O que é Aprendizado de Máquina Operacional?
Implantar modelos de aprendizado de máquina em produção para previsões em tempo real com dados ativos requer infraestrutura para disponibilização, monitoramento, re-treinamento e integração.
- Os padrões de implantação incluem APIs REST para previsões síncronas, pontuação em lote para inferência offline, implantação na borda em dispositivos e modelos incorporados em aplicativos, equilibrando latência, taxa de transferência e restrições de recursos.
- O monitoramento acompanha a precisão da previsão, as métricas de desempenho do modelo, a deriva de dados (detectando mudanças na distribuição), a deriva de conceito (identificando mudanças no relacionamento), a utilização de recursos e os KPIs de negócios (medindo o impacto do modelo).
- As práticas de MLOps abrangem pipelines de CI/CD para implantação de modelos, gatilhos de retreinamento automatizado, estruturas de teste A/B, implantações canary (minimizando riscos), recursos de reversão e procedimentos de resposta a incidentes para falhas do modelo.
Autor: Kevin Stumpf, cofundador e CTO
Em 2015, quando começamos a implantar a plataforma de machine learning da Uber, o Michelangelo, percebemos um padrão interessante: 80% dos modelos de ML lançados na plataforma alimentavam casos de uso de machine learning operacional, que impactam diretamente a experiência do usuário final, motoristas e passageiros da Uber. Apenas 20% eram casos de uso de machine learning analítico, voltados para apoiar a tomada de decisões analíticas.
A proporção entre ML operacional e ML analítico que observamos era exatamente o oposto de como a maioria das empresas aplicava ML na prática, em que o ML analítico predominava. Em retrospecto, a adoção massiva de ML operacional pela Uber não é nenhuma surpresa. O Michelangelo tornava extremamente fácil implementar ML operacional, e a empresa tinha uma longa lista de casos de uso de alto impacto. Hoje, sete anos depois, a dependência da Uber em ML operacional só aumentou. Sem ele, você veria preços de viagens inviáveis, previsões de tempo de chegada imprecisas e centenas de milhões de dólares perdidos em fraudes. Em resumo, sem ML operacional, a empresa simplesmente pararia.
O ML operacional tem sido fundamental para o sucesso da Uber e, por muito tempo, parecia algo que apenas gigantes da tecnologia conseguiam realizar. A boa notícia é que muita coisa mudou nos últimos sete anos. Hoje existem novas tecnologias e tendências que permitem que qualquer empresa deixe de usar predominantemente ML analítico e passe a usar ML operacional, e temos algumas recomendações para quem quer fazer essa transição. Vamos começar.
ML operacional vs. ML analítico
Machine learning operacional ocorre quando uma aplicação usa um modelo de ML para tomar decisões de forma autônoma e contínua, impactando o negócio em tempo real. Essas aplicações são de missão crítica e operam “online”, em produção, dentro da pilha operacional da empresa.
Exemplos comuns incluem sistemas de recomendação, ranqueamento de busca, precificação dinâmica, detecção de fraude e aprovação de solicitações de crédito.
O parente mais antigo do ML operacional, no mundo “offline��”, é o machine learning analítico. Essas aplicações ajudam usuários de negócio a tomar decisões melhores com base em machine learning. Aplicações de ML analítico fazem parte da pilha analítica da empresa e normalmente alimentam diretamente relatórios, painéis de controle e ferramentas de business intelligence.
Exemplos comuns incluem previsão de vendas, previsões de churn e segmentação de clientes.
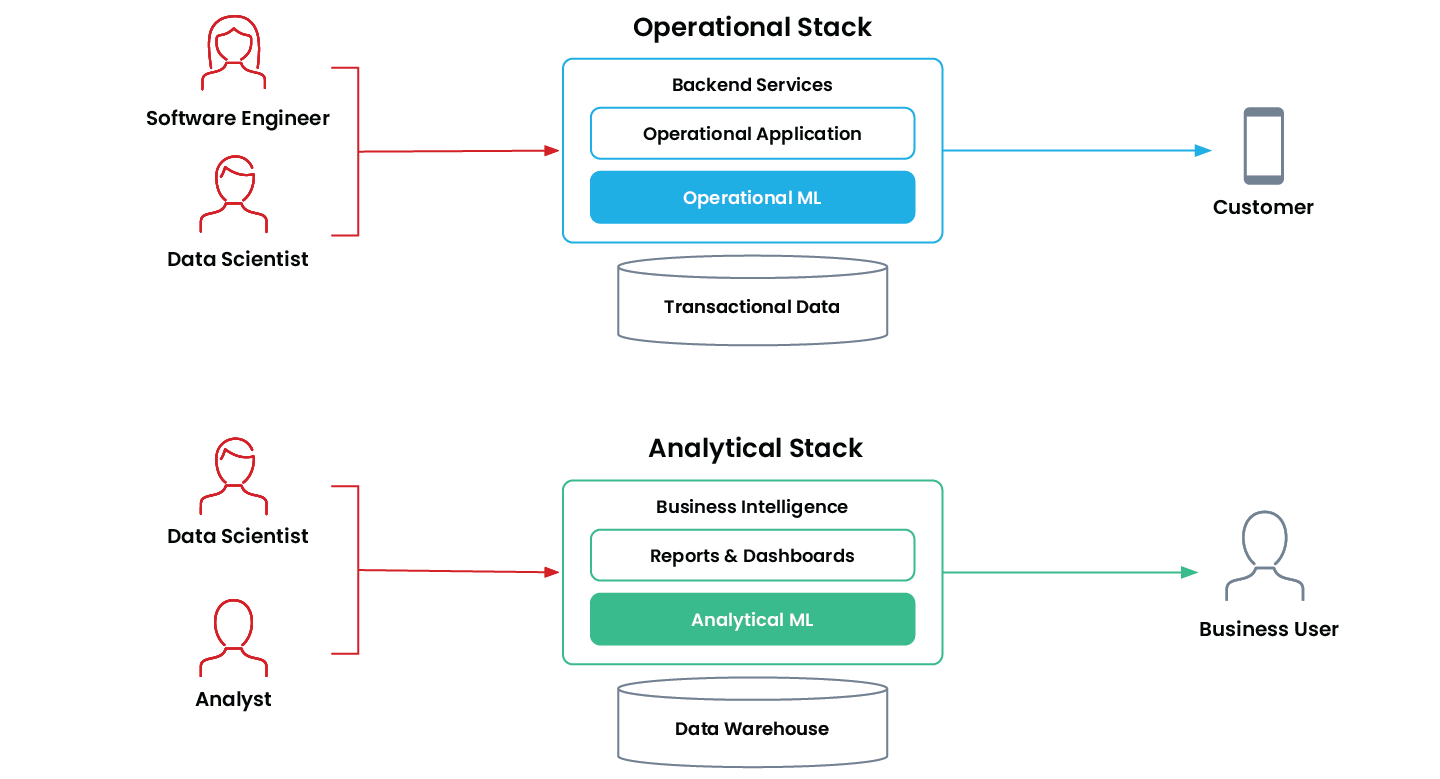
As organizações usam ML operacional e ML analítico para finalidades diferentes, e cada um tem requisitos técnicos distintos.
| ML analítico | ML Operacional | |
|---|---|---|
| Automação de decisões | Intervenção humana no processo | Totalmente autônomo |
| Velocidade de decisão | Velocidade humana | Tempo real |
| Otimizado para | Processamento em lote em grande escala | Baixa latência e alta disponibilidade |
| Público-alvo principal | Usuário interno de negócios | Cliente |
| Alimenta | Relatórios e dashboards | Aplicações em produção |
| Exemplos | Previsão de vendas Pontuação de leads Segmentação de clientes Previsões de churn | Recomendações de produtos Detecção de fraude Previsão de tráfego Preços em tempo real |
Características do ML analítico em comparação com o ML operacional
Machine Learning Operacional na Prática
Vamos analisar de forma mais concreta um exemplo real de machine learning operacional do Uber Eats. Quando você abre o app, ele recomenda uma lista de restaurantes e sugere quanto tempo levará até o pedido chegar à sua porta. O que parece simples no aplicativo é, na verdade, bastante complexo nos bastidores.
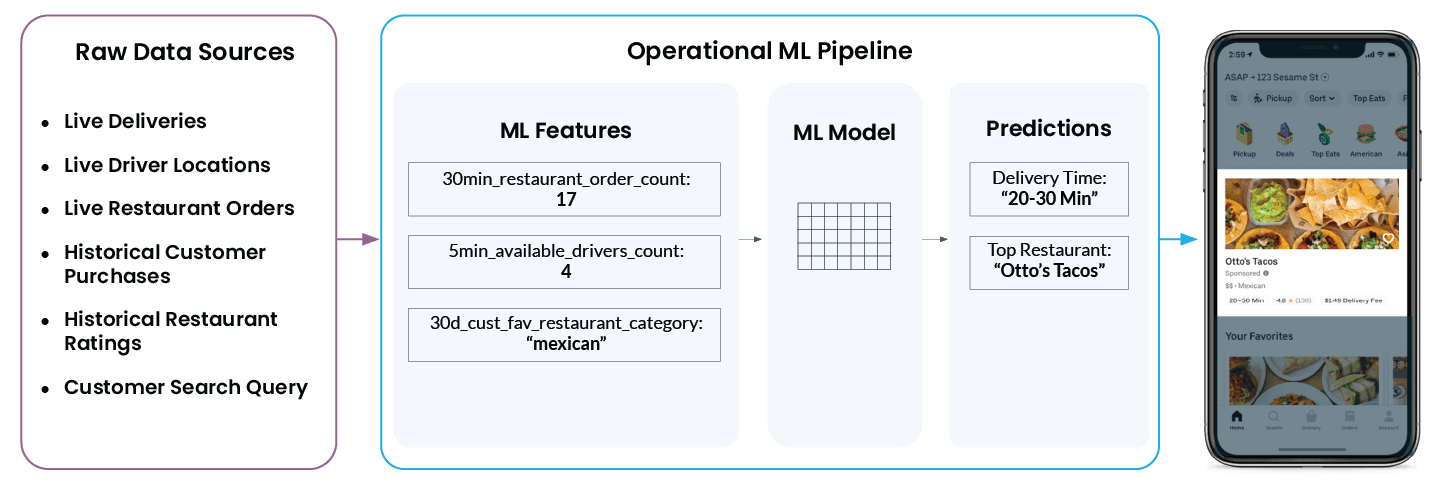
Para exibir “Otto’s Tacos” e “20–30 min” no app, a plataforma de ML da Uber precisa analisar uma ampla variedade de dados provenientes de diferentes fontes de dados brutos:
- Quantos motoristas estão na região do restaurante neste momento? Eles estão fazendo uma entrega ou disponíveis para o próximo envio?
- Quão ocupada está a cozinha do restaurante agora? Quanto mais pedidos o restaurante estiver processando, mais tempo levará para começar a preparar um novo pedido.
- Quais restaurantes o cliente avaliou bem ou mal no passado?
- Que tipo de culinária, se houver, o usuário está buscando ativamente no momento?
- E... qual é a localização atual do usuário?
A plataforma de recursos do Michelangelo converte esses dados em recursos de ML. Esses recursos são os sinais com os quais um modelo é treinado e que ele usa para fazer previsões em tempo real. Por exemplo, "num_orders_last_30_min" é usada como uma recurso de entrada para prever o tempo de entrega, que eventualmente será exibido no aplicativo móvel.
As etapas descritas acima, que transformam dados brutos de inúmeras fontes em recursos e recursos em previsões, são comuns a todos os casos de uso de machine learning operacional. Seja para detectar fraude em cartão de crédito, prever a taxa de juros de um financiamento de veículo, sugerir um artigo na seção de assuntos internacionais de um jornal ou recomendar o melhor brinquedo para uma criança de dois anos, os desafios técnicos são os mesmos. E é justamente essa base técnica comum que nos permitiu criar uma única plataforma central para todos os casos de uso de ML operacional.
O manual de IA agêntica para empresas

As tendências que viabilizam o machine learning operacional
A Uber estava bem posicionada para aproveitar o ML operacional porque construiu toda a sua pilha tecnológica com base em uma arquitetura de dados moderna e em princípios modernos. Nos últimos anos, vimos uma modernização semelhante acontecer muito além do Vale do Silício.
Dados históricos são preservados por períodos praticamente indefinidos.
Os custos de armazenamento de dados caíram drasticamente nos últimos anos. Como resultado, as empresas passaram a conseguir coletar, comprar e armazenar informações sobre cada ponto de contato com os clientes. Isso é essencial para ML. Treinar um bom modelo exige uma grande quantidade de dados históricos. E sem dados, não existe machine learning.
Os silos de dados estão sendo desfeitos
Desde o primeiro dia, a Uber centralizou praticamente todos os seus dados no sistema de arquivos distribuído baseado em Hive. O armazenamento de dados centralizado (ou, como alternativa, o acesso centralizado a repositórios de dados descentralizados) é importante porque permite que cientistas de dados, que treinam modelos de ML, saibam quais dados estão disponíveis, onde encontrá-los e como acessá-los. A maioria das empresas ainda não centralizou totalmente todos os seus dados (ou o acesso a eles). No entanto, tendências de arquitetura como o Modern Data Stack vêm trazendo o sonho do cientista de dados de acesso democratizado a dados muito mais para o centro da realidade.
Os dados em tempo real ficam disponíveis com streaming
Na Uber, tivemos a sorte de ter um “sistema nervoso central” para fluxos de dados: o Kafka. Muitos sinais em tempo real de serviços e apps móveis são transmitidos por streaming via Kafka. Isso é essencial para ML operacional.
Você não consegue detectar fraudes se só souber o que aconteceu ontem. Você precisa saber o que aconteceu nos últimos 30 segundos. Data warehouses e data lakes são projetados para armazenamento de longo prazo de dados históricos. E, nos últimos anos, vimos uma adoção enorme de infraestrutura de streaming, como Kafka ou Kinesis, para fornecer sinais em tempo real às aplicações.
MLOps permite iteração rápida
Na Uber, engenheiros individuais têm autonomia para fazer mudanças diárias no sistema em produção. Esse processo é apoiado pela adoção e automação de princípios de DevOps. Com o Michelangelo, levamos esses princípios ao ML operacional antes mesmo de o processo ser chamado de MLOps 🙂. Para nós, era importante que cientistas de dados conseguissem treinar modelos e implantá-los com segurança em produção literalmente em um único dia.
Fora da Uber e muito além do Vale do Silício, vimos um número crescente de adotantes iniciais levando princípios e automação de DevOps não apenas para a engenharia de software, mas também para as equipes de ciência de dados, por meio de MLOps. É claro que, para a maioria das empresas, ML ainda é muito mais doloroso do que software, pelos motivos que descrevi neste blog. Mas estou convencido de que o setor avança de forma constante rumo a um futuro em que o cientista de dados típico de uma organização típica da Fortune 500 consegue iterar em um modelo de ML operacional várias vezes ao dia.
Veja como é uma arquitetura de dados moderna que viabiliza ML operacional:
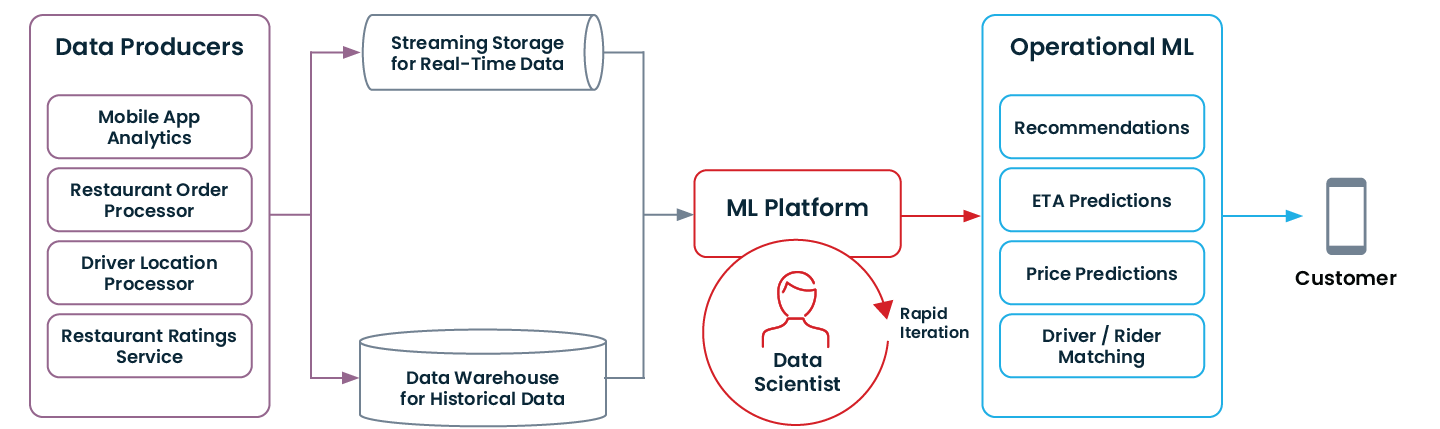
Se a sua organização passou por algumas das modernizações mencionadas acima (ou começou com elas do zero!), talvez você já esteja pronta para começar com ML operacional.
Começar com ML operacional
Em 2013, a Uber não usava machine learning em produção. Hoje, a empresa executa dezenas de milhares de modelos em produção. Essa mudança não aconteceu da noite para o dia.
Se você quer aproveitar ML operacional na sua organização, recomendo seguir as etapas abaixo:
Escolha um caso de uso adequado para machine learning
Nem todos os problemas podem ser resolvidos com ML. Indicadores de que um problema pode ser bem adequado para ML:
- Seu sistema toma muitas decisões muito semelhantes e repetidas (pelo menos dezenas de milhares)
- Tomar a decisão certa não
- Algum tempo depois de a decisão ser tomada, existe uma forma de determinar se ela foi uma decisão boa ou ruim
Se esses elementos forem verdadeiros, uma aplicação de machine learning pode tomar decisões, aprender com essas decisões e melhorar continuamente.
Escolha um caso de uso que realmente importe
Como mencionado anteriormente, o caminho para colocar o primeiro modelo em produção é difícil. Se o retorno futuro da sua primeira aplicação de machine learning não for muito promissor, será fácil demais desistir quando as coisas ficarem difíceis. As prioridades mudam, a liderança pode perder a paciência, e o esforço não se sustenta. Escolha um caso de uso com alto potencial.
Capacite uma equipe pequena e minimize as partes interessadas para o seu primeiro modelo
A probabilidade de falha de um projeto aumenta com o número de transferências envolvidas no treinamento e na implantação de um modelo. O ideal é começar com uma equipe muito pequena, de duas a três pessoas, que tenha acesso a todos os dados necessários, saiba treinar um modelo simples e esteja suficientemente familiarizada com o stack de produção para colocar uma aplicação em produção.
Engenheiros de ML são os mais indicados para abrir esse caminho, já que normalmente combinam, de forma rara, habilidades de engenharia de dados, engenharia de software e ciência de dados. É assim também que você deve escalar equipes de machine learning, com pequenos grupos de especialistas em ML incorporados às equipes de produto.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.