Explorando o Delta Lake: Desvendando o Log de Transações
![]()
O log de transações é fundamental para entender o Delta Lake porque ele é o fio condutor que atravessa muitos de seus recursos mais importantes, incluindo transações ACID, tratamento de metadados escalonável, viagem no tempo e muito mais. Neste artigo, exploraremos o que é o log de transações do Delta Lake, como ele funciona em nível de arquivo e como ele oferece uma solução elegante para o problema de múltiplas leituras e gravações concorrentes.
O que é o Log de Transações do Delta Lake?
O log de transações do Delta Lake (também conhecido como DeltaLog) é um registro ordenado de cada transação que já foi realizada em uma tabela Delta Lake desde sua criação.
Para que serve o Log de Transações?
Fonte Única de Verdade
O Delta Lake é construído sobre o Apache Spark™ para permitir que múltiplos leitores e escritores de uma determinada tabela trabalhem nela ao mesmo tempo. Para mostrar aos usuários visualizações corretas dos dados o tempo todo, o log de transações do Delta Lake serve como uma fonte única de verdade - o repositório central que rastreia todas as alterações que os usuários fazem na tabela.
Quando um usuário lê uma tabela Delta Lake pela primeira vez ou executa uma nova consulta em uma tabela aberta que foi modificada desde a última vez que foi lida, o Spark verifica o log de transações para ver quais novas transações foram postadas na tabela e, em seguida, atualiza a tabela do usuário final com essas novas alterações. Isso garante que a versão de uma tabela do usuário esteja sempre sincronizada com o registro mestre a partir da consulta mais recente e que os usuários não possam fazer alterações divergentes e conflitantes em uma tabela.
A Implementação de Atomicidade no Delta Lake
Uma das quatro propriedades das transações ACID, a atomicidade, garante que as operações (como um INSERT ou UPDATE) realizadas em seu data lake sejam concluídas totalmente ou não sejam concluídas de forma alguma. Sem essa propriedade, é muito fácil que uma falha de hardware ou um bug de software cause a gravação parcial de dados em uma tabela, resultando em dados confusos ou corrompidos.
O log de transações é o mecanismo pelo qual o Delta Lake oferece a garantia de atomicidade. Para todos os efeitos, se não estiver registrado no log de transações, nunca aconteceu. Ao registrar apenas transações que são executadas de forma completa e integral, e usando esse registro como a fonte única de verdade, o log de transações do Delta Lake permite que os usuários raciocinem sobre seus dados e tenham tranquilidade quanto à sua confiabilidade fundamental, em escala de petabytes.
Como Funciona o Log de Transações?
Dividindo Transações em Commits Atômicos
Sempre que um usuário executa uma operação para modificar uma tabela (como INSERT, UPDATE ou DELETE), o Delta Lake divide essa operação em uma série de etapas discretas compostas por uma ou mais das ações abaixo.
- Add file - adiciona um arquivo de dados.
- Remove file - remove um arquivo de dados.
- Update metadata - Atualiza os metadados da tabela (por exemplo, alterando o nome, esquema ou particionamento da tabela).
- Set transaction - Registra que um job de streaming estruturado confirmou um micro-batch com o ID fornecido.
- Change protocol - habilita novos recursos alternando o log de transações do Delta Lake para o protocolo de software mais recente.
- Commit info - Contém informações sobre o commit, qual operação foi feita, de onde e em que hora.
Essas ações são então registradas no log de transações como unidades ordenadas e atômicas conhecidas como commits.
Por exemplo, suponha que um usuário crie uma transação para adicionar uma nova coluna a uma tabela e adicionar mais dados a ela. O Delta Lake dividiria essa transação em suas partes componentes e, uma vez que a transação fosse concluída, as adicionaria ao log de transações como os seguintes commits:
- Update metadata - altera o esquema para incluir a nova coluna
- Add file - para cada novo arquivo adicionado
O Log de Transações do Delta Lake em Nível de Arquivo
Quando um usuário cria uma tabela Delta Lake, o log de transações dessa tabela é criado automaticamente no subdiretório _delta_log. À medida que ele ou ela faz alterações nessa tabela, essas alterações são registradas como commits ordenados e atômicos no log de transações. Cada commit é gravado como um arquivo JSON, começando com 000000.json. Alterações adicionais na tabela geram arquivos JSON subsequentes em ordem numérica ascendente, de modo que o próximo commit é gravado como 000001.json, o seguinte como 000002.json, e assim por diante.
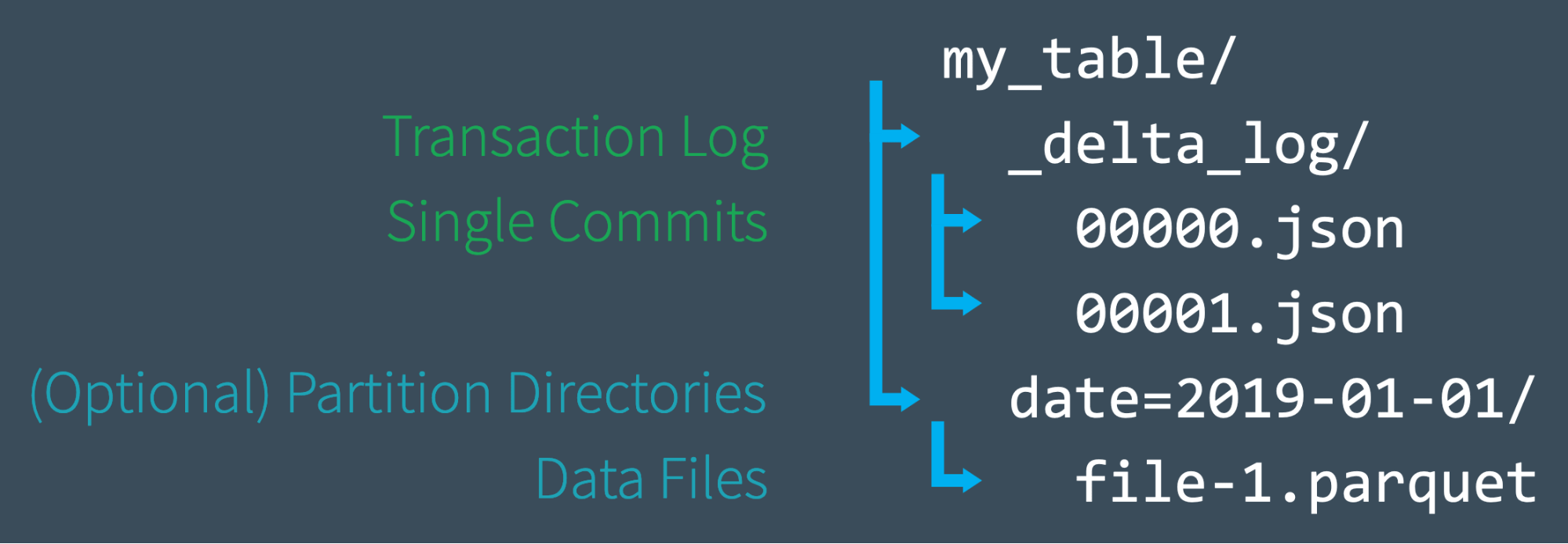
Assim, como exemplo, talvez adicionemos registros adicionais à nossa tabela a partir dos arquivos de dados 1.parquet e 2.parquet. Essa transação seria automaticamente adicionada ao log de transações, salva em disco como commit 000000.json. Então, talvez mudemos de ideia e decidamos remover esses arquivos e adicionar um novo arquivo em vez disso (3.parquet). Essas ações seriam registradas como o próximo commit no log de transações, como 000001.json, como mostrado abaixo.

Mesmo que 1.parquet e 2.parquet não façam mais parte da nossa tabela Delta Lake, sua adição e remoção ainda são registradas no log de transações porque essas operações foram realizadas em nossa tabela - apesar do fato de que elas acabaram se cancelando mutuamente. O Delta Lake ainda retém commits atômicos como esses para garantir que, caso precisemos auditar nossa tabela ou usar o "time travel" para ver como nossa tabela se parecia em um determinado ponto no tempo, possamos fazê-lo com precisão.
Além disso, o Spark não remove os arquivos do disco de forma proativa, mesmo que tenhamos removido os arquivos de dados subjacentes de nossa tabela. Os usuários podem excluir os arquivos que não são mais necessários usando VACUUM.
Recalculando Rapidamente o Estado com Arquivos de Checkpoint
Depois de fazermos vários commits no log de transações, o Delta Lake salva um arquivo de checkpoint em formato Parquet no mesmo subdiretório _delta_log. O Delta Lake gera automaticamente checkpoints conforme necessário para manter um bom desempenho de leitura.
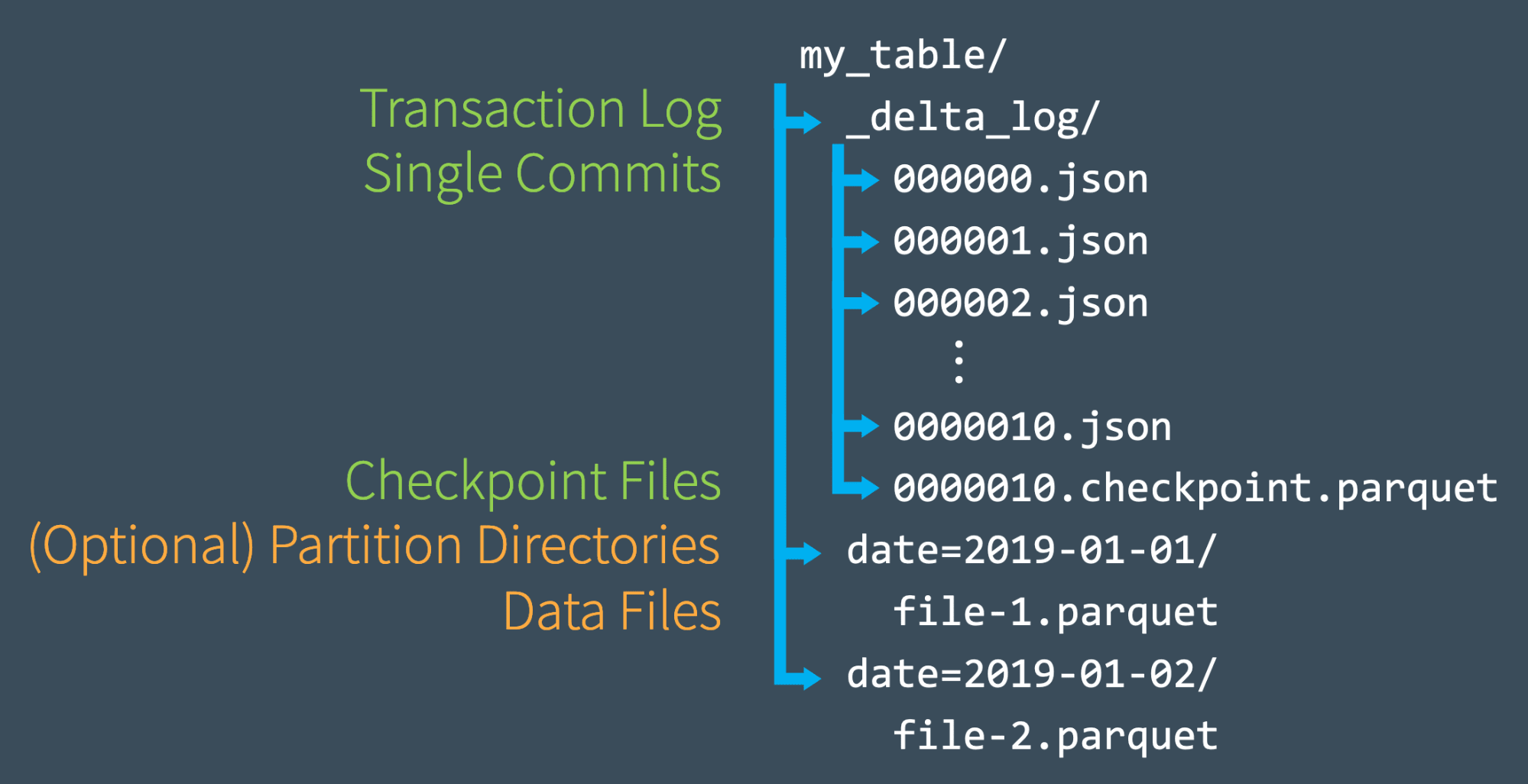
Esses arquivos de checkpoint salvam todo o estado da tabela em um determinado ponto no tempo - em formato Parquet nativo que é rápido e fácil para o Spark ler. Em outras palavras, eles oferecem ao leitor do Spark uma espécie de "atalho" para reproduzir completamente o estado de uma tabela, o que permite ao Spark evitar o reprocessamento de milhares de arquivos JSON pequenos e ineficientes.
Para se atualizar, o Spark pode executar uma operação listFrom para visualizar todos os arquivos no log de transações, pular rapidamente para o arquivo de checkpoint mais recente e processar apenas os commits JSON feitos desde que o arquivo de checkpoint mais recente foi salvo.
Para demonstrar como isso funciona, imagine que criamos commits até 000007.json, como mostrado no diagrama abaixo. O Spark está atualizado até este commit, tendo automaticamente armazenado em cache a versão mais recente da tabela na memória. Enquanto isso, no entanto, vários outros escritores (talvez seus colegas de equipe excessivamente ansiosos) escreveram novos dados na tabela, adicionando commits até 0000012.json.
Para incorporar essas novas transações e atualizar o estado de nossa tabela, o Spark executará uma operação listFrom version 7 para ver as novas alterações na tabela.

Em vez de processar todos os arquivos JSON intermediários, o Spark pode pular para o arquivo de checkpoint mais recente, pois ele contém todo o estado da tabela no commit nº 10. Agora, o Spark só precisa realizar o processamento incremental de 0000011.json e 0000012.json para ter o estado atual da tabela. O Spark então armazena em cache a versão 12 da tabela na memória. Ao seguir este fluxo de trabalho, o Delta Lake consegue usar o Spark para manter o estado de uma tabela sempre atualizado de forma eficiente.
Lidando com Múltiplas Leituras e Gravações Concorrentes
Agora que entendemos como o log de transações do Delta Lake funciona em um nível geral, vamos falar sobre concorrência. Até agora, nossos exemplos cobriram principalmente cenários em que os usuários confirmam transações linearmente, ou pelo menos sem conflitos. Mas o que acontece quando o Delta Lake está lidando com múltiplas leituras e grava�ções concorrentes?
A resposta é simples. Como o Delta Lake é alimentado pelo Apache Spark, não é apenas possível que vários usuários modifiquem uma tabela ao mesmo tempo - é esperado. Para lidar com essas situações, o Delta Lake emprega controle de concorrência otimista.
O Que é Controle de Concorrência Otimista?
O controle de concorrência otimista é um método para lidar com transações concorrentes que assume que as transações (alterações) feitas em uma tabela por diferentes usuários podem ser concluídas sem conflitar umas com as outras. É incrivelmente rápido porque, ao lidar com petabytes de dados, há uma alta probabilidade de que os usuários estejam trabalhando em partes diferentes dos dados, permitindo que eles concluam transações não conflitantes simultaneamente.
Por exemplo, imagine que você e eu estamos montando um quebra-cabeça juntos. Desde que ambos estejamos trabalhando em partes diferentes dele - você nos cantos e eu nas bordas, por exemplo - não há razão para não podermos trabalhar em nossa parte do quebra-cabeça maior ao mesmo tempo e terminar o quebra-cabeça duas vezes mais rápido. É apenas quando precisamos das mesmas peças, ao mesmo tempo, que surge um conflito. Isso é controle de concorrência otimista.
Claro, mesmo com o controle de concorrência otimista, às vezes os usuários tentam modificar as mesmas partes dos dados ao mesmo tempo. Felizmente, o Delta Lake tem um protocolo para isso.
Resolvendo Conflitos Otimisticamente
Para oferecer transações ACID, o Delta Lake tem um protocolo para descobrir como os commits devem ser ordenados (conhecido como o conceito de serialização em bancos de dados) e determinar o que fazer no caso de dois ou mais commits serem feitos ao mesmo tempo. O Delta Lake lida com esses casos implementando uma regra de exclusão mútua, e então tenta resolver qualquer conflito de forma otimista. Este protocolo permite que o Delta Lake cumpra o princípio ACID de isolamento, que garante que o estado resultante da tabela após múltiplas gravações concorrentes seja o mesmo como se essas gravações tivessem ocorrido serialmente, isoladamente umas das outras.
Em geral, o processo prossegue da seguinte forma:
- Registrar a versão inicial da tabela.
- Registrar leituras/gravações.
- Tentar um commit.
- Se outra pessoa vencer, verificar se algo que você leu mudou.
- Repetir.
Para ver como tudo isso acontece em tempo real, vamos dar uma olhada no diagrama abaixo para ver como o Delta Lake gerencia conflitos quando eles surgem. Imagine que dois usuários leiam da mesma tabela, e então cada um tente adicionar alguns dados a ela.

- O Delta Lake registra a versão inicial da tabela (versão 0) que é lida antes de fazer qualquer alteração.
- Os Usuários 1 e 2 tentam anexar alguns dados à tabela ao mesmo tempo. Aqui, encontramos um conflito porque apenas um commit pode vir em seguida e ser registrado como
000001.json. - O Delta Lake lida com esse conflito com o conceito de “exclusão mútua”, o que significa que apenas um usuário pode fazer o commit
000001.jsoncom sucesso. O commit do Usuário 1 é aceito, enquanto o do Usuário 2 é rejeitado. - Em vez de gerar um erro para o Usuário 2, o Delta Lake prefere lidar com esse conflito otimisticamente. Ele verifica se novos commits foram feitos na tabela, atualiza a tabela silenciosamente para refletir essas alterações e, em seguida, simplesmente tenta novamente o commit do Usuário 2 na tabela recém-atualizada (sem nenhum processamento de dados), confirmando com sucesso
000002.json.
Na grande maioria dos casos, essa reconciliação acontece silenciosamente, de forma integrada e bem-sucedida. No entanto, no caso de haver um problema irreconciliável que o Delta Lake não consiga resolver otimisticamente (por exemplo, se o Usuário 1 excluiu um arquivo que o Usuário 2 também excluiu), a única opção é gerar um erro.
Como nota final, como todas as transações feitas em tabelas Delta Lake são armazenadas diretamente em disco, este processo satisfaz a propriedade ACID de durabilidade, o que significa que persistirá mesmo em caso de falha do sistema.
Outros Casos de Uso
Viagem no Tempo (Time Travel)
Cada tabela é o resultado da soma total de todos os commits registrados no log de transações do Delta Lake - nem mais, nem menos. O log de transações fornece um guia de instruções passo a passo, detalhando exatamente como ir do estado original da tabela para seu estado atual.
Portanto, podemos recriar o estado de uma tabela em qualquer ponto no tempo começando com uma tabela original e processando apenas os commits feitos antes desse ponto. Essa habilidade poderosa é conhecida como “viagem no tempo” ou versionamento de dados, e pode ser uma salvação em diversas situações. Para mais informações, leia o post do blog Introducing Delta Time Travel for Large Scale Data Lakes, ou consulte a documentação de viagem no tempo do Delta Lake.
Linha do Tempo de Dados e Depuração
Como o registro definitivo de cada alteração já feita em uma tabela, o log de transações do Delta Lake oferece aos usuários uma linha do tempo de dados verificável que é útil para fins de governança, auditoria e conformidade. Ele também pode ser usado para rastrear a origem de uma alteração inadvertida ou um bug em um pipeline até a ação exata que a causou. Os usuários podem executar DESCRIBE HISTORY para ver metadados sobre as alterações que foram feitas.
Resumo do Log de Transações do Delta Lake
Neste blog, exploramos os detalhes de como o log de transações do Delta Lake funciona, incluindo:
- O que é o log de transações, como ele é estruturado e como os commits são armazenados como arquivos em disco.
- Como o log de transações serve como uma única fonte de verdade, permitindo que o Delta Lake implemente o princípio de atomicidade.
- Como o Delta Lake computa o estado de cada tabela - incluindo como ele usa o log de transações para se atualizar a partir do checkpoint mais recente.
- Usando controle de concorrência otimista para permitir múltiplas leituras e gravações concorrentes, mesmo enquanto as tabelas mudam.
- Como o Delta Lake usa exclusão mútua para garantir que os commits sejam serializados corretamente e como eles são retentados silenciosamente em caso de conflito.
Visite o hub online do Delta Lake para saber mais, baixar o código mais recente e se juntar à comunidade Delta Lake.
Relacionado
Artigos nesta série:
Mergulhando no Delta Lake #1: Desvendando o Log de Transações
Mergulhando no Delta Lake #2: Aplicação e Evolução de Esquema
Mergulhando no Delta Lake #3: Internos de DML (Update, Delete, Merge)
Artigos relacionados:
O Que é um Data Lake?
Produzindo Machine Learning com Delta Lake
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.