Armazenamento de Dados Inteligente no Databricks
Esta arquitetura mostra como a Plataforma de Inteligência de Dados Databricks possibilita armazenamento moderno e BI, combinando ingestão em streaming e lote, armazenamento governado, análises SQL escaláveis e IA integrada em uma lakehouse unificada.
Resumo da Arquitetura
A arquitetura suporta relatórios tradicionais, painéis em tempo real, modelagem preditiva e análises de autoatendimento - tudo isso enquanto atende aos padrões corporativos de segurança, governança e desempenho.
Esta solução demonstra como a Plataforma de Inteligência de Dados Databricks, alimentada pelo Databricks SQL, ajuda as organizações a modernizar sua estratégia de armazenamento de dados, atendendo às necessidades de equipes de dados e stakeholders de negócios.
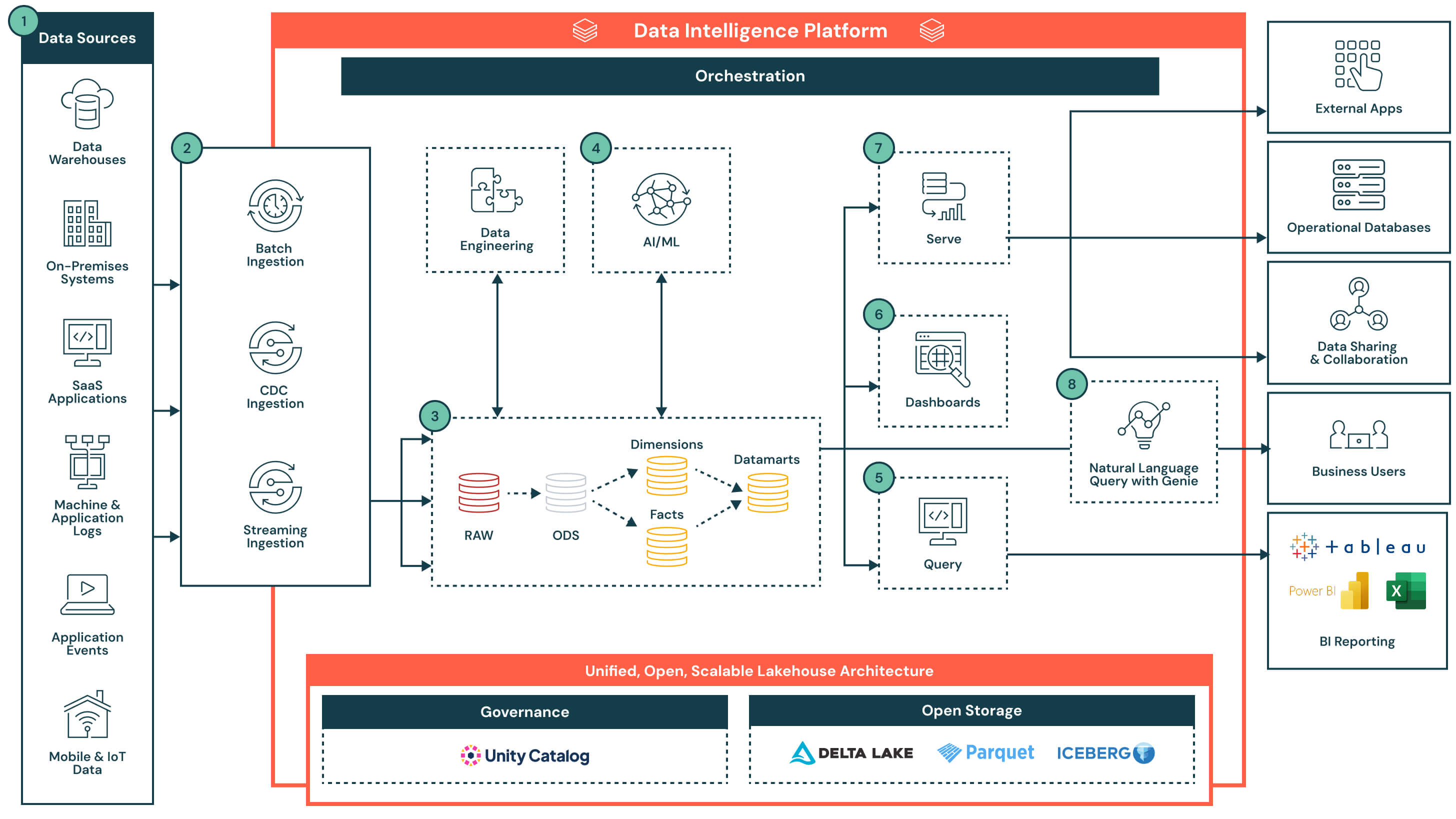
A arquitetura começa com um lakehouse aberto e governado, gerenciado pelo Unity Catalog. Os dados são ingeridos de uma variedade de sistemas - incluindo bancos de dados operacionais, aplicativos SaaS, fluxos de eventos e sistemas de arquivos - e aterrissam em uma camada de armazenamento central. A inteligência de dados da plataforma alimenta tudo, desde ETL e análises SQL até painéis e casos de uso de IA. Ao suportar acesso flexível através de SQL, ferramentas de BI e consultas em linguagem natural, a plataforma acelera a entrega de produtos de dados e torna os insights acessíveis em toda a organização.
Casos de uso
Casos de Uso Técnicos
- Ingestão de dados estruturados, não estruturados, em lote e em streaming de diversas fontes
- Construindo robustos pipelines ETL declarativos
- Modelando fatos, dimensões e data marts usando uma arquitetura de medalhão
- Executando consultas SQL de alta concorrência para relatórios e painéis
- Integrando saídas de ML diretamente no armazém para uso a jusante
Casos de Uso de Negócios
- Entregando painéis em tempo real sobre vendas, operações ou métricas de clientes
- Habilitando a exploração ad hoc através de interfaces de linguagem natural como o Genie
- Suportando casos de uso preditivos como previsão de demanda e modelagem de churn
- Compartilhando produtos de dados governados entre departamentos ou com parceiros
- Fornecendo insights rápidos e confiáveis para equipes de finanças, marketing e produto
Principais Capacidades Com Inteligência de Dados
O componente de inteligência de dados desta arquitetura torna a plataforma mais inteligente, adaptável e fácil de usar em diferentes personas e cargas de trabalho. Aplica IA e consciência de metadados em todo o sistema para simplificar experiências e automatizar a tomada de decisões:
- Interface de linguagem natural (Genie): Entende o contexto de negócios e permite que os usuários façam perguntas de dados em linguagem simples
- Consciência semântica: Reconhece relações entre tabelas, colunas e padrões de uso para sugerir junções, filtros ou cálculos
- Otimização preditiva: Ajusta continuamente o desempenho da consulta e a alocação de computação com base em cargas de trabalho históricas
- Governança unificada: Marca, classifica e rastreia o uso de ativos de dados, tornando a descoberta mais intuitiva e segura
- Capacidade chave: Uma plataforma auto-otimizável que se adapta aos seus dados e usuários
- Diferencial: A inteligência de dados está embutida em toda a ingestão, consulta, governança e visualização - não é adicionada posteriormente
Fluxo de Dados Com Capacidades Chave e Diferenciais
- Fontes de dados: Os dados são armazenados em uma grande variedade de sistemas, incluindo aplicativos empresariais (por exemplo, SAP, Salesforce), bancos de dados, dispositivos IoT, logs de aplicativos e APIs externas. Essas fontes podem produzir dados estruturados, semi-estruturados ou não estruturados.
- Ingestão de dados: Introduz dados através de trabalhos em lote, captura de dados de alteração (CDC) ou streaming. Esses pipelines alimentam a arquitetura lakehouse em tempo quase real ou em intervalos programados, dependendo do sistema de origem e do caso de uso.
- Diferencial chave: Ingestão unificada para todas as modalidades - lote, streaming e CDC - sem a necessidade de infraestrutura ou pipelines separados
- Transformação de dados, ETL, Pipelines Declarativos: Uma vez ingeridos, os dados são transformados através da arquitetura medallion e progressivamente refinados de dados brutos para dados curados.
- Zona Bruta para Zona Bronze: Dados ingeridos de sistemas de fonte externa onde as estruturas nesta camada correspondem às estruturas de tabela do sistema de origem “como estão”, sem transformação ou atualizações nos dados
- Zona Bronze para Zona Prata: Padronize e limpe os dados recebidos
- Zona Prata para Zona Ouro: Aplique lógica de negócios para criar modelos reutilizáveis
- Fatos e dimensões → Data marts: Agregue e cure dados para análises a jusante
- Diferencial chave: Pipelines declarativos de produção com linhagem integrada, observabilidade e evolução de esquema
- Dados curados para casos de uso de IA: Dados curados de data marts podem ser usados para treinar ou aplicar modelos de aprendizado de máquina. Esses modelos suportam casos de uso como previsão de demanda, detecção de anomalias e pontuação de clientes.
- As saídas do modelo são armazenadas ao lado dos dados tradicionais do armazém para fácil acesso via SQL ou painéis
- Os resultados podem ser atualizados em um cronograma ou pontuados em tempo real, dependendo dos requisitos
- Diferencial chave: Análises e cargas de trabalho de IA co-localizadas na mesma plataforma - não é necessário movimento de dados. As saídas do modelo são tratadas como ativos nativos, consultáveis e governados.
- Ferramentas de relatórios de BI alimentadas por consultas: O Databricks SQL suporta consultas de alta concorrência e baixa latência através de computação serverless, e se conecta facilmente a ferramentas de BI populares.
- Editor de consultas integrado e histórico de consultas
- As consultas retornam resultados governados e atualizados de data marts ou saídas de modelo enriquecidas
- Diferencial chave: O SQL do Databricks permite que as ferramentas de BI consultem dados diretamente - sem replicação - reduzindo a complexidade, evitando custos adicionais de licenciamento e diminuindo o TCO geral. Combinado com computação sem servidor e otimização inteligente, ele oferece desempenho de nível de armazém com ajuste mínimo.
- Painéis: Podem ser construídos diretamente no Databricks ou em ferramentas de BI externas como Power BI ou Tableau. Os usuários podem descrever visuais em linguagem natural, e o Assistente Databricks gerará os gráficos correspondentes, que podem ser refinados usando uma interface de apontar e clicar.
- Crie visualizações usando entrada de linguagem natural
- Modifique e explore painéis interativamente com filtros e detalhamentos
- Publique e compartilhe de forma segura painéis em toda a organização, incluindo com usuários fora do espaço de trabalho Databricks
- Diferencial chave: Oferece uma experiência de baixo código e assistida por IA para construir e explorar painéis em dados governados e em tempo real
- Servindo dados curados: Uma vez refinados, os dados podem ser servidos além dos painéis:
- Compartilhado com aplicativos downstream ou bancos de dados operacionais para tomada de decisões transacionais
- Usado em notebooks colaborativos para análise
- Distribuído via Delta Sharing para parceiros, equipes ou consumidores externos com governança unificada
- Consulta em linguagem natural (NLQ): Os usuários de negócios podem acessar dados governados usando linguagem natural. Esta experiência conversacional, alimentada por IA gerativa, permite que as equipes vão além dos painéis estáticos e obtenham insights de autoatendimento em tempo real. O NLQ traduz a intenção do usuário em SQL aproveitando a semântica e os metadados da organização do Catálogo Unity.
- Suporta perguntas ad hoc, interativas e em tempo real que não estão pré-construídas nos painéis
- Adapta-se inteligentemente à terminologia e ao contexto de negócios em evolução ao longo do tempo
- Aproveita a governança de dados existente e controles de acesso via Catálogo Unity
- Fornece auditabilidade e rastreabilidade de consultas em linguagem natural para conformidade e transparência
- Diferencial chave: Adapta-se continuamente a conceitos de negócios em evolução, fornecendo respostas precisas e conscientes do contexto sem exigir conhecimento em SQL
- Capacidades da plataforma: Governança, desempenho, orquestração e armazenamento aberto: A arquitetura é sustentada por um conjunto de capacidades nativas da plataforma que suportam segurança, otimização, automação e interoperabilidade em todo o ciclo de vida dos dados. Principais capacidades:
- Governança: O Catálogo Unity fornece controle de acesso centralizado, linhagem, auditoria e classificação de dados em todas as cargas de trabalho
- Desempenho: O motor Photon, cache inteligente e otimização consciente de carga de trabalho fornecem consultas rápidas sem ajuste manual
- Orquestração: A orquestração integrada gerencia pipelines de dados, fluxos de trabalho de IA e trabalhos agendados em cargas de trabalho em lote e em streaming, com suporte nativo para gerenciamento de dependências e tratamento de erros
- Armazenamento aberto: Os dados são armazenados em formatos abertos (Delta Lake, Parquet, Iceberg), permitindo interoperabilidade entre ferramentas, portabilidade entre plataformas e durabilidade a longo prazo sem bloqueio de fornecedor
- Monitoramento e auditabilidade: Visibilidade de ponta a ponta no desempenho da consulta, execução do pipeline e acesso do usuário para melhor controle e gerenciamento de custos
- Diferencial chave: Os serviços de nível de plataforma estão integrados - não sobrepostos - garantindo que a governança, automação e desempenho sejam consistentes em todos os fluxos de trabalho de dados, nuvens e equipes
Recomendado

Arquitetura de Referência

Arquitetura de Referência

Arquitetura da Indústria

Arquitetura da Indústria