Do caos à escala: Modelagem de pipelines declarativos do Spark com DLT-META
Um framework de metadados para criar pipelines consistentes, automatizados e governados em escala
por Ravi Gawai e Phoebe Weiser
- O escalonamento de pipelines de dados introduz sobrecarga, drift e lógica inconsistente entre as equipes.
- Essas lacunas atrasam a entrega, aumentam os custos de manutenção e dificultam a aplicação de padrões compartilhados.
- Este blog mostra como a metaprogramação orientada por metadados remove a duplicação e cria pipelines de dados automatizados e consistentes em escala.
Pipelines declarativos oferecem às equipes uma maneira orientada por intenção para criar fluxos de trabalho em lotes e de transmissão. Você define o que deve acontecer e deixa o sistema gerenciar a execução. Isso reduz o código personalizado e oferece suporte a padrões de engenharia repetíveis.
À medida que o uso de dados das organizações aumenta, os pipelines se multiplicam. Os padrões evoluem, novas fontes são adicionadas e mais equipes participam do desenvolvimento. Até mesmo pequenas atualizações de esquema se propagam por dezenas de notebooks e configurações. A metaprogramação orientada por metadados resolve esses problemas transferindo a lógica do pipeline para padrões estruturados que são gerados em Runtime.
Essa abordagem mantém o desenvolvimento consistente, reduz a manutenção e ganha escala com esforço de engenharia limitado.
Neste blog, você aprenderá a criar pipelines orientados por metadados para o Spark Declarative Pipelines usando o DLT-META, um projeto do Databricks Labs, que aplica padrões de metadados para automatizar a criação de pipelines.
Por mais úteis que os Pipelines Declarativos sejam, o trabalho necessário para dar suporte a eles aumenta rapidamente quando as equipes adicionam mais fontes e expandem o uso em toda a organização.
Por que pipelines manuais são difíceis de manter em escala
Pipelines manuais funcionam em pequena escala, mas o esforço de manutenção cresce mais rápido que os próprios dados. Cada nova fonte adiciona complexidade, levando a drift de lógica e retrabalho. As equipes acabam remendando os pipelines em vez de aprimorá-los. Engenheiros de dados enfrentam constantemente estes desafios de escalabilidade:
- Muitos artefatos por fonte: cada dataset exige novos Notebooks, configurações e scripts. A sobrecarga operacional cresce rapidamente com cada feed integrado.
- As atualizações de lógica não são propagadas: As alterações nas regras de negócio não são aplicadas aos pipelines, resultando em drift de configuração e saídas inconsistentes entre os pipelines.
- Qualidade e governança inconsistentes: as equipes criam verificações e linhagem personalizadas, dificultando a aplicação de padrões em toda a organização e tornando os resultados altamente variáveis.
- Contribuição segura limitada das equipes de domínio: analistas e equipes de negócios querem adicionar dados; no entanto, a engenharia de dados ainda revisa ou reescreve a lógica, atrasando a entrega.
- A manutenção se multiplica a cada mudança: ajustes ou atualizações simples de esquema criam um enorme backlog de trabalho manual em todos os pipelines dependentes, paralisando a agilidade da plataforma.
Esses problemas mostram por que uma abordagem que prioriza os metadados é importante. Ela reduz o esforço manual e mantém os pipelines consistentes à medida que escalam.
Como o DLT-META lida com escala e consistência
O DLT-META resolve os problemas de escala e consistência do pipeline. É um framework de metaprogramação orientado a metadados para Pipelines Declarativos do Spark. As equipes de dados o utilizam para automatizar a criação de pipelines, padronizar a lógica e dimensionar o desenvolvimento com o mínimo de código.
Com a metaprogramação, o comportamento do pipeline é derivado da configuração, em vez de notebooks repetidos. Isso oferece benefícios claros às equipes.
- Menos código para escrever e manter
- Integração mais rápida de novas fontes de dados
- Pipelines prontos para produção desde o começo
- Padrões consistentes em toda a plataforma
- Melhores práticas escaláveis com equipes enxutas
Spark Declarative Pipelines e DLT-META trabalham juntos. O Spark Declarative Pipelines define a intenção e gerencia a execução. O DLT-META adiciona uma camada de configuração que gera e escala a lógica do pipeline. Combinados, eles substituem a codificação manual por padrões repetíveis que dão suporte à governança, à eficiência e ao crescimento em escala.
Como o DLT-META atende às necessidades reais de engenharia de dados
1. Configuração centralizada e baseada em templates
O DLT-META centraliza a lógica do pipeline em padrões compartilhados para remover a duplicação e a manutenção manual. As equipes definem regras de ingestão, transformação, qualidade e governança em metadados compartilhados usando JSON ou YAML. Quando uma nova fonte é adicionada ou uma regra muda, as equipes atualizam a configuração uma única vez. A lógica se propaga automaticamente por todos os pipelines.
2. Escalabilidade instantânea e integração mais rápida
As atualizações orientadas por metadados facilitam a escala de pipelines e a integração de novas fontes. As equipes adicionam fontes ou ajustam as regras de negócios editando arquivos de metadados. As alterações se aplicam a todas as cargas de trabalho downstream sem intervenção manual. Novas fontes passam para a produção em minutos, em vez de semanas.
3. Contribuição da equipe de domínio com padrões aplicados
O DLT-META permite que as equipes de domínio contribuam com segurança por meio da configuração. Analistas e especialistas de domínio atualizam metadados para acelerar a entrega. As equipes de plataforma e engenharia mantêm o controle sobre validação, qualidade de dados, transformações e regras de compliance.
4. Consistência e governança em toda a empresa
Padrões de toda a organização são aplicados automaticamente em todos os pipelines e consumidores. A configuração central impõe uma lógica consistente para cada nova fonte. As regras integradas de auditoria, linhagem e qualidade de dados dão suporte a requisitos regulatórios e operacionais em escala.
Como as equipes usam o DLT-META na prática
Os clientes estão usando o DLT-META para definir a ingestão e as transformações uma vez e aplicá-las por meio da configuração. Isso reduz o código personalizado e acelera a integração.
A Cineplex viu um impacto imediato.
Usamos o DLT-META para minimizar o código personalizado. Os engenheiros não escrevem mais pipelines de maneira diferente para tarefas simples. Arquivos JSON de integração aplicam um framework consistente e cuidam do resto.—Aditya Singh, Engenheiro de Dados, Cineplex
A PsiQuantum mostra como equipes pequenas podem ser escaladas com eficiência.
O DLT-META nos ajuda a gerenciar cargas de trabalho bronze e silver com baixa manutenção. Ele oferece suporte a grandes volumes de dados sem notebooks ou código-fonte duplicados.—Arthur Valadares, Engenheiro de Dados Principal, PsiQuantum
Em todas as indústrias, as equipes aplicam o mesmo padrão.
- Varejo centraliza dados de lojas e da cadeia de suprimentos de centenas de fontes
- A Logistics padroniza a ingestão de lotes e transmissão para IoT e dados de frota
- Serviços financeiros garantem a auditoria e a compliance enquanto integram feeds mais rapidamente
- Saúde: mantém a qualidade e a capacidade de auditoria em datasets complexos
- Manufatura e telecomunicações escalam a ingestão em escala usando metadados reutilizáveis e governados centralmente
Essa abordagem permite que as equipes aumentem o número de pipelines sem aumentar a complexidade.
Como começar a usar o DLT-META em 5 passos simples
Você não precisa redesenhar sua plataforma para experimentar o DLT-META. Comece pequeno. Use algumas fontes. Deixe que os metadados cuidem do resto.
1. Obtenha o framework
Comece clonando o repositório DLT-META. Isso fornece os padrões, exemplos e ferramentas necessários para definir pipelines usando metadados.
2. Defina seus pipelines com metadados
Em seguida, defina o que seus pipelines devem fazer. Você faz isso editando um pequeno conjunto de arquivos de configuração.
- Use conf/onboarding.json para descrever as tabelas de entrada brutas.
- Use conf/silver_transformations.json para definir as transformações.
- Opcionalmente, adicione conf/dq_rules.json se quiser aplicar regras de qualidade de dados.
Neste ponto, você está descrevendo a intenção. Você não está escrevendo código de pipeline.
3. Incorpore os metadados na plataforma
Antes que os pipelines possam ser execução, o DLT-META precisa registro seus metadados. Este passo de integração converte suas configurações em tabelas delta do Dataflowspec que os pipelines leem em Runtime.
Você pode executar a incorporação a partir de um Notebook, um Lakeflow Job ou da CLI do DLT-META.
a. Integração manual via notebook, por exemplo, aqui
Use o notebook de onboarding fornecido para processar seus metadados e provisionar seus artefatos de pipeline:
b. Automatize o onboarding via Lakeflow Jobs com um Python wheel.
O exemplo abaixo mostra a UI do Lakeflow Jobs para criar e automatizar um pipeline DLT-META
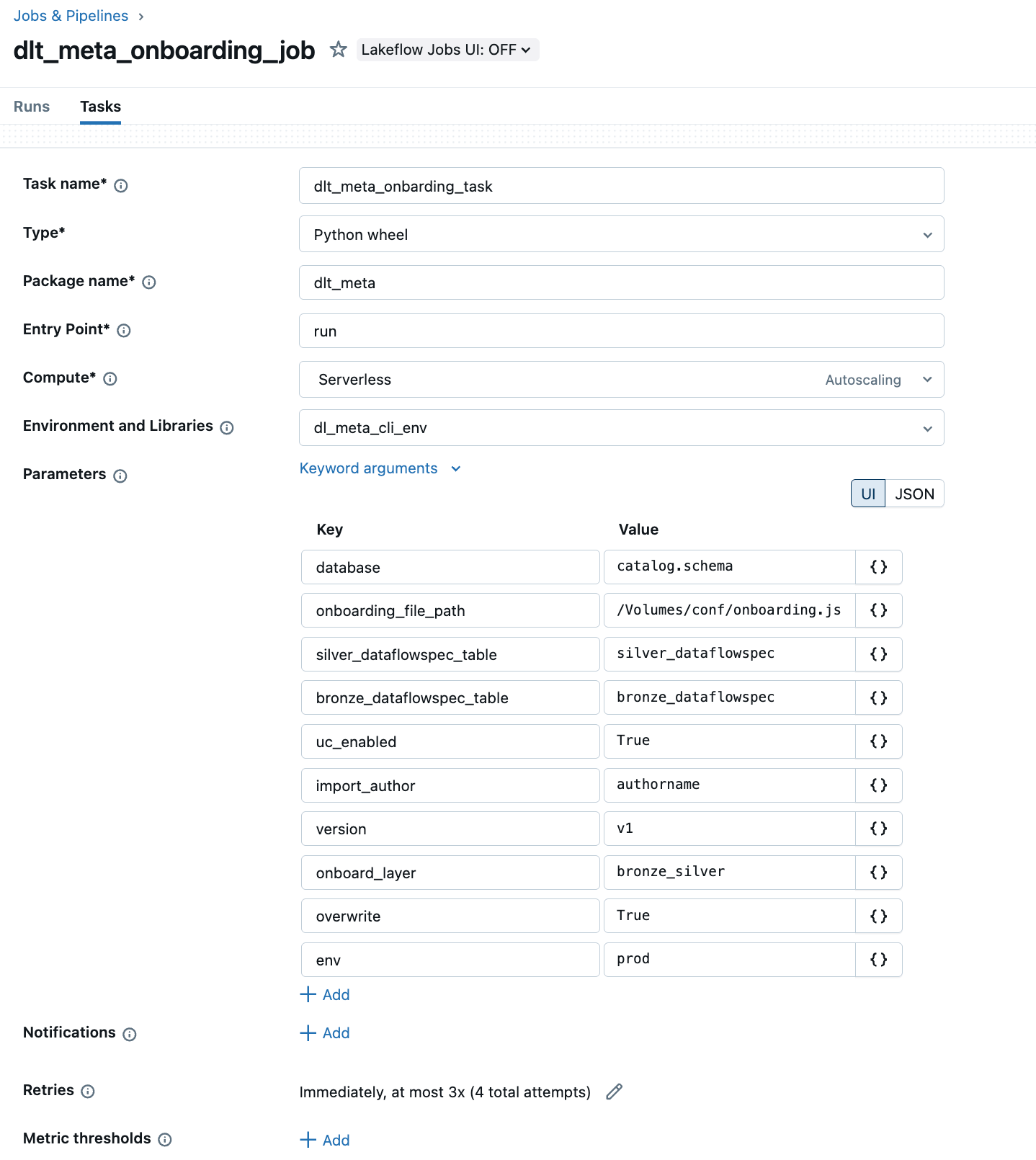
c. Faça a integração usando os comandos da CLI do DLT-META mostrados no repo: aqui.
A CLI do DLT-META permite que você execute o onboard e o deploy em um terminal Python interativo
4. Criar um pipeline genérico
Com os metadados em vigor, você cria um único pipeline genérico. Esse pipeline lê as tabelas Dataflowspec e gera lógica dinamicamente.
Use pipelines/dlt_meta_pipeline.py como o ponto de entrada e configure-o para referenciar suas especificações bronze e silver.
Este pipeline permanece inalterado à medida que você adiciona fontes. Os metadados controlam o comportamento.

5. Trigger e executar
Agora você está pronto para executar o pipeline. Acione-o como qualquer outro Spark Declarative Pipeline.
O DLT-META cria e executa a lógica do pipeline em Runtime.
O resultado são tabelas bronze e silver prontas para produção com transformações consistentes, regras de qualidade e linhagem aplicadas automaticamente.
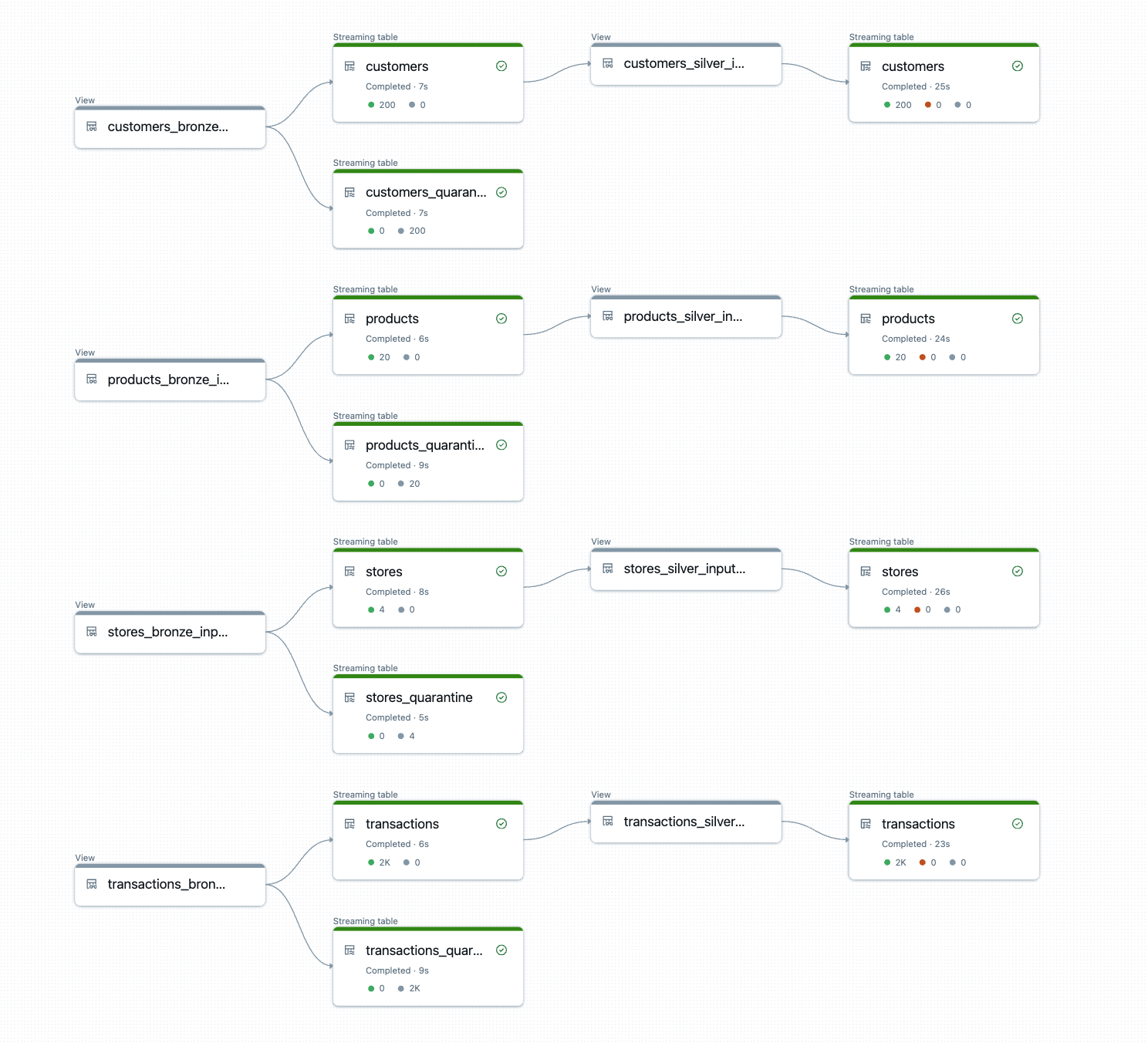
{kind=link}
Experimente hoje mesmo
Para começar, recomendamos iniciar uma prova de conceito usando seus Spark Declarative Pipelines existentes com algumas fontes, migrando a lógica do pipeline para metadados e deixando o DLT-META orquestrar em escala. Comece com uma pequena prova de conceito e veja como a metaprogramação orientada por metadados expande seus recursos de engenharia de dados além do que você imaginava ser possível.
Recursos do Databricks
- Primeiros passos: https://github.com/databrickslabs/DLT-META#getting-started
- GitHub: github.com/databrickslabs/DLT-META
- Documentação do GitHub: databrickslabs.github.io/DLT-META
- documentação da Databricks: https://docs.databricks.com/aws/en/dlt-ref/DLT-META
- Demos: databrickslabs.github.io/DLT-META/demo
- Última versão: https://github.com/databrickslabs/DLT-META/releases
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.