Código aberto do Dicer: o Auto-Sharder da Databricks
Criação de serviços particionados de alta disponibilidade em escala para alto desempenho e baixo custo
por Atul Adya, Colin Meek, Jonathan Ellithorpe, Vivek Jain e Yongxin Xu
- Dicer de código aberto: Estamos oficialmente abrindo o código do Dicer, o sistema fundamental de particionamento automático (auto-sharding) usado no Databricks para construir serviços particionados rápidos, escaláveis e de alta disponibilidade.
- O que é e por que usar o Dicer: Descrevemos os problemas das arquiteturas de serviço típicas atuais, por que os sistemas de particionamento automático (auto-sharders) são necessários, como o Dicer resolve esses problemas e discutimos suas abstrações principais e casos de uso.
- Casos de sucesso: O sistema atualmente alimenta componentes de missão crítica como o Unity Catalog e nosso mecanismo de orquestração de queries SQL, onde eliminou com sucesso as quedas de disponibilidade e manteve taxas de acerto de cache acima de 90% durante as reinicializações de pods.
1. Anúncio
Hoje, temos o prazer de anunciar a abertura do código aberto de um dos nossos componentes de infraestrutura mais críticos, Dicer: o auto-sharder da Databricks, um sistema fundamental projetado para criar serviços com sharding de baixa latência, escaláveis e altamente confiáveis. Ele está por trás de todos os principais produtos da Databricks, o que nos permite oferecer uma experiência do usuário consistentemente rápida, ao mesmo tempo que melhora a eficiência da frota e reduz os custos de cloud. O Dicer consegue isso gerenciando dinamicamente as atribuições de sharding para manter os serviços responsivos e resilientes mesmo diante de reinicializações, falhas e cargas de trabalho variáveis. Conforme detalhado nesta postagem do blog, o Dicer é usado para uma variedade de casos de uso, incluindo serviços de alto desempenho, particionamento de trabalho, pipelines em lotes, agregação de dados, multilocação, eleição de líder soft, utilização eficiente de GPU para cargas de trabalho de IA e muito mais.
Ao disponibilizar o Dicer para a comunidade em geral, esperamos colaborar com a indústria e a academia para avançar o estado da arte na construção de sistemas distribuídos robustos, eficientes e de alto desempenho. No restante desta postagem, discutimos a motivação e a filosofia de design por trás do Dicer, compartilhamos histórias de sucesso de seu uso no Databricks e fornecemos um guia sobre como instalar e experimentar o sistema por conta própria.
2. Motivação: indo além de arquiteturas sem estado e particionadas estaticamente
A Databricks oferece uma suíte de produtos em rápida expansão para processamento de dados, analítica e IA. Para dar suporte a isso em escala, operamos centenas de serviços que devem lidar com um estado massivo enquanto mantêm a responsividade. Historicamente, os engenheiros da Databricks confiavam em duas arquiteturas comuns, mas ambas apresentaram problemas significativos à medida que os serviços cresciam:
2.1. Os custos ocultos de arquiteturas stateless
A maioria dos serviços na Databricks começou com um modelo sem estado. Em um modelo sem estado típico, o aplicativo não retém o estado na memória entre as solicitações e precisa ler novamente os dados do banco de dados a cada solicitação. Essa arquitetura é inerentemente cara, pois cada solicitação incorre em um acesso ao banco de dados, aumentando tanto os custos operacionais quanto a latência [1].
Para mitigar esses custos, os desenvolvedores geralmente introduziam um cache remoto (como Redis ou Memcached) para aliviar a carga de trabalho do banco de dados. Embora isso tenha melhorado o throughput e a latência, não resolveu várias ineficiências fundamentais:
- Latência de rede: cada solicitação ainda paga o "imposto" dos saltos de rede para a camada de cache.
- Sobrecarga de CPU: Ciclos significativos são desperdiçados na (des)serialização enquanto os dados se movem entre o cache e a aplicação [2].
- O problema do "Overread": Serviços stateless geralmente buscam objetos inteiros ou blobs grandes do cache apenas para usar uma pequena fração dos dados. Esses overreads desperdiçam largura de banda e memória, pois o aplicativo descarta a maior parte dos dados que acabou de buscar [2].
A mudança para um modelo particionado e o cache de estado na memória eliminaram essas camadas de sobrecarga, alocando o estado diretamente com a lógica que opera sobre ele. No entanto, o particionamento estático introduziu novos problemas.
2.2. A fragilidade do sharding estático
Antes do Dicer, os serviços com sharding no Databricks dependiam de técnicas de sharding estático (por exemplo, hashing consistente). Embora essa abordagem fosse simples e permitisse que nossos serviços armazenassem o estado em cache na memória com eficiência, ela introduziu três problemas críticos na produção:
- Indisponibilidade durante reinicializações e escalonamento automático: a falta de coordenação com um gerenciador de cluster levava a tempo de inatividade ou degradação do desempenho durante operações de manutenção, como atualizações contínuas ou ao escalonar um serviço dinamicamente. Os esquemas de sharding estático não conseguiam se ajustar proativamente às alterações na composição do backend, reagindo somente depois que um nó já havia sido removido.
- Split-brain prolongado e tempo de inatividade durante falhas: sem uma coordenação central, os clientes poderiam desenvolver visões inconsistentes do conjunto de pods de back-end quando os pods falhavam ou ficavam intermitentemente sem resposta. Isso resultou em cenários de "split-brain" (em que dois pods acreditavam possuir a mesma chave) ou até na queda total do tráfego de um cliente (em que nenhum pod acreditava possuir a chave).
- O problema da chave quente: por definição, o particionamento estático não consegue reequilibrar dinamicamente as atribuições de chave nem ajustar a replicação em resposta a mudanças de carga. Consequentemente, uma única "chave quente" sobrecarregaria um pod específico, criando um gargalo que poderia desencadear falhas em cascata em todo o fleet.
À medida que nossos serviços cresciam cada vez mais para atender à demanda, o sharding estático acabou se tornando uma péssima ideia. Isso levou a uma crença comum entre nossos engenheiros de que arquiteturas stateless eram a melhor maneira de construir sistemas robustos, mesmo que isso significasse arcar com os custos de desempenho e de recursos. Isso foi na época em que o Dicer foi introduzido.
2.3. Redefinindo a narrativa do serviço fragmentado
Os perigos em produção do sharding estático, em contraste com os custos de se tornar stateless, deixaram vários de nossos serviços mais críticos em uma posição difícil. Esses serviços dependiam do sharding estático para oferecer uma experiência de usuário ágil aos nossos clientes. Convertê-los para um modelo stateless teria introduzido uma penalidade de desempenho significativa, sem mencionar os custos de cloud adicionais para nós.
Desenvolvemos o Dicer para mudar isso. O Dicer resolve as deficiências fundamentais do sharding estático ao introduzir um plano de controle inteligente que atualiza de forma contínua e assíncrona as atribuições de shard de um serviço. Ele reage a uma ampla gama de sinais, incluindo a saúde da aplicação, carga, avisos de término e outras entradas ambientais. Como resultado, o Dicer mantém os serviços altamente disponíveis e bem balanceados mesmo durante reinicializações contínuas, travamentos, eventos de autoscale e períodos de grande desbalanceamento de carga.
Como um auto-sharder, o Dicer se baseia em uma longa linha de sistemas anteriores, incluindo Centrifuge [3], Slicer [4] e Shard Manager [5]. Apresentamos o Dicer na próxima seção e descrevemos como ele ajudou a melhorar o desempenho, a confiabilidade e a eficiência dos nossos serviços.
3. Dicer: sharding dinâmico para alto desempenho e disponibilidade
Apresentamos agora uma visão geral do Dicer, suas abstrações principais e descrevemos seus vários casos de uso. Aguarde uma análise técnica aprofundada do design e da arquitetura do Dicer em uma futura postagem no blog.
3.1 Visão geral do Dicer
O Dicer modela uma aplicação como servindo solicitações (ou executando algum trabalho) associado a uma chave lógica. Por exemplo, um serviço que serve perfis de usuário pode usar IDs de usuário como suas keys. O Dicer fragmenta a aplicação gerando continuamente uma atribuição de keys para pods para manter o serviço altamente disponível e com balanceamento de carga.
Para atingir escala para aplicações com milhões ou bilhões de keys, o Dicer opera em intervalos de keys em vez de keys individuais. As aplicações representam chaves para o Dicer usando uma SliceKey (um hash da chave da aplicação), e um intervalo contíguo de SliceKeys é chamado de Slice. Conforme mostrado na Figura 1, um Assignment do Dicer é um conjunto de Slices que juntos abrangem todo o espaço de chaves da aplicação, com cada Slice atribuído a um ou mais recursos (ou seja, pods). O Dicer divide, mescla, replica e reatribui Slices dinamicamente em resposta a sinais de integridade e carga da aplicação, garantindo que todo o espaço de chaves seja sempre atribuído a pods íntegros e que nenhum pod individual fique sobrecarregado. O Dicer também pode detectar chaves quentes e dividi-las em seus próprios slices, e atribuir tais slices a vários pods para distribuir a carga.
A Figura 1 mostra um exemplo de atribuição do Dicer em 3 pods (P0, P1 e P2) para um aplicativo particionado por ID de usuário, em que o usuário com ID 13 é representado pela SliceKey K26 (ou seja, um hash do ID 13) e está atualmente atribuído ao pod P0. Um usuário quente com ID de usuário 42 e representado pela SliceKey K10 foi isolado em sua própria fatia e atribuído a vários pods para lidar com a carga (P1 e P2).

{kind=link}
A Figura 2 mostra uma visão geral de um aplicativo fragmentado integrado ao Dicer. Os pods do aplicativo aprendem a atribuição atual por meio de uma biblioteca chamada de Slicelet (S de lado do servidor). O Slicelet mantém um cache local da atribuição mais recente, buscando-a no serviço Dicer e observando atualizações. Quando recebe uma atribuição atualizada, o Slicelet notifica o aplicativo por meio de uma API listener.
As atribuições observadas pelos Slicelets são eventualmente consistentes, uma escolha de design deliberada que prioriza a disponibilidade e a recuperação rápida em detrimento de garantias fortes de propriedade da chave. Em nossa experiência, esse tem sido o modelo certo para a grande maioria dos aplicativos, embora planejemos oferecer suporte a garantias mais fortes no futuro, de forma semelhante ao Slicer e ao Centrifuge.
Além de se manterem atualizados sobre a atribuição, os aplicativos também usam o Slicelet para registrar a carga por chave ao processar solicitações ou executar trabalho para uma chave. O Slicelet agrega essas informações localmente e reporta um resumo de forma assíncrona para o serviço Dicer. Observe que, assim como o monitoramento de atribuições, isso também ocorre fora do caminho crítico do aplicativo, garantindo alto desempenho.
Os clientes de um aplicativo fragmentado do Dicer encontram o pod atribuído para uma determinada key por meio de uma biblioteca chamada Clerk (C de client side). Assim como os Slicelets, os Clerks também mantêm ativamente um cache local da atribuição mais recente em segundo plano para garantir o alto desempenho para pesquisas de chave no caminho crítico.

Finalmente, o Dicer Assigner é o serviço de controlador responsável por gerar e distribuir atribuições com base nos sinais de integridade e carga da aplicação. Em sua essência, há um algoritmo de fragmentação que calcula ajustes mínimos por meio de divisões de Slice, mesclagens, replicação/desreplicação e movimentações para manter as chaves atribuídas a pods íntegros e a aplicação geral com balanceamento de carga suficiente. O serviço Assigner é multilocatário e projetado para fornecer serviço de fragmentação automática para todas as aplicações fragmentadas em uma região. Cada aplicação fragmentada atendida pelo Dicer é chamada de Target.
3.2 Vasta classe de aplicações aprimoradas pelo Dicer
O Dicer é valioso para uma ampla gama de sistemas porque a capacidade de criar afinidade para cargas de trabalho em pods específicos resulta em melhorias significativas de desempenho. Identificamos várias categorias principais de casos de uso com base em nossa experiência em produção.
Serviço em memória e com GPU
O Dicer se destaca em cenários onde um grande corpus de dados deve ser carregado e servido diretamente da memória. Ao garantir que as solicitações de keys específicas sempre cheguem aos mesmos pods, serviços como armazenamentos de chave-valor podem alcançar latência abaixo de um milissegundo e alta taxa de throughput, evitando a sobrecarga de buscar dados de um armazenamento remoto.
O Dicer também é bem adequado para cargas de trabalho de inferência de LLM modernos, em que manter a afinidade é fundamental. Os exemplos incluem sessões de usuário com estado (stateful) que acumulam contexto em um cache KV por sessão, bem como implantações que servem um grande número de adaptadores LoRA e devem particioná-los de forma eficiente em recursos de GPU limitados.
Sistemas de controle e agendamento
Este é um dos casos de uso mais comuns no Databricks. Isso inclui sistemas como gerenciadores de clusters e mecanismos de orquestração de query que monitoram continuamente os recurso para gerenciar dimensionamento, agendamento de compute e multilocação. Para operar com eficiência, esses sistemas mantêm o estado de monitoramento e controle localmente, evitando a serialização repetida e permitindo respostas oportunas a mudanças.
Caches remotos
O Dicer pode ser usado para criar caches remotos distribuídos de alto desempenho, o que já fizemos em produção na Databricks. Ao usar os recursos do Dicer, nosso cache pode ser autoscalado e reiniciado de forma transparente, sem perda na taxa de acerto, e evitar o desbalanceamento de carga devido a chaves.
Particionamento de Trabalho e Trabalho em Segundo Plano
O Dicer é uma ferramenta eficaz para particionar tarefas em segundo plano e fluxos de trabalho assíncronos em uma frota de servidores. Por exemplo, um serviço responsável pela limpeza ou coleta de lixo de estado em uma tabela massiva pode usar o Dicer para garantir que cada pod seja responsável por um intervalo distinto e não sobreposto do espaço de chaves, evitando trabalho redundante e contenção de bloqueio.
Agrupamento em lotes e agregação
Para caminhos de escrita de alto volume, o Dicer permite a agregação eficiente de registros. Ao rotear registros relacionados para o mesmo pod, o sistema pode agrupar atualizações em memória antes de commitá-las no armazenamento persistente. Isso reduz significativamente as operações de entrada/saída por segundo necessárias e melhora o throughput geral do pipeline de dados.
Seleção Flexível de Líder
O Dicer pode ser usado para implementar a seleção "suave" de líder, designando um pod específico como o coordenador principal para uma determinada chave ou shard. Por exemplo, um programador de serviço pode usar o Dicer para garantir que um único pod atue como a autoridade principal para gerenciar um grupo de recursos. Embora o Dicer atualmente forneça seleção de líder baseada em afinidade, ele serve como uma base poderosa para sistemas que exigem um primário coordenado sem a sobrecarga pesada dos protocolos de consenso tradicionais. Estamos explorando melhorias futuras para fornecer garantias mais fortes em torno da exclusão mútua para essas cargas de trabalho.
Rendezvous e Coordenação
O Dicer atua como um ponto de encontro natural para clientes distribuídos que precisam de coordenação em tempo real. Ao rotear todas as solicitações de uma key específica para o mesmo pod, esse pod se torna um ponto de encontro central onde o estado compartilhado pode ser gerenciado na memória local, sem saltos de rede externos.
Por exemplo, em um serviço de bate-papo em tempo real, dois clientes que entram no mesmo "ID da Sala de Bate-papo" são roteados automaticamente para o mesmo pod. Isso permite que o pod sincronize suas mensagens e estado instantaneamente na memória, evitando a latência de um banco de dados compartilhado ou de um back-plane complexo para comunicação.
4. Histórias de sucesso
Vários serviços na Databricks alcançaram ganhos significativos com o Dicer, e destacamos várias dessas histórias de sucesso abaixo.
4.1 Unity Catalog
O Unity Catalog (UC) é a solução de governança unificada para ativos de dados e AI na plataforma Databricks. Originalmente projetado como um serviço stateless, o UC enfrentou desafios significativos de escalabilidade à medida que sua popularidade crescia, impulsionado principalmente por um volume de leitura extremamente alto. Atender a cada solicitação exigia acesso repetido ao banco de dados de backend, o que introduzia uma latência proibitiva. Abordagens convencionais, como o cache remoto, não eram viáveis, pois o cache precisava ser atualizado incrementalmente e permanecer consistente com o snapshot do armazenamento. Além disso, os catálogos de clientes podem ter gigabytes de tamanho, tornando cara a manutenção de Snapshots parciais ou replicados em um cache remoto sem introduzir uma sobrecarga substancial.
Para resolver isso, a equipe integrou o Dicer para criar um cache stateful em memória e fragmentado. Essa mudança permitiu que a UC substituísse chamadas de rede remotas e caras por chamadas de método locais, reduzindo drasticamente a carga do banco de dados e melhorando a capacidade de resposta. A figura abaixo ilustra o lançamento inicial do Dicer, seguido pela implantação da integração completa do Dicer. Ao utilizar a afinidade stateful do Dicer, a UC alcançou uma taxa de acerto de cache de 90 a 95%, reduzindo significativamente a frequência de round-trips do banco de dados.

{kind=link}
4.2 Mecanismo de orquestração de queries SQL
O mecanismo de orquestração de queries do Databricks, que gerencia o agendamento de queries em clusters Spark, foi originalmente criado como um serviço stateful em memória usando sharding estático. À medida que o serviço escalava, as limitações dessa arquitetura se tornaram um gargalo significativo; devido à implementação simples, o escalonamento exigia re-sharding manual, o que era extremamente trabalhoso, e o sistema sofria com quedas frequentes de disponibilidade, mesmo durante reinicializações contínuas.
Após a integração com o Dicer, esses problemas de disponibilidade foram eliminados (veja a Figura 4). O Dicer permitiu zero tempo de inatividade durante reinicializações e eventos de escalonamento, permitindo que a equipe reduzisse o trabalho repetitivo e melhorasse a robustez do sistema ao habilitar o escalonamento automático em todos os lugares. Além disso, o recurso de balanceamento de carga dinâmico do Dicer resolveu ainda mais a limitação crônica de CPU, resultando em um desempenho mais consistente em todo o fleet.
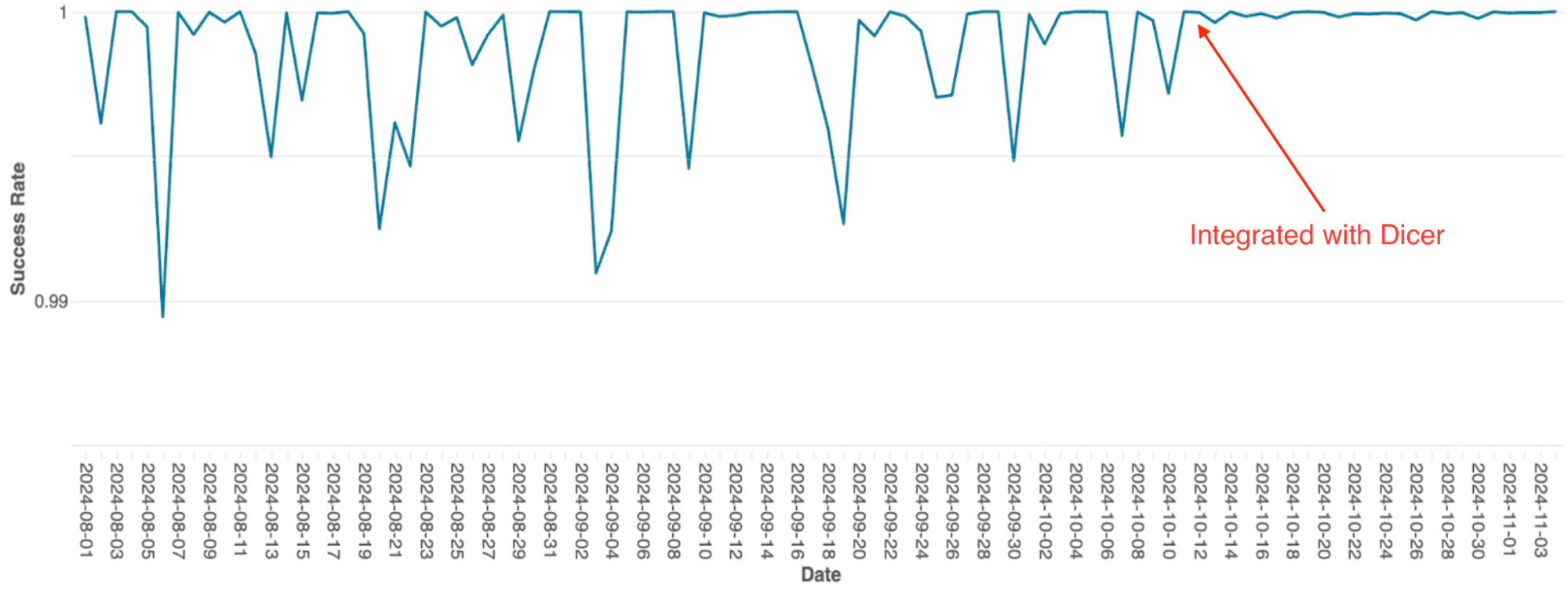
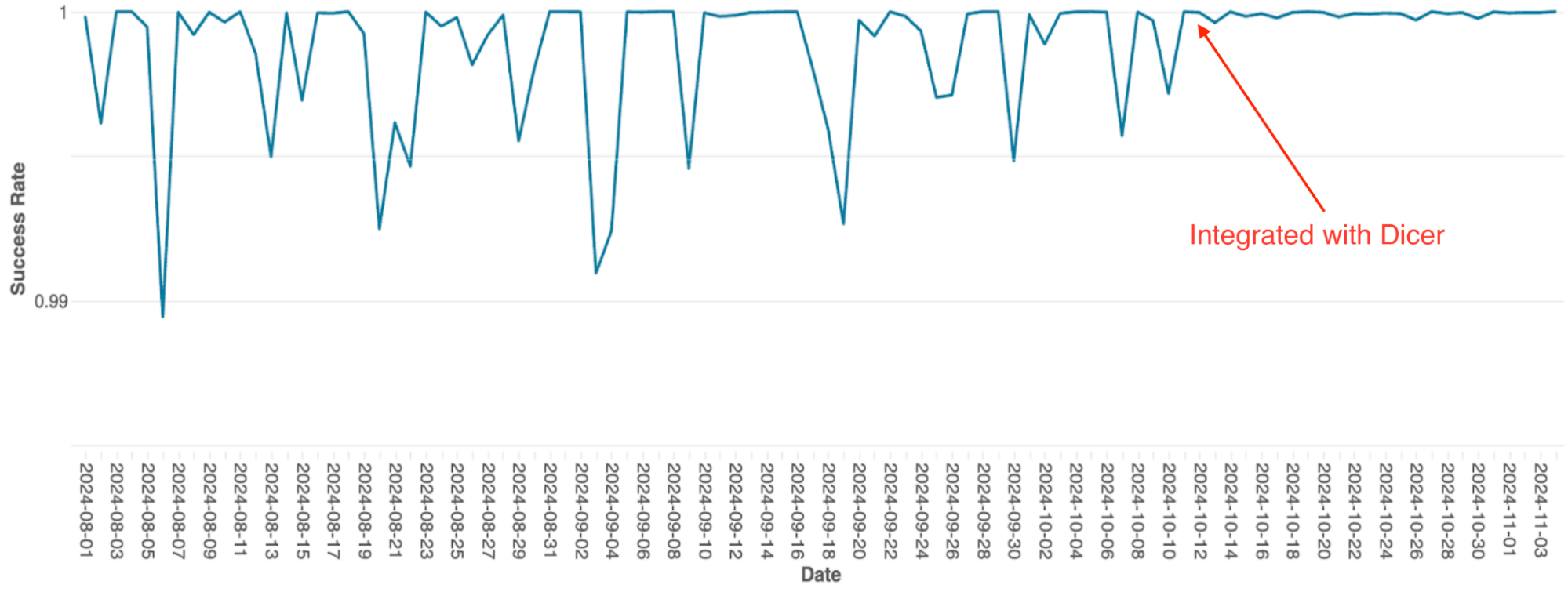{kind=link}
4.3 Cache remoto Softstore
Para serviços que não são fragmentados, desenvolvemos o Softstore, um cache distribuído de key-valor remoto. O Softstore aproveita um recurso do Dicer chamado transferência de estado, que migra dados entre pods durante o resharding para preservar o estado da aplicação. Isso é particularmente importante durante reinicializações contínuas planejadas, nas quais todo o espaço de chaves é inevitavelmente rotacionado. Em nosso parque de produção, as reinicializações planejadas representam cerca de 99,9% de todas as reinicializações, o que torna este mecanismo especialmente impactante e permite reinicializações contínuas com impacto insignificante nas taxas de acerto do cache. A Figura 5 mostra as taxas de acerto do Softstore durante uma reinicialização contínua, em que a transferência de estado preserva uma taxa de acerto estável de ~85% para um caso de uso representativo, com a variabilidade restante impulsionada pelas flutuações normais da carga de trabalho.
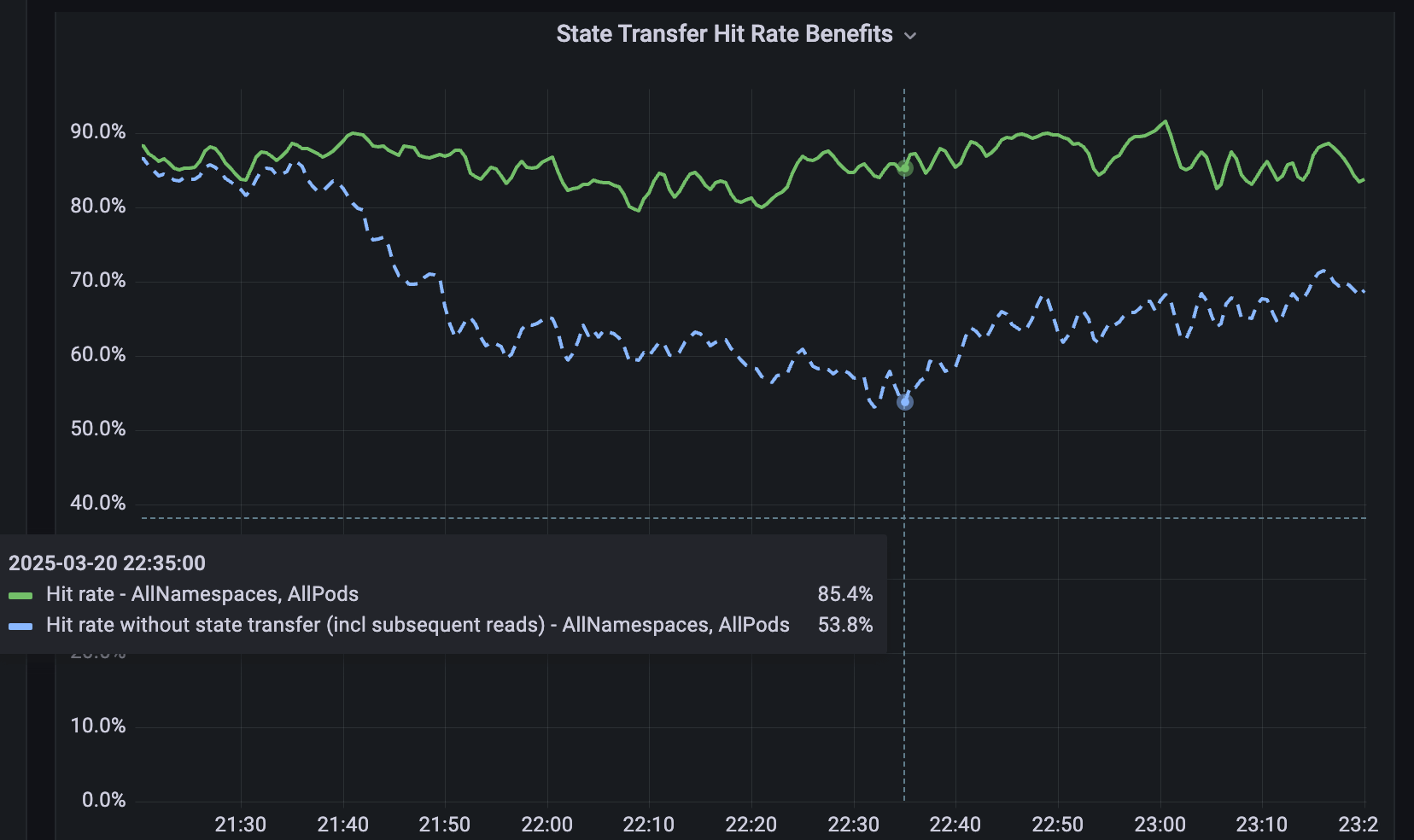
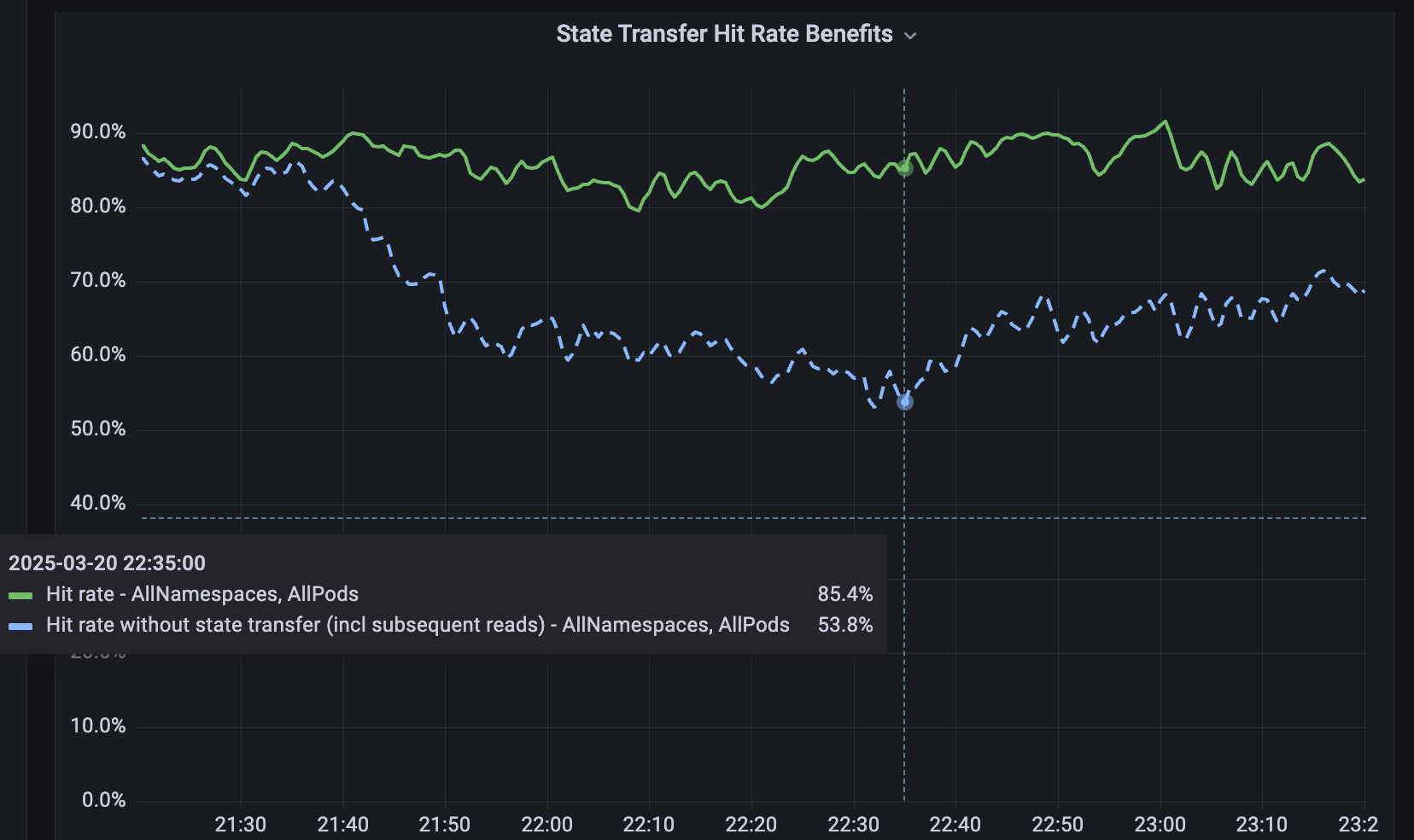{kind=link}
5. Agora você também pode usá-lo!
Você pode experimentar o Dicer hoje mesmo na sua máquina fazendo o download aqui. Uma demonstração simples para mostrar seu uso é fornecida aqui. Ela mostra uma configuração de exemplo do Dicer com um cliente e alguns servidores para uma aplicação. Consulte o README e o guia do usuário do Dicer.
6. Próximos recursos e artigos
O Dicer é um serviço crítico usado em todo o Databricks, e seu uso está crescendo rapidamente. No futuro, publicaremos mais artigos sobre o funcionamento interno e os designs do Dicer. Também lançaremos mais recursos à medida que os construímos e testamos internamente, por exemplo, bibliotecas Java e Rust para clientes e servidores, e os recursos de transferência de estado mencionados nesta postagem. Dê seu feedback e fique por dentro das novidades!
Se você gosta de resolver problemas de engenharia complexos e gostaria de se juntar à Databricks, confira databricks.com/careers!
7. Referências
[1] Ziming Mao, Jonathan Ellithorpe, Atul Adya, Rishabh Iyer, Matei Zaharia, Scott Shenker, Ion Stoica (2025). Rethinking the cost of distributed caches for datacenter serviços. Proceedings of the 24th ACM Workshop on Hot Topics in Networks, 1–8.
[2] Atul Adya, Robert Grandl, Daniel Myers, Henry Qin. Fast key-value stores: An idea whose time has come and gone. Anais do Workshop on Hot Topics in Operating Systems (HotOS ’19), 13 a 15 de maio de 2019, Bertinoro, Itália. ACM, 7 páginas. DOI: 10.1145/3317550.3321434.
[3] Atul Adya, James Dunagan, Alexander Wolman. Centrifuge: Gerenciamento de concessão integrado e particionamento para serviços em cloud. Anais do 7º Simpósio da USENIX sobre Projeto e Implementação de Sistemas em Rede (NSDI), 2010.
[4] Atul Adya, Daniel Myers, Jon Howell, Jeremy Elson, Colin Meek, Vishesh Khemani, Stefan Fulger, Pan Gu, Lakshminath Bhuvanagiri, Jason Hunter, Roberto Peon, Larry Kai, Alexander Shraer, Arif Merchant, Kfir Lev-Ari. Slicer: Auto-Sharding para Aplicações de Datacenter. Anais do 12º Simpósio USENIX sobre Design e Implementação de Sistemas Operacionais (OSDI), 2016, pp. 739–753.
[5] Sangmin Lee, Zhenhua Guo, Omer Sunercan, Jun Ying, Chunqiang Tang, et al. Shard Manager: A Generic Shard Management Framework for Geo distributed Applications. Anais do 28º Simpósio da ACM SIGOPS sobre Princípios de Sistemas Operacionais (SOSP), 2021. DOI: 10.1145/3477132.3483546.
[6] Atul Adya, Jonathan Ellithorpe. Serviços com estado (stateful): baixa latência, eficiência, escalabilidade — escolha três. Workshop de Sistemas de Transação de Alto Desempenho (HPTS) 2024, Pacific Grove, Califórnia, 15 a 18 de setembro de 2024.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.