10 trilhões de amostras por dia: Escalando além da infraestrutura de monitoramento tradicional na Databricks
Como construímos uma plataforma de monitoramento projetada para o crescimento exponencial da Databricks
por David Yuan, Yi Jin, Karan Bavishi, HC Zhu e Joey Beyda
- Os sistemas de monitoramento da Databricks gerenciam mais de 5 bilhões de séries temporais ativas em tempo real na AWS, Azure e GCP.
- Para manter esses sistemas confiáveis e de baixa manutenção, apesar da rápida escalabilidade, reestruturamos nossas camadas TSDB e de agregação personalizando soluções de monitoramento de código aberto.
- Diante do forte crescimento em métricas de solução de problemas de alta cardinalidade, desenvolvemos uma nova plataforma baseada em Lakehouse chamada Hydra. Essa abordagem desbloqueou recursos avançados de depuração em escala massiva e com armazenamento 50x mais barato do que nossa pilha existente.
A infraestrutura de monitoramento da Databricks mais do que triplicou de tamanho no último ano, agora rastreando 5 bilhões de séries temporais ativas em tempo real e ingerindo mais de 10 trilhões de amostras por dia. Nessa escala massiva, descobrimos que soluções prontas eram ineficientes ou difíceis de adaptar às nossas necessidades. Este post compartilha o que construímos em vez disso: uma plataforma escalável que aproveita o melhor do ecossistema de monitoramento de código aberto, enquanto incorpora personalizações para nossas necessidades exclusivas.
Engenheiros em toda a Databricks dependem de sistemas de monitoramento que nos alertam rapidamente sobre problemas, automatizam o escalonamento e os rollbacks, e permitem a solução de problemas inteligente. Esses sistemas precisam ser altamente confiáveis para que possamos ter confiança de que não ficaremos no escuro durante um incidente potencial. No entanto, provou não ser tarefa fácil desenvolver essa infraestrutura para a escala da Databricks:
- Além dos requisitos de escalabilidade, confiabilidade e eficiência, executamos nossos sistemas globalmente em aproximadamente 70 regiões de nuvem em cada uma das 3 principais nuvens. Precisamos suportar desempenho equivalente, apesar das diferenças entre nuvens e até mesmo entre regiões individuais.
- Diante dessa amplitude e variedade, operar infraestrutura em larga escala pode rapidamente se tornar insustentável. O sistema precisa ser o mais "autônomo" possível – autorreparável e autônomo – em vez de nossos oncalls gerenciarem diretamente cada pilha regional – e ainda assim fornecer interfaces simples para os usuários.
- Com o crescimento das cargas de trabalho serverless e de IA na Databricks, a rotatividade em nossa infraestrutura disparou, causando aumentos rápidos na cardinalidade das métricas. Não podíamos mais processar e armazenar dados de monitoramento de alta cardinalidade como sempre fizemos, mas ainda pretendíamos manter os fluxos de trabalho de depuração nos quais os engenheiros confiavam.
Diante desses desafios, a antiga pilha de monitoramento da Databricks sofria de problemas de confiabilidade. Decidimos desenvolver uma plataforma nova e confiável que atendesse às expectativas de nossos engenheiros. Desde então, abordamos 3 problemas principais:
- Arquitetando um banco de dados de séries temporais (TSDB) confiável e eficiente
- Introduzindo agregação de métricas para proteger os TSDBs da cardinalidade
- Habilitando a solução de problemas altamente dimensional com o lakehouse da Databricks
Bancos de dados de séries temporais Thanos
O que são TSDBs?
TSDBs são um componente central das arquiteturas tradicionais de sistemas de monitoramento. Esses bancos de dados especializados são projetados para ingerir grandes quantidades de dados de métricas de séries temporais e servir leituras em tempo real de baixa latência e alto QPS. Eles são especialmente ideais para padrões de consulta de monitoramento, como alertas e atualizações de painel, que exigem a emissão do mesmo conjunto de consultas repetidamente e a obtenção de resultados ultrarrápidos com base nos dados mais recentes.
Os antigos TSDBs da Databricks foram construídos para uma ordem de magnitude menor de escala e se tornaram um grande gargalo para nós nos últimos anos. De fato, o principal problema de confiabilidade para toda a infraestrutura de monitoramento foi a dificuldade de escalar nossos TSDBs. Esta é uma operação infrequente para muitas outras empresas, mas algo que precisávamos fazer quase diariamente, dado o crescimento exponencial da Databricks.
Então, desenvolvemos um novo TSDB codinome Pantheon, que é um fork do projeto de código aberto CNCF Thanos. Escalamos com sucesso para mais de 160 instâncias do Thanos em todas as regiões em três provedores de nuvem, com um total de cerca de 5 bilhões de séries temporais ativas em memória e mais de 10 trilhões de amostras ingeridas diariamente. Nossa maior instância hospeda cerca de 300 milhões de séries temporais em memória e suporta quase 1.000 consultas PromQL por segundo; também executamos pequenas implantações de 3 nós e tudo mais. Devido à amplitude, escala e variedade de nossas implantações, frequentemente descobrimos casos de borda e otimizações de desempenho do Thanos e contribuímos de volta para a comunidade de código aberto.
Migrar para o Pantheon nos permitiu economizar milhões de dólares em custos anuais de nuvem, enquanto reduzimos o tempo de inatividade da infraestrutura de monitoramento em ~5x e eliminamos muitas fontes de trabalho manual. A arquitetura do Pantheon é mostrada abaixo, e as seções a seguir explicam várias decisões de design chave que tornaram essas conquistas possíveis.
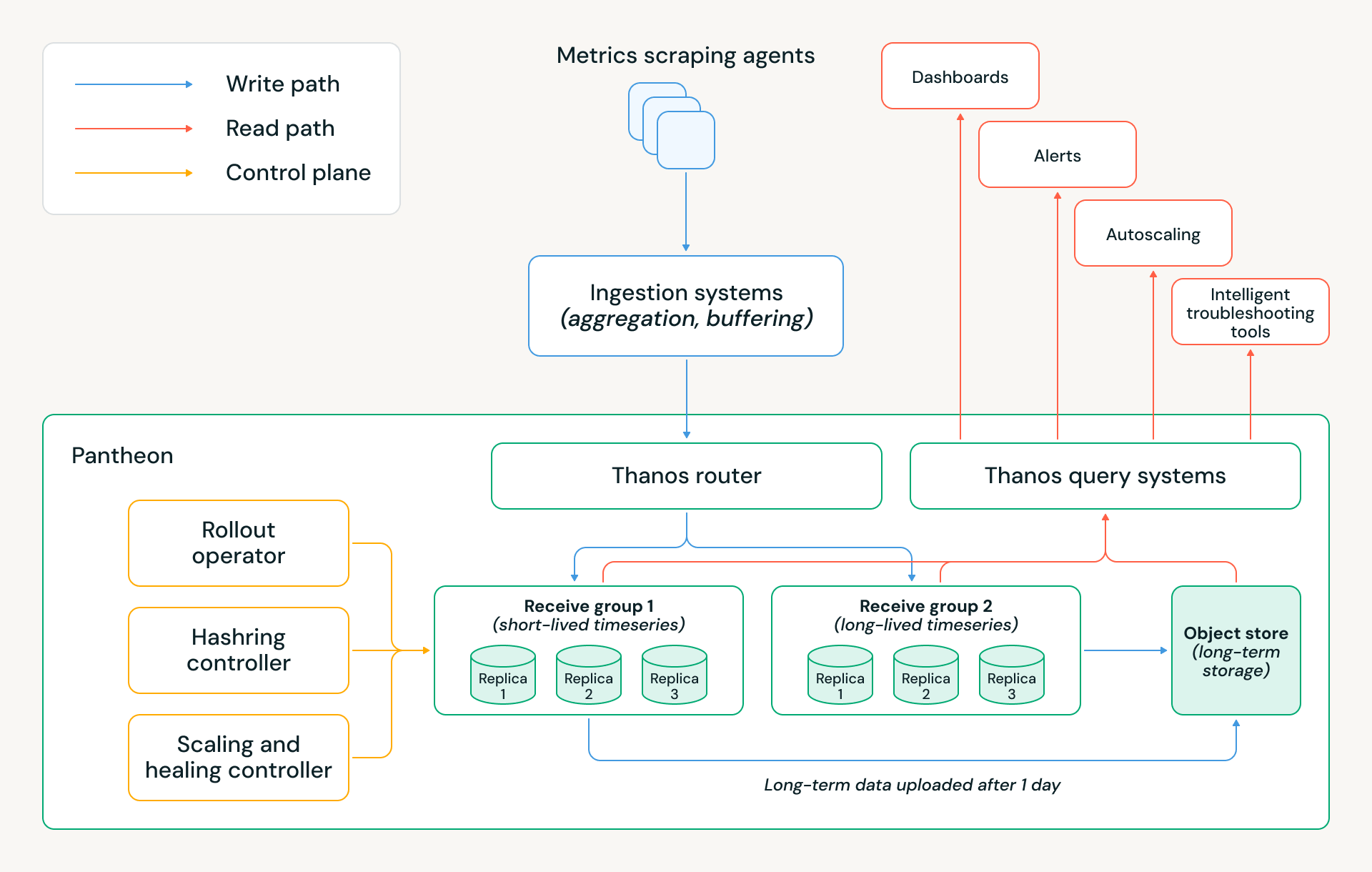
Arquitetura de armazenamento
Um elemento chave do Thanos é sua arquitetura de armazenamento em camadas. As séries temporais mais recentes são mantidas em memória, as séries temporais das últimas 24 horas são mantidas em disco e todos os dados mais antigos são mantidos em armazenamento de objetos. Isso significa que alertas e outras consultas em tempo real podem atender a requisitos de desempenho rigorosos, pois geralmente dependem dos dados mais recentes. Ao mesmo tempo, o uso de armazenamento de objetos permite que o sistema desacople essencialmente computação de armazenamento; um cluster pode escalar sem precisar rebalancear todos os seus dados históricos entre os nós do banco de dados.
Essa arquitetura abordou nosso principal gargalo (escalonamentos) e lançou as bases para as economias de custos do Pantheon. Aplicamos várias outras otimizações:
- Retenção de memória: Implantamos dois grupos de Recebimento com políticas de retenção de memória distintas: um otimizado para séries temporais de longa duração de serviços persistentes, mantendo duas horas de amostras em memória, e outro otimizado para séries temporais de curta duração de cargas de trabalho efêmeras da Databricks, mantendo apenas 30 minutos em memória. Essa divisão reflete o tempo de vida que observamos para cargas de trabalho serverless na Databricks e reduz significativamente o uso de memória e o custo da nuvem, preservando a correção.
- Estrutura do grupo de recebimento: Cada grupo é intencionalmente implementado como três StatefulSets isolados do Kubernetes, correspondendo a três réplicas, em vez de um único anel hash grande. Esse design preserva a replicação tripla com gravações de quórum, ao mesmo tempo que fornece isolamento operacional e de dados mais forte. Essa configuração nos permite atualizar ou reiniciar um StatefulSet inteiro em paralelo durante lançamentos ou rotações de nós sem violar o quórum ou impactar a disponibilidade de gravação, o que simplifica materialmente as operações do dia a dia.
- Multilocação: O Pantheon usa a multilocação do Thanos para hospedar conjuntos de locatários desarticulados em grupos de Recebimento. Na camada do roteador, aplicamos atribuição de locatário baseada em regras, inferindo o locatário para cada amostra de dados inspecionando o nome da métrica e os rótulos selecionados. Isso permite que amostras dentro do mesmo lote de gravação sejam roteadas para locatários diferentes – e, portanto, para grupos de Recebimento diferentes – sem exigir alterações no cliente upstream.
- Uploads pelo menos uma vez: Para otimizar ainda mais o custo, preservando a correção, apenas dois dos três StatefulSets carregam blocos para armazenamento de objetos. Isso reduz o tráfego de upload redundante e os custos de armazenamento em nuvem, mantendo a durabilidade dos dados e as garantias de consistência por meio de replicação e semântica de quórum.
Plano de controle do Pantheon
Em nossa escala global, operações manuais, automação do Kubernetes de melhor esforço ou comportamentos genéricos do Thanos são insuficientes. Cada lançamento, evento de escala ou falha de host deve ser tratado com segurança, automaticamente e com o mínimo de intervenção humana, preservando o quórum e a disponibilidade de dados. Para conseguir isso, o Pantheon introduz um plano de controle construído para fins específicos, responsável por orquestrar o ciclo de vida dos componentes do Thanos e as decisões de capacidade. Ele consiste em três controladores principais:
- Operador de Rollout: Coordena lançamentos e escalonamentos em três StatefulSets de Recebimento isolados, garantindo o quórum para leituras e gravações. Ele permite lançamentos mais rápidos por meio de atualizações paralelas de StatefulSet, garantindo que no máximo uma réplica esteja indisponível a qualquer momento.
- Controlador Hashring: Gerencia quais endpoints de Recebimento estão visíveis para o roteador. Apenas pods saudáveis e totalmente prontos são adicionados ao hashring, e as remoções são escalonadas durante o escalonamento para baixo ou a manutenção. Isso desacopla o gerenciamento de tráfego do ciclo de vida do pod e evita violações acidentais de quórum ou roteamento parcial durante mudanças dinâmicas de cluster.
- Controlador de Autociclo e Autorreparação: Escala clusters com base na ingestão específica do Pantheon e na pressão de recursos, em vez de sinais genéricos do Kubernetes. Um sistema de reparo integrado detecta e remedia continuamente modos de falha comuns – como hosts ruins, pods sobrecarregados ou um WAL corrompido – permitindo que o sistema se recupere sem intervenção do operador. Em nossa escala, essas automações entram em ação dezenas de vezes por semana.
Cardinalidade e agregação
O que é cardinalidade e por que ela é importante?
Os proprietários de métricas frequentemente adicionam rótulos como ID do nó ou ID do pod para ajudá-los a depurar problemas em dimensões específicas e mitigar incidentes mais rapidamente. No entanto, isso leva a um desafio clássico de observabilidade: o gerenciamento de cardinalidade. A cardinalidade de uma métrica é o número de combinações exclusivas de seus rótulos. Se o número de pods que você está monitorando aumenta 10x, o mesmo acontece com a cardinalidade de qualquer métrica com um rótulo de ID de pod. A cardinalidade é o principal fator de escalonamento para um TSDB, e o crescimento na cardinalidade de métricas existentes aumenta os custos e a pressão de escalonamento no Pantheon.
O crescimento rápido da infraestrutura é um desafio com o qual somos abençoados na Databricks. Ao mesmo tempo em que nossa base de clientes e o uso de produtos cresceram significativamente, muitos clientes adotaram recentemente nossa arquitetura de computação serverless, e nossa plataforma de computação serverless inicia dezenas de milhões de VMs diariamente. À medida que mais cargas de trabalho migram para o serverless, a infraestrutura que monitoramos se torna de maior rotatividade, e a vida útil desses rótulos identificadores continua a encurtar.
Isso fez com que a cardinalidade disparasse, consumindo as vitórias de escalabilidade e custo do Pantheon. Assim, tivemos que ser muito mais inteligentes sobre quais dados de métricas armazenávamos. É aqui que a “agregação” entrou em jogo: descartando rótulos caros de sistemas serverless durante a ingestão, ao mesmo tempo em que fornece uma visão agregada de toda a frota para os proprietários de serviços. Uma estratégia de agregação automatizada para métricas nos permitiu “curvar a trajetória” do crescimento da cardinalidade, garantindo que a infraestrutura de monitoramento não precise escalar mais rápido do que o restante da Databricks.
Arquitetura de agregação
Construir infraestrutura de agregação confiável em escala é difícil porque ela é stateful. Agregadores que gerenciam milhões de contadores de entrada devem ser capazes de lidar corretamente com reinicializações – se uma série temporal de entrada desaparecer, o valor de saída agregado deve continuar a aumentar monotonicamente em vez de diminuir. Com métricas particionadas entre agregadores, você também deve lidar com cenários como reinicializações de pods e desequilíbrio de carga.
Esses problemas são frequentemente resolvidos usando um sistema de mensagens como Kafka para atribuições de particionamento e manutenção de dados anteriores; isso é caro em nossa escala e adiciona atraso na ingestão que afeta casos de uso em tempo real. A abordagem alternativa é armazenar estado em memória nos agregadores e redirecionar métricas entre agregadores para honrar a atribuição. No entanto, isso leva à perda de dados quando um agregador é reimplantado; em uma versão inicial de nossa infraestrutura de agregação, esse comportamento tornou as métricas agregadas quase ininteligíveis para nossos usuários.
Para que isso funcione perfeitamente, desenvolvemos nosso próprio sistema de agregação usando Telegraf e o serviço “auto-sharder” da Databricks Dicer. Essa arquitetura usa roteamento inteligente e fixo em vez de redirecionar métricas entre agregadores, o que resolveu os modos de falha de reimplantamento. Com outras otimizações que adicionamos ao Telegraf, conseguimos escalar o pipeline para mais de 1 GB/s em nossa maior região e milhares de regras de agregação.
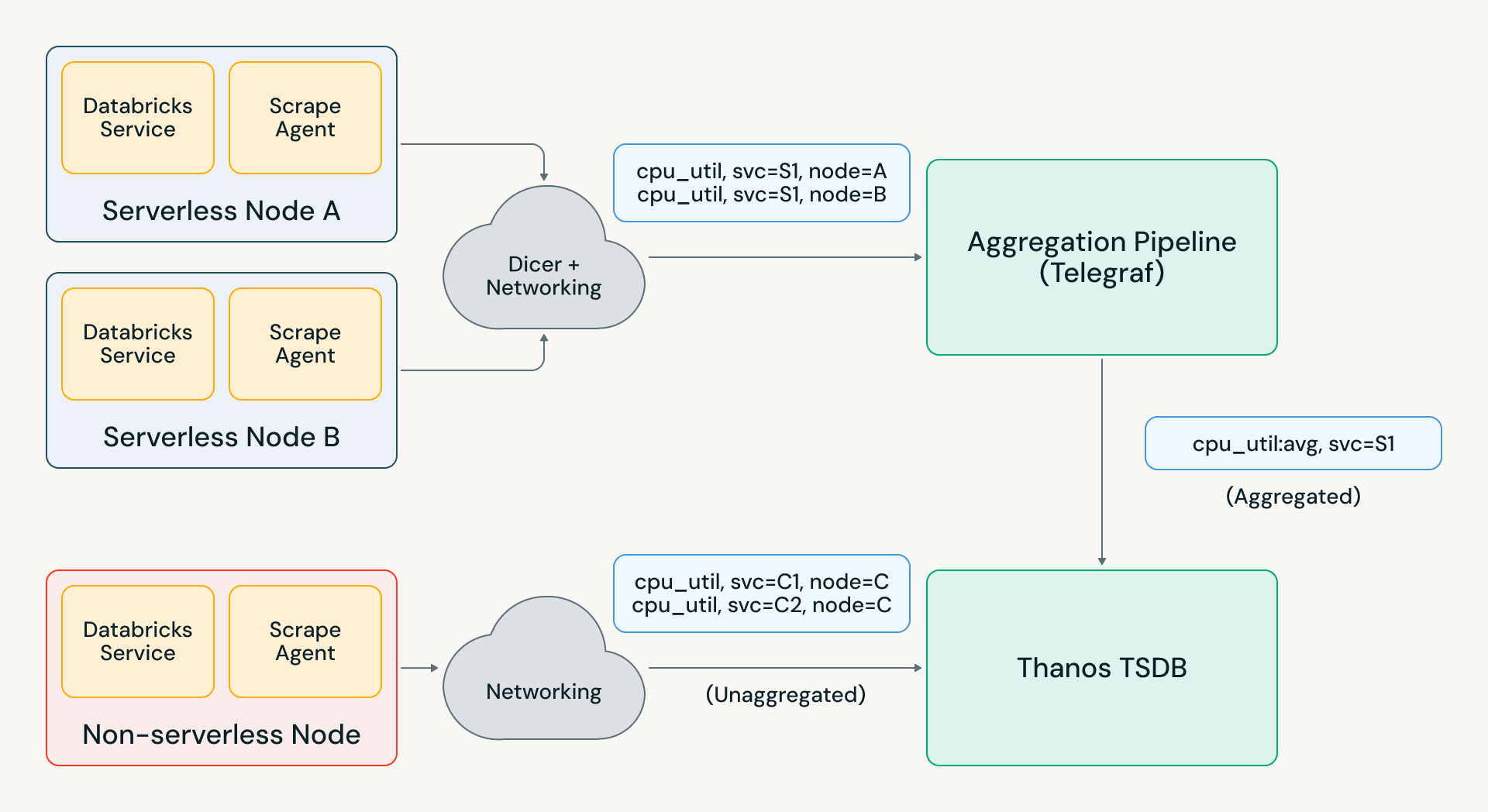
Este novo pipeline de agregação efetivamente se tornou o escudo que protege nossos TSDBs do crescimento de cardinalidade a longo prazo, bem como de picos inesperados de métricas. Por exemplo, um incidente recente na infraestrutura da Databricks resultou em um pico de 2 a 5 vezes na carga de métricas em várias regiões. O Telegraf absorveu a maior parte dessa carga, e o Pantheon viu apenas um pico de 20%, permitindo que engenheiros de toda a empresa executassem consultas de depuração e alerta sem qualquer impacto.
Dados de alta cardinalidade no lakehouse
O problema com a agregação
Nossa infraestrutura de agregação nos permite proteger o Pantheon do crescimento exponencial da cardinalidade, mas isso tem um custo – ela remove as dimensões exatas que os engenheiros precisam durante incidentes. Considere uma frota global com:
- Milhões de nós ativos nas últimas 2 horas
- Múltiplos tenants por nó
- Cargas de trabalho de curta duração
- Autoscaling rápido
Métricas agregadas informam:
- O uso de CPU em nível de região está elevado
- A latência em nível de serviço está aumentando
Mas elas não informam:
- Qual tenant está causando pressão de swap
- Qual nó falhou
- Qual shard está isolado
- Qual carga de trabalho está ruidosa
Engenheiros da Databricks ainda precisavam de uma solução para solucionar problemas de fluxos de trabalho que dependiam desses rótulos de alta cardinalidade. Esses cenários de “agulha no palheiro” exigiam o armazenamento e processamento eficientes de enormes quantidades de dados brutos, o que o Pantheon não conseguia. Para dar suporte a esses casos de uso, buscamos uma arquitetura de armazenamento diferente que não fosse limitada pelo crescimento da cardinalidade.
Apresentando o lakehouse!
Nossa principal percepção: o lakehouse da Databricks é um ajuste perfeito! Ele desacopla o armazenamento (armazenamento de objetos barato + Delta Lake) da computação (clusters de streaming + consulta) e é massivamente escalável em ambas as dimensões.
Usando o melhor das capacidades da Databricks, desenvolvemos uma nova plataforma para dados brutos de solução de problemas chamada Hydra, que tornou a depuração de alta cardinalidade prática em escala massiva. O Hydra ingere 20 bilhões de séries temporais ativas e não agregadas de milhões de nós em todo o mundo, alcançando 5 minutos de atualização de dados de ponta a ponta e armazenamento de dados 50x mais barato que o Thanos.
Essas vitórias foram possibilitadas pelo design nativo do lakehouse do Hydra:

- Usamos Apache Spark™ Structured Streaming na Databricks para executar trabalhos contínuos de ingestão que processam incrementalmente os dados de métricas à medida que chegam, gravando-os no Delta Lake. O Structured Streaming permite expressar computações de streaming da mesma forma que você escreve trabalhos em lote, mas com processamento contínuo e incremental e semântica de exatamente uma vez para ingestão confiável.
- Para descobrir e ingerir eficientemente milhões de arquivos de armazenamento de objetos, aproveitamos o Databricks Auto Loader, uma fonte Structured Streaming de alta taxa de transferência que rastreia e processa incrementalmente novos arquivos sem exigir listagem manual ou gerenciamento de estado. O Auto Loader persiste automaticamente metadados sobre arquivos descobertos e escala para lidar com padrões de chegada quase em tempo real.
- Também particionamos a ingestão por região, implantando trabalhos de streaming independentes entre geografias. Isso permite que cada pipeline escale automaticamente de forma independente, minimiza a latência entre regiões e reduz o raio de explosão em caso de falhas. Juntas, essas escolhas de design permitem que os dados brutos de métricas sejam consultáveis em minutos após a emissão, mesmo em volumes de bilhões de séries, mantendo os sistemas de dashboard performáticos.
Unificando interfaces
Construir o Hydra não foi apenas um desafio de infraestrutura; foi um desafio de design de interface. Desde o início, projetamos o Hydra em torno de Jornadas Críticas do Usuário (CUJs) para nossos engenheiros, em vez de em torno de camadas de armazenamento ou pipelines de ingestão. Nosso objetivo era simples: os engenheiros devem ser capazes de trabalhar com métricas de alta cardinalidade usando as mesmas interfaces em que já confiam.
Consultando através do Grafana
A maioria dos engenheiros começa seu fluxo de trabalho de depuração no Grafana. Eles esperam escrever PromQL, usar dashboards existentes, detalhar rótulos e pivotar rapidamente durante incidentes.
Para preservar esse fluxo de trabalho, o Hydra se integra diretamente ao Grafana, permitindo que consultas PromQL sejam executadas contra dados armazenados na Databricks. Construímos uma camada de conversão de PromQL para SQL que traduz expressões PromQL em consultas SQL executadas em tabelas Delta no Lakehouse. Essa abordagem permite que os engenheiros continuem usando a sintaxe e os dashboards PromQL familiares sem modificação. Ao mesmo tempo, as consultas subjacentes são executadas em tabelas Delta de grande escala em vez de um TSDB em memória.
Acesso SQL Direto na Databricks
Embora o Grafana seja ideal para depuração ao vivo, algumas investigações exigem análises mais profundas. Os engenheiros podem precisar juntar métricas com metadados de implantação, correlacionar métricas com logs, executar varreduras de amplo intervalo de tempo, realizar detecção de anomalias ou exportar conjuntos de dados para análise avançada.
O Hydra também expõe as tabelas Delta subjacentes diretamente no Databricks. Os engenheiros podem consultar essas tabelas usando Databricks SQL ou notebooks, permitindo análises flexíveis que vão além dos fluxos de trabalho de monitoramento tradicionais.
Como os dados residem no Lakehouse, eles se tornam combináveis com outros conjuntos de dados corporativos e governados sob os mesmos controles de segurança e acesso. Isso transforma os dados de observabilidade em um ativo analítico de primeira classe, em vez de um silo de monitoramento isolado.
Semântica Unificada de Métricas
Um princípio de design chave do Hydra é que os engenheiros não devem precisar entender nossa arquitetura de ingestão. Se uma métrica é acessada através do caminho agregado com suporte de TSDB ou do caminho de métrica bruta com suporte de Lakehouse, a interface permanece consistente.
Nomes de métricas, semântica de rótulos e dimensões de metadados são unificados em todos os ambientes. As equipes de serviço emitem métricas uma vez usando uma interface padronizada. A plataforma lida com agregação, preservação bruta, ingestão, armazenamento e roteamento de consultas. Esse modelo unificado reduz a sobrecarga cognitiva e elimina a necessidade de as equipes gerenciarem configurações separadas para diferentes backends de observabilidade.
No futuro, estamos buscando melhorar o desempenho do Hydra para que ele atinja uma atualidade de dados semelhante à do Pantheon e as duas experiências convergem ainda mais.
Conclusões
Para escalar a infraestrutura de monitoramento do Databricks, precisávamos otimizar a confiabilidade, eficiência, operabilidade e jornadas do desenvolvedor. "Escalar" para nós significou mais do que apenas aumentar nossas implantações. Significou:
- Incorporar resiliência e automação em nossa arquitetura fundamental, para alcançar operações "sem intervenção" para esses sistemas globais e em constante mudança
- Repensar a partir de princípios fundamentais os tipos de sistemas que eram necessários para vários casos de uso de monitoramento, desde alertas até solução de problemas e análise entre fontes de dados
- Evoluir nossa arquitetura à medida que o restante da infraestrutura do Databricks se transformou junto conosco
Essas serão jornadas intermináveis para nós, e elas ilustram por que a engenharia de infraestrutura é um espaço tão dinâmico no Databricks. Se você gosta de resolver problemas de engenharia difíceis e gostaria de se juntar a nós nessa jornada, confira databricks.com/careers!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.