Arquitetura de Referência para Ingestão de Dados
Esta arquitetura de referência para ingestão de dados fornece uma base simplificada, unificada e eficiente para carregar dados de diversas fontes empresariais na Plataforma de Inteligência de Dados Databricks.
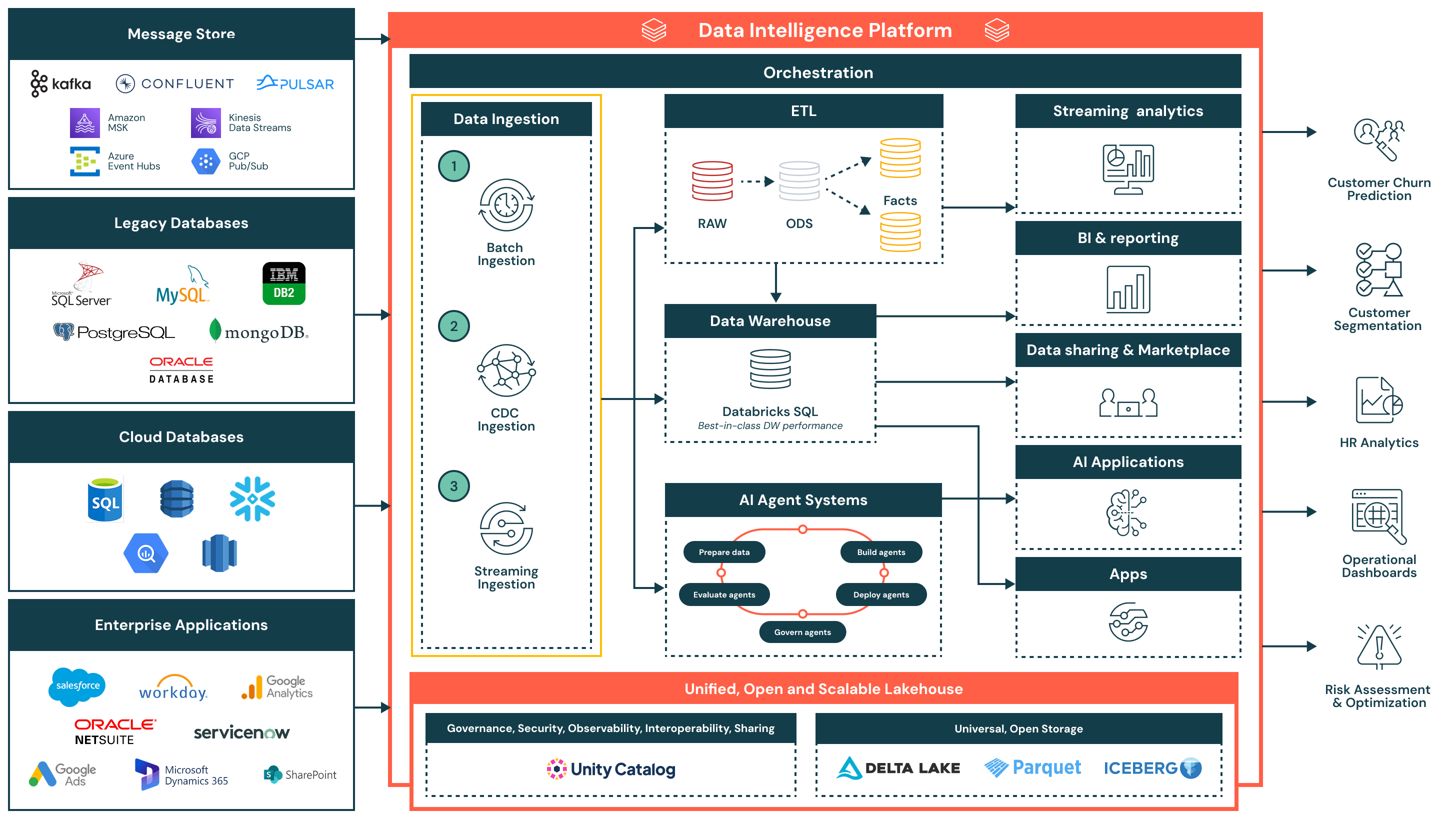
Resumo da Arquitetura
A arquitetura de referência para ingestão de dados suporta uma ampla gama de padrões de ingestão — incluindo em lote, captura de dados de alteração (CDC) e streaming — garantindo governança, desempenho e interoperabilidade. Uma vez ingeridos, os dados são refinados e disponibilizados para análise, IA e compartilhamento seguro de dados em toda a organização.
Esta arquitetura é ideal para organizações que procuram modernizar e operacionalizar pipelines de dados, reduzindo a complexidade e o overhead de integração. É construída em torno de três princípios-chave:
- Simples e de baixa manutenção: Os pipelines de ingestão são fáceis de construir e gerenciar, permitindo um tempo de valorização mais rápido, menos gargalos operacionais e um acesso mais amplo aos dados entre as equipes
- Unificado com a arquitetura do lakehouse: Os dados fluem diretamente para o lakehouse usando formatos abertos e governados pelo Catálogo Unity — garantindo consistência entre BI, IA e casos de uso operacionais
- Fluxo eficiente de ponta a ponta: Da ingestão à transformação e entrega, a plataforma suporta processamento eficiente e incremental que minimiza duplicação, latência e uso de recursos
Casos de uso
Casos de Uso Técnicos
- Ingestão periódica em lote de arquivos planos, exportações ou APIs para zonas de preparação
- Captura de dados de alteração (CDC) ingestão para sincronizar incrementalmente atualizações de sistemas transacionais como Oracle ou PostgreSQL
- Ingestão de streaming de eventos em tempo real de Kafka ou filas de mensagens para uso em painéis ao vivo ou sistemas de alerta
- Harmonizando a ingestão entre sistemas legados, bancos de dados nativos da nuvem e aplicações SaaS empresariais
- Alimentando com dados curados e transformados data warehouses, aplicações de IA e APIs externas
Casos de Uso de Negócios
- Previsão de churn de clientes ao ingerir dados comportamentais, transacionais e de suporte
- Alimentando painéis executivos com métricas operacionais atualizadas de sistemas ERP e CRM
- Segmentação de clientes combinando dados de campanha, vendas e uso do produto
- Realizando análises de RH integrando dados do Workday e plataformas de produtividade
- Realizando avaliação de risco analisando transações e feeds de alerta em tempo quase real
Fluxo de Ingestão de Dados e Capacidades Chave
- Ingestão em lote
- Carrega dados em intervalos programados ou sob demanda de fontes como arquivos planos, APIs ou exportações de banco de dados
- Adequado para relatórios diários, cargas de dados históricos e instantâneos do sistema de registro
- Suporta cargas completas e incrementais, com agendamento nativo, lógica de tentativa e transformação usando SQL ou Python
- Ingestão de mudança de dados (CDC)
- Captura alterações incrementais de sistemas transacionais como Oracle, PostgreSQL e MySQL
- Mantém as tabelas do lakehouse atualizadas sem recargas completas, melhorando a eficiência e a atualidade dos dados
- Permite sincronização de dados quase em tempo real para tabelas de fatos, trilhas de auditoria e camadas de relatórios
- Ingestão de streaming
- Processa continuamente dados de fontes de eventos como Kafka, Kinesis, Pub/Sub ou Event Hubs
- Ideal para painéis em tempo real, sistemas de alerta e detecção de anomalias
- O Structured Streaming gerencia estado, tolerância a falhas e throughput, reduzindo a sobrecarga operacional
Capacidades Adicionais da Plataforma
- Governança unificada
- Catálogo Unity fornece governança unificada, incluindo controle de acesso, linhagem e rastreamento de auditoria
- Os dados são armazenados em formatos abertos e interoperáveis usando Delta Lake e Apache Iceberg™, garantindo flexibilidade e interoperabilidade entre ferramentas e ambientes
- Uma camada de orquestração centralizada gerencia a programação do pipeline, dependências, monitoramento e recuperação
- Arquitetura Lakehouse: Os dados ingeridos são transformados e modelados na arquitetura de medalhão (Bronze, Prata e Ouro), possibilitando consultas de alto desempenho em Databricks SQL
- Orquestração: A orquestração integrada gerencia pipelines de dados, fluxos de trabalho de IA e trabalhos agendados em lotes e cargas de trabalho de streaming, com suporte nativo para gerenciamento de dependências e tratamento de erros
- IA e sistemas de agentes: Os dados alimentam sistemas de agentes para preparação de características, avaliação de modelos e implantação de aplicações alimentadas por IA
- Consumo a jusante:
- Análise de streaming: Visualização em tempo real de métricas chave e sinais operacionais
- BI/análise: Conjuntos de dados curados servidos para ferramentas como Power BI, Lakeview e clientes SQL
- Aplicações de IA: Conjuntos de dados governados consumidos por pipelines de treinamento e motores de inferência
- Compartilhamento de dados e marketplace: Compartilhamento de dados interno e externo seguro via Delta Sharing
- Aplicativos operacionais: Inteligência incorporada e insights contextuais em ferramentas empresariais
Recomendado

Arquitetura de Referência

Arquitetura de Referência

Arquitetura da Indústria

Arquitetura da Indústria
Arquitetura de Referência