Como depuramos milhares de bancos de dados com IA na Databricks
Lições de como construir uma plataforma de depuração de banco de dados assistida por IA
- Na Databricks, operamos milhares de instâncias OLTP em centenas de regiões na AWS, Azure e GCP.
- Construímos uma plataforma agentiva que unifica métricas, ferramentas e expertise para ajudar nossos engenheiros a gerenciar seus bancos de dados nessa escala.
- Essa plataforma agentiva agora é usada em toda a empresa, reduzindo o tempo de depuração em até 90% e diminuindo a curva de aprendizado para operar nossa infraestrutura.
Na Databricks, substituímos operações manuais de banco de dados por IA, reduzindo o tempo gasto em depuração em até 90%.
Nosso agente de IA interpreta, executa e depura recuperando métricas e logs importantes, e correlacionando sinais automaticamente. Ele opera em uma frota de bancos de dados implantados em todas as principais nuvens e em quase todas as regiões de nuvem.
Essa nova capacidade de agente permitiu que os engenheiros respondessem rotineiramente a perguntas em linguagem natural sobre a integridade e o desempenho de seus serviços, sem precisar contatar os engenheiros de plantão nas equipes de armazenamento.
O que começou como um pequeno projeto de hackathon para simplificar o fluxo de investigação evoluiu para uma plataforma inteligente com adoção em toda a empresa. Esta é a nossa jornada.
Antes da IA: Tudo Funcionava, mas Nada Funcionava Junto
Durante uma investigação típica de incidente MySQL, um engenheiro frequentemente
- Verificava métricas no Grafana
- Alternava para um dashboard Databricks para entender a carga de trabalho do cliente
- Executava comandos CLI para inspecionar o status do InnoDB, um snapshot do estado interno do MySQL que contém informações como histórico de transações, operações de I/O e detalhes de deadlock
- Fazia login em um console de nuvem para baixar logs de consultas lentas
Cada ferramenta funcionava bem sozinha, mas juntas elas falhavam em formar um fluxo de trabalho coeso ou fornecer insights de ponta a ponta. Um engenheiro MySQL experiente conseguia juntar uma hipótese pulando entre abas e comandos na sequência certa; no entanto, isso consumia um orçamento e tempo preciosos de SLO no processo. Um engenheiro mais novo muitas vezes não sabia por onde começar.
Ironicamente, essa fragmentação em nossas ferramentas internas refletia o próprio desafio que a Databricks ajuda nossos clientes a superar.
A Plataforma de Inteligência de Dados Databricks unifica dados, governança e IA, permitindo que usuários autorizados entendam seus dados e ajam sobre eles. Internamente, nossos engenheiros precisam do mesmo: uma plataforma unificada que consolide os dados e fluxos de trabalho que sustentam nossa infraestrutura. Com essa base, podemos aplicar inteligência usando IA para interpretar os dados e guiar os engenheiros para o próximo passo correto.
Nossa Jornada: Do Hackathon a Agentes Inteligentes
Não começamos com uma iniciativa grande e de vários trimestres. Em vez disso, testamos a ideia durante um hackathon em toda a empresa. Em dois dias, construímos um protótipo simples que unificou algumas métricas e dashboards centrais de banco de dados em uma única visualização. Não era polido, mas melhorou imediatamente os fluxos de trabalho básicos de investigação. Isso estabeleceu nosso princípio orientador: agir rápido e manter o foco no cliente.
Construindo Plataformas com Foco no Cliente
Antes de escrever mais código, entrevistamos equipes de serviço para entender seus pontos problemáticos na depuração. Os temas eram consistentes: engenheiros juniores não sabiam por onde começar, e engenheiros seniores achavam as ferramentas fragmentadas e complicadas.
Para ver a dor em primeira mão, acompanhamos sessões de plantão e observamos engenheiros depurando problemas em tempo real. Três padrões se destacaram:
- Ferramentas fragmentadas
Engenheiros alternavam entre dashboards, CLIs e etapas manuais para investigação e operações como reinicializações ou restaurações. Cada ferramenta funcionava isoladamente, mas a falta de integração tornava o fluxo de trabalho lento e propenso a erros. - Tempo perdido coletando contexto
A maior parte do trabalho era descobrir o que mudou, como era o “normal” e quem tinha o contexto certo para ajudar, mas não mitigar o incidente em si. - Orientação pouco clara sobre mitigação segura
Durante incidentes, engenheiros muitas vezes não tinham certeza de quais ações eram seguras ou eficazes. Sem runbooks claros ou automação, eles recorriam a investigações longas ou esperavam por especialistas.
Olhando para trás, os postmortems raramente expunham essa lacuna: as equipes não careciam de dados ou ferramentas; elas careciam de depuração inteligente para interpretar o fluxo de sinais e guiá-las para ações seguras e eficazes.
Iterando em Direção à Inteligência
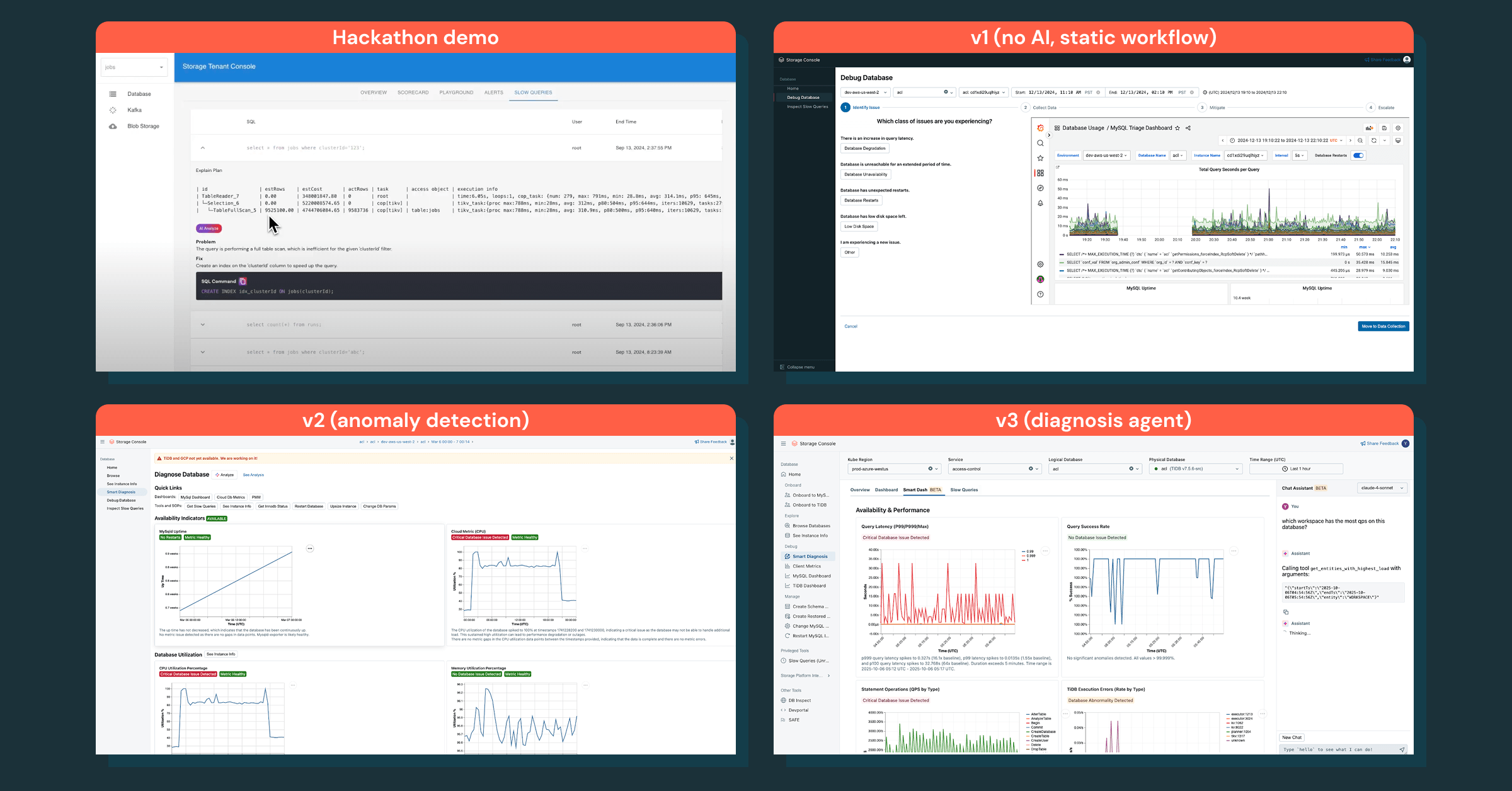
Começamos pequeno, com a investigação de banco de dados como primeiro caso de uso. Nossa v1 era um fluxo de trabalho agentic estático que seguia um SOP de depuração, mas não foi eficaz — engenheiros queriam um relatório de diagnóstico com insights imediatos, não uma lista de verificação manual.
Mudamos nosso foco para obter os dados corretos e adicionar inteligência por cima. Essa estratégia levou à detecção de anomalias, que apresentou as anomalias corretas, mas ainda não forneceu os próximos passos claros.
O verdadeiro avanço veio com um assistente de chat que codifica o conhecimento de depuração, responde a perguntas de acompanhamento e transforma investigações em um processo interativo. Isso transformou a maneira como os engenheiros depuram incidentes de ponta a ponta.
Uma Base: Abstração e Centralização
Dando um passo atrás, percebemos que, embora nosso framework existente pudesse unificar fluxos de trabalho e dados em uma única interface, nosso ecossistema não foi construído para a IA raciocinar sobre nosso cenário operacional. Qualquer agente precisaria lidar com a lógica específica de região e nuvem. E sem controles de acesso centralizados, ele se tornaria ou muito restritivo para ser útil, ou muito permissivo para ser seguro.
Esses problemas são especialmente difíceis de resolver na Databricks, pois operamos milhares de instâncias de banco de dados em centenas de regiões, oito domínios regulatórios e três nuvens. Sem uma base sólida que abstraia as diferenças de nuvem e regulatórias, a integração de IA rapidamente encontraria um conjunto de obstáculos inevitáveis:
- Fragmentação de contexto: Os dados de depuração viviam em lugares diferentes, tornando difícil para um agente construir um quadro consistente.
- Limites de governança pouco claros: Sem autorização centralizada e aplicação de políticas, garantir que o agente (e os engenheiros) permaneçam dentro das permissões corretas se torna difícil.
- Loops de iteração lentos: Abstrações inconsistentes dificultam o teste e a evolução do comportamento da IA, desacelerando severamente a iteração ao longo do tempo.
Para tornar o desenvolvimento de IA seguro e escalável, focamos em fortalecer a base da plataforma em torno de três princípios:
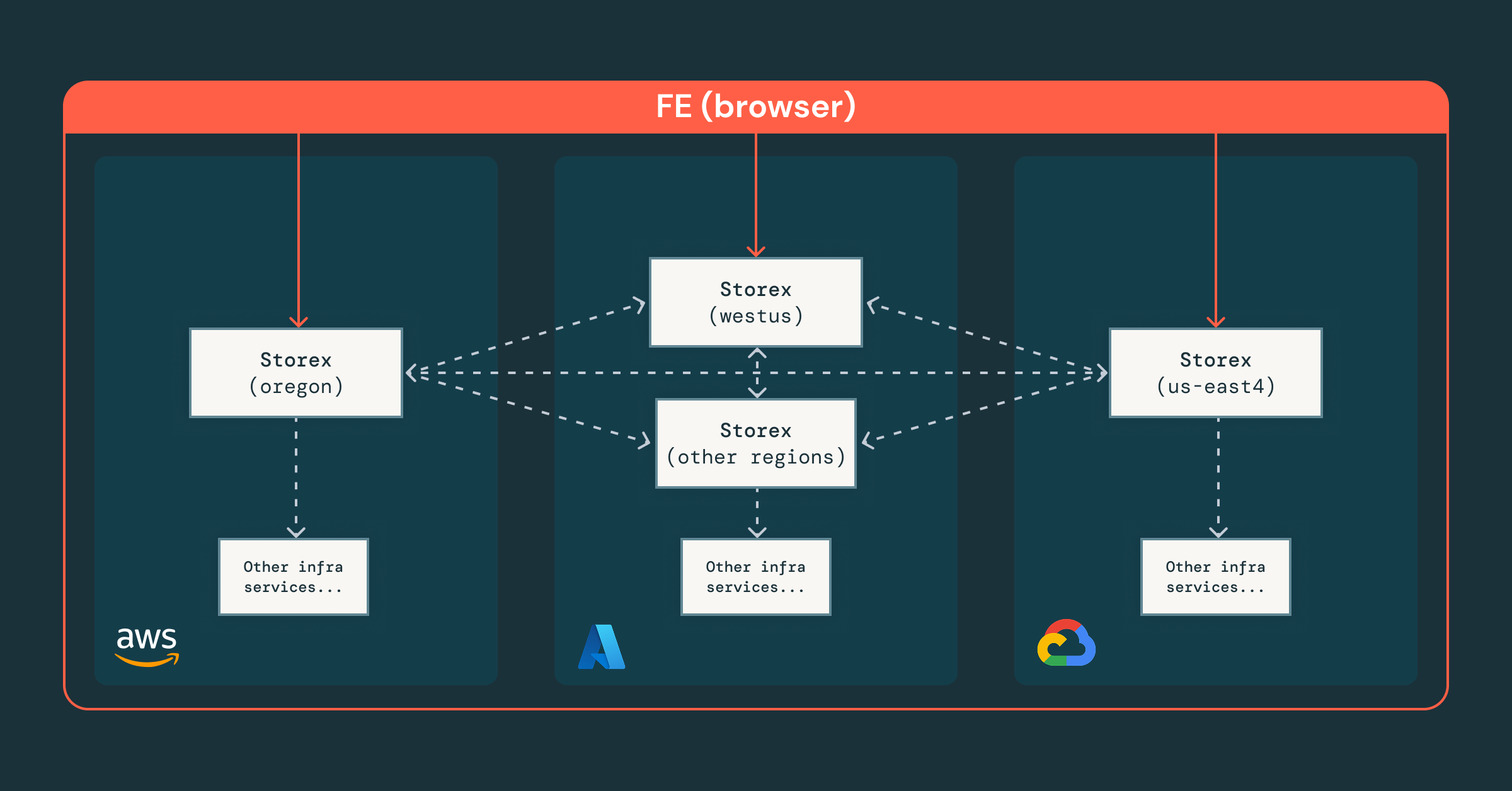
- Arquitetura sharded com foco central, onde uma instância global do Storex coordena shards regionais, fornecendo uma interface enquanto mantém os dados sensíveis locais e em conformidade.
- Controle de acesso granular, aplicado nos níveis de equipe, recurso e RPC, garantindo que engenheiros e agentes operem com segurança dentro das permissões corretas.
- Orquestração unificada, onde nossa plataforma integra serviços de infraestrutura existentes, permitindo abstrações consistentes entre nuvens e regiões.
Com os dados e o contexto centralizados, o próximo passo ficou claro: como poderíamos tornar a plataforma não apenas unificada, mas inteligente?
Da Visibilidade à Inteligência
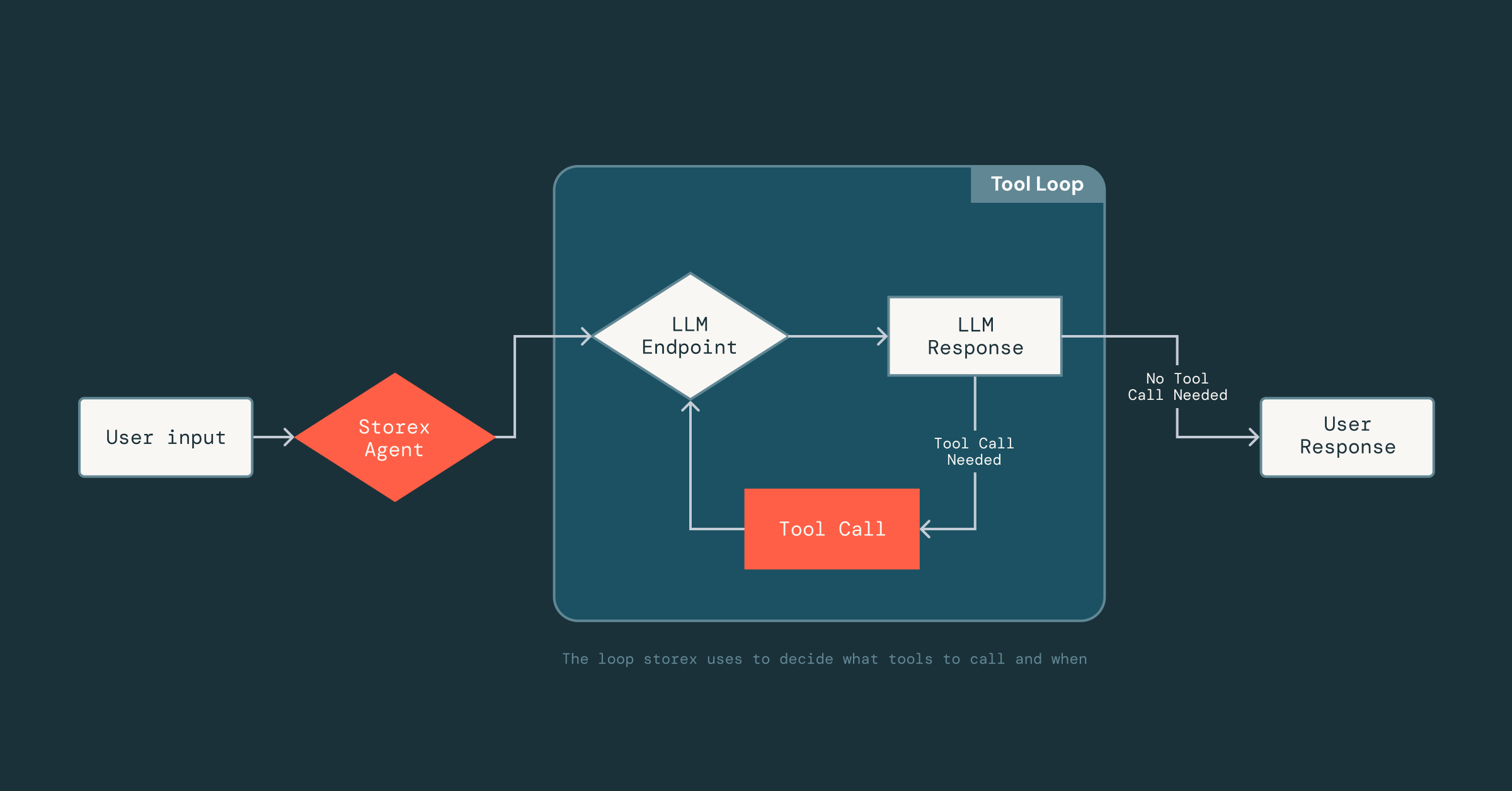
Com uma base unificada implementada, expor capacidades como recuperação de esquemas de banco de dados, métricas ou logs de consultas lentas para o agente de IA foi simples. Em poucas semanas, construímos um agente que podia agregar informações básicas do banco de dados, raciocinar sobre elas e apresentá-las de volta ao usuário.
Agora, a parte difícil era tornar o agente confiável: dado que LLMs são não determinísticos, não sabíamos como ele responderia às ferramentas, dados e prompts aos quais tinha acesso. Acertar isso exigiu muita experimentação para entender quais ferramentas eram eficazes e qual contexto incluir (ou omitir) nos prompts.
Para viabilizar essa iteração rápida, construímos um framework leve inspirado nas tecnologias de otimização de prompts do MLflow que utiliza DsPy, o qual desacopla o prompting da implementação de ferramentas. Engenheiros podem definir ferramentas como classes Scala normais e assinaturas de função, e simplesmente adicionar uma curta docstring descrevendo a ferramenta. A partir daí, o LLM pode inferir o formato de entrada da ferramenta, a estrutura de saída e como interpretar os resultados. Esse desacoplamento nos permite avançar rapidamente: podemos iterar em prompts ou trocar ferramentas dentro e fora do agente sem alterar constantemente a infraestrutura subjacente que lida com a análise, conexões de LLM ou estado da conversa.
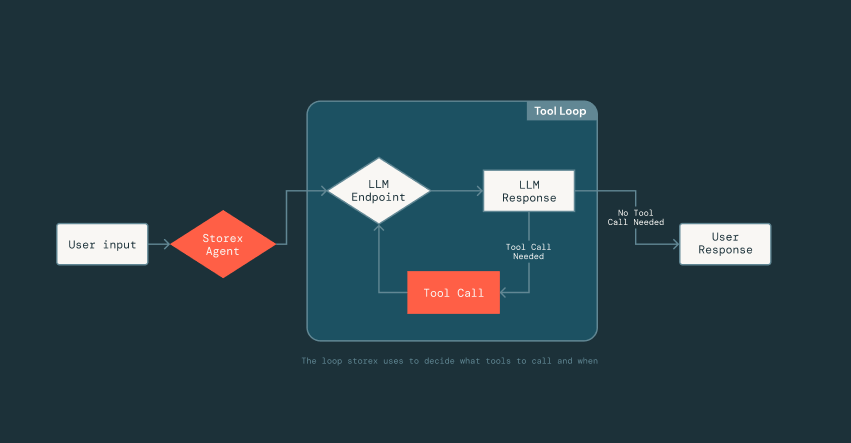{kind=link}
À medida que iteramos, como provamos que o agente está melhorando sem introduzir regressões? Para resolver isso, criamos um framework de validação que captura snapshots do estado de produção e os reproduz através do agente, usando um LLM “juiz” separado para pontuar as respostas quanto à precisão e utilidade à medida que modificamos os prompts e as ferramentas.
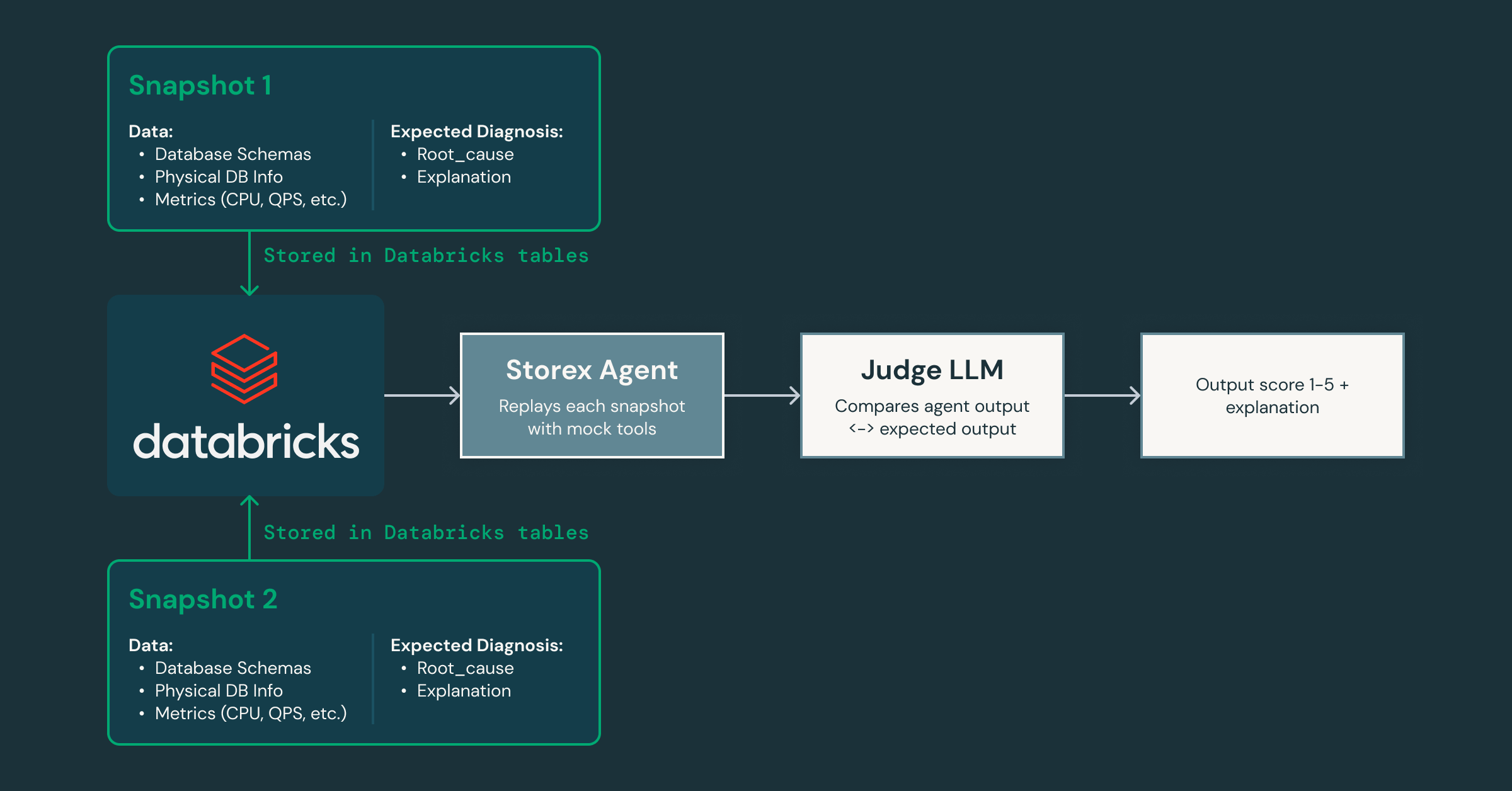
Como esse framework nos permite iterar rapidamente, podemos facilmente criar agentes especializados para diferentes domínios: um focado em problemas de sistema e banco de dados, outro em padrões de tráfego do lado do cliente, e assim por diante. Essa decomposição permite que cada agente construa um conhecimento profundo em sua área, enquanto colabora com outros para entregar uma análise de causa raiz mais completa. Isso também abre caminho para a integração de agentes de IA em outras partes de nossa infraestrutura, estendendo-se além dos bancos de dados.
Com conhecimento especializado e contexto operacional codificados em seu raciocínio, nosso agente pode extrair insights significativos e guiar ativamente os engenheiros durante as investigações. Em minutos, ele apresenta logs e métricas relevantes que os engenheiros talvez não considerassem examinar. Ele conecta sintomas entre camadas, como identificar o workspace que está gerando carga inesperada e correlacionar picos de IOPS com migrações recentes de esquema. Ele até explica a causa e o efeito subjacentes e recomenda os próximos passos para mitigação.
Juntas, essas peças marcam nossa transição da visibilidade para a inteligência. Passamos da visibilidade de ferramentas e métricas para uma camada de raciocínio que entende nossos sistemas, aplica conhecimento especializado e guia os engenheiros em direção a mitigações seguras e eficazes. É uma base sobre a qual podemos continuar construindo, não apenas para bancos de dados, mas também para a forma como operamos a infraestrutura como um todo.
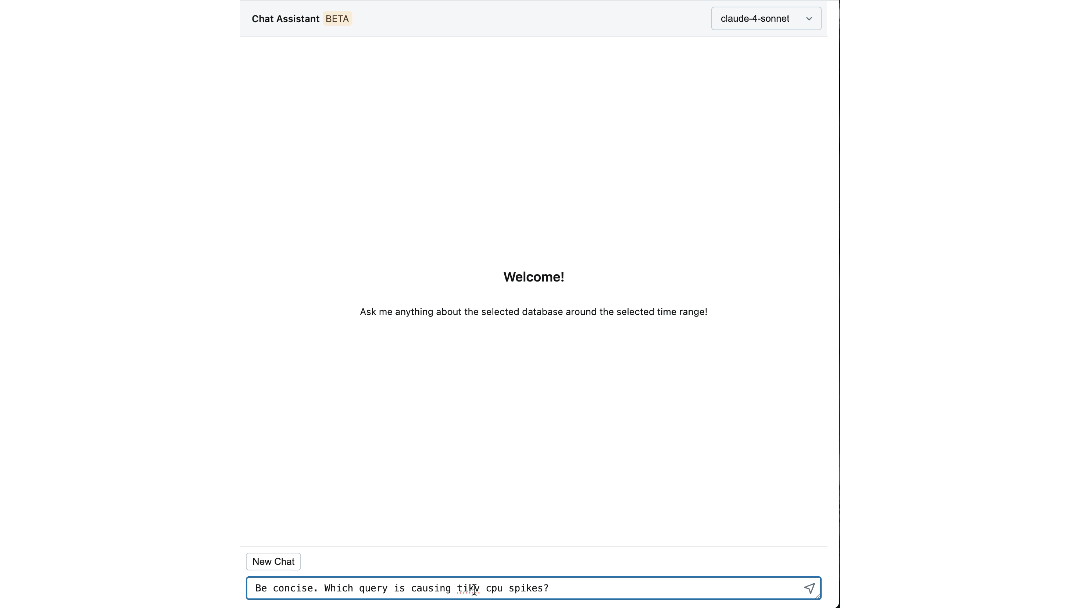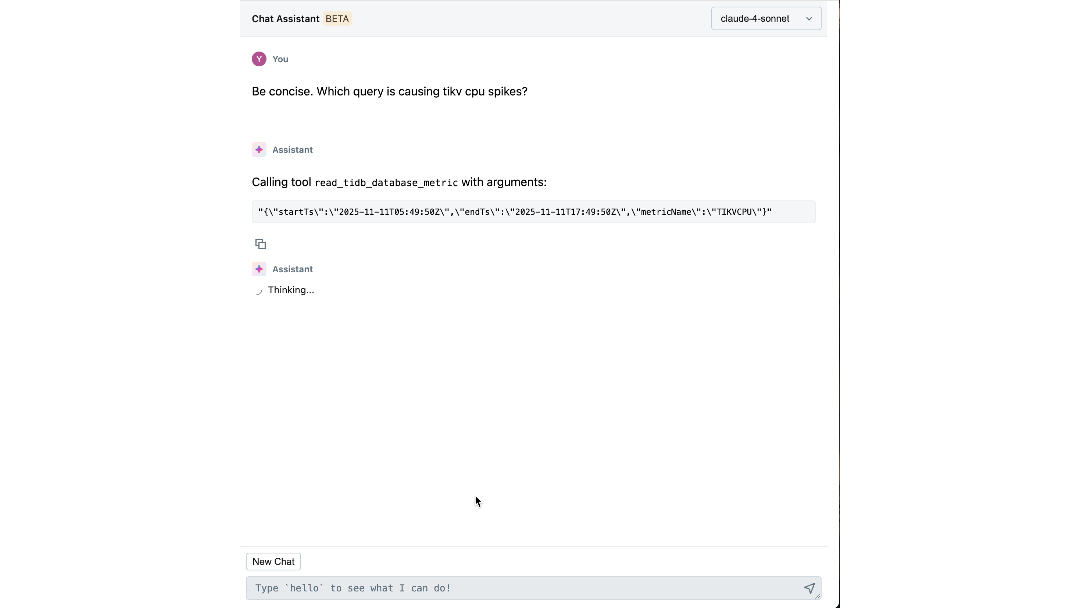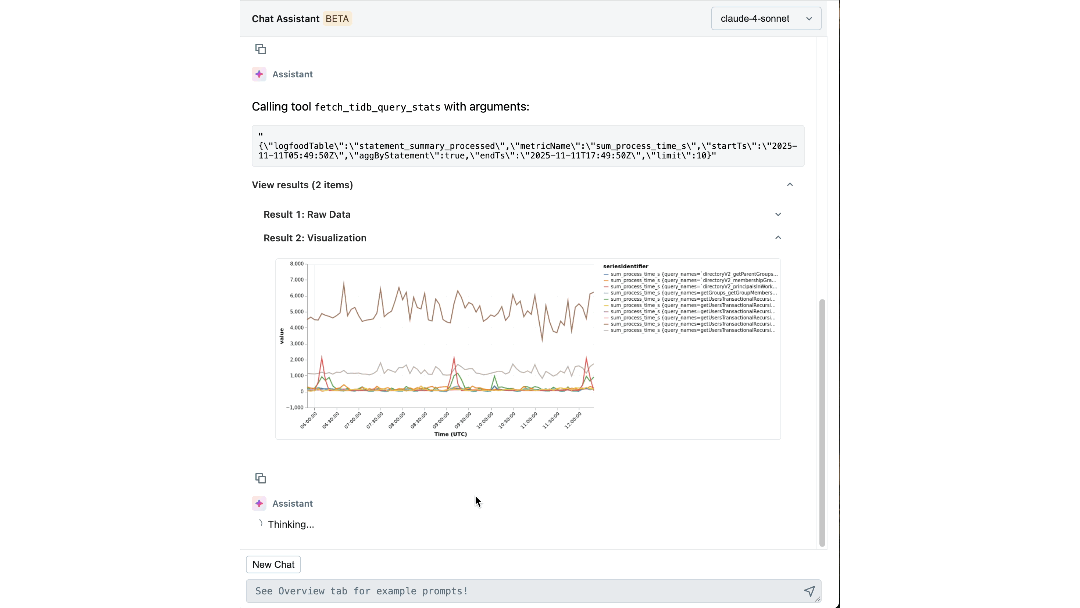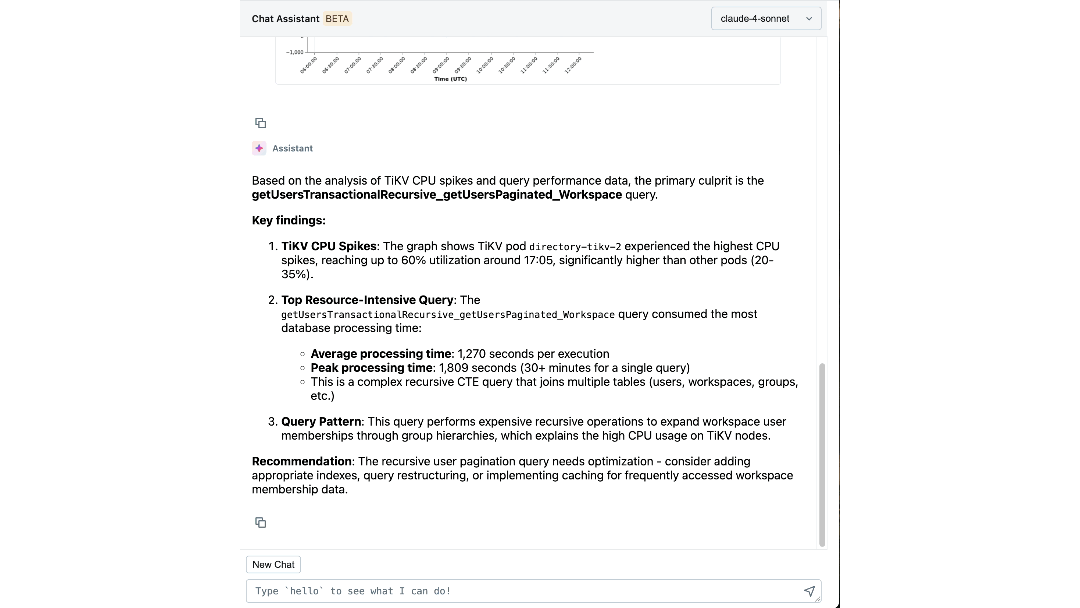
O Impacto: Redefinindo Como Construímos e Operamos em Escala
A plataforma mudou a forma como os engenheiros da Databricks interagem com sua infraestrutura. Etapas individuais que antes exigiam alternar entre dashboards, CLIs e SOPs agora podem ser facilmente respondidas por nosso assistente de chat, reduzindo o tempo gasto em até 90%.
A curva de aprendizado de nossa infraestrutura entre novos engenheiros também caiu acentuadamente. Novos contratados sem nenhum contexto agora podem iniciar uma investigação de banco de dados em menos de 5 minutos, algo que teria sido quase impossível antes. E recebemos ótimos feedbacks desde o lançamento desta plataforma:
O assistente de banco de dados realmente me economiza muito tempo, pois não preciso lembrar onde ficam todos os meus dashboards de consulta. Posso simplesmente perguntar qual workspace está gerando a carga. Melhor ferramenta de todos os tempos!—Yuchen Huo, Staff Engineer
Sou um usuário assíduo e não consigo acreditar que vivíamos sem ela. O nível de polimento e utilidade é muito impressionante. Parabéns à equipe, é uma mudança radical na experiência do desenvolvedor.—Dmitriy Kunitskiy, Staff Engineer
Adoro especialmente como estamos trazendo insights impulsionados por IA para depurar problemas de infraestrutura. Agradeço o quão visionária a equipe tem sido ao projetar este console desde o início com isso em mente.—Ankit Mathur, Senior Staff Engineer
Arquiteturalmente, a plataforma estabelece a base para a próxima evolução: operações de produção assistidas por IA. Com dados, contexto e salvaguardas unificados, agora podemos explorar como o agente pode ajudar com restaurações, consultas de produção e atualizações de configuração: o próximo passo em direção a um fluxo de trabalho operacional assistido por IA.
Mas o impacto mais significativo não foi apenas a redução do trabalho repetitivo ou o onboarding mais rápido: foi uma mudança de mentalidade. Nosso foco mudou da arquitetura técnica para as jornadas críticas do usuário (CUJs) que definem como os engenheiros vivenciam nossos sistemas. Essa abordagem centrada no usuário é o que permite que nossas equipes de infraestrutura criem plataformas sobre as quais nossos engenheiros podem construir produtos vencedores em sua categoria.
Conclusões
No final, nossa jornada se resumiu a três conclusões:
- Iteração rápida é essencial para o desenvolvimento de agentes: Agentes melhoram através de experimentação, validação e refinamento rápidos. Nosso framework inspirado em DsPy permitiu isso, permitindo-nos evoluir rapidamente prompts e ferramentas.
- A velocidade da iteração é limitada pela base subjacente: Dados unificados, abstrações consistentes e controle de acesso granular removeram nossos maiores gargalos, tornando a plataforma confiável, escalável e pronta para IA.
- A velocidade só importa quando tem a direção correta: Não começamos a construir uma plataforma de agentes. Cada iteração simplesmente seguiu o feedback do usuário e nos aproximou da solução que os engenheiros precisavam.
Construir plataformas internas é enganosamente difícil. Mesmo dentro da mesma empresa, equipes de produto e plataforma operam sob restrições muito diferentes. Na Databricks, estamos preenchendo essa lacuna construindo com obsessão pelo cliente, simplificando através de abstrações e elevando com inteligência, tratando nossos clientes internos com o mesmo cuidado e rigor que aplicamos aos nossos clientes externos.
Junte-se a Nós
À medida que olhamos para o futuro, estamos animados para continuar expandindo os limites de como a IA pode moldar sistemas de produção e fazer a infraestrutura complexa parecer sem esforço. Se você é apaixonado por construir a próxima geração de plataformas internas impulsionadas por IA, junte-se a nós!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.