Como os data lakehouses resolvem problemas comuns com os data warehouses
por Ryan Boyd
Leia Rise of the Data Lakehouse para explorar por que os lakehouses são a arquitetura de dados do futuro com o pai do data warehouse, Bill Inmon.
Nota do editor: Este é o primeiro de uma série de posts amplamente baseado no artigo do CIDR Lakehouse: Uma Nova Geração de Plataformas Abertas que Unificam data warehousing e analítica Avançada, com a permissão dos autores.
Analistas de dados, cientistas de dados e especialistas em inteligência artificial geralmente ficam frustrados com a falta fundamental de dados de alta qualidade, confiáveis e atualizados disponíveis para seu trabalho. Algumas dessas frustrações se devem a desvantagens conhecidas da arquitetura de dados de duas camadas que vemos predominar na grande maioria das empresas da Fortune 500 atualmente. A arquitetura aberta de lakehouse e a tecnología subjacente podem melhorar drasticamente a produtividade das equipes de dados e, assim, a eficiência das empresas que as empregam.
Desafios com a arquitetura de dados de duas camadas
Nessa arquitetura popular, os dados de toda a organização são extraídos de bancos de dados operacionais e carregados em um data lake bruto, às vezes chamado de pântano de dados devido à falta de cuidado para garantir que esses dados sejam utilizáveis e confiáveis. Em seguida, outro processo de ETL (extração, transformação e carregamento) é executado de forma programada para mover subconjuntos importantes dos dados para um data warehouse para Business Intelligence e tomada de decisões.
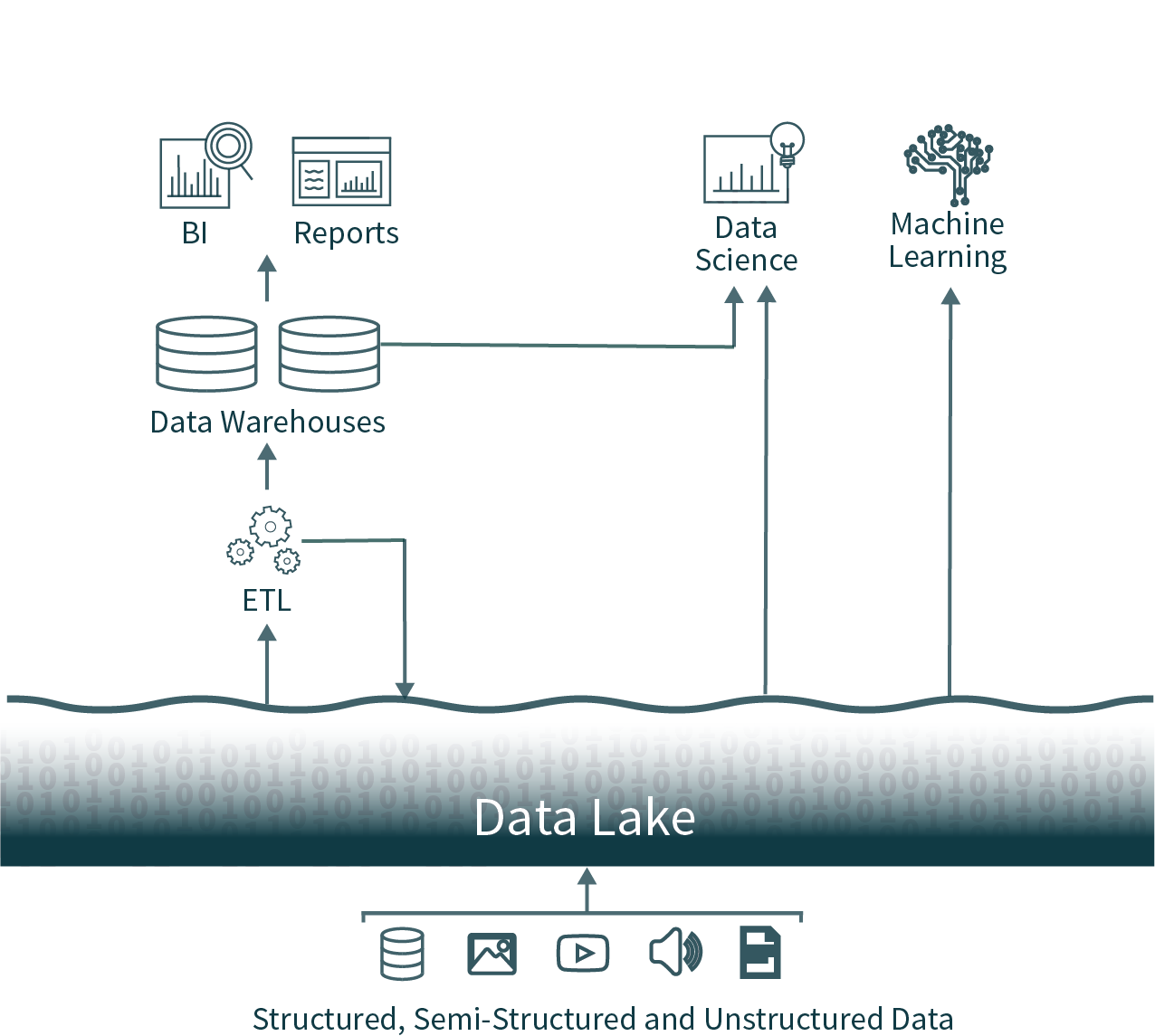
Essa arquitetura oferece aos analistas de dados uma escolha quase impossível: usar dados oportunos e não confiáveis do data lake ou usar dados desatualizados e de alta qualidade do data warehouse. Devido aos formatos fechados de soluções populares de data warehousing, também se torna muito difícil usar as estruturas de análise de dados de código aberto dominantes em fontes de dados de alta qualidade sem introduzir outra operação de ETL e adicionar mais desatualização.
Podemos fazer melhor: apresentando o Data Lakehouse
Essas arquiteturas de dados de duas camadas, comuns nas empresas de hoje, são altamente complexas tanto para os usuários quanto para os engenheiros de dados que as criam, independentemente de estarem hospedadas on-premises ou na cloud.
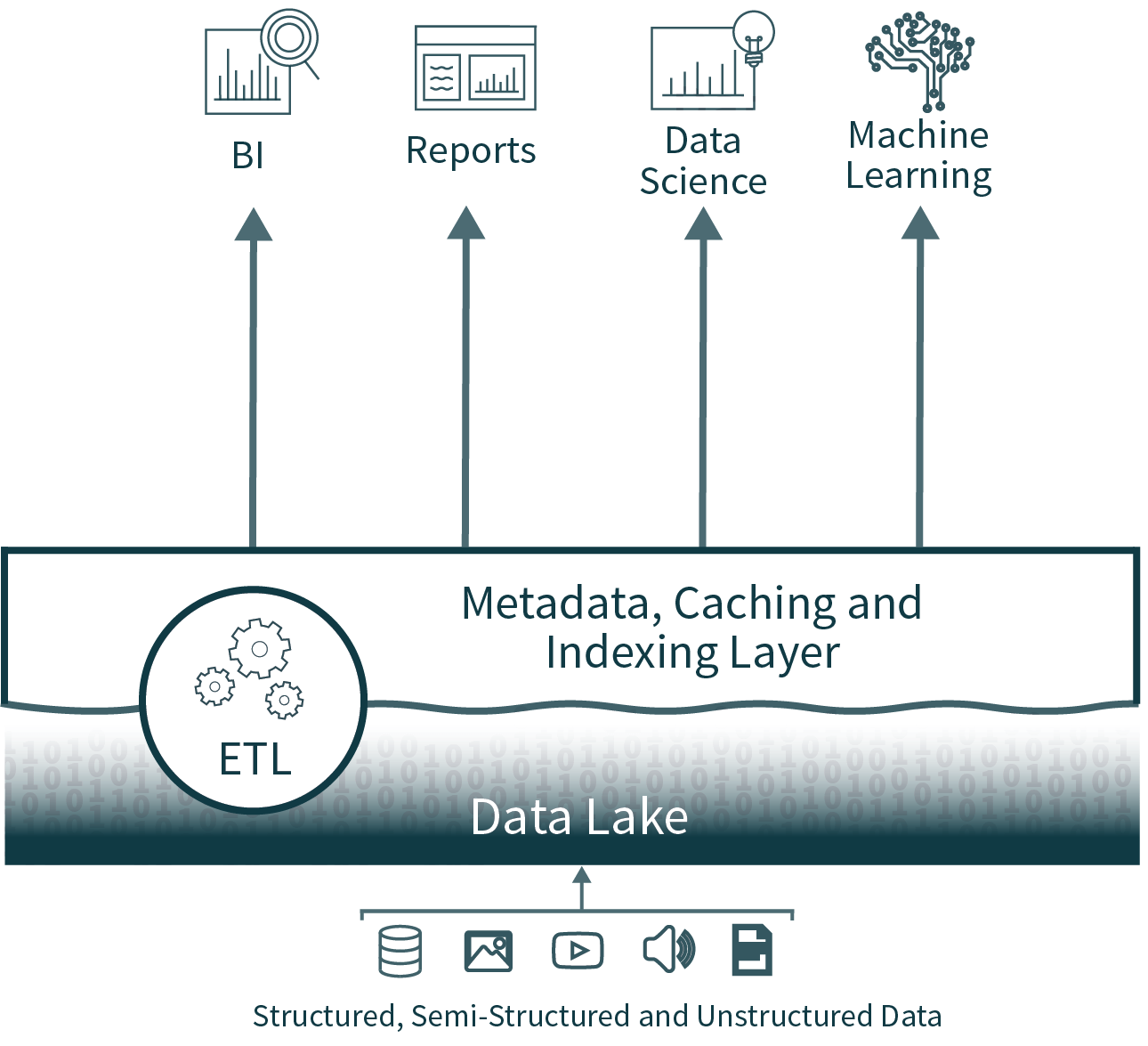
A arquitetura Lakehouse reduz a complexidade, o custo e a sobrecarga operacional, fornecendo muitos dos benefícios de confiabilidade e desempenho da camada do data warehouse diretamente sobre o data lake, eliminando, por fim, a camada do warehouse.
Confiabilidade dos dados
A consistência de dados é um desafio incrível quando você tem várias cópias de dados para manter em sincronia. Existem vários processos de ETL — movendo dados de bancos de dados operacionais para o data lake e, novamente, do data lake para o data warehouse. Cada processo adicional introduz mais complexidade, atrasos e modos de falha.
Ao eliminar a segunda camada, a arquitetura data lakehouse remove um dos processos de ETL, ao mesmo tempo que adiciona suporte para imposição e evolução de esquema diretamente sobre o data lake. Ela também oferece suporte a recursos como viagem do tempo para permitir a validação histórica da limpeza dos dados.
Desatualização de dados
Como o data warehouse é preenchido a partir do data lake, ele geralmente fica desatualizado. Isso força 86% dos analistas a usar dados desatualizados, de acordo com uma pesquisa recente da Fivetran.

Embora a eliminação da camada de data warehouse resolva esse problema, um lakehouse também pode oferecer suporte à mesclagem eficiente, fácil e confiável de transmissão em tempo real e processamento em lote, para garantir que os dados mais atualizados sejam sempre usados para análise.
Suporte limitado para analítica avançada
A analítica avançada, incluindo machine learning e análise preditiva, geralmente exige o processamento de datasets muito grandes. Ferramentas comuns, como TensorFlow, PyTorch e XGBoost, facilitam a leitura dos data lakes brutos em formatos de dados abertos. No entanto, essas ferramentas não leem a maioria dos formatos de dados proprietários usados pelos dados de ETL nos data warehouses. Os fornecedores de Warehouse, portanto, recomendam exportar esses dados para arquivos para processamento, resultando em um terceiro passo de ETL, além de maior complexidade e desatualização.
Como alternativa, na arquitetura de lakehouse aberto, esses conjuntos de ferramentas comuns podem operar diretamente em dados oportunos de alta qualidade armazenados no data lake.
Custo total de propriedade
Embora os custos de armazenamento na cloud estejam diminuindo, essa arquitetura de duas camadas para análise de dados na verdade tem três cópias on-line de grande parte dos dados corporativos: uma nos bancos de dados operacionais, uma no data lake e uma no data warehouse.
O custo total de propriedade (TCO) se agrava ainda mais ao adicionar os custos significativos de engenharia para manter os dados sincronizados aos custos de armazenamento.
A arquitetura de data lakehouse elimina uma das cópias mais caras dos dados, bem como pelo menos um processo de sincronização associado.
E quanto ao desempenho para Business Intelligence?
Business Intelligence e suporte à decisão exigem execução de alto desempenho de queries de análise exploratória de dados (EDA), bem como queries que alimentam dashboards, visualizações de dados e outros sistemas essenciais. As preocupações com o desempenho eram frequentemente o motivo pelo qual as empresas mantinham um data warehouse além de um data lake. A tecnología para otimizar queries em data lakes melhorou imensamente no último ano, tornando a maioria dessas preocupações de desempenho irrelevantes.
Os Lakehouses oferecem suporte para indexação, controles de localidade, otimização de queries e cache de dados quentes para melhorar o desempenho. Isso resulta em um desempenho SQL de data lake que supera os principais cloud data warehouses no TPC-DS, além de fornecer a flexibilidade e a governança esperadas dos data warehouses.
Conclusão e os próximos passos
Empresas e tecnólogos com visão de futuro olharam para a arquitetura de duas camadas usada atualmente e disseram: “precisa haver um jeito melhor”. Esse jeito melhor é o que chamamos de data lakehouse aberto, que combina a abertura e a flexibilidade do data lake com a confiabilidade, o desempenho, a baixa latência e a alta simultaneidade dos data warehouses tradicionais.
Abordarei mais detalhes sobre as melhorias no desempenho do data lake em um post futuro desta série.
Claro, você pode pular etapas lendo o artigo completo do CIDR ou assistindo a uma série de vídeos que mergulha na tecnología subjacente que suporta o lakehouse moderno.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.