O que é Geração Aumentada por Recuperação (RAG)?
Técnica que aprimora as respostas de LLM ao recuperar informações relevantes de bases de conhecimento externas antes da geração, fundamentando os resultados em fatos
- A geração aumentada por recuperação é um padrão de AI que melhora as respostas de grandes modelos de linguagem ao recuperar primeiro documentos relevantes de fontes de dados externas e, em seguida, fornecer esse contexto ao modelo.
- O RAG ajuda a reduzir alucinações, manter as respostas atualizadas e adaptar os resultados ao próprio conteúdo de uma organização, sem a necessidade de retreinar o modelo subjacente.
- Casos de uso comuns de RAG incluem chatbots de suporte ao cliente, busca de conhecimento interno e experiências de busca aumentada que respondem a perguntas diretamente a partir de documentos da empresa.
O que é Geração Aumentada de Recuperação, ou RAG?
A geração aumentada de recuperação (RAG) é uma estrutura de AI híbrida que reforça os grandes modelos de linguagem (LLMs) combinando-os com fontes de dados externas e atualizadas. Em vez de depender apenas de dados de treinamento estáticos, o RAG recupera documentos relevantes no momento da consulta e os fornece ao modelo como contexto. Ao incorporar dados novos e conscientes do contexto, a AI pode gerar respostas mais precisas, atuais e específicas do domínio.
O RAG está se tornando rapidamente a arquitetura padrão para a criação de aplicações de AI de nível empresarial. De acordo com pesquisas recentes, mais de 60% das organizações estão desenvolvendo ferramentas de recuperação baseadas em AI para melhorar a confiabilidade, reduzir alucinações e personalizar os resultados usando dados internos.
À medida que a AI generativa se expande para funções de negócios como atendimento ao cliente, gerenciamento de conhecimento interno e conformidade, a capacidade do RAG de preencher a lacuna entre a AI geral e o conhecimento organizacional específico o torna uma base essencial para implantações confiáveis no mundo real.
Como o RAG funciona
O RAG aprimora a saída de um modelo de linguagem injetando nela informações em tempo real e conscientes do contexto, recuperadas de uma fonte de dados externa. Quando um usuário envia uma consulta, o sistema primeiro aciona o modelo de recuperação, que usa um banco de dados vetorial para identificar e "recuperar" documentos, bancos de dados ou outras fontes semanticamente semelhantes com informações relevantes. Uma vez identificados, ele combina esses resultados com o prompt de entrada original e os envia para um modelo de AI generativa, que sintetiza as novas informações em seu próprio modelo.
Isso permite que o LLM produza respostas mais precisas e conscientes do contexto, baseadas em dados atualizados ou específicos da empresa, em vez de simplesmente confiar no modelo no qual foi treinado.
Os pipelines de RAG normalmente envolvem quatro etapas: preparação e divisão de documentos (chunking), indexação vetorial, recuperação e aumento de prompt. Esse fluxo de processo ajuda os desenvolvedores a atualizar as fontes de dados sem treinar novamente o modelo e torna o RAG uma solução escalável e econômica para criar aplicações de LLM em domínios como suporte ao cliente, bases de conhecimento e pesquisa interna.
Quais desafios a abordagem de geração aumentada de recuperação resolve?
Problema 1: os modelos de LLM não conhecem seus dados
Os LLMs usam modelos de aprendizado profundo (deep learning) e treinam em conjuntos de dados massivos para entender, resumir e gerar novos conteúdos. A maioria dos LLMs é treinada em uma ampla variedade de dados públicos para que um único modelo possa responder a muitos tipos de tarefas ou perguntas. Uma vez treinados, muitos LLMs não têm a capacidade de acessar dados além do ponto de corte dos dados de treinamento. Isso torna os LLMs estáticos e pode fazer com que respondam incorretamente, deem respostas desatualizadas ou alucinem quando questionados sobre dados nos quais não foram treinados.
Problema 2: as aplicações de AI devem aproveitar dados personalizados para serem eficazes
Para que os LLMs deem respostas relevantes e específicas, as organizações precisam que o modelo entenda seu domínio e forneça respostas a partir de seus dados, em vez de dar respostas amplas e generalizadas. For exemplo, as organizações criam bots de suporte ao cliente com LLMs, e essas soluções devem dar respostas específicas da empresa às perguntas dos clientes. Outras estão criando bots de Q&A internos que devem responder às perguntas dos funcionários sobre dados internos de HR. Como as empresas criam tais soluções sem treinar novamente esses modelos?
Solução: o aumento de recuperação agora é um padrão do setor
Uma maneira fácil e popular de usar seus próprios dados é fornecê-los como parte do prompt com o qual você consulta o modelo de LLM. Isso é chamado de geração aumentada de recuperação (RAG), pois você recuperaria os dados relevantes e os usaria como contexto aumentado para o LLM. Em vez de depender apenas do conhecimento derivado dos dados de treinamento, um fluxo de trabalho de RAG extrai informações relevantes e conecta LLMs estáticos com a recuperação de dados em tempo real.
Com a arquitetura de RAG, as organizações podem implantar qualquer modelo de LLM e aumentá-lo para retornar resultados relevantes para sua organização, fornecendo-lhe uma pequena quantidade de seus dados, sem os custos e o tempo de ajuste fino (fine-tuning) ou pré-treinamento do modelo.
Quais são os casos de uso do RAG?
Existem muitos casos de uso diferentes para o RAG. Os mais comuns são:
Chatbots de perguntas e respostas: a incorporação de LLMs aos chatbots permite que eles obtenham automaticamente respostas mais precisas a partir de documentos e bases de conhecimento da empresa. Os chatbots são usados para automatizar o suporte ao cliente e o acompanhamento de leads do site para responder a perguntas e resolver problemas rapidamente.
Por exemplo, a Experian, uma empresa multinacional de corretagem de dados e relatórios de crédito ao consumidor, queria criar um chatbot para atender às necessidades internas e voltadas para o cliente. Eles perceberam rapidamente que suas tecnologias de chatbot atuais tinham dificuldades para escalar e atender à demanda. Ao criar seu chatbot de GenAI — Latte — na Databricks Data Intelligence Platform, a Experian conseguiu melhorar a manipulação de prompts e a precisão do modelo, o que deu às suas equipes maior flexibilidade para experimentar diferentes prompts, refinar resultados e se adaptar rapidamente às evoluções na tecnologia de GenAI.
- Aumento de pesquisa: a incorporação de LLMs a mecanismos de pesquisa que aumentam os resultados de pesquisa com respostas geradas por LLM pode responder melhor a consultas informativas e facilitar para os usuários encontrarem as informações de que precisam para realizar seus trabalhos.
Mecanismo de conhecimento: faça perguntas sobre seus dados (por exemplo, HR, documentos de conformidade): os dados da empresa podem ser usados como contexto para LLMs e permitir que os funcionários obtenham respostas para suas perguntas facilmente, incluindo perguntas de HR relacionadas a benefícios e políticas e perguntas de segurança e conformidade.
Uma maneira pela qual isso está sendo implantado é na Cycle & Carriage, um grupo automotivo líder no Sudeste Asiático. Eles recorreram à Databricks para desenvolver um chatbot de RAG que melhora a produtividade e o engajamento do cliente ao acessar suas bases de conhecimento proprietárias, como manuais técnicos, transcrições de suporte ao cliente e documentos de processos de negócios. Isso facilitou para os funcionários a busca de informações por meio de consultas em linguagem natural que fornecem respostas contextuais em tempo real.
Quais são os benefícios do RAG?
A abordagem de RAG tem vários benefícios importantes, incluindo:
- Fornecer respostas atualizadas e precisas: o RAG garante que a resposta de um LLM não seja baseada apenas em dados de treinamento estáticos e desatualizados. Em vez disso, o modelo usa fontes de dados externas atualizadas para fornecer respostas.
- Reduzir respostas imprecisas, ou alucinações: ao basear a saída do modelo de LLM em conhecimento externo relevante, o RAG tenta mitigar o risco de responder com informações incorretas ou inventadas (também conhecidas como alucinações). As saídas podem incluir citações de fontes originais, permitindo a verificação humana.
- Fornecer respostas relevantes e específicas do domínio: usando o RAG, o LLM poderá fornecer respostas contextualmente relevantes adaptadas aos dados proprietários ou específicos do domínio de uma organização.
- Ser eficiente e econômico: em comparação com outras abordagens para personalizar LLMs com dados específicos do domínio, o RAG é simples e econômico. As organizações podem implantar o RAG sem a necessidade de personalizar o modelo. Isso é especialmente benéfico quando os modelos precisam ser atualizados com frequência com novos dados.
Quando devo usar o RAG e quando devo fazer o ajuste fino (fine-tuning) do modelo?
O RAG é o ponto de partida ideal, sendo fácil e possivelmente totalmente suficiente para alguns casos de uso. O ajuste fino (fine-tuning) é mais apropriado em uma situação diferente, quando se deseja que o comportamento do LLM mude ou que ele aprenda uma "linguagem" diferente. Eles não são mutuamente exclusivos. Como uma etapa futura, é possível considerar o ajuste fino de um modelo para entender melhor a linguagem do domínio e a forma de saída desejada — e também usar o RAG para melhorar a qualidade e a relevância da resposta.
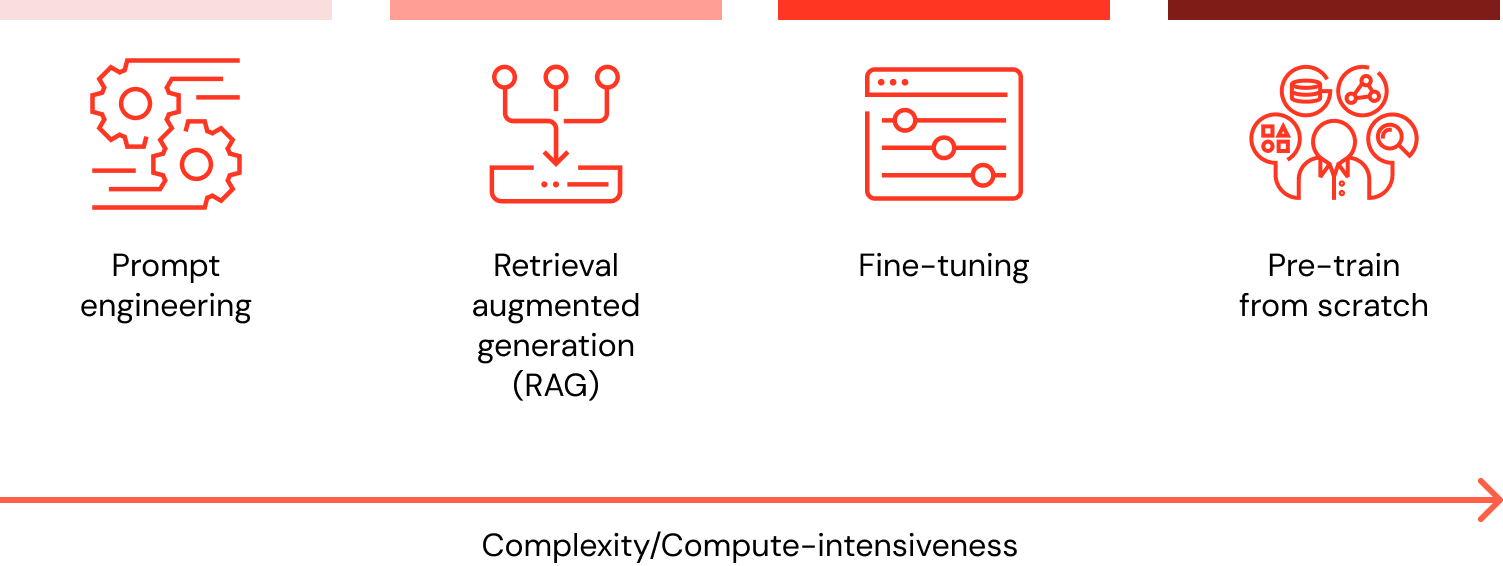
Quando quero personalizar meu LLM com dados, quais são todas as opções e qual método é o melhor (engenharia de prompt vs. RAG vs. ajuste fino vs. pré-treinamento)?
Existem quatro padrões arquitetônicos a serem considerados ao personalizar uma aplicação de LLM com os dados da sua organização. Essas técnicas estão descritas abaixo e não são mutuamente exclusivas. Em vez disso, elas podem (e devem) ser combinadas para aproveitar os pontos fortes de cada uma.
| Método | Definição | Caso de uso principal | Requisitos de dados | Vantagens | Considerações |
|---|---|---|---|---|---|
Engenharia de prompt | Criação de prompts especializados para guiar o comportamento do LLM | Orientação rápida e dinâmica do modelo | Nenhum | Rápido, econômico, sem necessidade de treinamento | Menos controle do que o fine-tuning |
Geração aumentada de recuperação (RAG) | Combinação de um LLM com recuperação de conhecimento externo | Conjuntos de dados dinâmicos e conhecimento externo | Base de conhecimento ou banco de dados externo (ex.: banco de dados vetorial) | Contexto atualizado dinamicamente, maior precisão | Aumenta o comprimento do prompt e o cálculo de inferência |
Fine-tuning | Adaptação de um LLM pré-treinado a conjuntos de dados ou domínios específicos | Especialização em domínios ou tarefas | Milhares de exemplos específicos de domínio ou de instrução | Controle granular, alta especialização | Exige dados rotulados, custo computacional |
Pré-treinamento | Treinamento de um LLM do zero | Tarefas exclusivas ou corporação específica de domínio | Grandes conjuntos de dados (de bilhões a trilhões de tokens) | Controle máximo, sob medida para necessidades específicas | Consome muitos recursos |

Independentemente da técnica selecionada, criar uma solução de maneira bem estruturada e modularizada garante que as organizações estejam preparadas para iterar e se adaptar. Saiba mais sobre essa abordagem e muito mais em The Big Book of MLOps.
Desafios comuns na implementação de RAG
A implementação de RAG em escala apresenta vários desafios técnicos e operacionais.
- Qualidade de recuperação. Mesmo os LLMs mais potentes podem gerar respostas ruins se recuperarem documentos irrelevantes ou de baixa qualidade. Portanto, é crucial desenvolver um pipeline de recuperação eficaz que inclua a seleção cuidadosa de modelos de embedding, métricas de similaridade e estratégias de ranqueamento.
- Limitações da janela de contexto. Com toda a documentação do mundo ao seu alcance, o risco pode ser injetar conteúdo em excesso no modelo, resultando em fontes truncadas ou respostas diluídas. As estratégias de chunking devem equilibrar a coerência semântica com a eficiência dos tokens.
- Atualização dos dados. O benefício do RAG está na sua capacidade de extrair informações atualizadas. No entanto, os índices de documentos podem ficar desatualizados rapidamente sem jobs de ingestão programados ou atualizações automatizadas. Ao garantir que seus dados estejam atualizados, você evita alucinações ou respostas obsoletas.
- Latência. Ao lidar com grandes conjuntos de dados ou APIs externas, a latência pode interferir na recuperação, no ranqueamento e na geração.
- Avaliação de RAG. Devido à natureza híbrida do RAG, os modelos tradicionais de avaliação de AI não são suficientes. Avaliar a precisão dos resultados exige uma combinação de julgamento humano, pontuação de relevância e verificações de fundamentação (groundedness) para avaliar a qualidade da resposta.
O que é uma arquitetura de referência para aplicações RAG?
Existem muitas maneiras de implementar um sistema de geração aumentada de recuperação, dependendo das necessidades específicas e das nuances dos dados. Abaixo está um fluxo de trabalho comumente adotado para fornecer uma compreensão básica do processo.
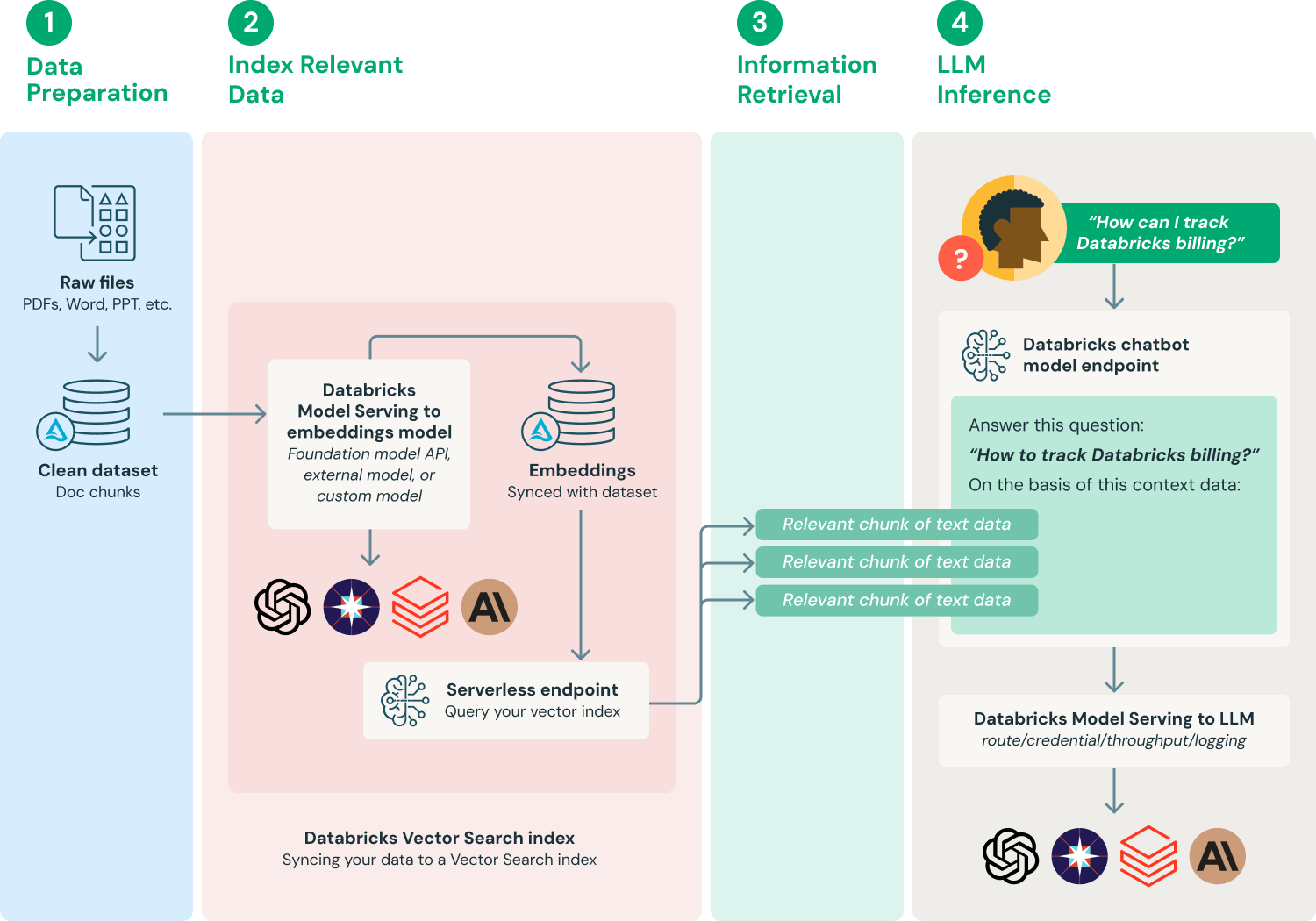
- Preparar os dados: Os dados dos documentos são coletados junto com os metadados e submetidos ao pré-processamento inicial — por exemplo, tratamento de PII (detecção, filtragem, redação, substituição). Para serem usados em aplicações RAG, os documentos precisam ser divididos em comprimentos apropriados (chunking) com base na escolha do modelo de embedding e na aplicação downstream de LLM que usa esses documentos como contexto.
- Indexar dados relevantes: Produzir embeddings de documentos e preencher um índice do AI Search com esses dados.
- Recuperar dados relevantes: Recuperação de partes dos seus dados que são relevantes para a consulta de um usuário. Esses dados de texto são então fornecidos como parte do prompt usado para o LLM.
- Criar aplicações de LLM: Agrupar os componentes de aumento de prompt e consulta ao LLM em um endpoint. Esse endpoint pode então ser exposto a aplicações como chatbots de perguntas e respostas (Q&A) por meio de uma API REST simples.
A Databricks também recomenda alguns elementos arquitetônicos importantes de uma arquitetura RAG:
- Banco de dados vetorial: Algumas aplicações de LLM (mas não todas) usam bancos de dados vetoriais para buscas rápidas de similaridade, na maioria das vezes para fornecer contexto ou conhecimento de domínio em consultas de LLM. Para garantir que o modelo de linguagem implantado tenha acesso a informações atualizadas, as atualizações regulares do banco de dados vetorial podem ser agendadas como um job. Observe que a lógica para recuperar do banco de dados vetorial e injetar informações no contexto do LLM pode ser empacotada no artefato do modelo registrado no MLflow usando os sabores de modelo MLflow LangChain ou PyFunc.
- MLflow LLM Deployments ou Model Serving: Em aplicações baseadas em LLM em que uma API de LLM de terceiros é usada, o suporte do MLflow LLM Deployments ou Model Serving para modelos externos pode ser usado como uma interface padronizada para rotear solicitações de provedores como OpenAI e Anthropic. Além de fornecer um gateway de API de nível empresarial, o MLflow LLM Deployments ou Model Serving centraliza o gerenciamento de chaves de API e oferece a capacidade de aplicar controles de custos.
- Model Serving: No caso de RAG usando uma API de terceiros, uma mudança arquitetônica fundamental é que o pipeline do LLM fará chamadas de API externas, do endpoint do Model Serving para APIs de LLM internas ou de terceiros. Vale ressaltar que isso adiciona complexidade, latência potencial e outra camada de gerenciamento de credenciais. Em contrapartida, no exemplo de modelo com ajuste fino (fine-tuned), o modelo e seu ambiente de modelo serão implantados.
Recursos
- Posts do blog da Databricks
- Demonstração da Databricks
- eBook da Databricks — The Big Book of MLOps
Clientes da Databricks que usam RAG
JetBlue
A JetBlue implantou o "BlueBot", um chatbot que usa modelos de AI generativa de código aberto complementados por dados corporativos, desenvolvido com a tecnologia da Databricks. Esse chatbot pode ser usado por todas as equipes da JetBlue para obter acesso a dados que são controlados por função. Por exemplo, a equipe financeira pode ver dados do SAP e relatórios regulatórios, mas a equipe de operações verá apenas informações de manutenção.
Leia também este artigo.
Chevron Phillips
A Chevron Phillips Chemical usa a Databricks para apoiar suas iniciativas de AI generativa, incluindo a automação de processos de documentos.
Thrivent Financial
A Thrivent Financial está avaliando a AI generativa para aprimorar as buscas, gerar insights mais acessíveis e resumidos, e aumentar a produtividade da engenharia.
Onde posso encontrar mais informações sobre geração aumentada por recuperação (RAG)?
Há muitos recursos disponíveis para encontrar mais informações sobre RAG, incluindo:
Blogs
- Como criar aplicações RAG de alta qualidade com a Databricks
- Versão preliminar pública do Databricks AI Search
- Melhore a qualidade de resposta de aplicações RAG com dados estruturados em tempo real
- Crie aplicativos de Gen AI mais rápido com novos recursos de modelo de fundação
- Melhores práticas para avaliação de LLM em aplicações RAG
- Como usar o MLflow AI Gateway e o Llama 2 para criar aplicativos de AI generativa (Obtenha maior precisão usando a geração aumentada por recuperação (RAG) com seus próprios dados)
E-books
Demos
Entre em contato com a Databricks para agendar uma demonstração e conversar sobre seus projetos de LLM e geração aumentada por recuperação (RAG)
O manual de IA agêntica para empresas

O futuro da tecnologia RAG
A RAG está evoluindo rapidamente de uma solução improvisada para um componente fundamental da arquitetura de AI corporativa. À medida que os LLMs se tornam mais capazes, o papel da RAG está mudando. Ela está deixando de apenas preencher lacunas de conhecimento para se tornar parte de sistemas estruturados, modulares e mais inteligentes.
Uma das formas de desenvolvimento da RAG é por meio de arquiteturas híbridas, em que a RAG é combinada com ferramentas, bancos de dados estruturados e agentes de chamada de função. Nesses sistemas, a RAG fornece fundamentação não estruturada, enquanto dados estruturados ou APIs lidam com tarefas mais precisas. Essas arquiteturas multimodais oferecem às organizações uma automação de ponta a ponta mais confiável.
Outro avanço importante é o cotreinamento de recuperador-gerador. Esse é um modelo em que o recuperador RAG e o gerador são treinados em conjunto para otimizar a qualidade das respostas um do outro. Isso pode reduzir a necessidade de engenharia de prompt manual ou ajuste fino, resultando em aprendizado adaptativo, menos alucinações e melhor desempenho geral de recuperadores e geradores.
À medida que as arquiteturas de LLM amadurecem, a RAG provavelmente se tornará mais integrada e contextual. Indo além de repositórios finitos de memória e informação, esses novos sistemas serão capazes de lidar com fluxos de dados em tempo real, raciocínio de múltiplos documentos e memória persistente, tornando-se assistentes experientes e confiáveis.
Perguntas frequentes (FAQ)
O que é geração aumentada por recuperação (RAG)?
A RAG é uma arquitetura de AI que reforça os LLMs ao recuperar documentos relevantes e inseri-los no prompt. Isso permite respostas mais precisas, atualizadas e específicas do domínio, sem a necessidade de gastar tempo para treinar novamente o modelo.
Quando devo usar a RAG em vez do ajuste fino?
Use a RAG quando quiser incorporar dados dinâmicos sem o custo ou a complexidade do ajuste fino. Ela é ideal para casos de uso que exigem informações precisas e atualizadas.
A RAG reduz as alucinações em LLMs?
Sim. Ao fundamentar a resposta do modelo em conteúdo recuperado e atualizado, a RAG reduz a probabilidade de alucinações. Esse é especialmente o caso em domínios que exigem alta precisão, como saúde, setor jurídico ou suporte corporativo.
De que tipo de dados a RAG precisa?
A RAG usa dados de texto não estruturados (como PDFs, e-mails e documentos internos) armazenados em um formato recuperável. Normalmente, eles são armazenados em um banco de dados vetorial, e os dados devem ser indexados e atualizados regularmente para manter a relevância.
Como avaliar um sistema de RAG?
Os sistemas de RAG são avaliados usando uma combinação de pontuação de relevância, verificações de fundamentação, avaliações humanas e métricas de desempenho específicas da tarefa. Mas, como vimos, as possibilidades de cotreinamento de recuperador-gerador podem facilitar a avaliação regular, à medida que os modelos aprendem e treinam uns aos outros.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.