LakeFlow
Ingerir, transformar e orquestrar com uma solução unificada de engenharia de dados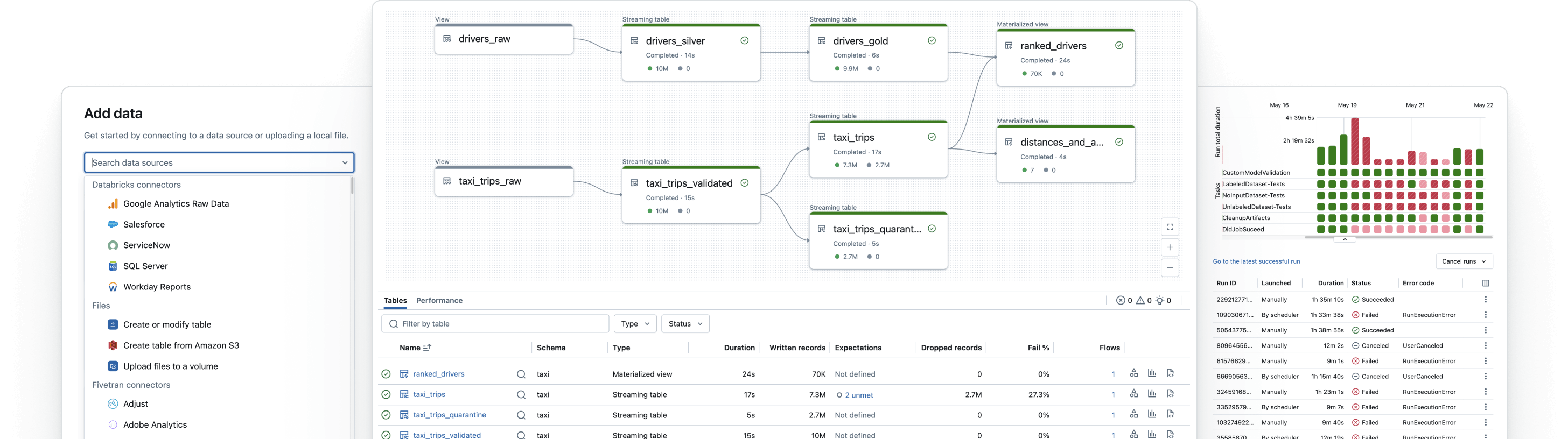
LAKEFLOW NAS MELHORES EMPRESAS
A solução ponta a ponta para entregar dados de alta qualidade.
Ferramentas que facilitam a criação de pipelines de dados sólidos de analítica e IA para as equipes.Conjunto de ferramentas unificado
Reduza os custos e as despesas gerais de integração com uma única solução para coletar e limpar todos os seus dados. Mantenha o controle com governança e linhagem unificadas e integradas.
Engenharia de dados agêntica
Use linguagem natural para construir mais rapidamente com agentes que compreendem seus dados e podem criar, manter e solucionar problemas em pipelines de dados.
Processamento de dados eficiente
Um mecanismo avançado otimiza automaticamente o uso de recursos para obter o melhor preço/desempenho para casos de uso em lote e em tempo real.
Desenvolvimento 85% mais rápido
Redução de 50% nos custos
Redução de 99% na latência do pipeline
Ferramentas unificadas para qualquer carga de trabalho de engenharia de dados

Genie Code
Desenvolva e mantenha pipelines de dados com uma IA agêntica que entende seus dados.
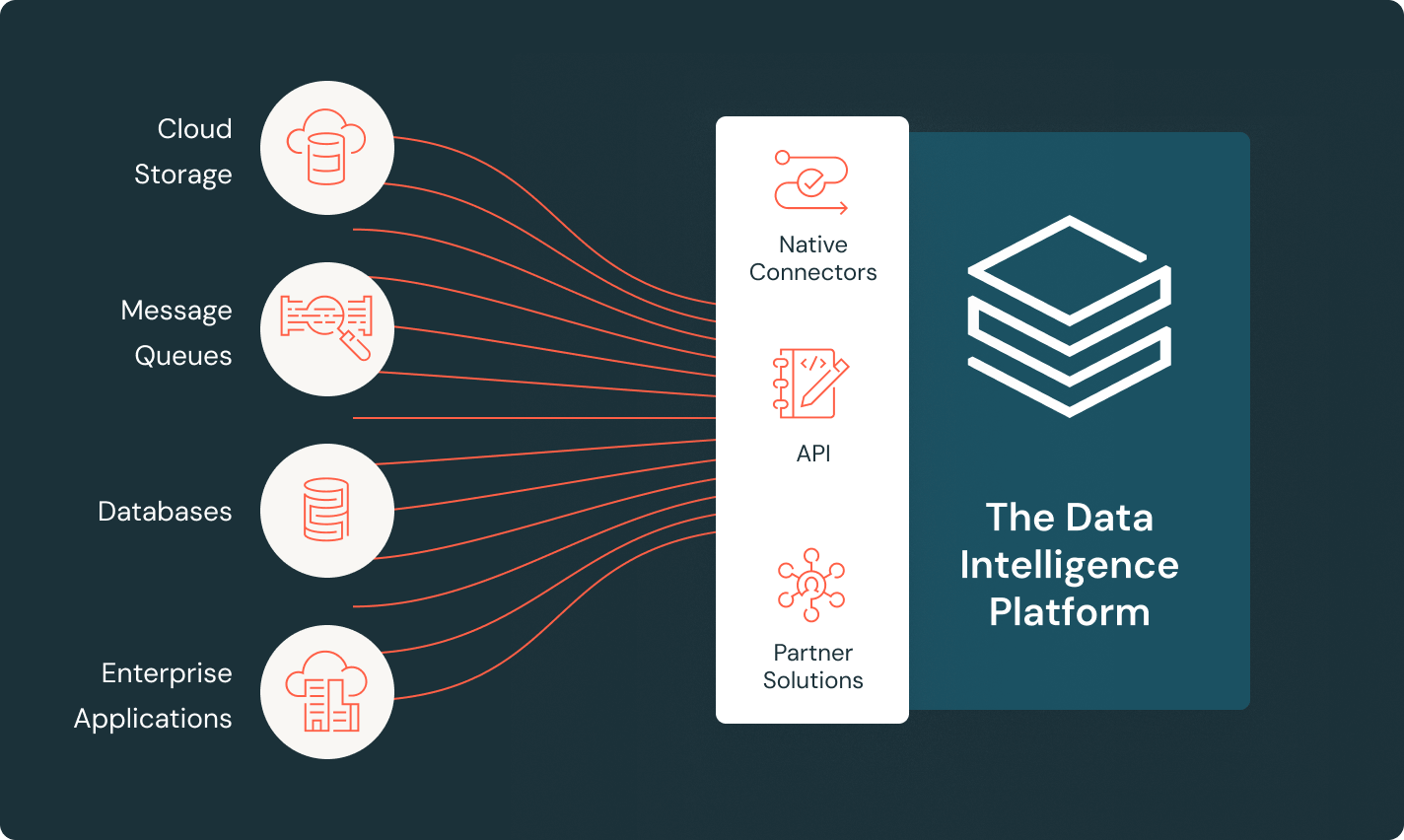
LakeFlow Connect
Conectores eficientes de ingestão de dados e integração nativa com o Data Intelligence Platform facilitam o acesso à analítica e IA, com governança unificada.

Apache Spark™ Declarative Pipelines
Simplifique o ETL em lotes e transmissão com qualidade de dados automatizada, captura de dados de alterações (CDC), ingestão de dados, transformações e governança unificada.

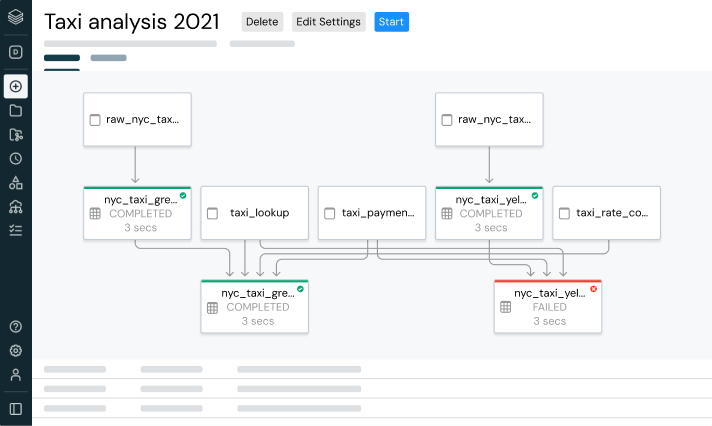
Jobs do Lakeflow
Capacite as equipes para automatizar e orquestrar melhor qualquer fluxo de trabalho de ETL, analítica e IA com observabilidade detalhada, alta confiabilidade e amplo suporte a tipos de tarefas.

Unity Catalog
Governe sem esforço todos os seus ativos de dados com a única solução de governança unificada e aberta do setor para dados e AI, integrada à Databricks Data Intelligence Platform.
Lakeflow Designer
Prepare e transforme dados com uma criação que prioriza a IA, diretamente na Databricks.
Crie pipelines de dados confiáveis
Transforme dados brutos em tabelas ouro de alta qualidade
Sua frase principal opcional aparece aqui, exibida um pouco maior.
Implemente pipelines ETL para filtrar, enriquecer, limpar e agregar dados para que estejam prontos para a analítica, IA e BI. Siga a arquitetura medallion para processar dados de tabelas bronze, prata e ouro.

Dê um passo adiante




Perguntas frequentes sobre a engenharia de dados
Pronto para se tornar uma empresa de dados + AI?
Dê os primeiros passos na transformação dos seus dados