API do Pandas no próximo Apache Spark™ 3.2
por Hyukjin Kwon e Xinrong Meng
A Free Edition substituiu a Community Edition, oferecendo recursos aprimorados sem custo. Comece a usar a Free Edition hoje mesmo.
Temos o prazer de anunciar que a API do pandas fará parte do próximo lançamento do Apache Spark™ 3.2. O pandas é uma biblioteca poderosa e flexível que cresceu rapidamente e se tornou uma das bibliotecas padrão de ciência de dados. Agora, os usuários do pandas poderão aproveitar a API do pandas em seus clusters Spark existentes.
Há alguns anos, lançamos o Koalas, um projeto de código aberto que implementa a API pandas DataFrame no Spark, que se tornou amplamente adotado entre data scientists. Recentemente, o Koalas foi oficialmente incorporado ao PySpark pelo SPIP: Support pandas API layer on PySpark como parte do Project Zen (veja também Project Zen: Making Data Science Easier in PySpark do Data + AI Summit 2021).
Os usuários do pandas poderão escalar suas cargas de trabalho com uma simples alteração de linha no próximo lançamento do Spark 3.2:
Esta postagem no blog resume o suporte à API do pandas no Spark 3.2 e destaca os recursos notáveis, as mudanças e o roteiro.
Escalabilidade além de uma única máquina
Uma das limitações conhecidas do pandas é que ele não escala linearmente com o volume de dados devido ao processamento em uma única máquina. Por exemplo, o pandas falha por falta de memória se tentar ler um dataset maior que a memória disponível em uma única máquina:
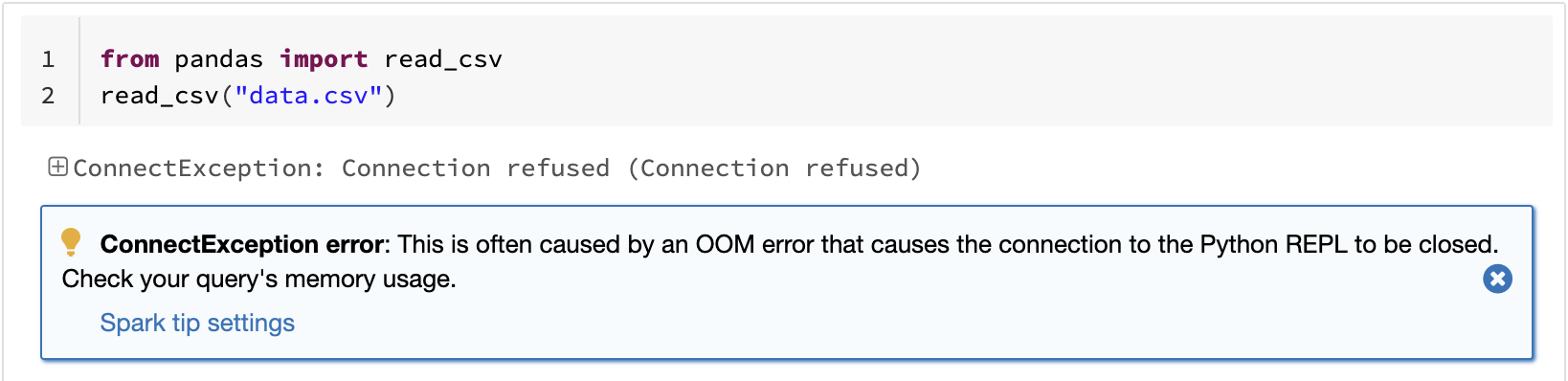
A API do pandas no Spark supera a limitação, permitindo que os usuários trabalhem com grandes datasets aproveitando o Spark:

A API do pandas no Spark também escala bem para grandes clusters de nós. O gráfico abaixo mostra seu desempenho ao analisar um dataset Parquet de 15 TB com clusters de tamanhos diferentes. Cada máquina no cluster tem 8 vCPUs e 61 GiB de memória.
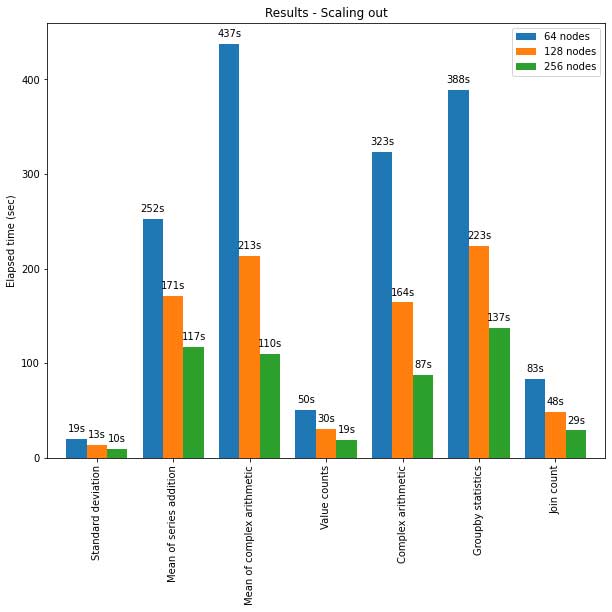
A execução distribuída da API do pandas no Spark escala quase linearmente neste teste. O tempo decorrido diminui pela metade quando o número de máquinas dentro de um cluster dobra. A aceleração em comparação com uma única máquina também é significativa. Por exemplo, no benchmark de desvio padrão, um cluster de 256 máquinas consegue processar aproximadamente 250 vezes mais dados do que uma única máquina em aproximadamente o mesmo tempo (cada máquina tem 8 vCPUs e 61 GiB de memória):
| Máquina única | Cluster de 256 máquinas | |
| Conjunto de dados Parquet | 60GB | 60 GB x 250 (15 TB) |
| Tempo decorrido (s) do desvio padrão | 12s | 10 s |
Desempenho otimizado em máquina única
A API do pandas no Spark geralmente supera o pandas mesmo em uma única máquina, graças às otimizações no mecanismo Spark. O gráfico abaixo demonstra a API do pandas no Spark em comparação com o pandas em uma máquina (com 96 vCPUs e 384 GiB de memória) em um dataset CSV de 130 GB:
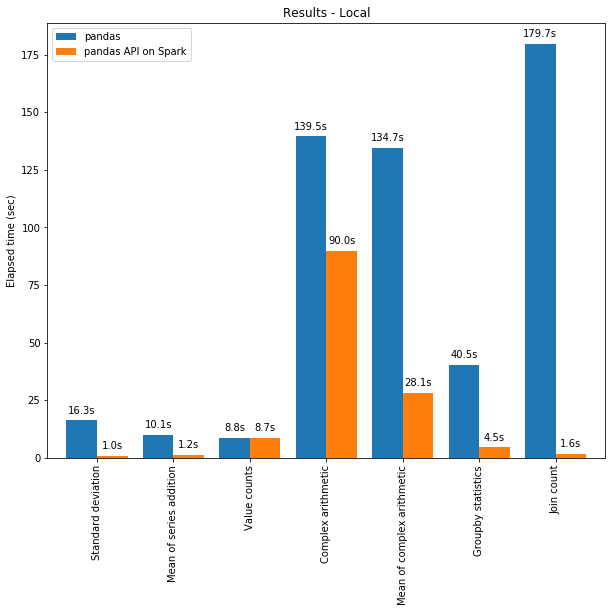
Tanto o multithreading quanto o otimizador Catalyst do Spark SQL contribuem para o desempenho otimizado. Por exemplo, a operação Join count é aproximadamente 4 vezes mais rápida com a geração de código de estágio completo: 5,9 s sem geração de código, 1,6 s com geração de código.
O Spark tem uma vantagem especialmente significativa no encadeamento de operações. O otimizador de queries Catalyst pode reconhecer filtros para pular dados de forma inteligente e aplicar joins baseados em disco, enquanto o pandas tende a carregar todos os dados na memória a cada passo.
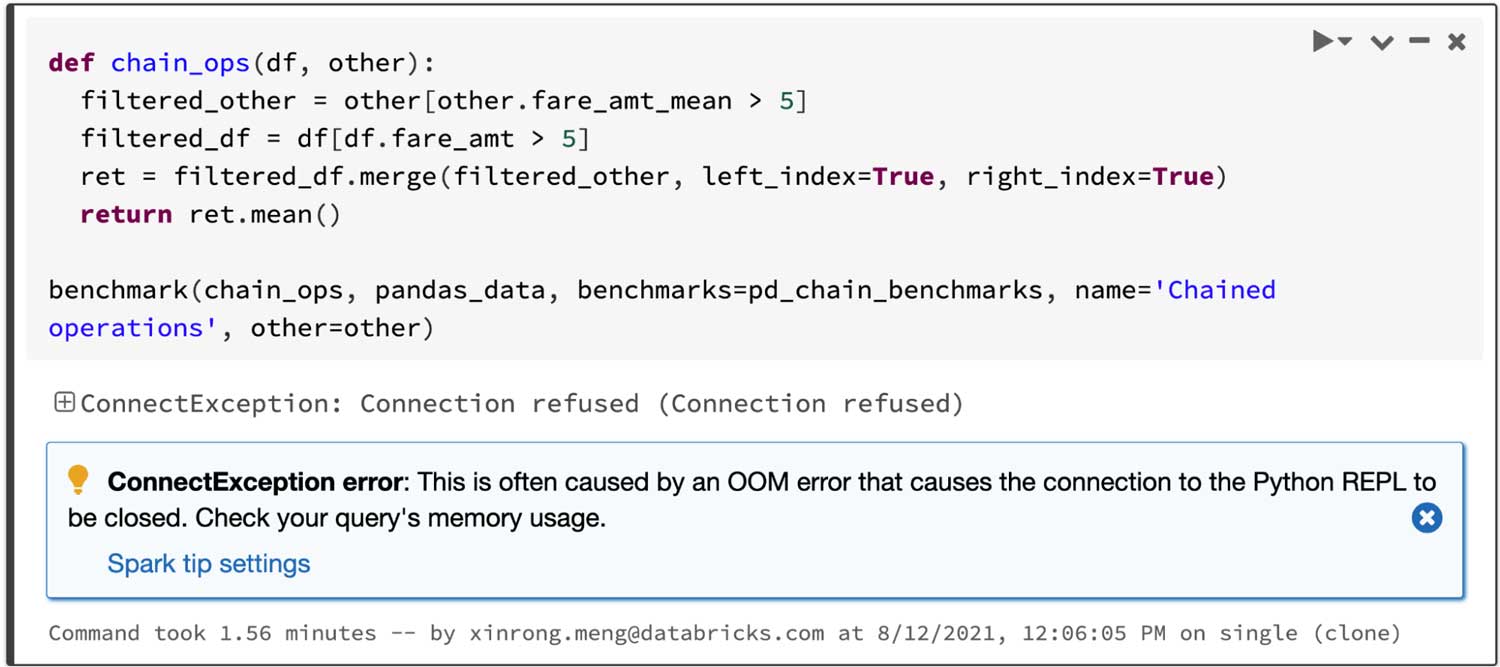
Considerando uma query que une dois frames filtrados e, em seguida, compute a média do frame unido, a API do pandas no Spark é concluída em 4,5 s, enquanto o pandas falha devido ao erro de OOM (falta de memória) abaixo:
Visualização de dados interativa
O pandas usa o matplotlib por default, que fornece gráficos estáticos. Por exemplo, os códigos abaixo geram um gráfico estático:
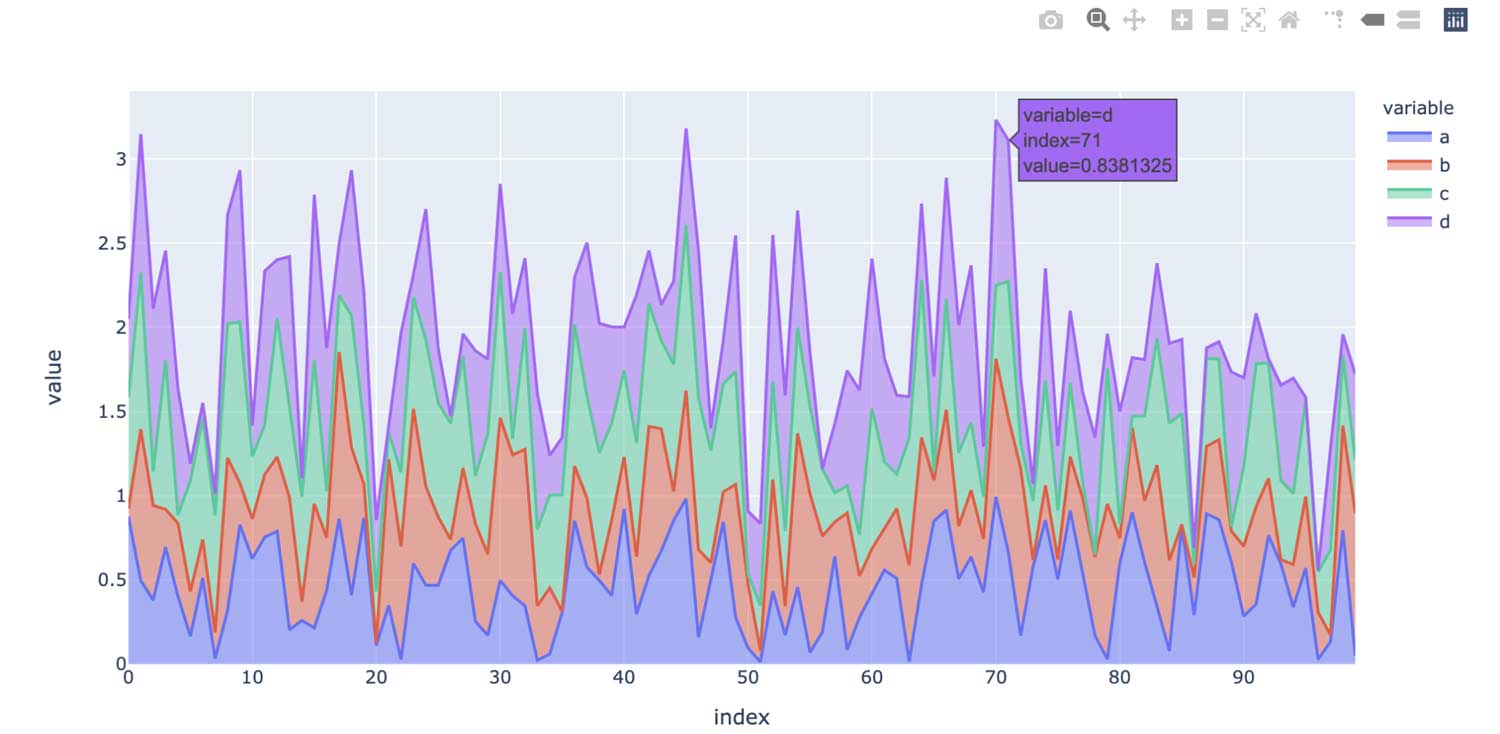
Em contraste, a API do pandas no Spark usa um backend plotly default, que fornece gráficos interativos. Por exemplo, ele permite que os usuários aumentem e diminuam o zoom interativamente. Com base no tipo de gráfico, a API do pandas no Spark determina automaticamente a melhor maneira de executar a computação internamente ao gerar gráficos interativos:
Aproveitando a funcionalidade de análise unificada no Spark
O pandas foi projetado para ciência de dados em Python com processamento em lotes, enquanto o Spark foi projetado para unified analytics, incluindo SQL, processamento de transmissão e machine learning. Para preencher a lacuna entre eles, a API do pandas no Spark oferece muitas maneiras diferentes para que usuários avançados aproveitem o mecanismo do Spark, por exemplo:
- Os usuários podem consultar dados diretamente via SQL com o mecanismo de SQL otimizado do Spark, conforme mostrado abaixo:
- Ele também suporta a sintaxe de interpolação de strings para interagir com objetos Python naturalmente:
- A API do pandas no Spark também oferece suporte a processamento de transmissão:
- Os usuários podem chamar facilmente as bibliotecas do machine learning escaláveis no Spark:
Consulte também a postagem no blog sobre a interoperabilidade entre o PySpark e a API do pandas no Spark.
Quais são os próximos passos?
Para as próximas versões do Spark, o roteiro se concentra em:
• Mais dicas de tipo
O código na API do pandas no Spark está atualmente parcialmente tipado, o que ainda permite análise estática e preenchimento automático. No futuro, todo o código será totalmente tipado.
• Melhorias de desempenho
Há vários pontos na API do pandas no Spark em que podemos melhorar ainda mais o desempenho, interagindo mais de perto com o engine e o otimizador de SQL.
• Estabilização
Há vários pontos para corrigir, especialmente relacionados a valores ausentes, como NaN e NA, que apresentam casos extremos com diferenças de comportamento.
Além disso, a API do pandas no Spark alinhará seu comportamento com a versão mais recente do pandas nesses casos.
• Mais cobertura de API
A API do pandas no Spark atingiu 83% de cobertura da API do pandas, e esse número continua a aumentar. Agora, a meta é de até 90%.
Por favor, abra uma issue se houver bugs ou recursos ausentes de que você precise e, claro, sempre aceitamos contribuições da comunidade.
Introdução
Se você quiser experimentar a API do pandas no Spark no Databricks Runtime 10.0 Beta (próximo Apache Spark 3.2), inscreva-se no Databricks Community Edition ou no Databricks Trial gratuitamente e comece a usar em minutos.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.