O que é um Banco de Dados Relacional (SGBDR)?
Armazene e gerencie dados estruturados em tabelas com relacionamentos definidos, garantindo a integridade dos dados por meio de propriedades ACID.
- Compreenda o que são Sistemas de Gerenciamento de Banco de Dados Relacionais (SGBDR) e como eles organizam dados em tabelas estruturadas com relacionamentos.
- Aprenda sobre os princípios de bancos de dados relacionais, incluindo chaves primárias, chaves estrangeiras, normalização e consultas baseadas em SQL.
- Descubra por que as soluções de SGBDR continuam sendo essenciais para sistemas transacionais que exigem consistência de dados e integridade referencial.
O que é um banco de dados relacional?
Um banco de dados relacional é um tipo de banco de dados que armazena e fornece acesso a dados em tabelas que podem ser vinculadas umas às outras por meio de colunas e linhas compartilhadas, chamadas de relações, com identificadores exclusivos (chaves) que mostram os diferentes relacionamentos entre as tabelas.
Esse modelo relacional é semelhante a um modelo de planilha em que as linhas representam os registros individuais, como cliente, contas ou transações, enquanto as colunas representam os atributos desses registros, como ID do cliente, número da conta ou valor da transação. Usando esse modelo, as linhas de uma tabela podem ser vinculadas a linhas de outra tabela usando chaves comuns que estabelecem os relacionamentos entre as tabelas.
Este modelo fornece uma maneira padronizada de representar e fazer query de dados, podendo ser utilizado por uma infinidade de aplicações.
Um sistema de gerenciamento de banco de dados relacional (RDBMS) é um sistema de software (às vezes chamado de mecanismo de banco de dados) que implementa o modelo de banco de dados relacional e gerencia dados relacionais, não apenas tabelas; desde gravações e leituras de/para discos, até a manutenção de índices, execução de queries e garantia da integridade de dados.
Conceitos fundamentais do modelo relacional
Tabelas, linhas e colunas
A estrutura fundamental do modelo relacional é a organização dos dados em tabelas, linhas e colunas. Tabelas são estruturas de dados bidimensionais criadas para exibir uma coleção de dados relacionados, organizados logicamente para permitir a execução de query estruturada.
Linhas representam entidades ou registros específicos (tuplas) em uma tabela de banco de dados relacional e contêm o valor de cada coluna.
Colunas representam as categorias de atributos para cada registro em uma linha.
Em essência, as colunas definem a estrutura e as linhas fornecem os dados reais. Uma tabela de produtos simples pode incluir as seguintes linhas de produtos específicos com colunas de atributos associados:
| ID do produto | Nome do produto | Tipo de produto | Preço (US$) |
|---|---|---|---|
| PSHL16 | Linguiça de porco apimentada do Chuck | Linguiça de porco apimentada em gomos (450 g) | 5,99 |
| PSML16 | Linguiça de porco do Chuck | Linguiça de porco padrão em gomos (450 g) | 5,99 |
| GTS16 | Linguiça de Peru Moída do Chuck | Peito de peru moído e temperado (450 g) | 6,59 |
| GT48 | Peru Moído do Chuck | Peito de peru moído (1,36 kg) | 18,59 |
Esquema e dados estruturados
O esquema de um banco de dados relacional descreve a estrutura do banco de dados. Define um modelo de como os dados devem ser apresentados e as regras que devem seguir. Os dados estruturados são armazenados em um formato consistente e previsível de acordo com esse esquema (linhas e colunas com relações consistentes que definem os tipos de dados, para onde podem ir e como devem ser representados).
Um bom esquema proporciona integridade e consistência aos tipos de dados. Com uma estrutura conhecida, é possível otimizar o armazenamento e as queries para manter o desempenho e aprimorar a compreensão, já que cada tabela e coluna tem o mesmo significado.
Restrições e índices
Podem existir restrições e regras ao escrever em uma tabela. Por exemplo, no exemplo acima, todo produto deve estar associado a um ID real de produto e cada tipo de produto descreverá produtos com revestimento (em gomos) ou moídos junto com o peso de forma consistente. Além disso, pode definir restrições como, por exemplo, que cada coluna deve conter valores (NOT NULL) sem duplicados (UNIQUE), exceto para o preço.
Isso significa que cada linha possui os mesmos campos e cada campo tem o mesmo significado. Com um esquema rigoroso, os dados permanecem limpos, os relacionamentos permanecem válidos e as queries permanecem previsíveis.
Bancos de dados relacionais também podem ter índices que tornam a localização de linhas mais rápida, sem a necessidade de uma varredura completa da tabela. Um índice armazena os valores das colunas e fornece ponteiros para as linhas da tabela onde esses valores aparecem. O desempenho pode ser afetado ao fazer queries em tabelas grandes, e a indexação evita a varredura de todas as linhas da tabela.
Os bancos de dados armazenam índices em diversos tipos de estruturas otimizadas para melhorar a velocidade de recuperação de dados:
- A indexação B-Tree (árvore B) é uma estrutura de dados comum, projetada para lidar com grandes datasets de forma eficiente, reduzindo a altura da árvore. Cada nó em uma árvore B pode armazenar várias chaves e ter vários secundários, o que minimiza o número de operações de E/S de disco necessárias para o acesso aos dados. Ao permitir mais secundários em um mesmo nó do que uma árvore binária de busca auto-balanceada comum, a árvore B reduz a altura da árvore e coloca os dados em menos blocos separados.
- Tabelas hash são estruturas de dados que mapeiam chaves para valores e usam uma função hash para converter uma chave em um índice onde o valor correspondente é armazenado. Os índices baseados em hash são eficazes para pesquisas de correspondência exata, mas não são universalmente aceitos ou usados como o tipo de índice default em todos os RDBMSs relacionais e não preservam a ordenação como as árvores B.
Chaves e relacionamentos
As chaves são essenciais para garantir a unicidade, a integridade e a recuperação eficiente dos dados. Elas identificam linhas de forma única, estabelecem relações entre tabelas e evitam duplicação, formando a base de projetos de esquemas relacionais. Os pontos de dados em tabelas podem ser unidos por meio de chaves comuns, possibilitando a query de tabelas para gerar relatórios. Ao usar chaves comuns, os relacionamentos podem ser de um para um, de um para muitos e de muitos para muitos.
As tabelas se conectam por meio de vários tipos de chaves:
- Superchaves são conjuntos de um ou mais atributos que podem identificar exclusivamente um registro.
- Uma chave candidata é um conjunto mínimo de atributos que pode identificar exclusivamente um registro.
- Uma chave primária é uma chave única que identifica uma linha em sua tabela. Por exemplo, em uma tabela de clientes, o ID do cliente seria uma chave primária.
- Uma chave alternativa é uma chave candidata que não foi escolhida como chave primária.
- Uma chave estrangeira é uma coluna que aponta para uma chave primária em outra tabela. Por exemplo, uma tabela de transações pode fazer referência ao ID do cliente da tabela de clientes com Orders.customer_id.
- Uma chave composta é necessária quando uma combinação de dois ou mais atributos é necessária para identificar todos os registros de uma tabela.
Propriedades-chave de bancos de dados relacionais
Bancos de dados relacionais são grupos de operações (transações) que funcionam em conjunto e possuem diversos recursos que os tornam confiáveis. Essas transações seguem um conjunto de regras conhecido como ACID, que significa:
- Atomicidade: Todas as atualizações devem ser concluídas completamente
- Consistência: as regras são sempre aplicadas
- Isolamento: transações concorrentes não interferem nos estados intermediários umas das outras.
- Durabilidade: uma vez gravados, os dados podem sobreviver a falhas ou interrupções.
Essas regras ajudam a garantir a integridade de dados no nível transacional, assegurando que as operações do banco de dados sejam concluídas de forma confiável e correta. O design do esquema, os tipos de dados e as restrições são responsáveis por garantir que os valores nas colunas sejam atômicos e consistentes. Restrições são usadas para manter a consistência entre múltiplas tabelas.
Outra propriedade fundamental dos bancos de dados relacionais é a Linguagem de Consulta Estruturada (SQL), a linguagem mais comum de extração de dados. Como os dados são armazenados em tabelas previsíveis com relacionamentos definidos, o SQL é usado para responder de forma eficiente a perguntas complexas e auxiliar na análise dos dados. Oferece um método padrão para executar queries, recuperar dados, inserir/atualizar/excluir registros, criar novos bancos de dados ou novas tabelas e definir permissões em tabelas, procedimentos e views.
Os bancos de dados relacionais também devem garantir segurança/controle de acesso para proteger os dados em diversas dimensões:
- Autenticação – aqueles que acessam o banco de dados são quem dizem ser
- Autorização – você está fazendo o que tem permissão para fazer
- Auditoria – confirmação do que você fez e quando
A segurança de banco de dados também envolve recursos como criptografia para proteger os dados caso sejam interceptados ou roubados, além de backup e recuperação para que os dados não sejam perdidos durante falhas do sistema.
Os bancos de dados relacionais tornaram-se os "sistemas de registro" default devido à sua padronização e maturidade. Recursos, estruturas e funcionalidades padrão mantêm um RDBMS previsível, confiável, seguro e escalável ao longo do tempo. Por exemplo, com SQL como forma padrão de fazer query, conceitos e habilidades centrais podem ser transferidos de um RDBMS para outro, e aplicações e ferramentas de dados podem ser mantidas por meio de migrações. A padronização também aumenta a concorrência e a escolha dos fornecedores.
Bancos de dados relacionais existem há muito tempo. Essa maturidade significa que elas foram testadas e aprovadas para cargas do mundo real e otimizadas para transações extremamente sofisticadas.
Bancos de dados relacionais x bancos de dados não relacionais
A diferença mais óbvia entre os bancos de dados relacionais e não relacionais é que os bancos de dados não relacionais não armazenam dados estruturados em tabelas. Eles têm a flexibilidade de armazenar dados em contêineres no melhor formato para os dados que estão sendo armazenados. Esses dados não estruturados, definidos de forma vaga, podem incluir emails, documentos comerciais, vídeos e imagens. Mas eles também podem armazenar uma combinação de dados transacionais estruturados e dados não estruturados.
Bancos de dados não relacionais são frequentemente chamados de bancos de dados NoSQL, um termo que originalmente significava "não apenas SQL", refletindo que esses sistemas não dependem do SQL como sua interface principal, embora muitos agora aceitam consultas baseadas em SQL.
Bancos de dados relacionais usam um esquema fixo com linhas e colunas e relacionamentos com chaves e SQL joins, enquanto bancos de dados não relacionais armazenam dados em estruturas flexíveis que não requerem um esquema pré-definido, como pares de valor-chave, nós/arestas e documentos. Em bancos de dados relacionais, os dados devem corresponder ao esquema no momento da gravação, enquanto que em bancos de dados não relacionais o formato dos dados pode variar. Nesses bancos de dados, os dados são interpretados no momento da leitura e os relacionamentos geralmente são gerenciados nas aplicações, e não no banco de dados.
Os bancos de dados relacionais também empregam transações ACID robustas por default, enquanto os bancos de dados NoSQL são tradicionalmente projetados para uma consistência eventual e priorizam a disponibilidade e a velocidade em vez da correção.
Bancos de dados relacionais são escolhidos quando se necessita de uma estrutura clara com regras rígidas, além de uma grande quantidade de relações entre os pontos de dados. Um modelo relacional é mais adequado para relatórios e analítica com transações que devem estar sempre corretas. Bancos de dados relacionais são ótimos para analítica pontual e filtragem e agrupamento complexos, enquanto os não relacionais geralmente são otimizados para um conjunto de queries restrito. Os bancos de dados relacionais normalmente escalam verticalmente, com os sistemas modernos suportando escalabilidade horizontal por meio de réplicas, fragmentação ou execução distribuída, frequentemente com complexidade adicional, enquanto os bancos de dados não relacionais são projetados para escalar horizontalmente e geralmente são escolhidos para grandes redes distribuídas.
Bancos de dados não relacionais são escolhidos para dados flexíveis ou em rápida evolução em grande escala, com padrões de query simples.
Exemplos comuns de RDBMS
- MySQL – um RDBMS de código aberto, agora de propriedade da Oracle Corp., que implementa o padrão SQL. Geralmente, é a escolha preferida para aplicativos web, sistemas comerciais e serviços essenciais data-driven que exigem alto desempenho. É comumente usado para aplicativos web, lojas e catálogos on-line, contas de usuário e sistemas de autenticação, registros e analítica, aplicativos e painéis SaaS.
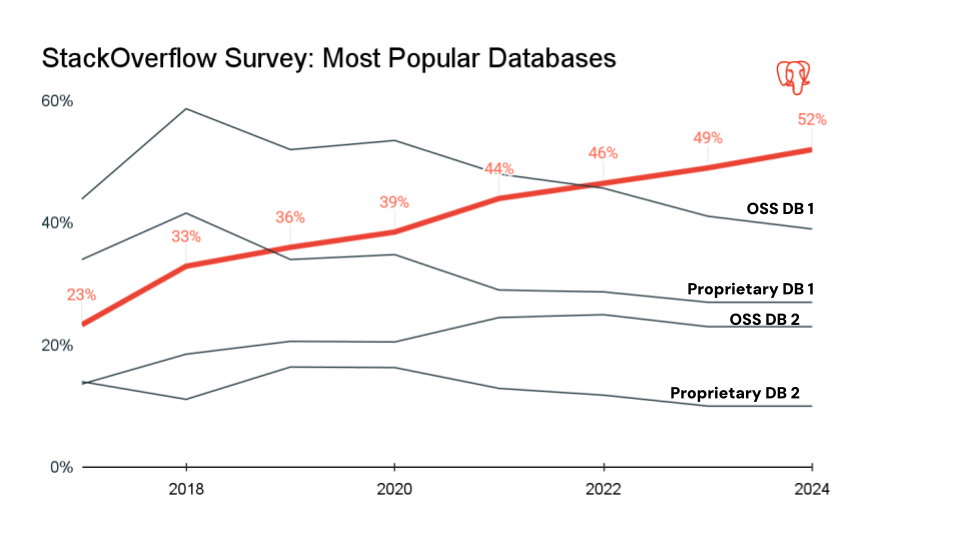
- PostgreSQL – um RDBMS de código aberto altamente extensível, conhecido por seus padrões rigorosos e compliance com ACID, oferecendo um bom equilíbrio entre confiabilidade e flexibilidade. Aceita armazenamento tanto em SQL quanto em JSON/JSONB semiestruturado e utiliza Controle de Concorrência Multiversão. O PostgreSQL é usado para aplicativos web, plataformas SaaS multi-tenant, transações financeiras, analítica e relatórios, dados científicos e cargas de trabalho OLTP. É bastante usado em empresas que operam exclusivamente online. Nos últimos sete anos, o Postgres tornou-se o banco de dados mais conhecido na comunidade de desenvolvedores, sendo o preferido para aplicações modernas.
- SQLite – um banco de dados relacional serverless, multiplataforma e de código aberto, que usa SQL e é executado dentro de uma aplicação por meio de uma biblioteca C leve. Não requer nenhuma configuração ou administração. O SQLite é usado principalmente para sistemas incorporados e pequenas aplicações em dispositivos pessoais.
- Oracle – um RDBMS proprietário de nível empresarial desenvolvido pela Oracle Corp. Conhecido por sua escalabilidade, capacidade de clusters e confiabilidade, é otimizado para cargas de trabalho transacionais (OLTP) e analíticas (OLAP) e utilizado em bancos, companhias aéreas, na área da saúde, telecomunicações, governo e em sistemas ERP/CRM de grande escala.
- Microsoft SQL Server – RDBMS proprietário da Microsoft de nível empresarial baseado em Transact-SQL (T-SQL), a extensão SQL da Microsoft. Disponível para Windows e Linux, o SQL Server é conhecido por suas ferramentas de gerenciamento e administração e por sua forte integração com Microsoft Azure e outras tecnologias da Microsoft. Os casos de uso típicos incluem ERP, CRM, RH, comércio eletrônico, Business Intelligence e analítica. O SQL Server é muito utilizado nos setores financeiro, bancário e de saúde.
- IBM Db2 – uma família proprietária de sistemas RDBMS desenvolvida pela IBM para alto desempenho, confiabilidade e processamento de dados em escala empresarial. As versões do Db2 RDBMS são executadas em múltiplas plataformas, incluindo Linux, UNIX, Windows, IBM AS/400 e mainframes IBM. É baseado em SQL, mas aceita documentos JSON, armazenamento XKL, dados de séries temporais, armazenamento em colunas e recursos de gráfico em algumas versões. É amplamente utilizado nos setores financeiro, governamental, de saúde e seguros, varejo, aviação e em ambientes de IT corporativos.
- MariaDB — um RDBMS de código aberto voltado para a comunidade e criado como um substituto imediato do MySQL, e gerenciado pela MariaDB Foundation. Ele é amplamente usado para cargas de trabalho OLTP e OLAP em aplicativos web, plataformas SaaS, sistemas cloud e empresas, e bastante presente em sistemas Linux e pilhas de código aberto. Os casos de uso comuns incluem aplicativos e sites da web, plataformas SaaS, gerenciamento de conteúdo, comércio eletrônico e analítica.
O manual de IA agêntica para empresas

SQL, RDBMS e perguntas frequentes relacionadas
O SQL é um banco de dados relacional?
Não, SQL é uma linguagem de query usada para interagir com um banco de dados relacional, não com um sistema de banco de dados.
O MySQL é um banco de dados relacional?
Sim, o MySQL é um RDBMS com uma estrutura baseada em tabelas que aceita relacionamentos entre tabelas.
O Excel é relacional?
Não, o Excel é o programa de planilha da Microsoft, não um RDBMS. Embora o Excel utilize um formato de tabela, não existe um esquema imposto com uma estrutura e restrições consistentes. O Excel não consegue executar queries SQL por conta própria e não existem transações ACID.
Qual é a diferença entre o banco de dados relacional e a terminologia do RDBMS?
Embora intimamente relacionados e frequentemente usados de forma intercambi�ável, os bancos de dados relacionais se referem ao próprio modelo de dados, enquanto um RDBMS é um sistema de software que gerencia esse modelo de dados.
Benefícios e Limitações
Os benefícios do uso de bancos de dados relacionais incluem:
- Forte integridade e consistência de dados aplicadas por transações ACID para garantir que não haja atualizações parciais, dados corrompidos e operações confiáveis. Dados estruturados e bem definidos garantem dados limpos e previsíveis.
- Os recursos de query padronizados e as ferramentas com SQL fornecem filtragem, agrupamento, agregação, indexação e joins complexos para tornar os bancos de dados relacionais ideais para analítica, relatórios e lógica comercial complexa.
- Com décadas de maturidade, os bancos de dados relacionais são bem aceitos e oferecem um desempenho confiável, modelos sólidos de segurança e disponibilidade e um ecossistema de ferramentas para reduzir os riscos.
As limitações incluem:
- O esquema rígido e fixo dos bancos de dados relacionais reduz a agilidade e não é adequado para dados não estruturados ou semiestruturados e para formatos de registro que mudam frequentemente.
- Bancos de dados relacionais são ótimos para escalonamento vertical, mas o escalonamento horizontal é complexo.
- O desempenho pode ser prejudicado com datasets muito grandes e joins complexos, o que pode tornar as cargas de trabalho distribuídas mais lentas.
- Os RDBMSs comerciais podem ser custosos, especialmente em grande escala.
- O OLTP não se destina a queries analíticas complexas.
- É fácil de criar silos de dados, aumentando os custos de armazenamento.
- Complexidade do ETL (no caso de movimentação de dados entre armazenamentos operacionais e analíticos).
- Manipulação de dados semiestruturados (Delta, Iceberg, Parquet — aquilo que você encontra em um lakehouse).
- Dificuldade com tipos de dados não padronizados para integração de ML/IA
- Não foi projetado para gerenciar dados de xtreaming
- Dependência do fornecedor de nuvem
Evolução além do RDBMS tradicional
- Era do data warehouse: os RDBMSs são projetados para usar dados atuais e são otimizados para muitas leituras/gravações pequenas para o processamento de transações on-line (OLTP). Dessa forma, eles podem ter dificuldades com analítica em grande escala. Para superar essa limitação, os data warehouses usam esquemas desnormalizados que podem gerenciar enormes e complexas queries sobre data histórica e atual para o processamento analítico on-line (OLAP).
- Desafio do Big Data: os RDBMSs relacionais têm dificuldades ao gerenciar dados massivos, rápidos, diversos e distribuídos. Seu esquema rígido, escalabilidade vertical e sobrecarga de transações ACID os tornavam menos adequados para analítica distribuída em larga escala. Os RDBMSs relacionais tradicionais dependem de joins executados em armazenamento gerenciado localmente, o que limita a escalabilidade em ambientes distribuídos.
- Requisitos nativos cloud: os sistemas tradicionais de bancos de dados relacionais têm dificuldades em arquiteturas nativas cloud que favorecem o armazenamento de objetos. Eles foram projetados para armazenamento em bloco com hardware fortemente acoplado e acesso ao disco com baixa latência. Historicamente, o armazenamento de objetos não oferecia as garantias de baixa latência necessárias para o processamento clássico de transações ACID, o que gerava dificuldades para os projetos tradicionais de RDBMS. Armazenamento de objetos é otimizado para taxas de transferência em vez de latência. Aplicativos nativo cloud também escalam horizontalmente, enquanto os projetos tradicionais de RDBMS dependem de compute e armazenamento fortemente acoplados, geralmente centralizados em um servidor principal.
- Data lakes modernos: as arquiteturas Lakehouse evoluíram para abordar as limitações dos data lakes tradicionais, combinando a escalabilidade e o baixo custo dos data lakes com a estrutura, governança e características de desempenho dos data warehouses e sistemas relacionais.
Um lakehouse usa armazenamento de objetos nativo cloud para persistência de dados, ao mesmo tempo em que introduz formatos de tabela gerenciados, camadas de metadados e logs de transações que permitem a imposição de esquema, acesso SQL e transações ACID diretamente nesse armazenamento. Isso permite que dados estruturados, semiestruturados e não estruturados coexistam em um único sistema.
Diferentemente dos primeiros data lakes que dependiam fortemente de esquema-na-leitura e lógica de processamento externa, os lakehouses aceitam esquema-na-escrita ou evolução do esquema gerenciada no nível da tabela. Isso permite definições consistentes de dados, aplicação de qualidade de dados e analíticas confiáveis. Ao desacoplar o armazenamento do compute, as arquiteturas de lakehouse permitem que múltiplos motores de compute operem nos mesmos dados para analítica, engenharia de dados, transmissão e machine learning. Essa flexibilidade torna os lakehouses apropriados para a analítica em grande escala, Business Intelligence e cargas de trabalho avançadas de dados, mantendo a eficiência de custos e a abertura por meio de formatos de arquivo e tabela abertos. - Arquitetura Lakebase: um lakebase é uma nova categoria de banco de dados operacional projetada para aplicações modernas e inteligentes. Embora os RDBMS se destaquem em consistência transacional e esquemas estruturados, eles estão isolados dos dados analíticos, pipelines de machine learning e inteligência em tempo real dos quais as aplicações dependem cada vez mais. Um Lakebase combina capacidades centrais de banco de dados, como transações, indexação e acesso de baixa latência, com integração nativa ao lakehouse, permitindo que aplicações operem diretamente com dados novos, compartilhados, analíticos e prontos para IA. Isso permite que um único sistema aceite tanto cargas de trabalho operacionais quanto o comportamento inteligente de aplicações data-driven, sem duplicar dados ou dividir arquiteturas.
Sobre mitos comuns
- Todos os bancos de dados são relacionais
Há muitos bancos de dados não relacionais que não seguem o modelo relacional (armazenando dados em tabelas e usando SQL para definir e fazer query em relacionamentos). - Os bancos de dados relacionais são somente SQL
A maioria dos bancos de dados relacionais usa o SQL como linguagem principal. O SQL foi desenvolvido para o modelo relacional, mas alguns bancos de dados utilizam outras linguagens relacionais, como Quel, Tutorial D, Rel e Datalog. - Bancos de dados relacionais estão obsoletos
Bancos de dados relacionais estão longe de estar obsoletos. Eles continuam sendo a melhor opção, de longe, para dados complexos e estruturados e ainda são a base dos sistemas de missão crítica atuais. E o SQL continua sendo uma das linguagens mais utilizadas. Atualmente, os bancos de dados relacionais coexistem com NoSQL, data lakes e lakehouses, à medida que os casos de uso de dados continuam evoluindo.
Conclusão
Bancos de dados relacionais com esquemas estruturados que organizam os dados em tabelas, linhas e colunas, com chaves e joins para recuperação rápida de dados e transações ACID, permanecem uma arquitetura fundamental para aplicações seguras e críticas para a missão. Com uma estrutura projetada para queries rápidas e confiáveis, os bancos de dados relacionais oferecem integridade e consistência aos tipos de dados, e você pode otimizar o armazenamento e as queries para manter o desempenho. Eles também podem coexistir com bancos de dados não relacionais em ambientes modernos de data lake e lakehouse distribuídos.
A padronização e a maturidade dos RDBMSs relacionais significam que eles foram testados e aprovados para cargas do mundo real e otimizados para transações extremamente sofisticadas. Arquiteturas modernas, como o lakebase, estendem essas bases relacionais comprovadas para ambientes nativos cloud, permitindo que a confiabilidade relacional e a analítica baseada em SQL coexistam com armazenamento escalável de objetos e compute distribuído.
Recursos adicionais
- Introdução facilitada para iniciantes, abrangendo tabelas, relações e conceitos básicos
- Visão geral abrangente da arquitetura, dos recursos e das aplicações corporativas do RDBMS
- Explicação abrangente de 1NF a 5NF com exemplos
- Análise detalhada de Atomicidade, Consistência, Isolamento e Durabilidade
- Cobertura abrangente incluindo as regras e fundamentos teóricos de Codd
- Lakehouse: uma nova geração de plataformas abertas que unificam armazenamento de dados e análise avançada
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.