Construa ETL de Produção com Pipelines Declarativos Lakeflow
Projetada para análises modernas e cargas de trabalho de IA, esta arquitetura de referência fornece uma base robusta e escalável para construir e automatizar pipelines de extração, transformação e carregamento (ETL) em dados em lote e em streaming.
Resumo da Arquitetura
Esta arquitetura de referência é bem adequada para organizações que procuram unificar pipelines de lote e streaming sob um único framework declarativo, garantindo a confiabilidade, qualidade e governança dos dados em todas as etapas. Ele aproveita a Plataforma de Inteligência de Dados Databricks para simplificar o gerenciamento de pipeline, impor expectativas de dados e fornecer insights em tempo real com observabilidade e automação integradas.
Ela suporta uma ampla gama de cenários de engenharia e análise de dados, desde a ingestão e transformação de dados até fluxos de trabalho complexos com verificações de qualidade em tempo real, lógica de negócios e recuperação automática. Organizações que adotam essa arquitetura geralmente buscam modernizar o ETL legado, reduzir a sobrecarga operacional e acelerar a entrega de dados curados e de alta qualidade para inteligência de negócios, aprendizado de máquina e aplicações operacionais.
Casos de Uso Técnicos
- Esta arquitetura permite pipelines de captura de dados de alteração (CDC) que aplicam incrementalmente atualizações dos sistemas de origem no lakehouse
- Engenheiros de dados podem construir padrões de dimensão que mudam lentamente (SCD) para gerenciar modelos dimensionais em camadas analíticas
- Pipelines de streaming podem ser construídos de forma resiliente para lidar com eventos fora de ordem e dados que chegam atrasados com marcas d'água e pontos de verificação
- Engenheiros de dados podem impor a evolução do esquema e regras de qualidade automatizadas usando restrições declarativas
- Engenheiros de dados podem automatizar o rastreamento de linhagem de dados e registro de auditoria em todo o pipeline sem instrumentação manual
Casos de Uso de Negócios
- Empresas de varejo e bens de consumo embalados (CPG) podem usar essa arquitetura para construir painéis em tempo real que rastreiam vendas, estoque e comportamento do cliente em vários canais
- Ao integrar dados de transações, interações digitais e sistemas de CRM, instituições financeiras podem apoiar a detecção de fraudes e a segmentação de clientes
- Organizações de saúde podem processar e normalizar dados de dispositivos médicos e registros de pacientes para insights clínicos e relatórios de conformidade
- Fabricantes podem combinar dados de sensores IoT com logs históricos para impulsionar a manutenção preditiva e a otimização da cadeia de suprimentos
- Provedores de telecomunicações podem unificar dados de CRM e telemetria de rede para modelar a rotatividade de clientes e padrões de uso em tempo quase real
Capacidades Chave
- Desenvolvimento de Pipelines Declarativos: Defina pipelines usando SQL ou Python, abstraindo a lógica de orquestração
- Suporte a lotes e streaming: Lide com cargas de trabalho em tempo real e programadas em um framework unificado
- Aplicação de qualidade de dados: Aplique expectativas diretamente no pipeline para detectar, bloquear ou quarentenar dados ruins
- Observabilidade e linhagem: Monitoramento integrado, alertas e rastreamento visual de linhagem melhoram a transparência e a resolução de problemas
- Tratamento e recuperação de erros: Detecte e recupere automaticamente falhas em qualquer estágio do pipeline
- Governança com o Catálogo Unity: Aplique controles de acesso refinados, audite o uso de dados e mantenha a classificação de dados em toda a pilha
- Execução otimizada: Aproveite o Spark e o Photon para processamento escalável e de alto desempenho
- Operações automatizadas: Pipelines podem ser versionados, implantados e gerenciados por meio de CI/CD, com suporte para agendamento e parametrização
Fluxo de Dados
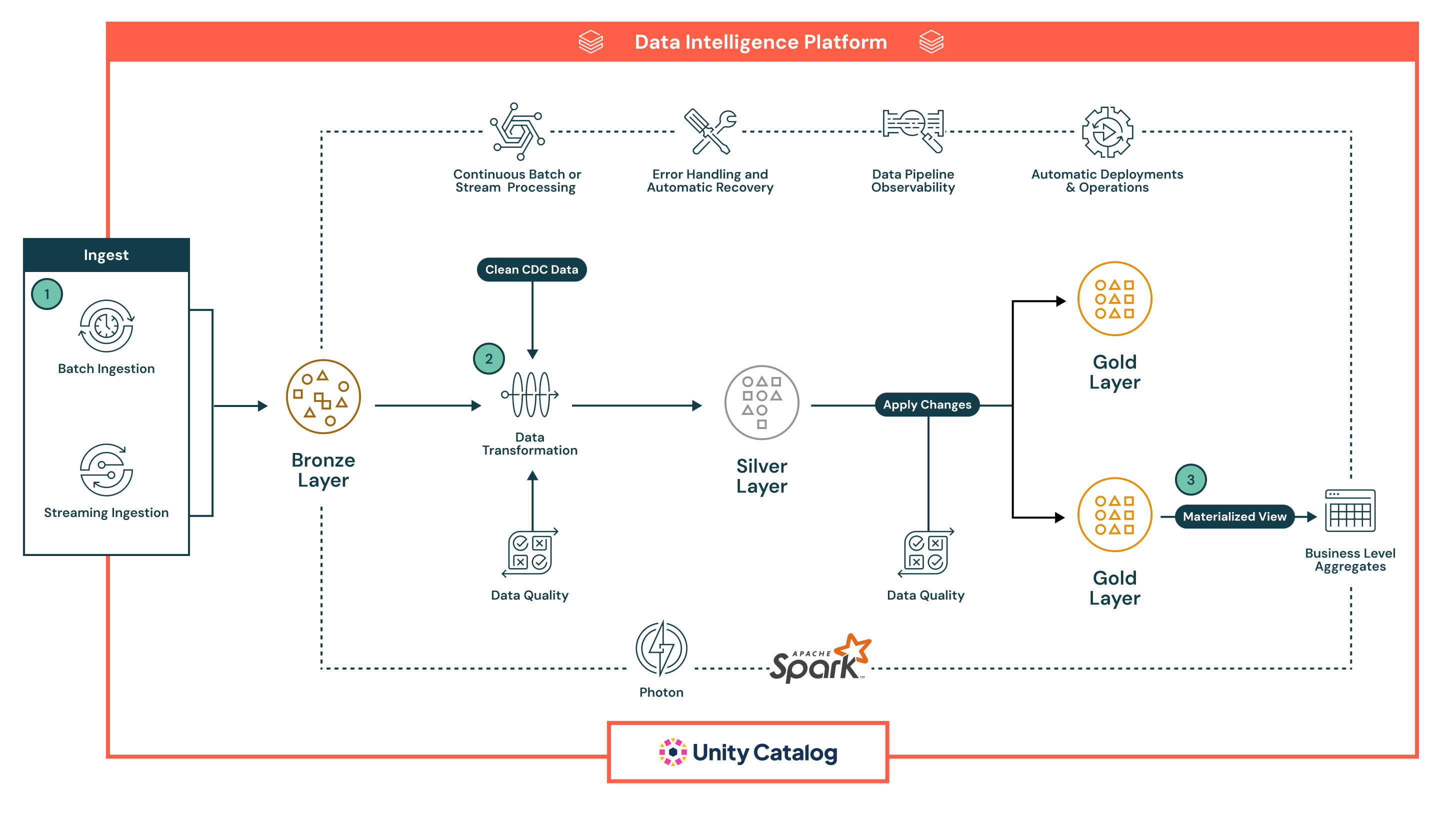
A arquitetura segue uma robusta arquitetura de medalhão multicamadas, aprimorada pelas capacidades integradas de automação, governança e confiabilidade dos Declarative Pipelines do Lakeflow. Cada fase do pipeline é declarativa, observável e otimizada para casos de uso de lote e streaming:
- O Lakeflow’s Declarative Pipelines suporta tanto a ingestão em lote quanto em streaming, fornecendo uma maneira unificada e automatizada de trazer dados para o lakehouse.
- A ingestão em lote carrega dados em um cronograma ou gatilho, ideal para fluxos de trabalho ETL periódicos. Ele suporta cargas completas e incrementais de armazenamento em nuvem e bancos de dados. Ao contrário das ferramentas tradicionais, o declarativo gerencia a orquestração, as tentativas e a evolução do esquema de forma nativa, reduzindo a necessidade de agendadores externos ou scripts.
- A ingestão em streaming processa continuamente dados de fontes como Kafka e Event Hubs usando Structured Streaming. Declarative Pipelines lida com pontos de verificação, gerenciamento de estado e escalonamento automático, eliminando a configuração manual normalmente necessária em pipelines de streaming.
Todos os dados chegam primeiro na camada Bronze em forma bruta, permitindo linhagem completa, rastreabilidade e reprocessamento seguro. A abordagem declarativa dos pipelines, verificações de qualidade integradas e gerenciamento automático de infraestrutura reduzem significativamente a complexidade operacional e facilitam a construção de pipelines resilientes e de qualidade de produção - algo que a maioria das ferramentas ETL legadas luta para entregar nativamente.
- Após a ingestão, os dados podem ser processados na Camada Prata, onde são limpos, unidos e enriquecidos para preparação para consumo downstream.
- Pipelines são definidos usando SQL declarativo ou Python, tornando as transformações fáceis de ler, manter e versionar. As transformações são executadas usando Apache Spark™ com Photon, proporcionando processamento escalável e de alto desempenho.
- Verificações de qualidade de dados são aplicadas inline usando expectativas, um recurso nativo dos Pipelines Declarativos que permite às equipes impor regras de validação (por exemplo, verificações de nulos, tipos de dados, limites de intervalo). Dados inválidos podem ser configurados para descartar registros ruins, colocá-los em quarentena ou falhar no pipeline - garantindo que os sistemas downstream recebam apenas dados confiáveis.
- O pipeline automaticamente lida com o rastreamento de dependência de trabalho, tentativas de tarefas e isolamento de erros, reduzindo a sobrecarga operacional. Isso garante que os dados processados na camada Silver sejam precisos, consistentes e prontos para produção - mantendo a simplicidade operacional.
- Na Camada Ouro, o pipeline gera agregados de nível de negócios e conjuntos de dados curados prontos para consumo.
- Essas saídas são otimizadas para uso em painéis de BI, recursos de aprendizado de máquina e sistemas operacionais
- Pipelines Declarativos suportam tabelas temporais e lógica SCD, permitindo casos de uso avançados como rastreamento histórico e relatórios de auditoria
- Em todas as camadas, Pipelines Declarativos fornecem observabilidade rica e linhagem de pipeline.
- A interface do usuário exibe gráficos de fluxo de dados, métricas operacionais e painéis de qualidade para suportar a resolução rápida de problemas e relatórios de conformidade
- Com a integração do Unity Catalog, cada tabela, coluna e transformação é governada por meio de controle de acesso centralizado, registro de auditoria e classificação de dados
- Pipelines são prontos para produção por design.
- As equipes podem implantar Pipelines Declarativos usando definições controladas por versão, agendá-los via Lakeflow Jobs e gerenciá-los por meio de ferramentas de CI/CD como GitHub Actions ou Azure DevOps
- Essa automação substitui scripts frágeis e configurações de orquestração complexas, ajudando as equipes de dados a se concentrarem na lógica de negócios em vez de infraestrutura
Recomendado

Vídeo sob demanda

Vídeo sob demanda
Tour do produto

Arquitetura Industrial
