Data Warehousing Inteligente no Databricks - Clonado
Esta arquitetura de referência mostra como a Databricks Data Intelligence Platform permite data warehousing e BI modernos combinando ingestão em lote e streaming, armazenamento governado, análise SQL escalável e AI integrada em um lakehouse unificado.
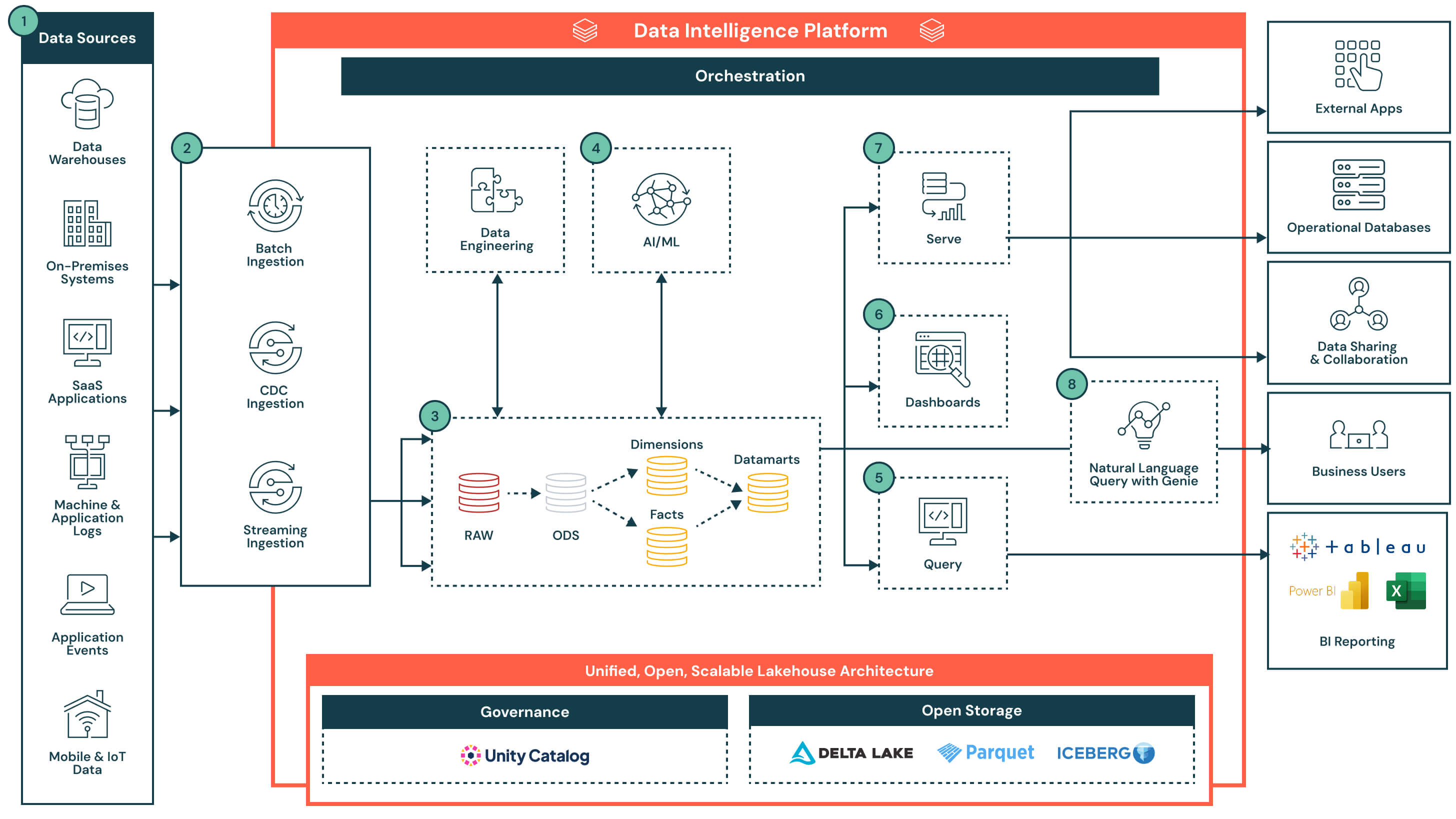
Resumo da arquitetura
A arquitetura oferece suporte a relatórios tradicionais, dashboards em tempo real, modelagem preditiva e analytics de autoatendimento — tudo isso atendendo aos padrões corporativos de segurança, governança e desempenho.
Esta solução demonstra como a Databricks Data Intelligence Platform, equipada com o Databricks Lakehouse, ajuda as organizações a modernizarem sua estratégia de data warehousing, atendendo às necessidades tanto das equipes de dados quanto das partes interessadas de negócios.
A arquitetura começa com um lakehouse aberto e governado, gerenciado pelo Unity Catalog. Os dados são ingeridos de diversos sistemas — incluindo bancos de dados operacionais, aplicativos SaaS, fluxos de eventos e sistemas de arquivos — e chegam a uma camada de armazenamento central. A inteligência de dados da plataforma potencializa tudo, desde ETL e analytics de SQL até dashboards e casos de uso de AI. Ao oferecer suporte a acessos flexíveis por meio de SQL, ferramentas de BI e consultas em linguagem natural, a plataforma acelera a entrega de produtos de dados e torna os insights acessíveis em toda a organização.
Casos de uso
Casos de uso técnicos
- Ingestão de dados estruturados, não estruturados, em lote (batch) e streaming de diversas fontes
- Construção de pipelines de ETL declarativos robustos
- Modelagem de fatos, dimensões e data marts usando uma arquitetura medalhão
- Execução de consultas SQL de alta simultaneidade para relatórios e dashboards
- Integração de saídas de ML diretamente no warehouse para uso downstream
Casos de uso de negócios
- Entrega de dashboards em tempo real sobre métricas de vendas, operações ou clientes
- Permissão de exploração ad hoc por meio de interfaces de linguagem natural como o Genie
- Suporte a casos de uso preditivos, como previsão de demanda e modelagem de churn
- Compartilhamento de produtos de dados governados entre departamentos ou com parceiros
- Fornecimento de insights rápidos e confiáveis para equipes de finanças, marketing e produtos
Principais recursos com inteligência de dados
O componente de inteligência de dados desta arquitetura torna a plataforma mais inteligente, adaptável e fácil de usar em diferentes perfis e cargas de trabalho. Ele aplica AI e reconhecimento de metadados em todo o sistema para simplificar as experiências e automatizar a tomada de decisões:
- Interface de linguagem natural (Genie): Compreende o contexto de negócios e permite que os usuários façam perguntas sobre dados em linguagem simples
- Reconhecimento semântico: Reconhece relações entre tabelas, colunas e padrões de uso para sugerir junções (joins), filtros ou cálculos
- Otimização preditiva: Ajusta continuamente o desempenho das consultas e a alocação de computação com base em cargas de trabalho históricas
- Governança unificada: Identifica, classifica e rastreia o uso de ativos de dados, tornando a descoberta mais intuitiva e segura
- Recurso principal: Uma plataforma de auto-otimização que se adapta aos seus dados e usuários
- Diferencial: A inteligência de dados está incorporada em toda a ingestão, consulta, governança e visualização — não adicionada posteriormente
Fluxo de dados com principais recursos e diferenciais
- Fontes de dados: Os dados são armazenados em uma ampla variedade de sistemas, incluindo aplicativos corporativos (por exemplo, SAP, Salesforce), bancos de dados, dispositivos IoT, logs de aplicativos e APIs externas. Essas fontes podem produzir dados estruturados, semiestruturados ou não estruturados.
- Ingestão de dados: Traz dados por meio de trabalhos em lote (batch), captura de dados alterados (CDC) ou streaming. Esses pipelines alimentam a arquitetura lakehouse quase em tempo real ou em intervalos programados, dependendo do sistema de origem e do caso de uso.
- Principal diferencial: Ingestão unificada para todas as modalidades — lote (batch), streaming e CDC — sem a necessidade de infraestrutura ou pipelines separados
- Transformação de dados, ETL, pipelines declarativos: Uma vez ingeridos, os dados são transformados por meio da arquitetura medalhão e refinados progressivamente de dados brutos para dados selecionados.
- Zona Raw para zona Bronze: Dados ingeridos de sistemas de origem externos onde as estruturas nesta camada correspondem às estruturas de tabela do sistema de origem "no estado em que se encontram", sem transformação ou atualizações nos dados
- Zona Bronze para zona Silver: Padronização e limpeza dos dados recebidos
- Zona Silver para zona Gold: Aplicação de lógica de negócios para criar modelos reutilizáveis
- Fatos e dimensões → data marts: Agregação e curadoria de dados para analytics downstream
- Principal diferencial: Pipelines declarativos de nível de produção com linhagem integrada, observabilidade e evolução de esquema
- Dados selecionados para casos de uso de AI: Os dados selecionados dos data marts podem ser usados para treinar ou aplicar modelos de machine learning. Esses modelos oferecem suporte a casos de uso como previsão de demanda, detecção de anomalias e pontuação de clientes (customer scoring).
- As saídas do modelo são armazenadas junto com os dados tradicionais do warehouse para facilitar o acesso via SQL ou dashboards
- Os resultados podem ser atualizados de forma programada ou pontuados em tempo real, dependendo dos requisitos
- Principal diferencial: Cargas de trabalho de analytics e AI colocalizadas na mesma plataforma — sem necessidade de movimentação de dados. As saídas do modelo são tratadas como ativos nativos, consultáveis e governados.
- Ferramentas de relatórios de BI alimentadas por consultas: O Databricks Lakehouse oferece suporte a consultas de alta simultaneidade e baixa latência por meio de computação serverless e se conecta facilmente a ferramentas de BI populares.
- Editor de consultas integrado e histórico de consultas
- As consultas retornam resultados governados e atualizados de data marts ou saídas de modelos enriquecidas
- Principal diferencial: O Databricks Lakehouse permite que as ferramentas de BI consultem os dados diretamente — sem replicação —, reduzindo a complexidade, evitando custos adicionais de licenciamento e diminuindo o TCO geral. Combinado com computação serverless e otimização inteligente, ele oferece desempenho de nível de data warehouse com o mínimo de ajuste.
- Dashboards: Podem ser criados diretamente no Databricks ou em ferramentas de BI externas, como Power BI ou Tableau. Os usuários podem descrever elementos visuais em linguagem natural, e o Databricks Assistant gerará os gráficos correspondentes, que podem ser refinados usando uma interface de apontar e clicar.
- Crie visualizações usando entrada em linguagem natural
- Modifique e explore dashboards de forma interativa com filtros e drill-downs
- Publique e compartilhe dashboards com segurança em toda a organização, inclusive com usuários fora do workspace do Databricks
- Principal diferencial: Oferece uma experiência low-code e assistida por AI para criar e explorar dashboards em dados governados em tempo real
- Disponibilização de dados curados: Depois de refinados, os dados podem ser disponibilizados além dos dashboards:
- Compartilhados com aplicativos downstream ou bancos de dados operacionais para tomada de decisões transacionais
- Usados em notebooks colaborativos para análise
- Distribuídos via Delta Sharing para parceiros, equipes ou consumidores externos com governança unificada
- Consulta em linguagem natural (NLQ): Os usuários de negócios podem acessar dados governados usando linguagem natural. Essa experiência conversacional, impulsionada por AI generativa, permite que as equipes vão além dos dashboards estáticos e obtenham insights em tempo real no modelo de autoatendimento. O NLQ traduz a intenção do usuário em SQL aproveitando a semântica e os metadados da organização do Unity Catalog.
- Suporta perguntas ad hoc, interativas e em tempo real que não estão pré-configuradas nos dashboards
- Adapta-se de forma inteligente à evolução da terminologia e do contexto de negócios ao longo do tempo
- Aproveita a governança de dados e os controles de acesso existentes por meio do Unity Catalog
- Oferece auditabilidade e rastreabilidade de consultas em linguagem natural para conformidade e transparência
- Principal diferencial: Adapta-se continuamente aos conceitos de negócios em evolução, fornecendo respostas precisas e conscientes do contexto, sem exigir conhecimento em SQL
- Recursos da plataforma: governança, desempenho, orquestração e armazenamento aberto: A arquitetura é sustentada por um conjunto de recursos nativos da plataforma que oferecem suporte a segurança, otimização, automação e interoperabilidade em todo o ciclo de vida dos dados. Principais recursos:
- Governança: O Unity Catalog oferece controle de acesso centralizado, linhagem, auditoria e classificação de dados em todas as cargas de trabalho
- Desempenho: O mecanismo Photon, o cache inteligente e a otimização com reconhecimento de carga de trabalho oferecem consultas rápidas sem ajuste manual
- Orquestração: A orquestração integrada gerencia pipelines de dados, fluxos de trabalho de AI e tarefas agendadas em cargas de trabalho em lote (batch) e streaming, com suporte nativo para gerenciamento de dependências e tratamento de erros
- Armazenamento aberto: Os dados são armazenados em formatos abertos (Delta Lake, Parquet, Iceberg), permitindo interoperabilidade entre ferramentas, portabilidade entre plataformas e durabilidade a longo prazo sem dependência de fornecedor (vendor lock-in)
- Monitoramento e auditabilidade: Visibilidade de ponta a ponta sobre o desempenho das consultas, a execução de pipelines e o acesso dos usuários para melhor controle e gerenciamento de custos
- Principal diferencial: Os serviços no nível da plataforma são integrados — e não sobrepostos —, garantindo que a governança, a automação e o desempenho sejam consistentes em todos os fluxos de trabalho de dados, nuvens e equipes
Recomendado

Arquitetura de Referência

Arquitetura de Referência

Arquitetura Industrial