Introdução às Funções de Janela no Spark SQL
por Yin Huai e Michael Armbrust
Neste post, apresentamos o novo recurso de funções de janela que foi adicionado ao Apache Spark. As funções de janela permitem que os usuários do Spark SQL calculem resultados como a classificação de uma determinada linha ou uma média móvel em um intervalo de linhas de entrada. Elas melhoram significativamente a expressividade das APIs SQL e DataFrame do Spark. Este post primeiro apresentará o conceito de funções de janela e, em seguida, discutirá como usá-las com o Spark SQL e a API DataFrame do Spark.
O que são Funções de Janela?
Antes da versão 1.4, havia dois tipos de funções suportadas pelo Spark SQL que poderiam ser usadas para calcular um único valor de retorno. Funções internas ou UDFs, como substr ou round, recebem valores de uma única linha como entrada e geram um único valor de retorno para cada linha de entrada. Funções de agregação, como SUM ou MAX, operam em um grupo de linhas e calculam um único valor de retorno para cada grupo.
Embora ambas sejam muito úteis na prática, ainda há uma ampla gama de operações que não podem ser expressas usando apenas esses tipos de funções. Especificamente, não havia como operar em um grupo de linhas e, ao mesmo tempo, retornar um único valor para cada linha de entrada. Essa limitação torna difícil realizar várias tarefas de processamento de dados, como calcular uma média móvel, calcular uma soma cumulativa ou acessar os valores de uma linha que aparece antes da linha atual. Felizmente para os usuários do Spark SQL, as funções de janela preenchem essa lacuna.
Em sua essência, uma função de janela calcula um valor de retorno para cada linha de entrada de uma tabela com base em um grupo de linhas, chamado de Frame. Cada linha de entrada pode ter um frame exclusivo associado a ela. Essa característica das funções de janela as torna mais poderosas do que outras funções e permite que os usuários expressem várias tarefas de processamento de dados que são difíceis (se não impossíveis) de serem expressas sem funções de janela de forma concisa. Agora, vamos dar uma olhada em dois exemplos.
Suponha que temos uma tabela productRevenue como mostrado abaixo.
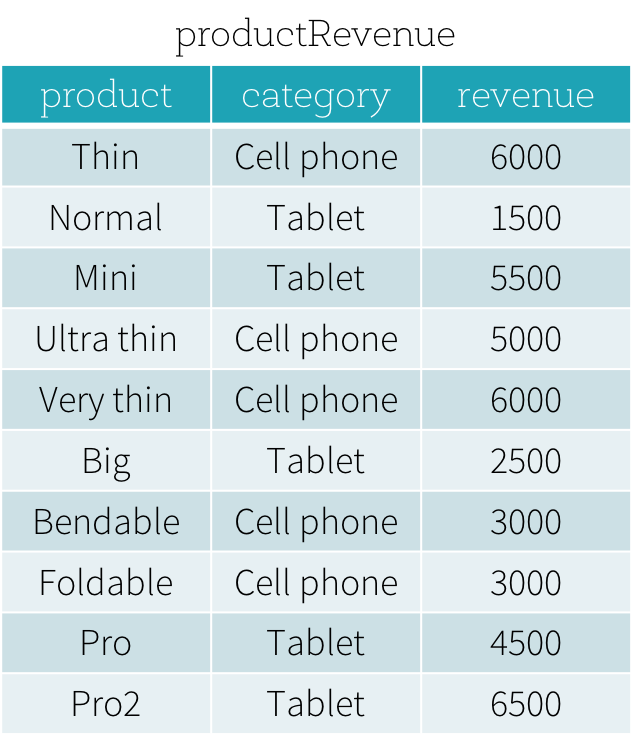
Queremos responder a duas perguntas:
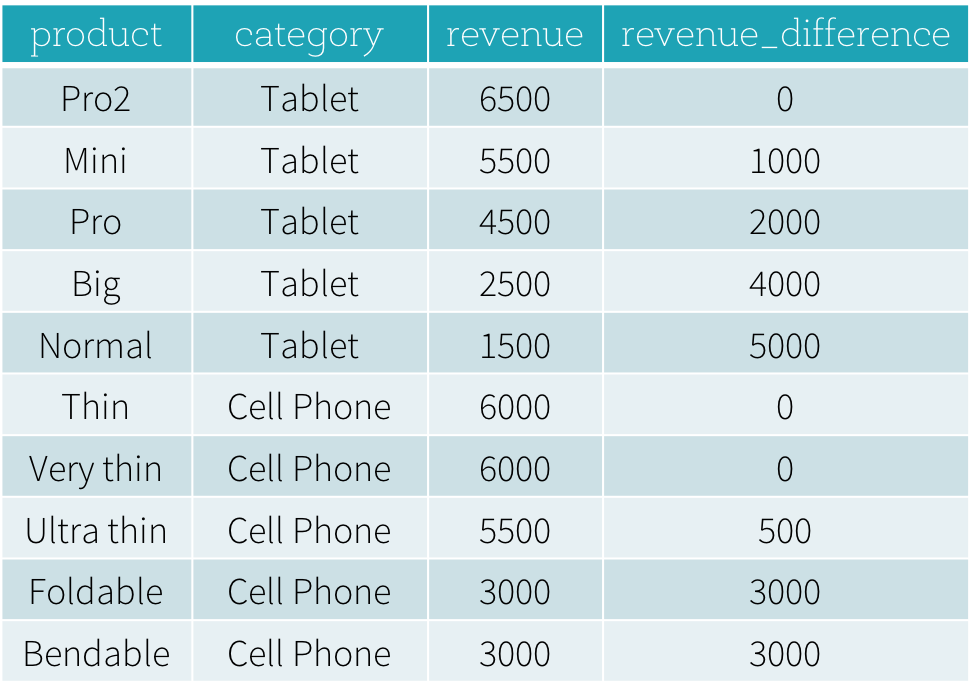
- Quais são os produtos mais vendidos e os segundos mais vendidos em cada categoria?
- Qual é a diferença entre a receita de cada produto e a receita do produto mais vendido na mesma categoria desse produto?
Para responder à primeira pergunta “Quais são os produtos mais vendidos e os segundos mais vendidos em cada categoria?”, precisamos classificar os produtos em uma categoria com base em sua receita e selecionar os produtos mais vendidos e os segundos mais vendidos com base na classificação. Abaixo está a consulta SQL usada para responder a essa pergunta usando a função de janela dense_rank (explicaremos a sintaxe de uso de funções de janela na próxima seção).
O resultado deste programa é mostrado abaixo. Sem usar funções de janela, os usuários precisam encontrar todos os maiores valores de receita de todas as categorias e, em seguida, juntar este conjunto de dados derivado com a tabela productRevenue original para calcular as diferenças de receita.
Usando Funções de Janela
O Spark SQL suporta três tipos de funções de janela: funções de classificação, funções analíticas e funções de agregação. As funções de classificação e analíticas disponíveis são resumidas na tabela abaixo. Para funções de agregação, os usuários podem usar qualquer função de agregação existente como uma função de janela.
| SQL | DataFrame API | |
| Funções de classificação | rank | rank |
| dense_rank | denseRank | |
| percent_rank | percentRank | |
| ntile | ntile | |
| row_number | rowNumber | |
| Funções analíticas | cume_dist | cumeDist |
| first_value | firstValue | |
| last_value | lastValue | |
| lag | lag | |
| lead | lead |
Para usar funções de janela, os usuários precisam marcar que uma função está sendo usada como uma função de janela, seja
- Adicionando uma cláusula OVER após uma função suportada em SQL, por exemplo,
avg(revenue) OVER (...); ou - Chamando o método over em uma função suportada na API DataFrame, por exemplo,
rank().over(...).
Uma vez que uma função é marcada como uma função de janela, o próximo passo chave é definir a Especificação de Janela associada a essa função. Uma especificação de janela define quais linhas são incluídas no frame associado a uma determinada linha de entrada. Uma especificação de janela inclui três partes:
- Especificação de Particionamento: controla quais linhas estarão na mesma partição que a linha dada. Além disso, o usuário pode querer garantir que todas as linhas com o mesmo valor para a coluna de categoria sejam coletadas para a mesma máquina antes de ordenar e calcular o frame. Se nenhuma especificação de particionamento for fornecida, todos os dados devem ser coletados para uma única máquina.
- Especificação de Ordenação: controla a maneira como as linhas em uma partição são ordenadas, determinando a posição da linha dada em sua partição.
- Especificação de Frame: indica quais linhas serão incluídas no frame para a linha de entrada atual, com base em sua posição relativa à linha atual. Por exemplo, "as três linhas precedentes à linha atual até a linha atual" descreve um frame que inclui a linha de entrada atual e três linhas que aparecem antes da linha atual.
Em SQL, as palavras-chave PARTITION BY e ORDER BY são usadas para especificar expressões de particionamento para a especificação de particionamento e expressões de ordenação para a especificação de ordenação, respectivamente. A sintaxe SQL é mostrada abaixo.
OVER (PARTITION BY ... ORDER BY ...)
Na API DataFrame, fornecemos funções utilitárias para definir uma especificação de janela. Tomando Python como exemplo, os usuários podem especificar expressões de particionamento e ordenação da seguinte forma.
Além da ordenação e particionamento, os usuários precisam definir o limite inicial do frame, o limite final do frame e o tipo de frame, que são três componentes de uma especificação de frame.
Existem cinco tipos de limites, que são UNBOUNDED PRECEDING, UNBOUNDED FOLLOWING, CURRENT ROW, UNBOUNDED PRECEDING e UNBOUNDED FOLLOWING representam a primeira linha da partição e a última linha da partição, respectivamente. Para os outros três tipos de limites, eles especificam o deslocamento da posição da linha de entrada atual e seus significados específicos são definidos com base no tipo de frame. Existem dois tipos de frames, frame ROW e frame RANGE.
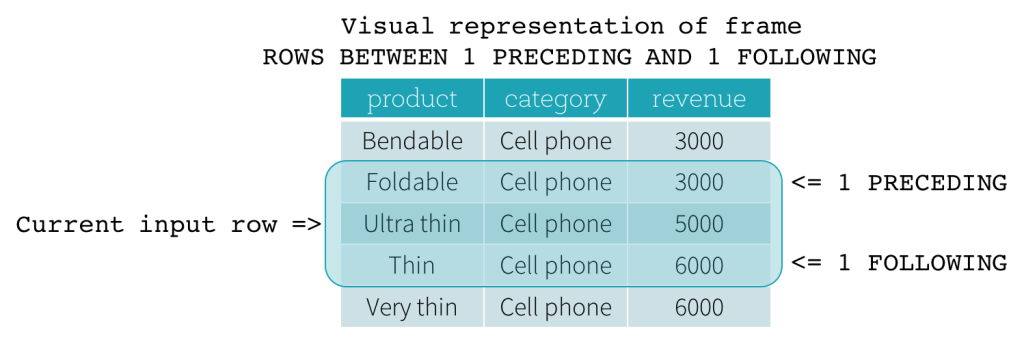
Frame ROW
Os quadros ROW são baseados em deslocamentos físicos a partir da posição da linha de entrada atual, o que significa que CURRENT ROW, CURRENT ROW for usado como um limite, ele representa a linha de entrada atual. 1 PRECEDING como limite inicial e 1 FOLLOWING como limite final (ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING na sintaxe SQL).
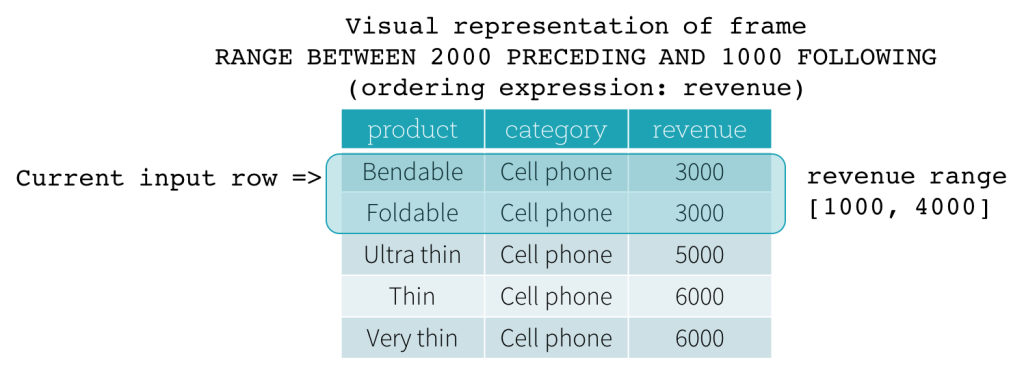
Quadro RANGE
Os quadros RANGE são baseados em deslocamentos lógicos a partir da posição da linha de entrada atual e têm sintaxe semelhante ao quadro ROW. Um deslocamento lógico é a diferença entre o valor da expressão de ordenação da linha de entrada atual e o valor dessa mesma expressão da linha limite do quadro. Devido a essa definição, quando um quadro RANGE é usado, apenas uma única expressão de ordenação é permitida. Além disso, para um quadro RANGE, todas as linhas que possuem o mesmo valor da expressão de ordenação da linha de entrada atual são consideradas como a mesma linha no que diz respeito ao cálculo do limite.
Agora, vamos dar uma olhada em um exemplo. Neste exemplo, a expressão de ordenação é revenue; o limite inicial é 2000 PRECEDING; e o limite final é 1000 FOLLOWING (este quadro é definido como RANGE BETWEEN 2000 PRECEDING AND 1000 FOLLOWING na sintaxe SQL). As cinco figuras a seguir ilustram como o quadro é atualizado com a atualização da linha de entrada atual. Basicamente, para cada linha de entrada atual, com base no valor da receita, calculamos o intervalo de receita [valor da receita atual - 2000, valor da receita atual + 1000]. Todas as linhas cujos valores de receita caem nesse intervalo estão no quadro da linha de entrada atual.
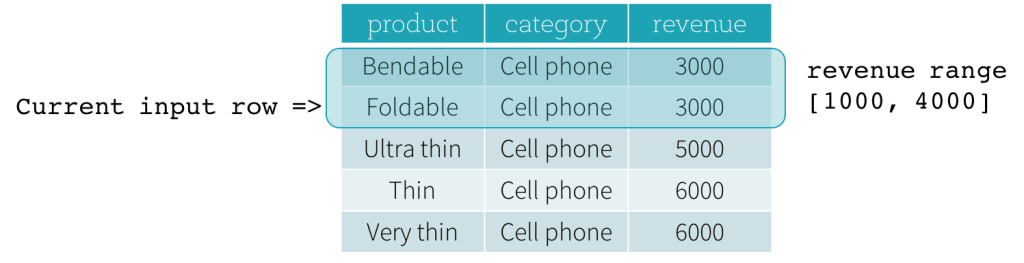
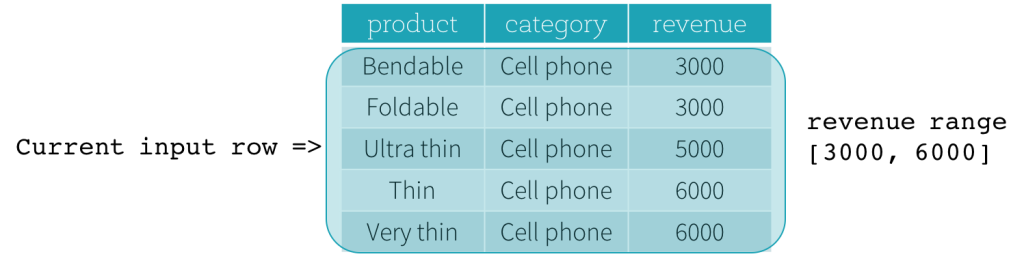
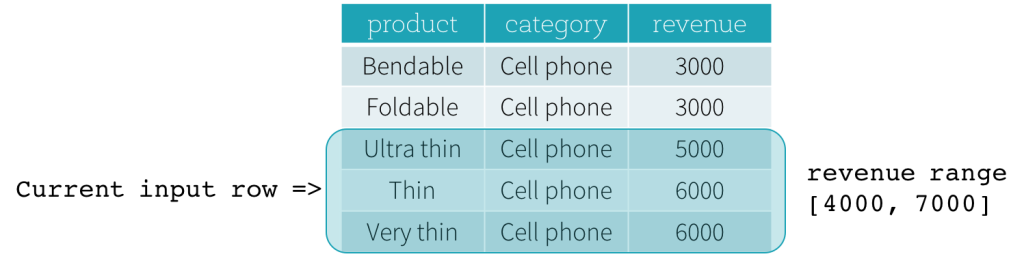
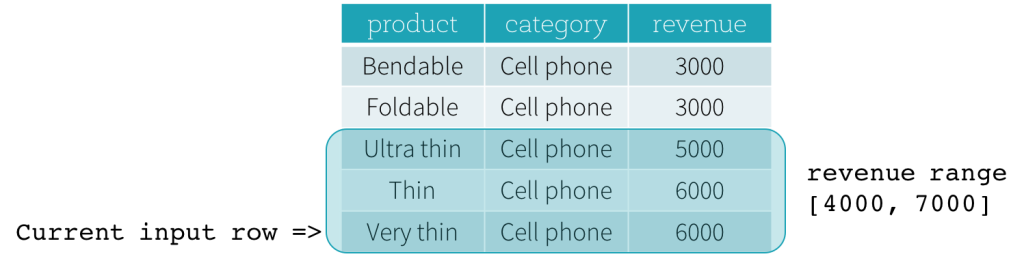
Em resumo, para definir uma especificação de janela, os usuários podem usar a seguinte sintaxe em SQL.
OVER (PARTITION BY ... ORDER BY ... frame_type BETWEEN start AND end)
Aqui, frame_type pode ser ROWS (para quadro ROW) ou RANGE (para quadro RANGE); start pode ser qualquer um de UNBOUNDED PRECEDING, CURRENT ROW, end pode ser qualquer um de UNBOUNDED FOLLOWING, CURRENT ROW,
Na API de DataFrame do Python, os usuários podem definir uma especificação de janela da seguinte forma.
E agora?
Desde o lançamento do Spark 1.4, temos trabalhado ativamente com membros da comunidade em otimizações que melhoram o desempenho e reduzem o consumo de memória do operador que avalia funções de janela. Algumas delas serão adicionadas no Spark 1.5 e outras serão adicionadas em nossos lançamentos futuros. Além do trabalho de melhoria de desempenho, há dois recursos que adicionaremos em um futuro próximo para tornar o suporte a funções de janela no Spark SQL ainda mais poderoso. Primeiro, temos trabalhado na adição de suporte ao tipo de dados Interval para os tipos de dados Date e Timestamp (SPARK-8943). Com o tipo de dados Interval, os usuários podem usar intervalos como valores especificados em
Para experimentar esses recursos do Spark, obtenha um teste gratuito do Databricks ou use a Community Edition.
Agradecimentos
O desenvolvimento do suporte a funções de janela no Spark 1.4 é um trabalho conjunto de muitos membros da comunidade Spark. Em particular, gostaríamos de agradecer a Wei Guo por contribuir com o patch inicial.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.