Governança unificada e aberta para dados e IA
Elimine silos, simplifique a governança e acelere as percepções em escala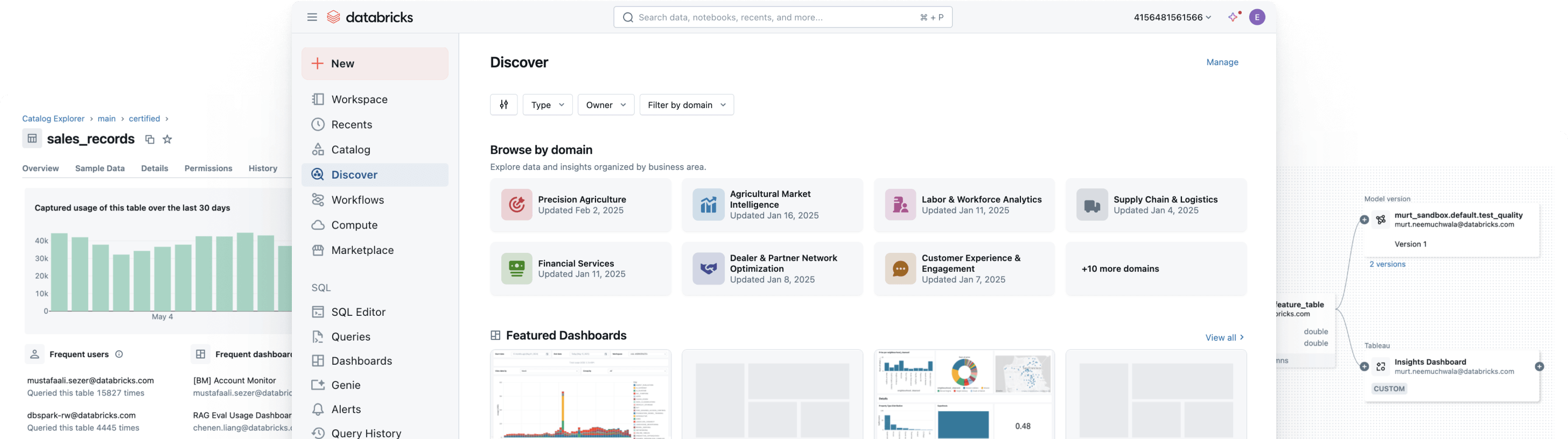
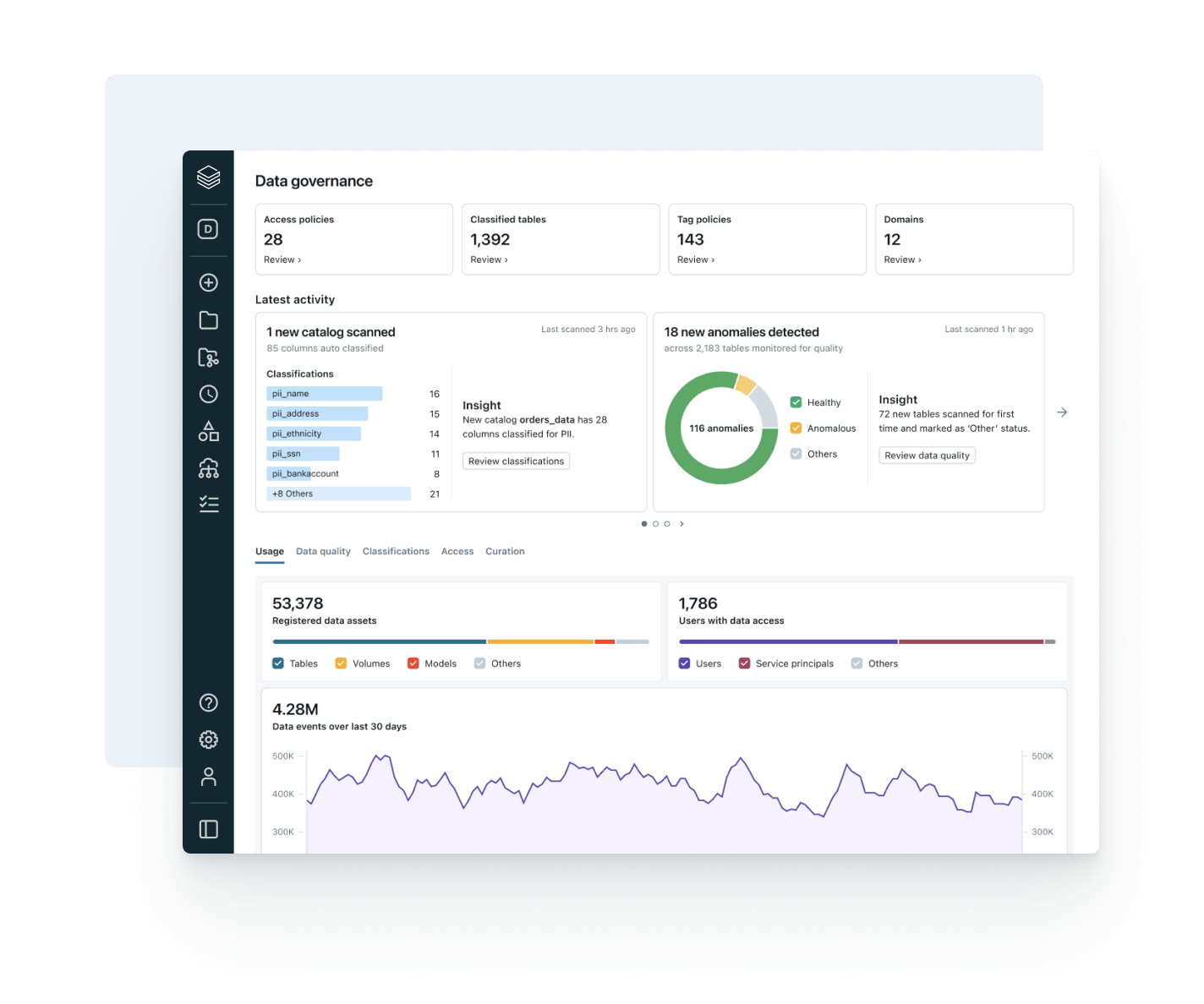
EQUIPES DE MELHOR DESEMPENHO USAM A GOVERNANÇA UNIFICADA E ABERTAGoverne, descubra, monitore e compartilhe, tudo num só lugar
Unifique seu cenário de dados, simplifique a compliance e gere percepções mais rápidas e confiáveis com governança aberta e inteligente em dados e AIGovernança unificada
Implemente controles consistentes de descoberta, acesso, monitoramento de qualidade e compliance em dados estruturados e não estruturados, modelos de ML e métricas de negócios — em qualquer cloud. Com a governança unificada, é possível reduzir riscos, simplificar auditorias e acelerar o acesso aos dados sem comprometer o controle.
Aberta
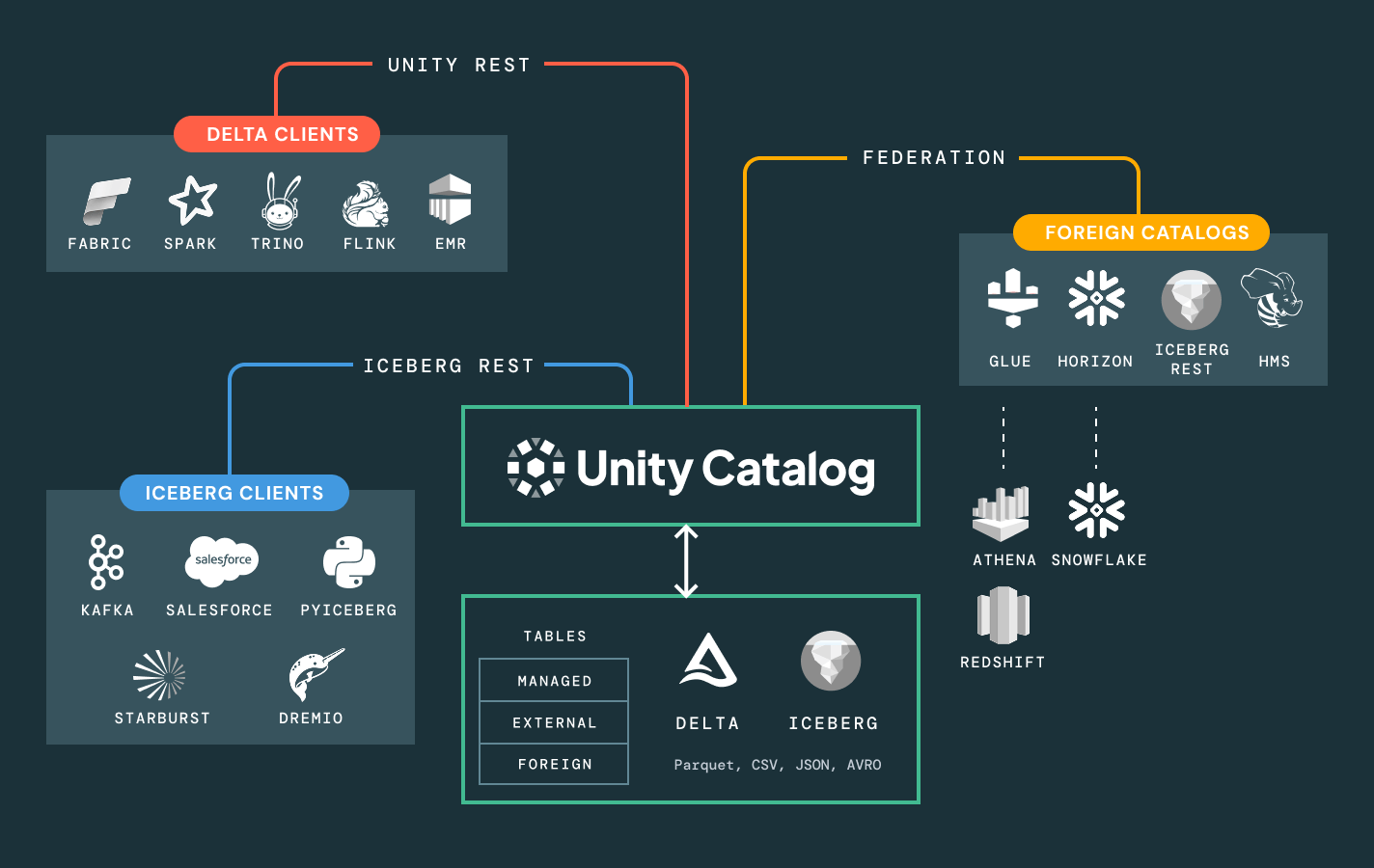
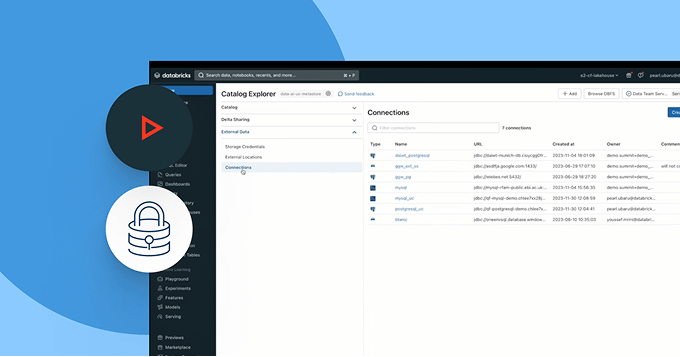
Liberte-se do aprisionamento a plataformas. Aproveite qualquer formato aberto de lakehouse (Delta, Apache Iceberg™, Hudi, Parquet) de sua escolha, conecte-se a fontes de dados externas sem migração e integre-se às suas ferramentas existentes de BI, IA e catálogo por meio de APIs abertas. Seja compartilhando dados internamente ou com parceiros, garanta que a colaboração seja segura, escalável e baseada em padrões abertos.
Inteligência integrada
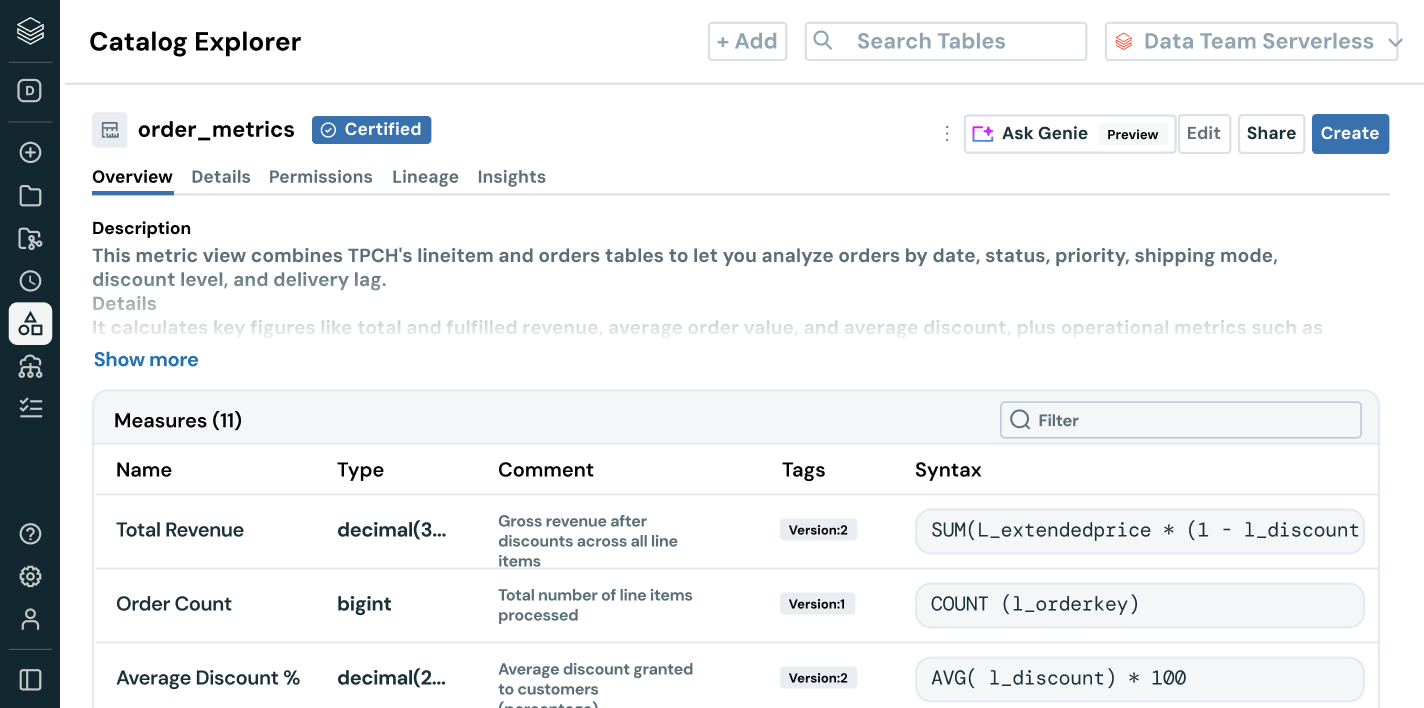
Vá além do descobrimento de dados e do gerenciamento de acesso, capacitando os usuários com o contexto de negócios. Com linhagem integrada, percepções de uso e semântica empresarial, os usuários podem localizar, compreender e explorar dados mais rapidamente. A documentação com tecnologia de AI, a pesquisa em linguagem natural e os espaços de conversação ajudam os usuários técnicos e empresariais a passar dos dados à decisão, mais rapidamente e com todo o contexto empresarial.
Governança inteligente integrada
Simplifique a descoberta, a compliance e o monitoramento em todo o seu patrimônio de dados e AI com governança inteligenteCatálogo unificado para todos os dados estruturados, dados não estruturados, métricas de negócios e modelos de AI em formatos de dados abertos como Delta Lake, Apache Iceberg, Hudi, Parquet e muito mais.

Mais recursos
Desbloqueie todo o valor de negócios dos dados com governança unificada
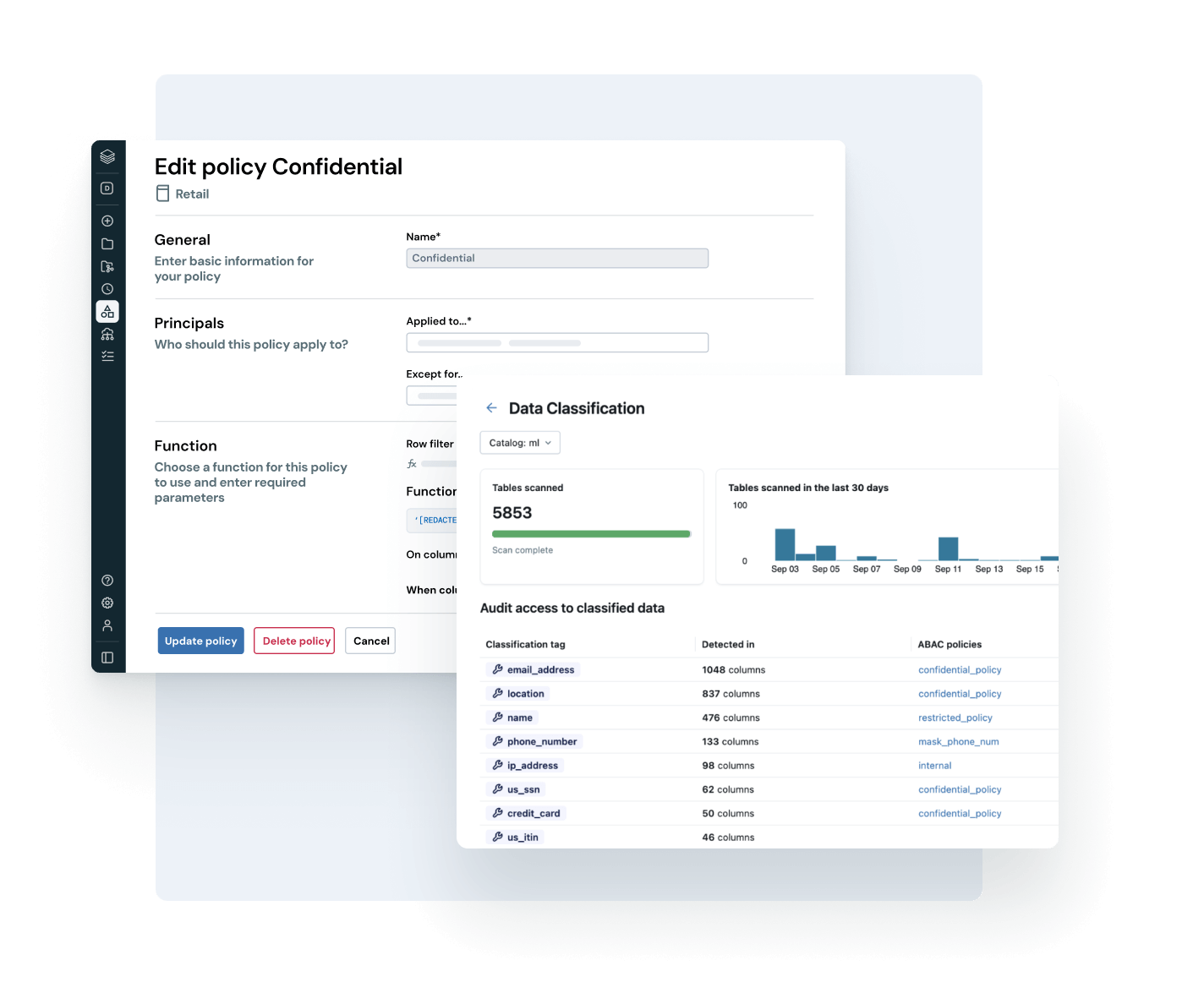
Capacite cada usuário a encontrar, confiar e usar os dados corretos
Torne seus dados ativos mais valiosos fáceis de encontrar e entender – em toda a empresa.
- A descoberta auto-curada destaca ativos de dados confiáveis e de alto impacto
- Documentação, tags e percepções com tecnologia de AI adicionam contexto rico
- A semântica de negócios governada proporciona métricas consistentes e confiáveis entre equipes e ferramentas
- A interface conversacional com o AI/BI Genie auxilia os usuários empresariais a explorar dados sem a necessidade de SQL.
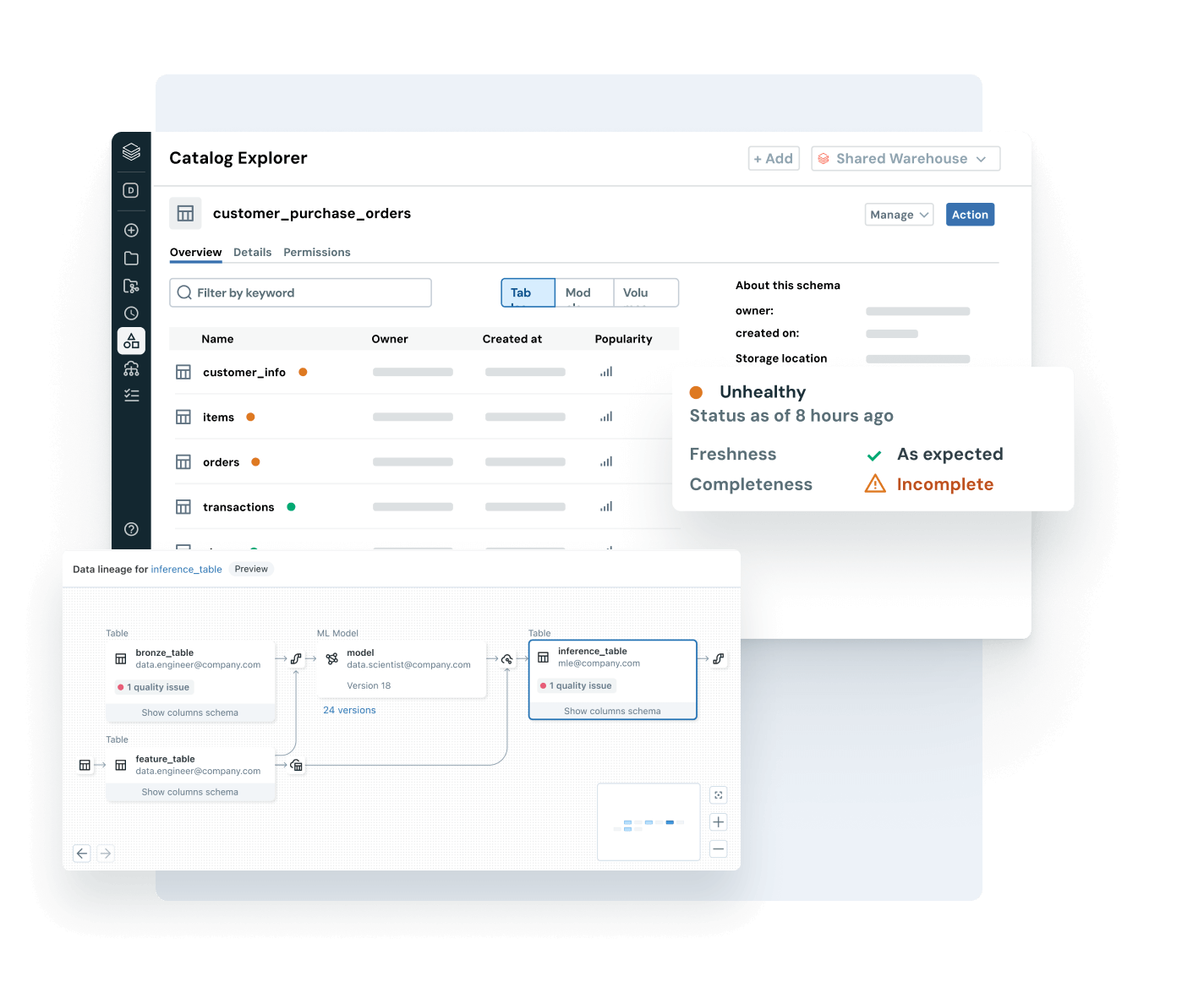
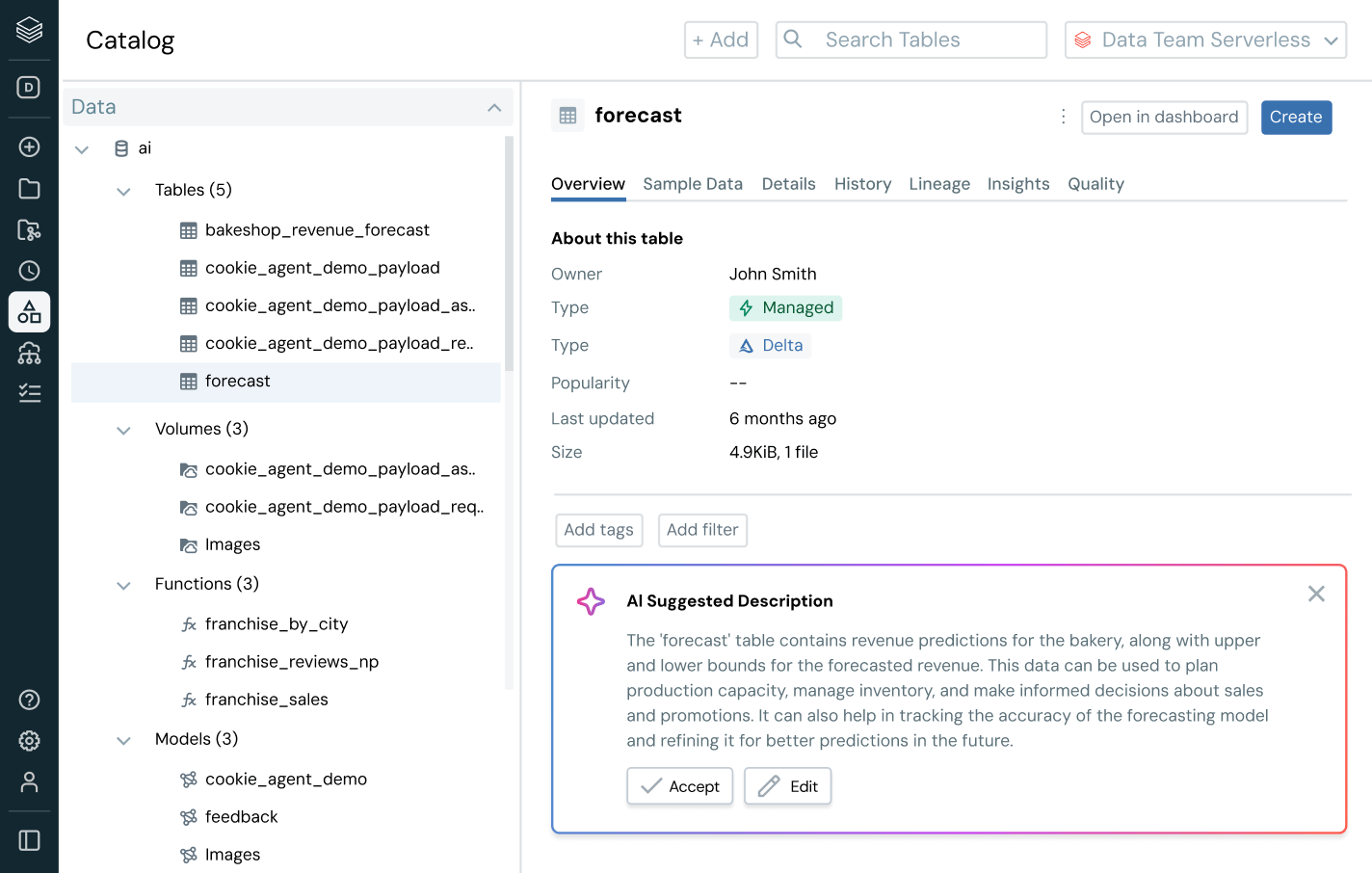
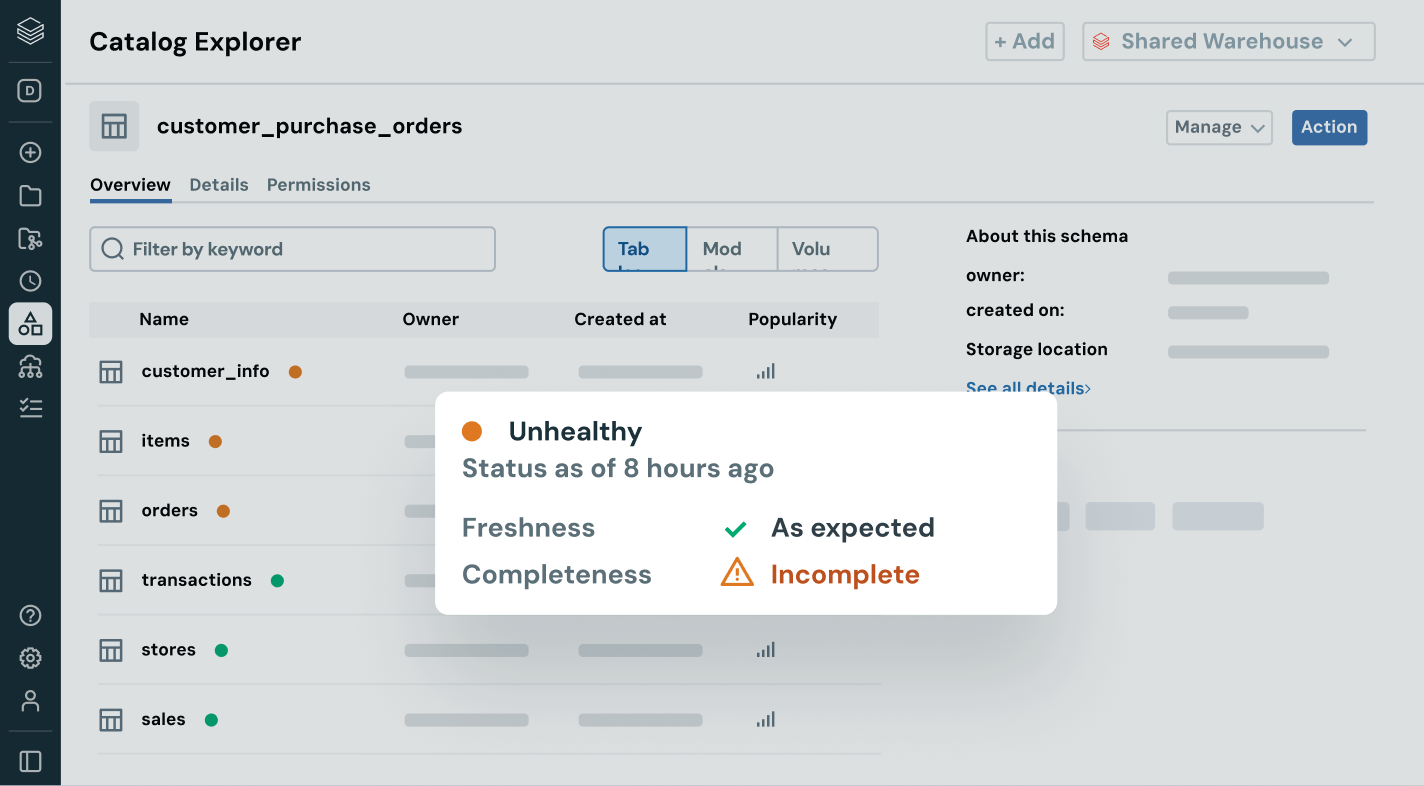
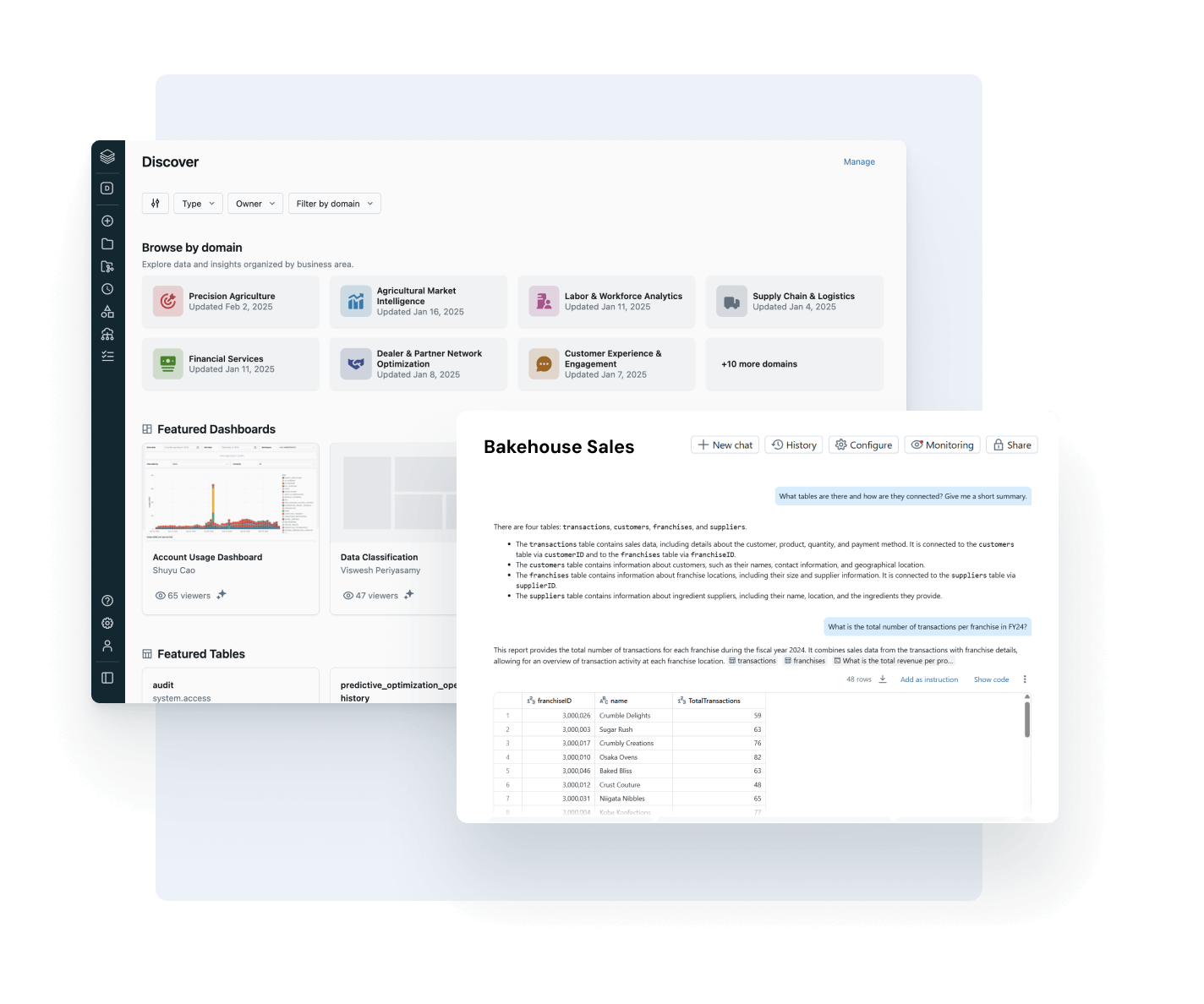
Certifique-se de que os dados em que você confia sejam atualizados, completos e confiáveis.
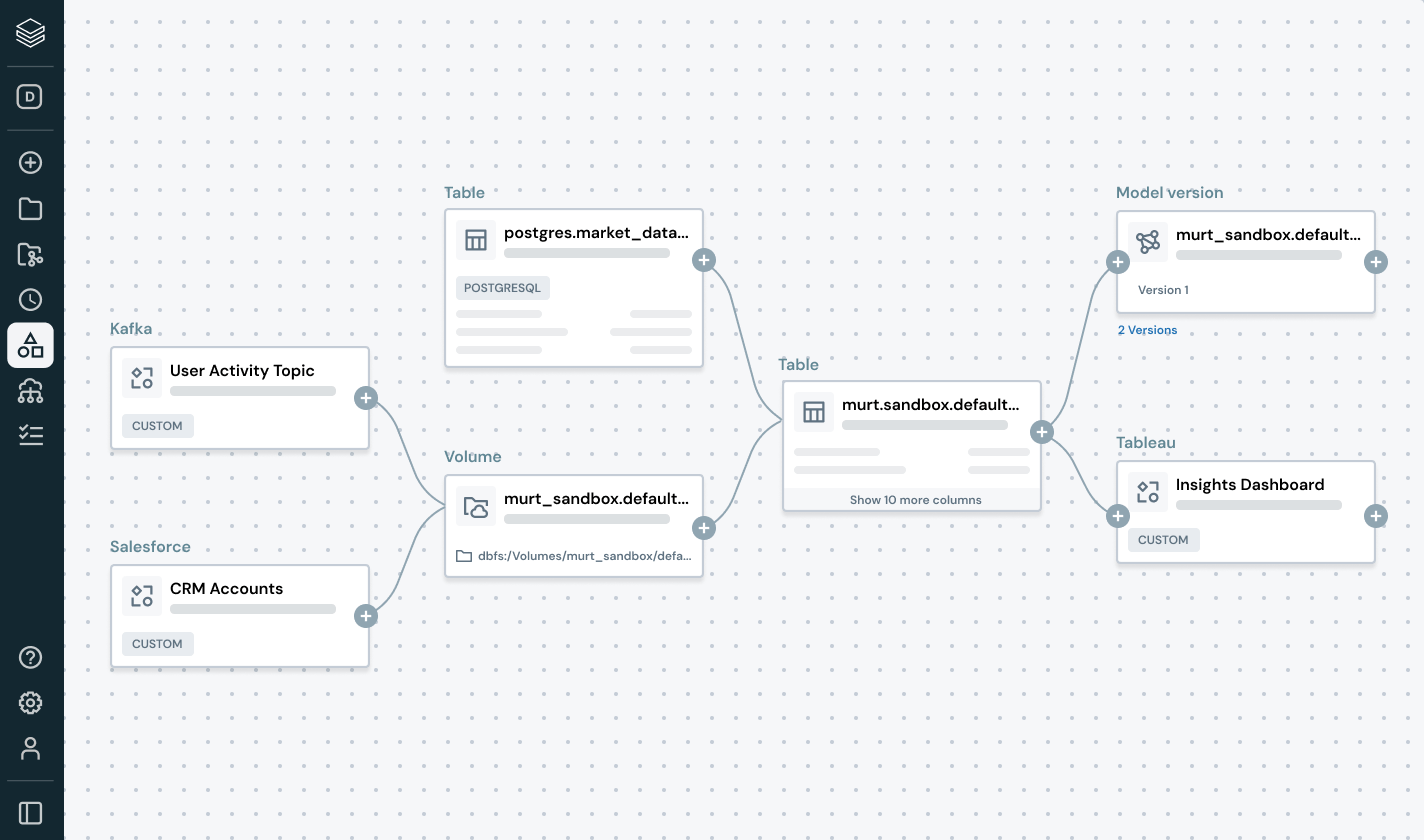
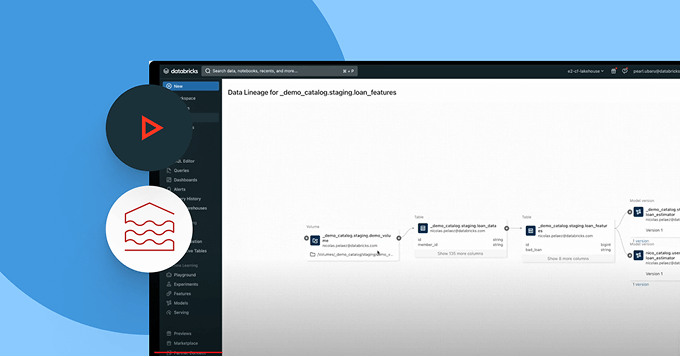
Detecte e resolva proativamente problemas de dados com visibilidade completa sobre os sinais de linhagem e qualidade.
- Monitore a integridade dos dados com atualização, integridade e detecção de anomalias
- Rastreie a linhagem de ponta a ponta em pipelines, modelos e dashboards
- Avalie o impacto downstream de dados quebrados e pipelines de AI
- Fortaleça a confiança ao expor percepções de qualidade ao lado de cada ativo
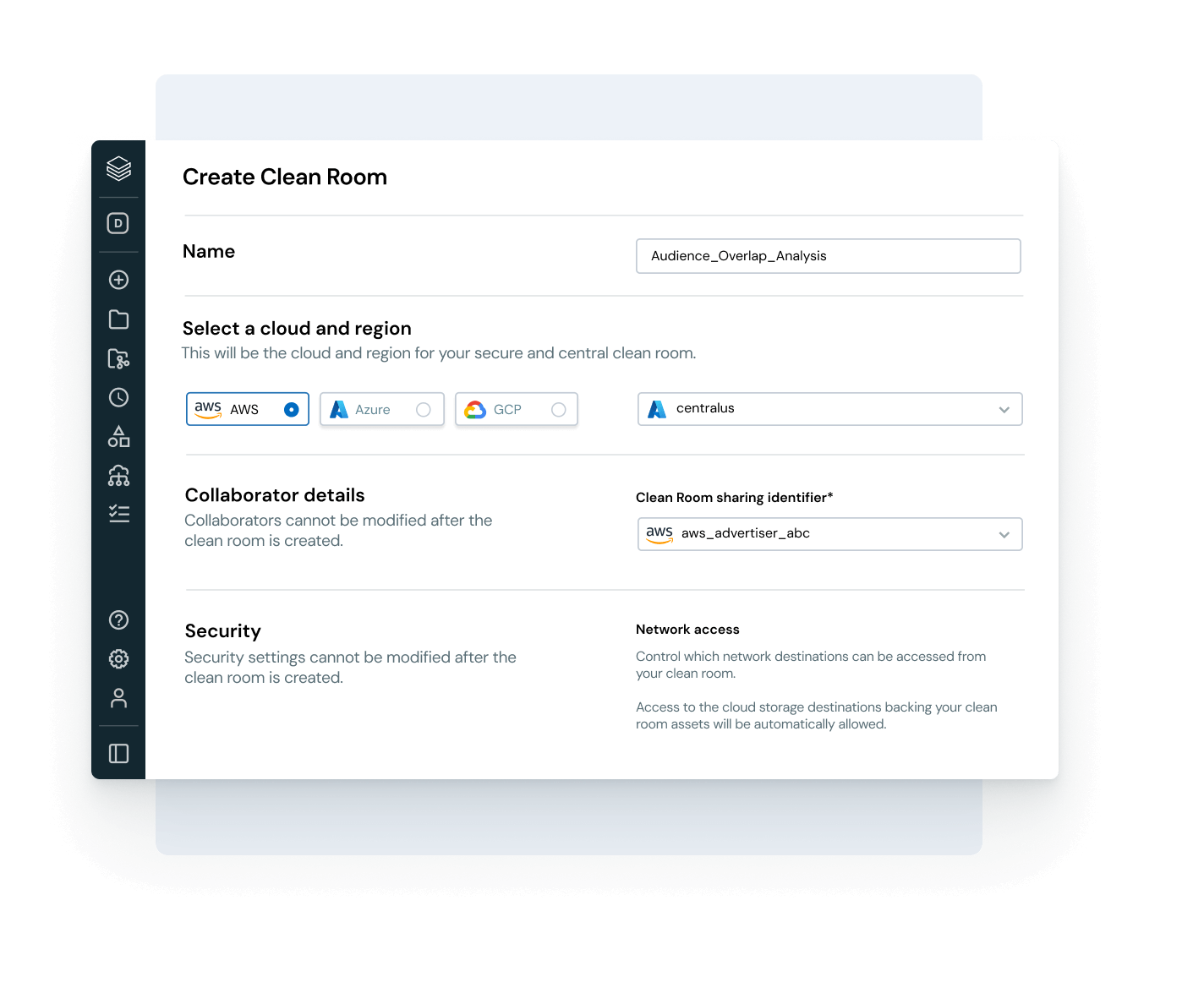
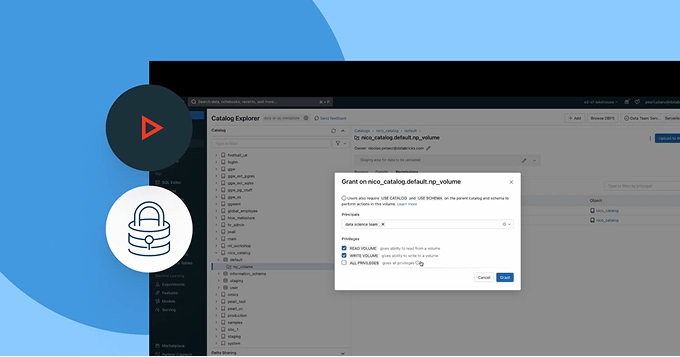
Permita uma colaboração segura e aberta entre clouds e parceiros
Rompa os silos e amplie a escala do compartilhamento de dados e AI, com controle total de governança.
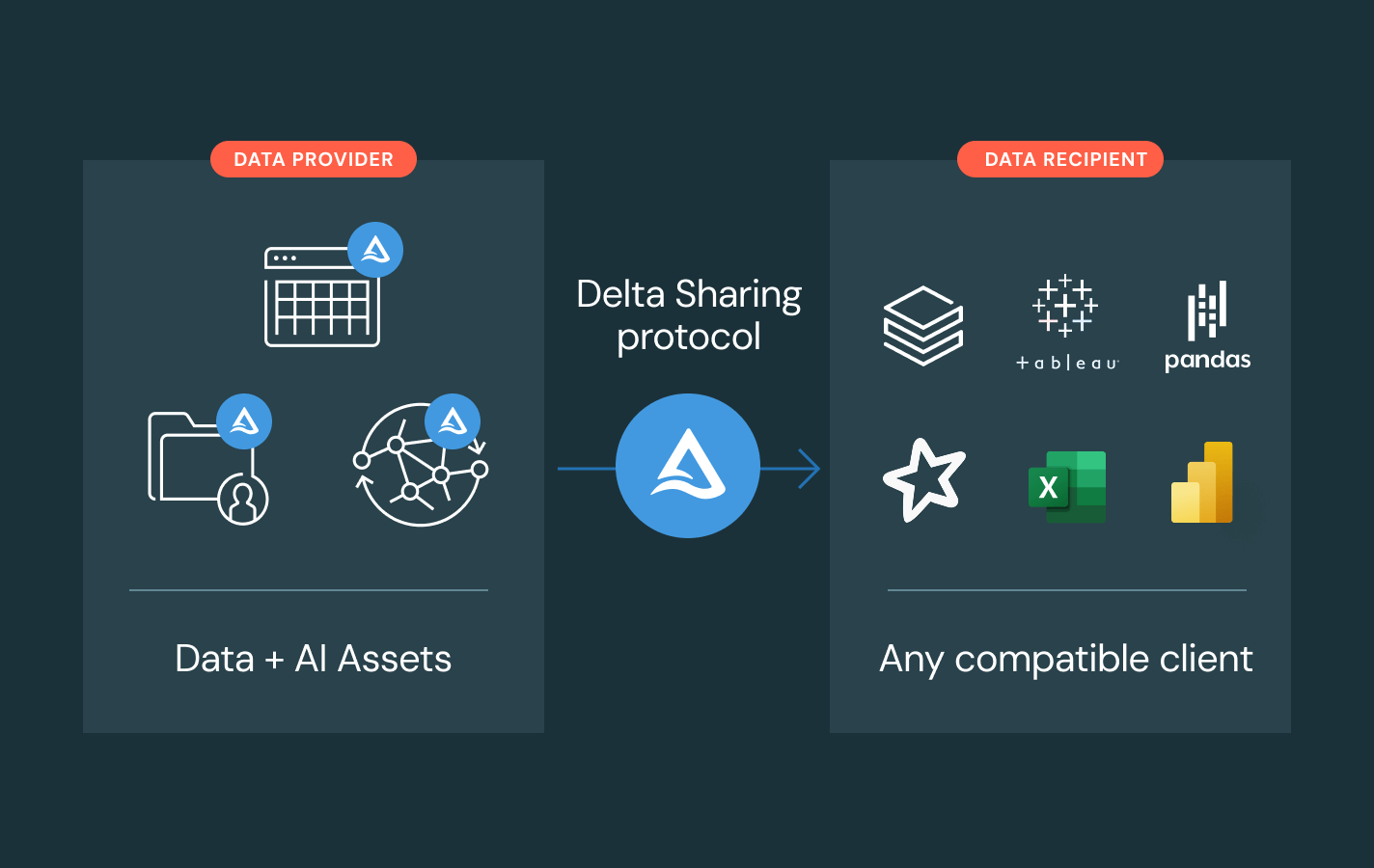
- Compartilhe dados governados e ativos de AI entre equipes, clouds ou parceiros usando o Delta Sharing
- Use Clean Rooms para colaboração segura e preservação da privacidade
- Evite a dependência do fornecedor com padrões de compartilhamento abertos
Alinhe o uso de dados com o valor de negócios e o custo operacional
Use a observabilidade integrada para otimizar os gastos, impulsionar a adoção da governança e aumentar o ROI.
- Acompanhe as tendências de consumo de dados entre usuários, equipes e unidades de negócios.
- Vincule a linhagem ao uso de compute e armazenamento para identificar alavancas de otimização
- Monitore a adoção de políticas e padrões de acesso a dados em uma única interface de usuário
- Permita que os donos do produto de dados meçam e relatem o valor dos dados
Explore as demonstrações do Unity Catalog

Descubra mais
Explore produtos que expandem o poder do Unity Catalog em governança, colaboração e inteligência de dados.
Databricks Clean Rooms
Analise dados compartilhados de várias partes sem conceder acesso direto aos dados brutos.

Databricks Marketplace
Um mercado aberto para dados, bem como ativos de AI e análise, como modelos ML e notebooks.

Delta Sharing
Uma abordagem de código aberto para o compartilhamento de dados e AI entre plataformas. Compartilhe dados em tempo real com governança centralizada e sem replicação.

AI/BI Genie
Uma experiência de conversação, impulsionada por AI generativa, para que as equipes de negócios explorem dados e obtenham percepções em tempo real por meio de linguagem natural.

Databricks Assistant
Descreva sua tarefa em linguagem natural e deixe o assistente gerar queries SQL, explicar códigos complexos e corrigir erros automaticamente.
Plataforma de inteligência de dados Databricks
Aproveite a grande variedade de ferramentas disponíveis na Databricks Data Intelligence Platform para integrar dados e AI em toda a sua organização.
Dê um passo adiante
Explore a documentação do Unity Catalog
Obtenha orientações detalhadas sobre recursos, configuração e práticas recomendadas na documentação do Unity Catalog para AWS, Azure e GCP.
Explorar demonstrações de produtos
Assista às demonstrações do Unity Catalog para ver como você pode governar, descobrir e compartilhar dados e ativos de AI em todo o seu ambiente.




Perguntas frequentes do Unity Catalog
Pronto para se tornar uma empresa de dados + AI?
Dê os primeiros passos na transformação dos seus dados