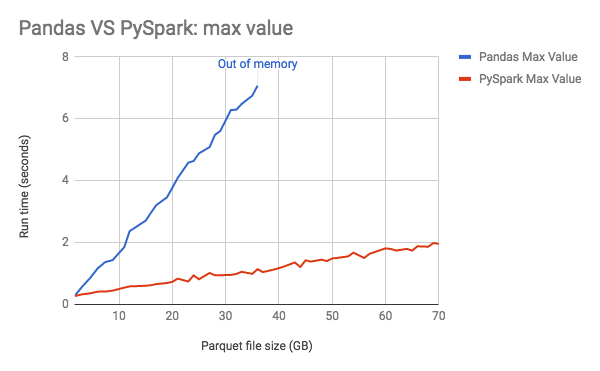
Orientações de desempenho:
- Se sua carga de trabalho envolve groupby, join ou varredura de grandes volumes de Parquet, o Polars geralmente leva vantagem.
- Se seu fluxo de trabalho é uma EDA interativa, com muita lógica Python customizada, o Pandas costuma ser mais conveniente.
Benchmarking
Para entender as diferenças de desempenho, veja algumas abordagens de benchmarking que você pode implementar:
Benchmarking rápido e ad hoc
- Use
time.perf_counter()para medir o tempo de execução (wall time) - Repita várias vezes
- Reporte a
mediana e o p95
Microbenchmarks repetíveis (para uma equipe / PRs)
- Use
pytest-benchmarkouasv - Execute em uma máquina estável, ou em um runner de CI fixo
- Salve os resultados entre commits
Benchmarking em condições próximas de produção (o mais significativo)
- Use um dataset real, com forma e tamanho representativos
- Compare execuções com cache frio versus cache quente
- Meça o tempo de um pipeline de ponta a ponta
- Monitore memória e CPU
Para tornar as comparações justas, use o mesmo formato de entrada, alinhe tipos de dados, use os mesmos agrupamentos, chaves e saídas e controle o threading, seja o comportamento padrão, seja um cenário “uma CPU” para uma comparação direta.
- Quando diferenças de desempenho são mais importantes para casos de uso específicos
- Melhorias médias de tempo no mundo real com Polars em datasets grandes
Como lidar com dados ausentes e tipos de dados
A forma como uma biblioteca de DataFrame lida com dados ausentes e tipos de dados afeta correção, qualidade dos dados, desempenho e facilidade de uso. O Pandas oferece um tratamento flexível, mas às vezes inconsistente, de dados ausentes e dtypes, enquanto o Polars aplica um único modelo de valores nulos com tipagem forte, resultando em um comportamento mais seguro, mais rápido e mais previsível, especialmente em escala.
O modelo de dados ausentes do Pandas trata vários valores, como NaN (float), None, NaT (datetime) e pd.NA (escalar anulável), como valores ausentes. Isso ajuda na flexibilidade, mas pode ser inconsistente quando diferentes tipos de dados lidam com dados ausentes de formas distintas. Ao preencher valores ausentes, o Pandas pode alterar o tipo de dado de maneira inesperada. A semântica ambígua de null torna mais difícil para o Pandas detectar problemas de qualidade de dados.
O Polars usa um único valor ausente, null, e aplica o mesmo comportamento em todos os tipos de dados, além de tornar todos os tipos anuláveis por default. Isso tende a produzir um comportamento previsível e melhor desempenho. Ao preencher valores ausentes, o Polars é explícito e preserva o tipo de dado. O tratamento consistente de null do Polars normalmente resulta em menos erros de qualidade de dados.
Também existem considerações sobre como diferentes modelos de memória afetam conversões de tipo e interoperabilidade. Historicamente, o Pandas se apoia no NumPy, com um modelo mais orientado a linhas e objetos Python que podem conter tipos de dados mistos, enquanto o Polars é nativo em Arrow e colunar, o que facilita a integração com o restante da stack de dados em Python.
Veja algumas práticas recomendadas para manter a integridade dos dados ao usar as duas bibliotecas de DataFrame:
- Para ambas as bibliotecas…
Imponha unicidade e restrições de banco de dados, como unicidade de chave primária, validade de chave estrangeira e contagens de linhas ou partições esperadas. Valide joins para evitar explosões silenciosas de linhas. Use transformações consistentes e determinísticas, que são muito mais fáceis de testar e reproduzir. Armazene dados “fonte de verdade” em Parquet, com esquema estável, para preservar tipos. E não espere até o final para validar. Valide em pontos-chave, como após a ingestão, após grandes transformações e após a publicação.
- Com Pandas...
Defina tipos de dados explicitamente no momento da leitura sempre que possível e prefira tipos anuláveis, como Int64, Boolean, string ou datetime64[ns], para que o Pandas não recorra a object. Normalize valores ausentes logo no início e fique atento a problemas silenciosos, como NaN == NaN. Evite indexação em cadeia e lógica linha a linha para a lógica principal.
- Com Polars...
Defina esquema e tipos de dados explicitamente e confie na tipagem estrita do Polars. Use null de forma consistente e prefira tratamento de null baseado em expressões.
Sintaxe e transições de API
- Diferenças principais de API: encadeamento do Polars versus operações do Pandas
- No Polars, normalmente você cria um único pipeline encadeado e baseado em expressões e, no modo lazy, o Polars consegue otimizar toda a cadeia. No Pandas, com frequência você escreve uma sequência de instruções que fazem mutações no método eager, passo a passo.
- Exemplos de código lado a lado: filtragem, agrupamento, agregações
- Filtragem e seleção (encadeamento)
- Pandas
- Filtragem e seleção (encadeamento)
result = pdf[pdf["country"] == "US"][["user_id", "revenue"]]
- Polars
resultado = (
pldf
.filter(pl.col("country") == "US")
.select(["user_id", "revenue"])
)
- Agrupamento e agregação:
- Pandas
rev_by_user = (
pdf
.groupby("user_id", as_index=False)["revenue"]
.sum()
)
- Polars
rev_by_user = (
pldf
.group_by("user_id")
.agg(pl.col("revenue").sum())
)
Fundamentos de sintaxe do Polars:
Há dois conceitos que mais importam ao aprender Polars: expressões e execução lazy versus eager. O Polars é construído em torno de expressões, uma computação orientada a colunas, semelhante a SQL, que descreve o que você quer calcular e um mecanismo que decide como calcular isso de forma eficiente. As expressões não são executadas imediatamente. Elas são blocos de construção no modo “lazy”, em que as operações constroem um plano de query e as execuções acontecem apenas quando você chama.
Por outro lado, no modo eager, que corresponde ao comportamento do Pandas, as operações são executadas imediatamente, o que é bom para exploração e depuração, mas desacelera em pipelines de grande escala. O Polars pode oferecer execução eager para interatividade e execução lazy para pipelines otimizados e em grande escala.
Convertendo código existente de Pandas para Polars
Conversão geralmente significa:
- Substitua a indexação de linhas e colunas
df[...]por.filter()/.select() - Substitua a atribuição in-place por
.with_columns() - Substitua
.apply()por expressões nativas, sempre que possível - Considere o modo lazy para ETL apoiado em arquivos
Exemplo de conversão:
Original em Pandas:
df = pd.read_parquet("events.parquet")
df = df[df["country"] == "US"][["user_id", "revenue", "ts"]]
df["receita"] = df["receita"].fillna(0)
df["day"] = pd.to_datetime(df["ts"]).dt.date
)
out = (
df.groupby(["user_id", "day"], as_index=False)
.agg(total_revenue=("revenue", "sum"))
Polars otimizado para lazy:
importar polars como pl
out = (
pl.scan_parquet("events.parquet")
.filter(pl.col("country") == "US")
.select(["user_id", "receita", "ts"])
.with_columns([
pl.col("revenue").fill_null(0),
pl.col("ts").dt.date().alias("dia"),
])
.group_by(["user_id", "day"])
.agg(pl.col("revenue").sum().alias("total_revenue"))
.collect()
)
Quando uma equipe troca bibliotecas de dados, por exemplo, de Pandas para Polars, ou passa a adicionar Polars ao lado de Pandas, a curva de aprendizado está menos na sintaxe e mais no mindset, nos fluxos de trabalho e no gerenciamento de riscos. O mindset do Pandas é imperativo, passo a passo, com mutações ao longo do caminho e inspeção após cada linha. O mindset do Polars é declarativo e baseado em expressões, em que você cria transformações como pipelines com dados imutáveis e usa planejamento de query no estilo SQL.
O desafio de aprendizado é começar a pensar de forma orientada a colunas e declarativa, em vez de linha a linha. Hábitos de depuração e inspeção também precisam mudar: pense em transformações, não em estados.
Com o Polars, a rigidez de tipos de dados pode parecer hostil quando força consistência de esquema e falha rapidamente diante de problemas de tipo, mas essas falhas evitam bugs silenciosos de qualidade de dados. O desafio é tratar erros de tipo de dados como sinais de qualidade, e não como incômodos.
As equipes também podem sentir lacunas de ferramentas ao migrar para o Polars, já que praticamente todo o ecossistema de dados em Python aceita Pandas e há uma vasta base de documentação. Considere uma abordagem híbrida quando ferramentas legadas forem necessárias, usando Polars para preparação pesada de dados e Pandas para modelagem e visualização.
Existem camadas de compatibilidade de API para reutilizar código de DataFrame no estilo Pandas sobre o Polars. Esses adaptadores suportam os mesmos nomes e assinaturas de métodos do Pandas, com comportamentos semelhantes, e traduzem chamadas para operações nativas do Polars. Mas atenção: uma camada de API não é conversão. Ela pode introduzir lacunas semânticas e ocultar armadilhas de desempenho.
A seguir, alguns padrões comuns de refatoração e estratégias de migração ao trocar de uma pilha de DataFrame para outra.
Padrões comuns de refatoração (pandas para Polaris):
Substitua a indexação Boolean por .filter() e .select()
- pandas
df2 = df[df["x"] > 0][["id", "x"]]
- Polars
df2 = df.filter(pl.col("x") > 0).select(["id", "x"])
Substitua a mutação in-place por .with_columns()
- Pandas
df["y"] = df["x"] * 2
- Polars
df = df.with_columns((pl.col("x") * 2).alias("y"))
Substitua np.where / atribuição condicional por when/then/otherwise
- Pandas
df["tier"] = np.where(df["revenue"] >= 100, "high", "low")
- Polars
df = df.with_columns(
pl.when(pl.col("revenue") >= 100).then("high").otherwise("low").alias("tier")
)
- Reescreva agregações de groupby para .agg (...) baseado em expressão
- Pandas
out = df.groupby("k", as_index=False).agg(total=("v","sum"), users=("id","nunique"))
- Polars
out = df.group_by("k").agg(
pl.col("v").sum().alias("total"),
pl.col("id").n_unique().alias("users"),
)
Prefira varreduras lazy para ETL baseado em arquivos
- Pandas
df = pd.read_parquet("events.parquet")
- Polars
out = (
.scan_parquet("events.parquet")
.filter(pl.col("country") == "US")
.select(["user_id", "revenue"])
.group_by("user_id")
.agg(pl.col("receita").sum().alias("rev"))
.collect()
)
Substitua .apply() por expressões nativas (ou isole UDFs)
- Pandas
A maioria das migrações do Pandas trava em .apply(axis=1)
- Polars
Tente expressar a lógica com expressões do Polars (str.*, dt.*, list.*, when/then).
Se for inevitável, isole a UDF em uma coluna ou subconjunto pequeno e especifique return_dtype.
- Link interno: programação em Python (âncora: Python para análise de dados)
O manual de IA agêntica para empresas

Integração e compatibilidade com o ecossistema
Polars e Pandas foram projetados para funcionar juntos, mas são construídos sobre modelos diferentes de execução e tipagem. A interoperabilidade existe por meio de pontos explícitos de conversão, não por mecanismos internos compartilhados. Como ambas as bibliotecas falam Apache Arrow, o Arrow pode atuar como uma camada-chave de interoperabilidade, permitindo transferência colunar eficiente e melhor preservação de esquema.
- Use Parquet ou tabelas Arrow como formato de intercâmbio
- Evite CSV em fluxos de trabalho entre bibliotecas
A interoperabilidade é explícita e intencional. Não há mecanismo de execução compartilhado nem semântica de índice comum. Também não há garantia de cópia zero. Sempre valide.
Conversão de dados entre formatos: to_pandas() e importação em Polars
- De Pandas para Polars
- As colunas do Pandas são convertidas para tipos compatíveis com Arrow no Polars.
- O Index do Pandas é descartado, a menos que você o redefina
- Colunas do tipo object são inspecionadas e convertidas (geralmente para Utf8 ou geram erro)
- Práticas recomendadas
- Use
pd_df.reset_index()se o índice for relevante - Normalize os dtypes antes:
- Use string, Int64 e Boolean
- Evite colunas object com tipos mistos
- Use
- Polars para pandas
- As colunas do Polars são convertidas para Pandas, muitas vezes com suporte do Arrow quando disponível.
- Um RangeIndex default é criado.
- Valores nulos são mapeados para as representações de valores ausentes do Pandas.
- Práticas recomendadas
- Faça a conversão uma única vez no limite do fluxo de trabalho, e não repetidamente.
- Valide os dtypes após a conversão, especialmente inteiros com nulos.
- Regra geral: converta nos limites do fluxo de trabalho, não dentro de loops nem em caminhos críticos.
Ao integrar com bibliotecas de visualização e ferramentas de plotting, a maioria das bibliotecas de visualização em Python espera Pandas ou arrays NumPy. O Polars se integra bem, mas, na prática, você costuma converter para Pandas no limite do plotting ou passar arrays ou colunas diretamente.
Para conectividade com bancos de dados e suporte a formatos de arquivo, o Pandas é mais adequado para leituras ad hoc e compatibilidade com o ecossistema. O Polars é mais indicado para arquivos grandes, Parquet e analítica centrada em arquivos. O Pandas oferece suporte a PostgreSQL, MySQL, SQL Server, Oracle, SQLite e qualquer banco de dados com driver SQLAlchemy. O Polars não é um cliente de banco de dados completo. Ele espera que os dados cheguem como arquivos ou tabelas Arrow. Alguns bancos de dados e ferramentas conseguem exportar Arrow diretamente, o que o Polars consegue ingerir com eficiência.
Ambos oferecem suporte a análise de CSV. O Polars é muito rápido, com menor sobrecarga de memória, enquanto o Pandas tem análise mais flexível e lida melhor com CSVs desorganizados, embora a análise tenda a ser intensiva em CPU e o uso de memória possa aumentar significativamente.
O Polars é superior para Parquet. O Pandas consegue ler Parquet, mas as operações são eficazes apenas com pushdown limitado em comparação ao Polars. Com execução em streaming e um mecanismo colunar nativo em Arrow, o Polars pode gerar resultados com ganhos de desempenho de ordens de magnitude em datasets grandes.
A integração e a compatibilidade com bibliotecas de machine learning (ML) são um dos fatores práticos mais importantes ao escolher entre Pandas e Polars, ou ao usar ambos. A maioria das bibliotecas de ML espera arrays NumPy (X: np.ndarray, y: np.ndarray), DataFrames ou Series do Pandas, comuns em fluxos de trabalho com scikit-learn, ou Arrow. Muitas bibliotecas tratam o Pandas como o contêiner tabular default. Portanto, se sua stack de ML é majoritariamente baseada em scikit-learn e ecossistema relacionado, o Pandas continua sendo o caminho de menor atrito.
A maioria das bibliotecas de ML ainda não aceita DataFrames do Polars diretamente como entradas de primeira classe. O Polars é excelente para engenharia de recursos, mas planeje a conversão no limite. A recomendação é fazer a preparação pesada de dados no Polars e converter para Pandas ou NumPy para treinamento e inferência de modelos.
Checklist rápido para alimentar dados em ML:
- Não usar colunas com tipos mistos.
- Garantir que todos os recursos sejam numéricos ou codificados.
- Tratar nulos adequadamente, por imputação, remoção ou uso de modelos que lidem com valores ausentes.
- Manter a ordem dos recursos estável.
- Preservar os nomes dos recursos, se necessário.
- Garantir validação de esquema entre treinamento e inferência.
Considerações de produção
Quando você leva cargas de trabalho de Pandas ou Polars de notebooks para produção, os principais pontos de atenção geralmente têm menos a ver com sintaxe e mais com runtime, empacotamento, previsibilidade de desempenho e operabilidade. Valide o comportamento sob os limites reais de memória e CPU do seu alvo de implantação. Escolha estratégias como poda de colunas, filtragem antecipada e varreduras em streaming ou lazy para cargas de trabalho baseadas em arquivos.
Para runtime e empacotamento, garanta que a versão de Python em produção corresponda à que você testa localmente. O Polars inclui código nativo, em Rust, e o Pandas depende do NumPy ou de mecanismos opcionais como PyArrow e fastparquet. Parquet e Arrow geralmente são melhores para produção, oferecendo mais estabilidade de esquema, leituras mais rápidas e menos surpresas de tipo de dados do que CSV.
O Polars usa multithreading por default. Considere definir e controlar o uso de threads por meio de configuração de ambiente em produção. A otimização lazy do Polars pode aumentar o throughput, mas jobs muito pequenos podem ter sobrecarga de planejamento.
Pipelines de produção devem impor tipos de dados e expectativas de anulabilidade de forma explícita, já que ambas as bibliotecas exigem que você declare restrições. Adicione verificações em torno de joins para evitar explosões silenciosas de linhas.
Para observabilidade, acompanhe runtime, contagens de linhas, contagens de null em colunas-chave e tamanhos de saída por execução. Adicione verificações do tipo stop-the-line nos limites, como antes de publicar saídas. E garanta que erros apareçam com contexto acionável, como partição, arquivo ou tabela, e qual verificação falhou.
Valide saídas, como contagens de linhas, agregações e taxas de null, além de orçamentos de desempenho, como thresholds de tempo e memória. Execute testes em containers que correspondam ao OS e ao glibc de produção para evitar surpresas com wheels nativos.
Estratégias práticas de migração
Estratégias de migração para mover uma equipe de Pandas para Polars, ou adotar Polars ao lado de Pandas:
- Padrão Strangler: quando você precisa de baixo risco e entrega contínua, substitua um segmento por vez por Polars, mantendo o Pandas antigo em execução. Converta nos limites.
- Usar ambos: quando o gargalo está em ETL e agregação, mas você depende de ferramentas nativas do Pandas a jusante, use Polars para I/O, joins, groupbys e computação de recursos. Converta o resultado final para Pandas para scikit-learn, plotting e bibliotecas de estatística.
- Reescrita completa de um pipeline: quando você quer uma história de sucesso clara e padrões reutilizáveis, escolha um pipeline de ponta a ponta e reescreva-o totalmente em Polars para servir como implementação de referência interna.
- Paridade com execução dupla: quando a correção é crítica, execute versões em Pandas e Polars em paralelo por um período, compare saídas, métricas e custos e faça a troca quando a paridade estiver comprovada.
Perfil de desempenho: para identificar oportunidades de otimização, comece a rastrear wall time, tempo de pico de memória, contagem de linhas, contagem de colunas e correção das saídas. A maioria dos pipelines tem gargalos em uma destas áreas: I/O, join, groupby, sort, análise de strings ou UDFs em Python. Adicione timers simples em torno dessas etapas. Use perfiladores do Pandas, em Python, quando suspeitar de trabalho em nível de Python e perfiladores do Polars para inspecionar um plano de query lazy. Faça uma alteração pontual e execute o mesmo benchmark novamente para comparar.
Considerações sobre treinamento de equipes e transferência de conhecimento
O objetivo é ter sucesso sem interromper as entregas nem perder a confiança nos dados. Garanta que a equipe entenda as motivações da mudança e consiga conectá-las a ganhos reais, como quais problemas estão sendo resolvidos, quais cargas de trabalho se beneficiam mais e o que não vai mudar. Defina responsáveis claros, como líder da migração, revisores e tomadores de decisão, para garantir prestação de contas.
Use pipelines reais da empresa como exemplos, aumentando a relevância e o engajamento. Como o Polars é conceitualmente mais próximo de SQL, embora use sintaxe Python, as principais mudanças são de mindset:
- Imperativo para declarativo
- De processamento linha a linha para processamento orientado a colunas
- De estado mutável para pipelines imutáveis
- De execução imediata para planejamento e execução lazy
Estruture o treinamento em camadas para que as equipes se sintam produtivas rapidamente. Comece com operações básicas, como filter, select e groupby, antes de avançar para expressões, tratamento de null e diferenças de tipos de dados. Em seguida, introduza execução lazy e otimização, antes de abordar padrões de migração e produção. Estabeleça uma fase híbrida, com orientações claras sobre quando o uso de Pandas é permitido, para reduzir ansiedade. Para acelerar a transferência de conhecimento, promova pareamento entre pessoas com experiência em Polars e usuários mais focados em Pandas.
Valide a correção de forma visível, construa confiança e meça e compartilhe os ganhos.
Perguntas frequentes
- Pandas é melhor do que Polars? Nenhum é universalmente melhor. A escolha depende dos requisitos específicos do fluxo de trabalho, do tamanho dos datasets e das necessidades de desempenho.
- O que é melhor, Polars ou Pandas? O Pandas se destaca em análise interativa e integração com o ecossistema, enquanto o Polars apresenta melhor desempenho em pipelines de produção em larga escala.
- Polars substitui o Pandas? O Polars complementa o Pandas, em vez de substituí-lo. Ambos atendem a casos de uso diferentes de forma eficaz.
- Vale a pena migrar para Polars? Depende de você estar processando datasets grandes, nos quais o modo lazy e a otimização de query do Polars trazem benefícios mensuráveis.
Conclusão
Ao decidir qual biblioteca de DataFrame faz mais sentido para suas equipes, não existe uma resposta única. Em geral, o Pandas é mais adequado para datasets pequenos a médios e para análise exploratória, enquanto o Polars, com execução lazy, é mais indicado para alto desempenho em cargas de trabalho grandes, inclusive maiores do que a memória disponível. Dependendo dos casos de uso, você pode acabar usando ambos. Teste partes pequenas de fluxos de trabalho específicos com as duas bibliotecas e avalie com base nas tarefas reais de processamento de dados.
As equipes precisam entender os pontos fortes e as limitações do armazenamento colunar em comparação ao orientado a linhas e as implicações disso para diferentes padrões de query. Diferenças na API principal, na sintaxe, nos formatos de dados e na conectividade com bancos de dados exigem uma curva de aprendizado ao alternar entre bibliotecas de DataFrame.
Recursos para aprofundamento e experimentação:
Criação de pipelines de dados escaláveis
Processamento de dados distribuído
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.