Sinalização de recursos de alta disponibilidade na Databricks
Como construímos um sistema de sinalizador de recurso com zero tempo de inatividade para a infraestrutura global da Databricks
por Benjamin Congdon
- A SAFE é a plataforma interna de feature flagging da Databricks que permite aos engenheiros desacoplar a implantação de código da ativação de recursos, permitindo rollouts mais seguros e uma mitigação de incidentes mais rápida em centenas de serviços
- Esta postagem descreve a arquitetura da SAFE, que lida com >25.000 flags ativas e mais de 300 milhões de avaliações por segundo com latência na escala de microssegundos por meio de técnicas como pré-avaliação de dimensão estática e entrega global em várias camadas.
- O sistema alcança alta confiabilidade por meio de mecanismos de resiliência em camadas, incluindo comportamento fail-static, caminhos de entrega fora de banda e pacotes de configuração de inicialização a frio que garantem que os serviços continuem operando mesmo durante falhas no pipeline de entrega.
Entregar software rapidamente e, ao mesmo tempo, manter a confiabilidade é um desafio constante. À medida que a Databricks cresceu, também aumentou a complexidade de implementar alterações com segurança em centenas de serviços, várias clouds e milhares de cargas de trabalho de clientes. Os feature flags nos ajudam a gerenciar essa complexidade, separando a decisão de implantar o código da decisão de habilitá-lo. Essa separação permite que os engenheiros isolem falhas e mitiguem incidentes mais rapidamente, sem sacrificar a velocidade de entrega.
Um dos principais componentes da estratégia de estabilidade do Databricks é a nossa plataforma interna de feature flagging e experimentação, chamada "SAFE". Os engenheiros do Databricks usam o SAFE diariamente para lançar recursos, controlar o comportamento do serviço dinamicamente e medir a eficácia de seus recursos com experimentos A/B.
Plano de fundo
O SAFE foi iniciado com o objetivo "norte" de desacoplar totalmente os lançamentos de binários de serviço da ativação de recursos, permitindo que as equipes implementem recursos independentemente da implantação de seus binários. Isso permite muitos benefícios secundários, como a capacidade de disponibilizar um recurso de forma confiável e progressiva para grupos de usuários cada vez maiores, e mitigar rapidamente os incidentes causados por uma implementação.
Na escala da Databricks, atendendo a milhares de clientes corporativos em múltiplas clouds com uma superfície de produto em rápido crescimento, precisávamos de um sistema de sinalização de recurso que atendesse aos nossos requisitos exclusivos:
- Padrões elevados para segurança e gerenciamento de mudanças. A principal proposta de valor para o SAFE era melhorar a estabilidade e a postura operacional da Databricks, portanto, quase todos os outros requisitos decorreram disso.
- Multinuvem, entrega global e contínua no Azure, AWS e GCP, com latência de avaliação de flag abaixo de um milissegundo para dar suporte a serviços de produção de alta throughput e sensíveis à latência.
- Suporte transparente para todos os locais onde os engenheiros do Databricks escrevem código, incluindo nosso plano de controle, a UI do Databricks, o Databricks Runtime Environment e o plano de dados Serverless do Databricks.
- Uma interface que era opinativa o suficiente sobre as práticas de lançamento da Databricks para tornar os lançamentos de flags comuns "seguros por padrão", mas flexível o suficiente para suportar um grande conjunto de casos de uso mais esotéricos.
- Requisitos de disponibilidade extremamente rigorosos, pois os serviços não podem ser iniciados com segurança sem o carregamento das definições de flag.
Após considerarmos cuidadosamente esses requisitos, finalmente optamos por construir um sistema de sinalização de recurso personalizado e interno. Precisávamos de uma solução que pudesse evoluir junto com nossa arquitetura e que fornecesse os controles de governança necessários para gerenciar flags com segurança em centenas de serviços e milhares de engenheiros. Alcançar nossas metas de escalabilidade e segurança com sucesso exigiu uma integração profunda com nosso modelo de dados de infraestrutura, frameworks de serviço e sistemas de CI.
No final de 2025, a SAFE tem aproximadamente 25 mil flags ativas, com 4 mil trocas de flags semanais. Em momentos de pico, a SAFE executa mais de 300 milhões de avaliações por segundo, tudo isso mantendo uma latência p95 de ~10μs para avaliações de flags.
Esta publicação explora como construímos o SAFE para atender a esses requisitos e os aprendizados que tivemos ao longo do caminho.
Sinalizadores de recurso em Ação
Para começar, vamos discutir uma jornada de usuário típica para uma flag SAFE. Em sua essência, um sinalizador de recurso é uma variável que pode ser acessada no fluxo de controle de um serviço, a qual pode assumir valores diferentes dependendo de condições controladas por uma configuração externa. Um caso de uso extremamente comum para sinalizadores de recurso é habilitar gradualmente um novo caminho de código de forma controlada, começando primeiro com uma pequena parte do tráfego e, gradualmente, habilitando-o em nível global.
Os usuários do SAFE primeiro começam definindo sua flag no código do serviço e a usam como um gate condicional para a lógica do novo recurso:
Em seguida, o usuário acessa a UI interna do SAFE, registra essa flag e seleciona um padrão para fazer o roll out dela. Este padrão define um plano de ramp up gradual que consiste em uma lista de estágios ordenados. O ramp up de cada estágio é feito lentamente por porcentagens. O usuário visualiza uma interface como esta após a criação da flag:
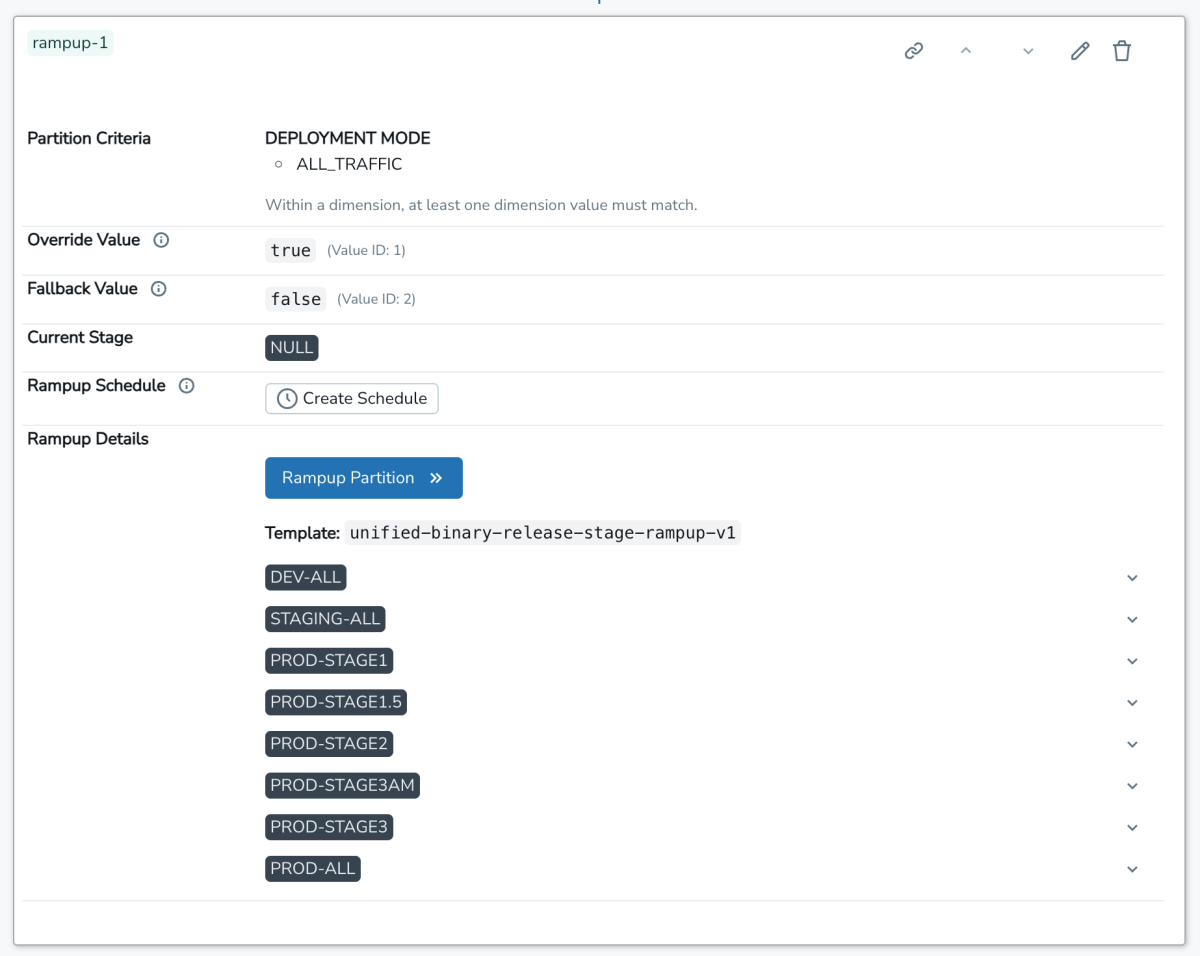
A partir daqui, o usuário pode liberar manualmente seu flag, uma fase de cada vez, ou programar para que as alterações de flag sejam criadas automaticamente. Internamente, a fonte da verdade para a configuração do flag é um arquivo jsonnet enviado para o monorepo do Databricks, que usa uma linguagem de domínio específico (DSL) leve para gerenciar a configuração do flag:
Quando os usuários alteram um flag na IU, o resultado dessa alteração é um Pull Request que precisa ser revisado por pelo menos mais um engenheiro. O SAFE também executa uma variedade de checagens pré-merge para proteger contra alterações inseguras ou não intencionais. Assim que a alteração for merge, o serviço do usuário aplicará a alteração e começará a emitir o novo valor dentro de 2 a 5 minutos após o merge do PR.
Casos de uso
Além do caso de uso descrito acima para o lançamento de recursos, o SAFE também é usado para outros aspectos da configuração dinâmica de serviços, como: configurações dinâmicas de longa duração (por exemplo, tempos limite ou limites de taxa), controle de máquina de estado para migrações de infraestrutura ou para entregar pequenos blobs de configuração (por exemplo, políticas de registro direcionadas).
Arquitetura
Bibliotecas de cliente
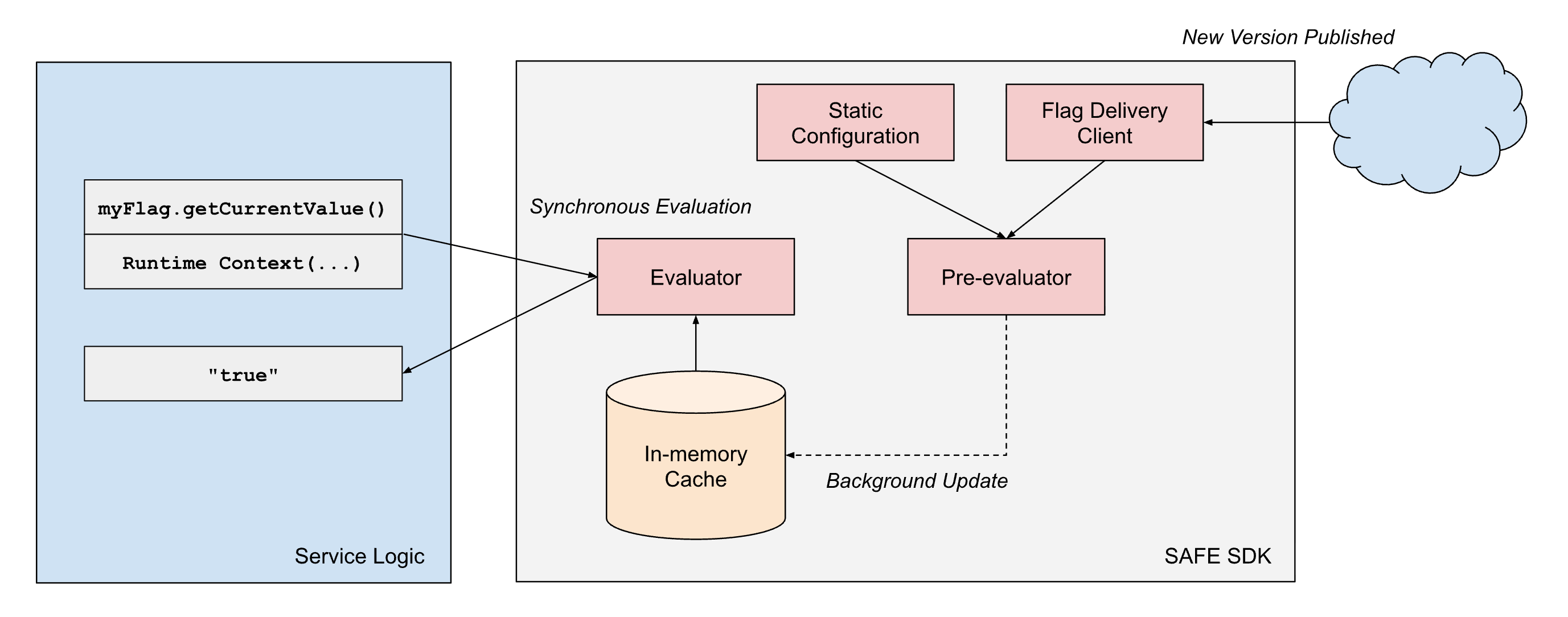
O SAFE fornece "SDKs" de cliente em várias linguagens com suporte interno, sendo o SDK do Scala o mais maduro e amplamente adotado. O SDK é essencialmente uma biblioteca de avaliação de critérios, combinada com um componente de carregamento de configuração. Para cada flag, há um conjunto de critérios que controlam qual valor o SDK deve retornar em Runtime. O SDK gerencia o carregamento do conjunto de configurações mais recente e precisa retornar rapidamente o resultado da avaliação desses critérios em Runtime.
Em pseudocódigo, os critérios internos se parecem com algo assim:
Os critérios podem ser modelados como algo semelhante a uma sequência de árvores de expressão Boolean. Cada expressão condicional precisa ser avaliada de forma eficiente para retornar um resultado rápido.
Para atender aos nossos requisitos de desempenho, o design do SDK do SAFE incorpora alguns princípios de arquitetura: (1) separação da entrega da configuração da avaliação e (2) separação das dimensões de avaliação estática e de Runtime.
- Separação da entrega da avaliação: As bibliotecas de cliente da SAFE sempre tratam a entrega como um processo assíncrono e nunca bloqueiam o "hot path" da avaliação de flag na entrega da configuração. Assim que o cliente tiver um snapshot de uma configuração de flag, ele continuará a retornar resultados com base nesse snapshot até que um processo assíncrono em segundo plano faça uma atualização atômica desse snapshot para um snapshot mais recente.
- Separação de tipos de dimensão: a avaliação de flags no SAFE opera em dois tipos de dimensões:
- Dimensões estáticas representam características do próprio binário em execução, como provedor de nuvem, região da nuvem e ambiente (desenvolvimento/homologação/produção). Esses valores permanecem constantes durante toda a vida de um processo.
- Dimensões de Runtime capturam o contexto específico da solicitação, como IDs de workspace, IDs de account, valores fornecidos pelo aplicativo e outros atributos por solicitação que variam a cada avaliação.
Para atingir de forma confiável uma latência de avaliação inferior a um milissegundo em escala, o SAFE emprega a pré-avaliação de partes da árvore de expressão booleana que são estáticas. Quando um pacote de configuração do SAFE é entregue a um serviço, o SDK avalia imediatamente todas as dimensões estáticas em relação à representação na memória da configuração da flag. Isso produz uma árvore de configuração simplificada que contém apenas a lógica relevante para aquela instância de serviço específica.
Quando uma avaliação de flag é solicitada durante o processamento da solicitação, o SDK só precisa avaliar as dimensões de Runtimes restantes em relação a essa configuração pré-compilada. Isso reduz significativamente o custo computacional de cada avaliação. Como muitos flags usam apenas dimensões estáticas em suas árvores de expressão Boolean, muitos flags podem ser efetivamente pré-avaliados por completo.
Entrega de flag
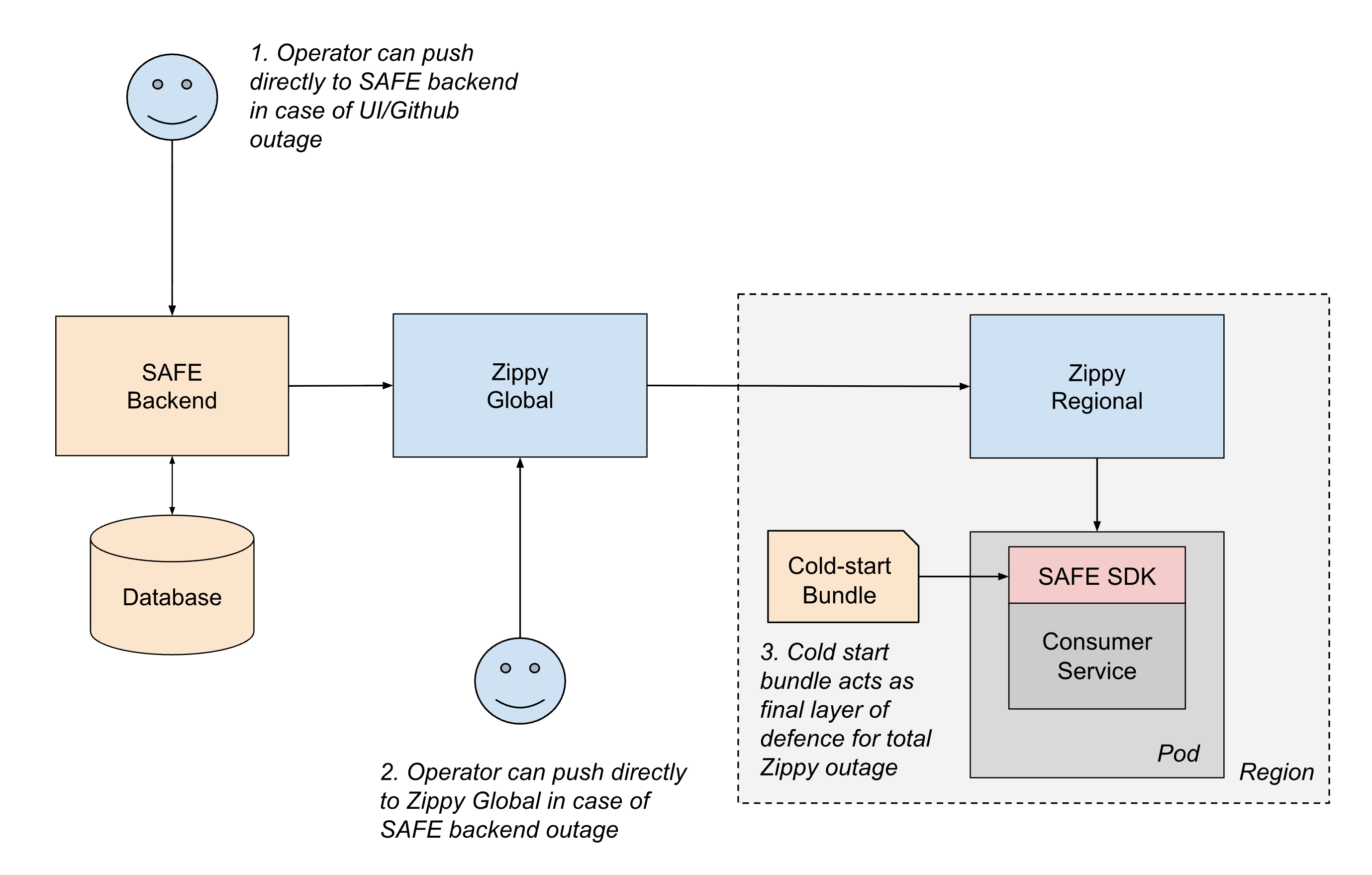
Para entregar a configuração de forma confiável a todos os serviços da Databricks, o SAFE opera em conjunto com nossa plataforma interna de entrega de configuração dinâmica, a Zippy. Uma descrição detalhada da arquitetura Zippy fica para outra postagem, mas, em resumo, o Zippy usa uma arquitetura global/regional de várias camadas e armazenamento de blobs por nuvem para transportar blobs de configuração arbitrários de uma fonte central para (entre outras superfícies) todos os pods do Kubernetes em execução no Painel de Controle do Databricks.
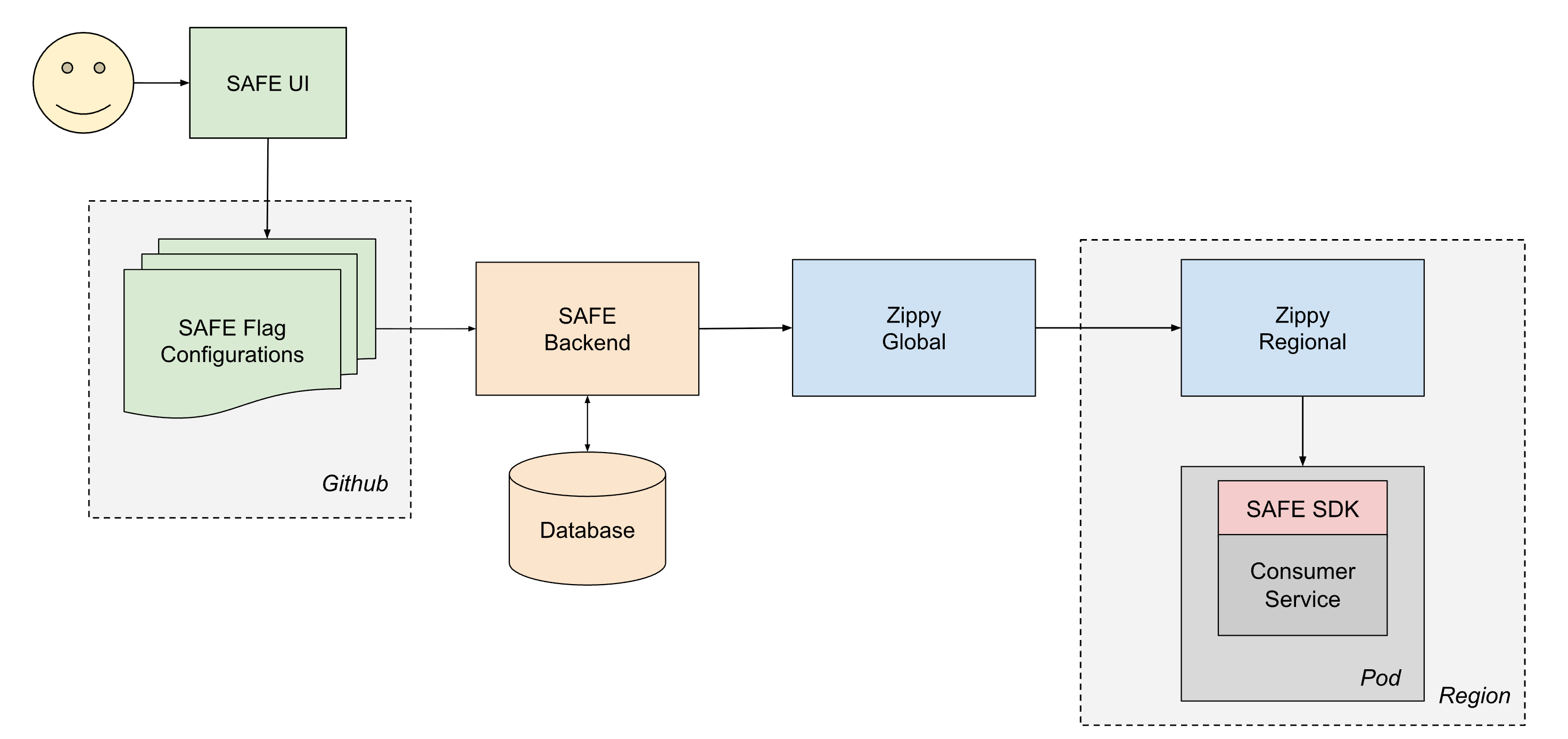
O ciclo de vida de uma flag entregue é o seguinte:
- Um usuário cria e merge um PR em um de seus arquivos jsonnet de configuração de flag, que então é merged no monorepo do Databricks no Github.
- Em aproximadamente 1 minuto, um job de CI pós-merge coleta o arquivo modificado e o envia para o backend SAFE, que, em seguida, armazena uma cópia da nova configuração em um banco de dados.
- Periodicamente (intervalos de ~1 minuto), o backend do SAFE agrupa todas as configurações de flag do SAFE e as envia para o backend do Zippy Global.
- O Zippy Global distribui essas configurações para cada uma de suas instâncias do Zippy Regional, em aproximadamente 30 segundos.
- O SDK do SAFE, executado em cada pod de serviço, recebe periodicamente os pacotes da nova versão usando uma combinação de entrega baseada em push e pull.
- Depois de entregue, o SDK SAFE pode usar a nova configuração durante a avaliação.
De ponta a ponta, uma alteração de flag normalmente se propaga para todos os serviços dentro de 3 a 5 minutos após o merge de um PR.
Pipeline de configuração de flags
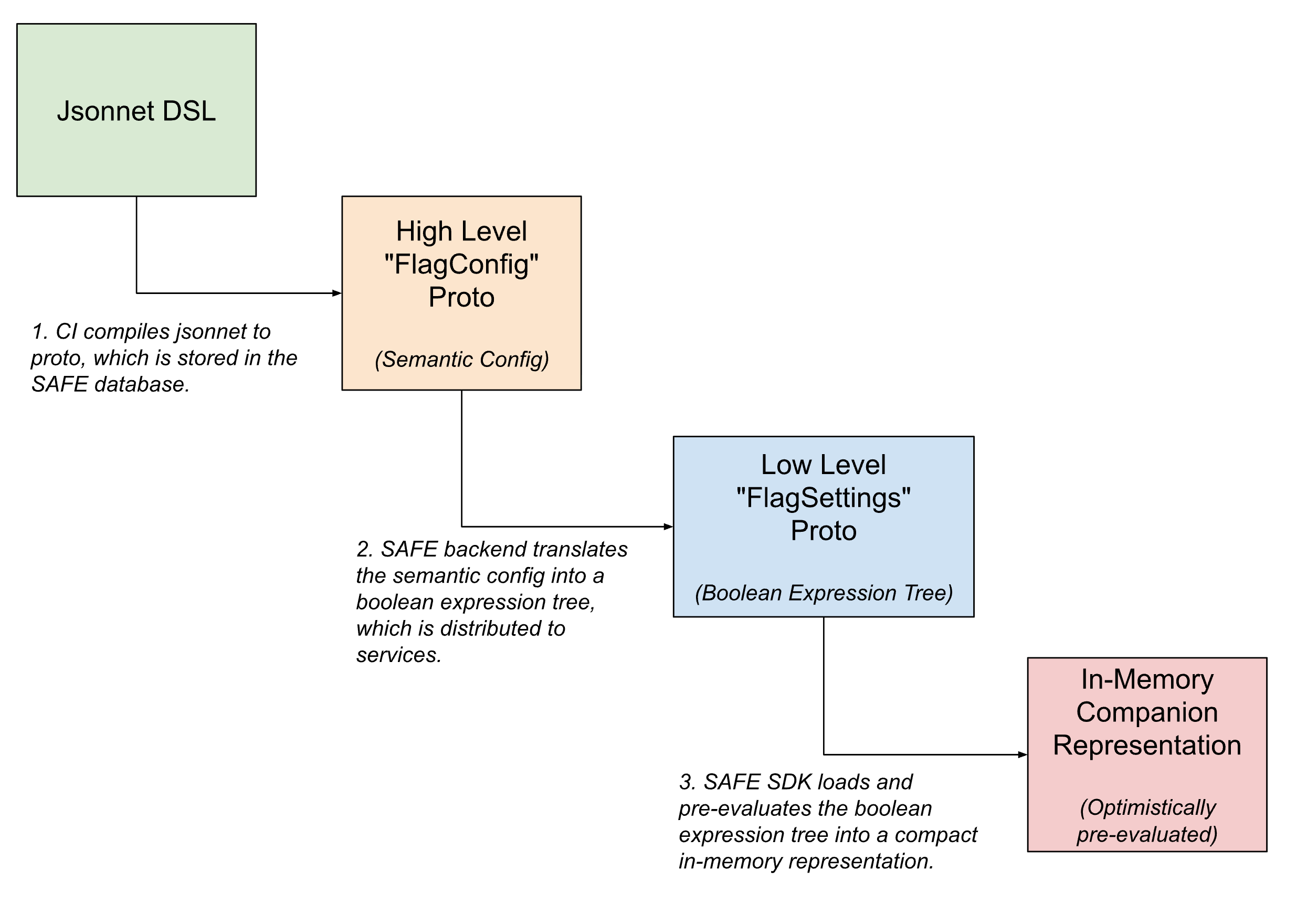
Dentro do pipeline de entrega de flags, as configurações de flag assumem várias formas, sendo progressivamente traduzidas de configurações semânticas de alto nível e legíveis por humanos para versões compactas e legíveis por máquina, à medida que o flag se aproxima de ser avaliado.
Na interface voltada para o usuário, os flags são definidos usando Jsonnet com uma DSL personalizada para permitir configurações de flag arbitrariamente complicadas. Essa DSL tem recursos para casos de uso comuns, como configurar a liberação de um flag usando um padrão ou definir substituições específicas em fatias de tráfego.
Após o check-in, esta DSL é traduzida para um equivalente protobuf interno, que captura a intenção semântica da configuração. O backend do SAFE então traduz essa configuração semântica em uma árvore de expressão Boolean. Uma descrição protobuf desta árvore de expressão Boolean é entregue ao SDK do SAFE, que a carrega em uma representação na memória ainda mais compactada da configuração.
UI
A maioria das alterações de estado das flags é iniciada a partir de uma UI interna para gerenciar as flags do SAFE. Esta UI permite que os usuários criem, modifiquem e aposentem flags por meio de um fluxo de trabalho que abstrai grande parte da complexidade do Jsonnet para alterações simples, ao mesmo tempo que fornece acesso à maior parte do poder da DSL para casos de uso avançados.
Uma IU rica também nos permitiu disponibilizar recursos adicionais de qualidade de vida, como a capacidade de programar a alternância de flags, suporte para verificações de integridade pós-merge e ferramentas de depuração para determinar alternâncias de flags recentes que afetaram uma determinada região ou serviço.
Revisão de configuração de flag
Todas as alterações de flag SAFE são criadas como PRs normais do Github e validadas por um extenso conjunto de validadores de pré-merge. Esse conjunto de validadores cresceu para abranger dezenas de verificações individuais, à medida que aprendemos mais sobre a melhor forma de nos protegermos contra alterações de flag potencialmente inseguras. Durante a introdução inicial do SAFE, as análises post-mortem de incidentes que foram causados ou mitigados por uma alteração de flag SAFE informaram muitas dessas verificações. Agora temos verificações que, por exemplo, exigem revisão especializada em alterações de grande blast radius, exigem que uma versão binária específica do serviço seja implantada antes que um flag possa ser ativado, evitam padrões sutis e comuns de configuração incorreta e assim por diante.
As equipes também podem definir suas próprias verificações de pré-merge específicas para a flag ou equipe, para aplicar invariantes em suas configurações.
Gerenciamento de Modos de Falha
Dado o papel crítico do SAFE na estabilidade do serviço, o sistema é projetado com várias camadas de resiliência para garantir a operação contínua, mesmo quando partes do pipeline de entrega falham.
O cenário de falha mais comum envolve interrupções no caminho de entrega da configuração. Se algo no caminho de entrega resultar em falha na atualização das configurações, os serviços simplesmente continuarão a usar sua última configuração conhecida até que o caminho de entrega seja restaurado. Essa abordagem de "fail static" garante que o comportamento do serviço existente permaneça estável mesmo durante interrupções no upstream.
Para cenários mais graves, mantemos vários mecanismos de fallback:
- Entrega fora de banda: se qualquer parte do caminho de push de CI ou do Github estiver indisponível, os operadores podem enviar configurações diretamente para o backend do SAFE usando ferramentas de emergência.
- Failover regional: se o backend do SAFE ou o Zippy Global estiverem fora do ar, os operadores podem enviar configurações temporariamente direto para as instâncias do Zippy Regional. Os serviços também podem fazer polling entre regiões para mitigar o impacto de uma única interrupção regional do Zippy.
- Pacotes de inicialização a frio: para lidar com casos em que o próprio Zippy não está disponível durante a startup do serviço, o SAFE distribui periodicamente pacotes de configuração para os serviços por meio de um registro de artefatos. Embora esses pacotes possam estar desatualizados em algumas horas, eles fornecem backup suficiente para que os serviços comecem com segurança, em vez de serem bloqueados na entrega ao vivo.
Dentro do próprio SDK do SAFE, o design defensivo garante que os erros de configuração tenham um impacto limitado. Se a configuração de uma flag específica estiver malformada, apenas essa única flag é afetada. O SDK também mantém o contrato de nunca lançar exceções e, em caso de falha, sempre reverte para o valor padrão do código, de modo que os desenvolvedores de aplicativos não precisam tratar a avaliação da flag como um processo falível. O SDK também alerta imediatamente os engenheiros de plantão quando ocorrem falhas de análise ou avaliação da configuração. Devido à maturidade do SAFE e à validação extensiva pré-merge, essas falhas são agora extremamente infrequentes em produção.
Essa abordagem em camadas para a resiliência garante que o SAFE se degrade de forma suave e minimiza o risco de se tornar um ponto único de falha.
Lições Aprendidas
Minimizar as dependências e o fallback redundante em camadas reduzem a carga operacional. Apesar de ser implantado e usado intensivamente por quase todas as superfícies de compute na Databricks, a carga operacional de manter o SAFE tem sido bastante gerenciável. Adicionar redundâncias em camadas, como o pacote de inicialização a frio e o comportamento de "falha estática" do SDK, tornou grande parte da arquitetura do SAFE autorregenerativa.
A experiência do desenvolvedor é fundamental. Escalar o "aspecto humano" de um sistema de flagging robusto exigiu um forte foco em UX. A SAFE é um sistema de missão crítica, frequentemente usado para mitigar incidentes. Por isso, criar uma UX amigável para trocar as flags durante emergências teve um grande impacto. Adotar uma mentalidade focada no produto levou a menos problemas pequenos, menos confusão e, por fim, a um menor tempo médio de recuperação (MTTR) para incidentes em toda a empresa.
Faça das "melhores práticas" o caminho de menor atrito. Um dos nossos maiores aprendizados foi que não se pode apenas documentar as melhores práticas e esperar que os engenheiros as sigam. Os engenheiros têm muitas prioridades concorrentes ao lançar recursos. O SAFE torna o caminho seguro o caminho fácil: liberações graduais exigem menos esforço e têm mais recursos de qualidade de vida disponíveis do que padrões de habilitação mais arriscados. Quando o sistema incentiva um comportamento mais seguro, a plataforma pode incentivar os engenheiros a adotar uma cultura de gerenciamento de mudanças responsável.
Estado Atual e Trabalhos Futuros
O SAFE é agora uma plataforma interna madura no Databricks e é amplamente utilizado. Os investimentos feitos em disponibilidade e experiência do desenvolvedor rendem frutos, pois vemos uma redução contínua tanto no tempo médio para resolução quanto no raio de impacto de incidentes de produção por meio do uso das flags do SAFE.
À medida que a superfície do produto da Databricks continua a se expandir, as primitivas de infraestrutura subjacentes a esses produtos também se expandem em abrangência e complexidade. Como resultado, tem havido um investimento significativo e contínuo para garantir que o SAFE ofereça suporte a todos os locais onde os engenheiros da Databricks escrevem e implantam código.
Se você tem interesse em dimensionar infraestruturas de missão crítica como esta, explore as vagas abertas na Databricks!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.