Chatbot de futebol auto-otimizável guiado por especialistas de domínio no Databricks
Um guia prático para criar, implantar, avaliar e governar um assistente agêntico que ajuda os coordenadores de defesa a antecipar as tendências do oponente e se otimiza continuamente com base no feedback de especialistas no assunto.
por Wesley Pasfield e Nick Ragonese
- Objetivo: Criar um assistente de agente voltado para o treinador que responde a perguntas como “O que este ataque fará?” usando ferramentas governadas e de nível de produção sobre dados de jogada a jogada, participação e escalação.
- Abordagem: Criar um agente de chamada de ferramenta com funções do Unity Catalog (análise SQL sobre Delta) e implantar via Agent Framework com MLflow Tracing. Implementar um loop de auto-otimização onde o feedback do SME capturado nas sessões de rotulagem do MLflow ensina juízes alinhados (align()) que impulsionam a melhoria automática de prompts (optimize_prompts()), codificando o conhecimento especializado em futebol diretamente no sistema.
- Resultado: Os coordenadores obtêm tendências com reconhecimento de situação (descida e distância, formação/pessoal, ataque de dois minutos, taxas de screen) com iteração rápida e verificações de qualidade prontas para as instalações da semana do jogo. Os desenvolvedores obtêm uma arquitetura reutilizável para qualquer domínio: capturar feedback de especialistas, alinhar os juízes ao que “bom” significa para o seu caso de uso e permitir que o sistema melhore continuamente com a otimização de prompts orientada pelos juízes alinhados.
Juízes LLM genéricos e prompts estáticos não conseguem capturar nuances específicas do domínio. Determinar o que torna uma análise defensiva de futebol americano “boa” exige profundo conhecimento de futebol americano: esquemas de cobertura, tendências de formação, contexto situacional. Avaliadores de propósito geral deixam isso passar. O mesmo vale para revisão jurídica, triagem médica, due diligence financeiro ou qualquer domínio onde o julgamento de especialistas importa.
Esta postagem apresenta uma arquitetura para agentes com auto-otimização construída no Databricks Agent Framework, onde o conhecimento humano específico da empresa melhora continuamente a qualidade da IA usando o MLflow, e os desenvolvedores controlam toda a experiência. Usamos um Assistente de Coordenador Defensivo (CD) de Futebol Americano como exemplo prático nesta postagem: um agente de chamada de ferramentas que pode responder a perguntas como "Quem recebe a bola na formação de 11 jogadores em uma terceira descida para 6 jardas?" ou "O que o adversário faz nos últimos 2 minutos de cada tempo?" O exemplo a seguir mostra esse agente interagindo com um usuário por meio do Databricks Apps.

De Agente a Sistema Auto-otimizável
A solução tem duas fases: construir o agente e, em seguida, otimizá-lo continuamente com o feedback de especialistas.
Construir
- Ingerir dados: Carregue os dados do domínio (jogada a jogada, participação, escalações) em tabelas Delta governadas no Unity Catalog.
- Ingerimos dois anos (2023–2024) de dados de participação e jogada a jogada de futebol americano do
`nflreadpy`como os dados para este agente.
- Ingerimos dois anos (2023–2024) de dados de participação e jogada a jogada de futebol americano do
- Criar ferramentas: Defina funções SQL como ferramentas do Unity Catalog que o agente pode chamar, aproveitando os dados extraídos.
- Defina e implante o agente: vincule as ferramentas a um
ResponsesAgent, registre um prompt de sistema de linha de base no Prompt Registry e implante no Model Serving. - Avaliação inicial: Execute a avaliação automatizada com juízes LLM e registre os rastros usando versões de linha de base de juízes personalizados.
Otimizar
- Capture o feedback de especialistas: os SMEs analisam os resultados do agente e fornecem feedback estruturado por meio de sessões de rotulagem do MLflow.
- Alinhar juízes: use a função
align()do MLflow para calibrar o juiz LLM de linha de base para corresponder às preferências do especialista no assunto (SME), ensinando-o o que é considerado "bom" para este domínio. - Otimizar prompts:
o `optimize_prompts()`do MLflow usa um otimizador GEPA guiado pelo juiz alinhado para melhorar iterativamente o prompt de sistema original. - Repetir: Cada sessão de rotulagem do MLflow é usada para aprimorar o juiz, que por sua vez é usado para otimizar o prompt do sistema. Todo esse processo pode ser automatizado para promover automaticamente novas versões de prompt que excedam os benchmarks de desempenho, ou pode informar atualizações manuais no agente, como adicionar mais ferramentas ou dados, com base nos modos de falha observados.
A fase de construção leva você a um protótipo inicial, e a fase de otimização acelera você para a produção, otimizando continuamente seu agente usando o feedback de especialistas do domínio como motor.
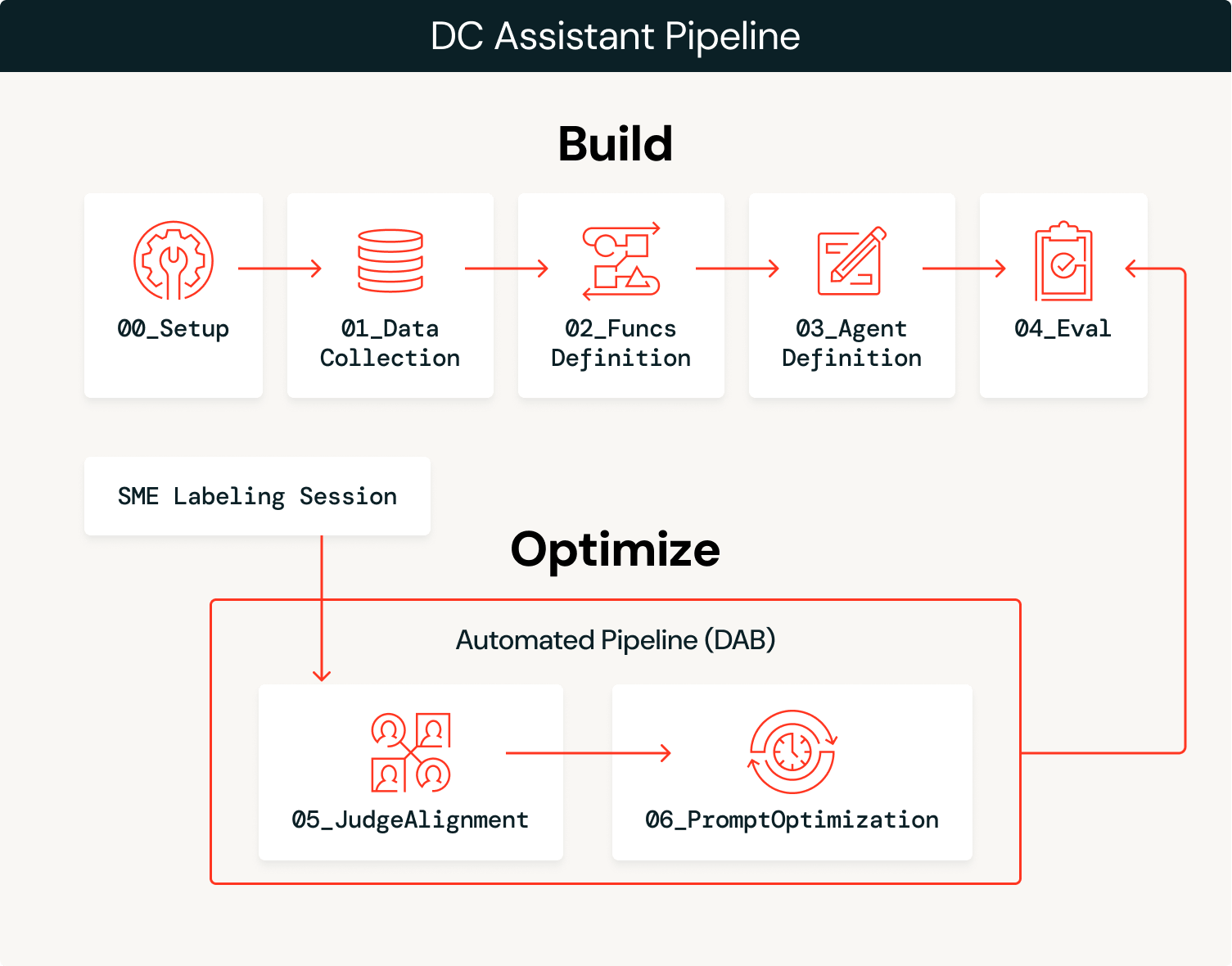
Visão geral da arquitetura
O agente equilibra probabilismo e determinismo: um LLM interpreta a intenção semântica das user queries e seleciona as ferramentas certas, enquanto as funções SQL determinísticas extraem dados com 100% de precisão. Por exemplo, quando um treinador pergunta “Como nosso adversário ataca o Blitz?”, o LLM interpreta isso como um pedido de análise de pass-rush/cobertura e seleciona success_by_pass_rush_and_coverage(). A função SQL retorna estatísticas exatas dos dados subjacentes. Ao usar as funções do Unity Catalog, garantimos que as estatísticas sejam 100% precisas, enquanto o LLM lida com o contexto da conversa.
| Passo | tecnología |
|---|---|
| Ingerir dados | Delta Lake + Unity Catalog |
| Crie ferramentas | Função do Unity Catalog |
| Implantar agente | ResponsesAgent + Model Serving via agents.deploy() |
| Avalie com um LLM como juiz | MLflow GenAI evaluate() com avaliadores integrados e personalizados |
| Capturar feedback | Sessões de rotulagem do MLflow para feedback das PMEs |
| Alinhar juízes | MLflow align() usando um otimizador SIMBA personalizado |
| Otimize os prompts | MLflow optimize_prompts() usando um otimizador GEPA |
Vamos percorrer cada passo com o código e as saídas da implementação do DC Assistant.
Construir
1. Ingerir dados.
Um notebook de configuração (00_setup.ipynb) define todas as variáveis de configuração globais usadas em todo o fluxo de trabalho: catálogo/esquema do workspace, experimento do MLflow, endpoints do LLM, nomes de modelos, datasets de avaliação, nomes de ferramentas do Unity Catalog e configurações de autenticação. Essa configuração é persistida em config/dc_assistant.json e carregada por todos os notebooks posteriores, garantindo a consistência em todo o pipeline. Este passo é opcional, mas ajuda na organização geral.
Com esta configuração em vigor, carregamos dados de futebol americano via nflreadpy e aplicamos processamento incremental para prepará-los para o consumo do agente: descartando colunas não utilizadas, padronizando esquemas e persistindo tabelas Delta limpas no Unity Catalog. Aqui está um exemplo simples de carregamento dos dados que não aborda muito do processamento de dados:
As saídas deste processo são tabelas Delta governadas no Unity Catalog (jogada a jogada, participação, escalações, equipes, jogadores) que estão prontas para a criação de ferramentas e o consumo de agentes.
2. Crie ferramentas.
O agente precisa de ferramentas determinísticas para query os dados subjacentes. Nós as definimos como funções SQL do Unity Catalog que calculam tendências ofensivas em várias dimensões situacionais. Cada função recebe parâmetros como team e season e retorna estatísticas agregadas que o agente pode usar para responder a perguntas do coordenador. Usamos apenas funções baseadas em SQL para este exemplo, mas é possível configurar funções de UC baseadas em Python, índices de pesquisa vetorial, ferramentas do Protocolo de Contexto de Modelo (MCP) e espaços do Genie como funcionalidade adicional que um agente pode aproveitar para complementar o LLM que supervisiona o processo.
O exemplo a seguir mostra success_by_pass_rush_and_coverage(), que calcula as divisões de passe/execução, EPA (Pontos Esperados Adicionados), taxa de sucesso e jardas ganhas, agrupados por número de pass rushers e tipo de cobertura defensiva. A função inclui um COMMENT que descreve sua finalidade, que o LLM usa para determinar quando chamá-la.
Como essas funções residem no Unity Catalog, elas herdam o modelo de governança da plataforma: controles de acesso baseados em função, acompanhamento de linhagem e capacidade de descoberta em todo o workspace. As equipes podem encontrar e reutilizar ferramentas sem duplicar a lógica, e os administradores mantêm a visibilidade dos dados que o agente pode acessar.
3. Defina e implante o agente.
Criar o agente pode ser tão simples quanto usar o AI Playground. Selecione o LLM que você quer usar, adicione suas ferramentas do Unity Catalog, defina seu prompt de sistema e clique em “Criar notebook do agente” para exportar um notebook que produz um agente no formato ResponsesAgent. A captura de tela a seguir mostra este fluxo de trabalho em ação. O notebook exportado contém a estrutura de definição do agente, conectando suas funções do UC ao agente por meio do UCFunctionToolkit.
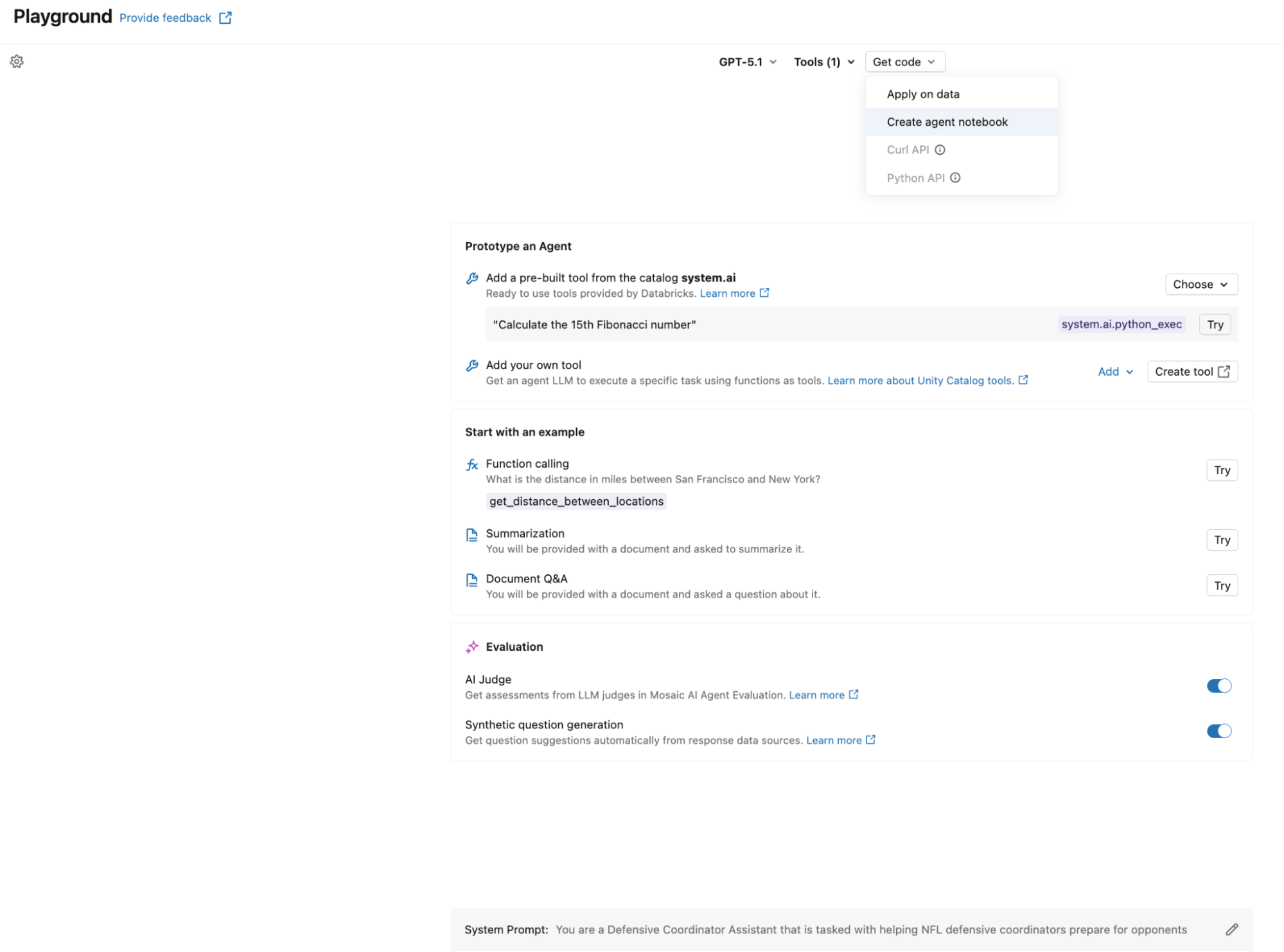
Para habilitar o loop de auto-otimização, registramos o prompt do sistema no Prompt Registry em vez de fixá-lo no código. Isso permite que a fase de otimização atualize o prompt sem reimplantar o agente:
Depois que o código do agente for testado e o modelo for registrado no Unity Catalog, implantá-lo em um endpoint persistente é tão simples quanto o código abaixo. Isso cria um endpoint de Model Serving com o MLflow Tracing ativado, tabelas de inferência para registrar solicitações/respostas e dimensionamento automático:
Para acesso do usuário final, o agente também pode ser implantado como um Databricks App, fornecendo uma interface de chat que coordenadores e analistas podem usar diretamente sem precisar de acesso a notebooks ou API. A captura de tela na introdução mostra esta implantação baseada em App em ação.
4. Avaliação inicial.
Com o agente implantado, executamos uma avaliação automatizada usando juízes LLM para estabelecer uma medição de qualidade de referência. O MLflow é compatível com vários tipos de juízes, e usamos três em combinação.
Juízes integrados lidam com critérios de avaliação comuns prontamente. RelevanceToQuery() verifica se a resposta aborda a pergunta do usuário. Juízes baseados em diretrizes avaliam em relação a regras específicas baseadas em texto, numa base de aprovação/reprovação. Definimos uma diretriz para garantir que as respostas usem a terminologia de futebol profissional adequada:
Juízes personalizados usam make_judge() para avaliação específica do domínio com controle total sobre os critérios de pontuação. Este é o juiz que alinharemos ao feedback do SME na fase de otimização:
Com todos os juízes definidos, podemos fazer uma execução contra o dataset:
O juiz personalizado football_analysis_base fornece uma pontuação de referência, mas ele apenas reflete uma tentativa de melhor esforço para fornecer uma rubrica do zero que o LLM pode usar para seus julgamentos, em vez de um verdadeiro conhecimento de domínio. A UI do MLflow Experiments nos mostra o desempenho do agente neste juiz de referência, bem como uma justificativa para a pontuação em cada exemplo.
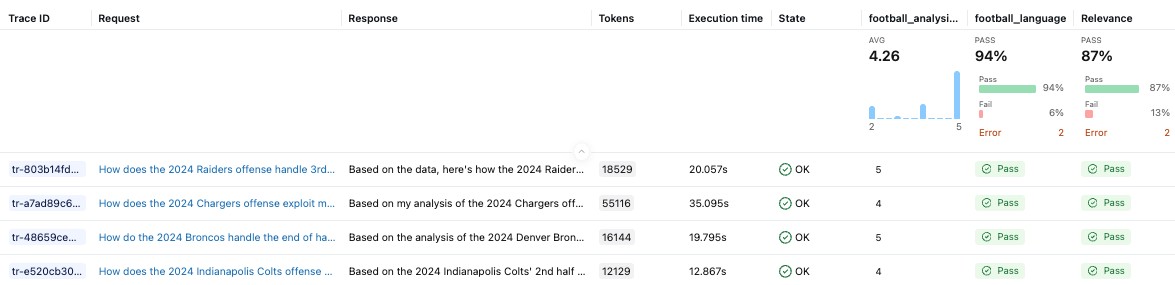

Na fase de otimização, alinharemos o juiz de análise de futebol com as preferências do SME, ensinando a ele o que “bom” realmente significa para a análise do coordenador defensivo.
Otimizar
5. Capture o feedback de especialistas.
Com o agente implantado e a avaliação de linha de base concluída, entramos no ciclo de otimização. É aqui que o conhecimento de domínio é codificado no sistema, primeiro por meio de juízes LLM alinhados e, em seguida, diretamente no agente, através da otimização do prompt do sistema guiada pelo nosso juiz alinhado.
Começamos criando um esquema de rótulos que usa as mesmas instruções e critérios de avaliação do juiz de análise de futebol que criamos com make_judge(). Em seguida, criamos uma sessão de rotulagem que permite que nosso especialista de domínio revise as respostas para os mesmos rastreamentos usados no job evaluate() e forneça suas pontuações e feedback por meio do Aplicativo de Revisão (ilustrado abaixo).
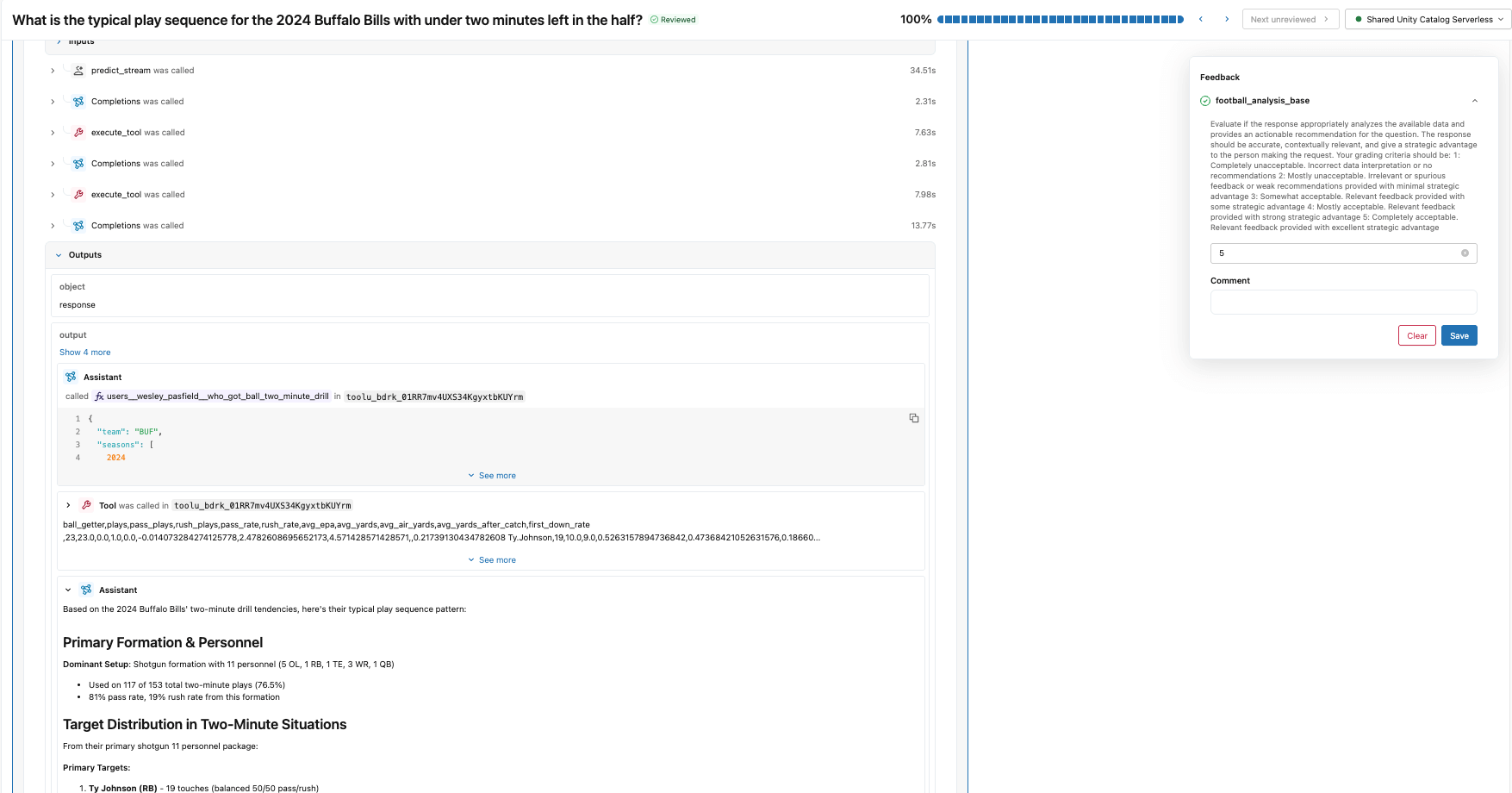
Este feedback se torna a verdade fundamental para o alinhamento do juiz. Analisando onde as pontuações do juiz de referência e do SME divergem, aprendemos o que o juiz está errando sobre este domínio específico.
6. Alinhar juízes.
Agora que temos rastros que incluem tanto o feedback de especialistas do domínio quanto o feedback do juiz LLM, podemos aproveitar a funcionalidade align() do MLflow para alinhar nosso juiz LLM ao feedback dos nossos especialistas do domínio. Um juiz alinhado reflete a perspectiva dos seus especialistas do domínio e os dados exclusivos da sua organização. O alinhamento traz especialistas do domínio para o processo de desenvolvimento de uma forma que antes não era possível: o feedback do domínio molda diretamente como o sistema mede a qualidade, tornando as métricas de desempenho do agente confiáveis e escaláveis.
align() permite que você use seu próprio otimizador ou o otimizador binário default SIMBA (Simplified Multi-Bootstrap Aggregation). Nesse caso, utilizamos um otimizador SIMBA personalizado para calibrar um juiz de escala Likert:
Em seguida, recuperamos os rastros que têm tanto as pontuações do juiz LLM quanto o feedback do SME que marcamos ao longo do processo. Essas pontuações pareadas são o que o SIMBA usa para aprender a lacuna entre o julgamento genérico e o de especialistas.
A captura de tela a seguir mostra o processo de alinhamento em andamento. O modelo identifica lacunas entre os juízes LLM e o feedback do SME, propõe novas regras e detalhes para incorporar ao juiz para fechar essas lacunas e, em seguida, avalia os novos juízes candidatos para ver se eles superam o desempenho do juiz de referência.

O resultado final deste processo é um juiz alinhado que reflete diretamente o feedback de especialistas do domínio com instruções detalhadas.

Dicas para um alinhamento eficaz:
- O objetivo do alinhamento é fazer com que você sinta que tem especialistas no domínio sentados ao seu lado durante o desenvolvimento. Esse processo pode levar a pontuações de desempenho mais baixas para o agente de linha de base, o que significa que o juiz de linha de base foi subespecificado. Agora que você tem um juiz que critica o agente da mesma forma que seus SMEs o fariam, você pode fazer melhorias manuais ou automatizadas para melhorar o desempenho.
- O processo de alinhamento depende da qualidade do feedback fornecido. Foque na qualidade, não na quantidade. Um feedback detalhado e consistente em um número menor de exemplos (mínimo de 10) produz melhores resultados do que um feedback inconsistente em muitos exemplos.
Definir a qualidade costuma ser o principal obstáculo para melhorar o desempenho do agente. Independentemente da técnica de otimização, se não houver uma definição clara de qualidade, o desempenho do agente deixará a desejar. A Databricks oferece um workshop que ajuda os clientes a definir a qualidade por meio de um exercício iterativo e multifuncional. Para saber mais, entre em contato com sua equipe de contas da Databricks ou preencha este formulário.
7. Otimize os prompts.
Com um juiz alinhado que reflete as preferências do SME, agora podemos melhorar automaticamente o prompt de sistema do agente. A função optimize_prompts() do MLflow usa o GEPA para refinar iterativamente o prompt com base na pontuação do juiz alinhado. O GEPA (Genetic-Pareto), cocriado por Matei Zaharia, CTO da Databricks, é um algoritmo de prompt genético-evolutivo que utiliza modelos de linguagem grandes para realizar mutações reflexivas em prompts, permitindo que ele refine iterativamente as instruções e supere as técnicas tradicionais de aprendizado por reforço na otimização do desempenho do modelo.
Em vez de um desenvolvedor adivinhar quais adjetivos adicionar ao prompt de sistema, o otimizador GEPA evolui matematicamente o prompt para maximizar a pontuação específica definida pelo especialista. O processo de otimização requer um dataset com respostas esperadas que orientam o otimizador para os comportamentos desejados, como este:
O otimizador GEPA usa o prompt de sistema atual e propõe melhorias iterativamente, avaliando cada candidato em relação ao juiz alinhado. Aqui, usamos o prompt inicial, o conjunto de dados de otimização que criamos e o juiz alinhado para aproveitar o optimize_prompts() do MLflow. Em seguida, usamos o otimizador GEPA para criar um novo prompt de sistema orientado por nosso juiz alinhado:
A captura de tela a seguir mostra a mudança no prompt do sistema: o antigo está à esquerda e o novo à direita. O prompt final escolhido é aquele com a pontuação mais alta, conforme medido pelo nosso juiz alinhado. O novo prompt foi truncado por questões de espaço, mas fica claro neste exemplo que conseguimos incorporar respostas de especialistas do domínio para criar um prompt fundamentado em linguagem específica do domínio com orientações explícitas sobre como lidar com certas solicitações.

A capacidade de gerar esse tipo de orientação automaticamente usando o feedback de SMEs permite que seus SMEs instruam indiretamente um agente apenas fornecendo feedback sobre os rastros do agente.
Neste caso, o novo prompt gerou um desempenho melhor em nosso dataset de otimização de acordo com nosso juiz alinhado, portanto, demos ao prompt recém-registrado o alias de produção, o que nos permitiu reimplantar nosso agente com este prompt aprimorado.
Dicas para otimização de prompt:
- O dataset de otimização deve abranger a diversidade de queries que seu agente processará. Inclua casos extremos, solicitações ambíguas e cenários em que a seleção de ferramentas é importante.
- As respostas esperadas devem descrever o que o agente deve fazer (quais ferramentas chamar, quais informações incluir) em vez do texto de saída exato.
- Comece com
max_metric_callsdefinido entre50e100. Valores mais altos exploram mais candidatos, mas aumentam o custo e o runtime. - O otimizador GEPA aprende com os modos de falha. Se o juiz alinhado penalizar a ausência de benchmarks ou ressalvas de amostras pequenas, o GEPA injetará esses requisitos no prompt otimizado.
8. Fechando o ciclo: Automação e melhoria contínua.
Os passos individuais que percorremos podem ser orquestrados em um pipeline de otimização contínua, no qual a rotulagem do especialista de domínio se torna o trigger para o ciclo de otimização, e tudo pode ser englobado em um job do Databricks usando Asset Bundles:
- Os SMEs rotulam as saídas do agente através da UI da Sessão de Rotulagem do MLflow, fornecendo pontuações e comentários em rastreamentos de produção reais.
- O pipeline detecta novos rótulos e extrai traces com o feedback de SMEs e as pontuações de base do juiz LLM.
- As execuções de alinhamento do juiz produzem uma nova versão do juiz calibrada de acordo com as preferências mais recentes do SME.
- As execuções de otimização de prompt usam o juiz alinhado para melhorar iterativamente o prompt do sistema.
- A promoção condicional leva o novo prompt à produção se ele exceder os limites de desempenho. Isso pode envolver o acionamento de outro job de avaliação para garantir que o novo prompt seja generalizado para outros exemplos.
- O agente melhora automaticamente à medida que o registro de prompts fornece a versão otimizada.
Quando os especialistas de domínio concluem uma sessão de rotulagem, um job evaluate() é acionado para gerar pontuações do juiz LLM nos mesmos rastreamentos. Quando o job evaluate() é concluído, um job align() �é executado para alinhar o juiz LLM com o feedback do especialista de domínio. Quando esse job é concluído, um job optimize_prompts() é executado para gerar um novo prompt de sistema aprimorado que pode ser imediatamente testado em um novo dataset e, se apropriado, promovido para produção.
Todo este processo pode ser totalmente automatizado, mas a revisão manual também pode ser inserida em qualquer passo, dando aos desenvolvedores controle total sobre o nível de automação envolvido. O processo se repete à medida que os SMEs continuam rotulando, resultando em testes rápidos de desempenho em novas versões do agente e ganhos de desempenho cumulativos nos quais os desenvolvedores podem realmente confiar.
Conclusão
Essa arquitetura transforma a forma como os agentes melhoram ao longo do tempo, usando o Databricks Agent Framework e o MLflow. Em vez de os desenvolvedores adivinharem o que constitui uma boa resposta, os especialistas do domínio moldam diretamente o comportamento do agente por meio do feedback de especialistas. Os processos de alinhamento e otimização do juiz traduzem o conhecimento do domínio em mudanças concretas no sistema, enquanto os desenvolvedores mantêm o controle sobre todo o sistema, incluindo quais partes automatizar e onde permitir intervenção manual.
Nesta publicação, ilustramos como personalizar um agente para refletir a linguagem e os detalhes específicos que são importantes para os especialistas de domínio no futebol profissional. O DC Assistant demonstra o padrão, mas a abordagem funciona para qualquer domínio em que o julgamento de especialistas é importante: revisão de documentos legais, preparação de rebatidas no beisebol profissional, triagem médica, análise de tacadas de golfe, escalonamento de suporte ao cliente ou qualquer outra aplicação em que "bom" é difícil para os desenvolvedores especificarem sem o apoio de especialistas de domínio.
Experimente em seu próprio problema de domínio específico e veja como ele pode impulsionar a melhoria automatizada e contínua com base no feedback do SME!
Saiba mais sobre o Databricks Sports e o Agent Bricks ou solicite uma demonstração para ver como sua organização pode gerar percepções competitivas.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.