Como Acelerar o Fluxo de Dados entre Databricks e SAS
por Oleg Mikhov e Satish Garla
Esta é uma publicação colaborativa entre Databricks e T1A. Agradecemos a Oleg Mikhov, Arquiteto de Soluções na T1A, por suas contribuições.
Este é o primeiro post de uma série de blogs sobre as melhores práticas para unir a Databricks Lakehouse Platform e o SAS. Um post anterior da Databricks introduziu o Databricks e o PySpark para desenvolvedores SAS. Neste post, discutimos maneiras de trocar dados entre a Databricks Lakehouse Platform e o SAS, e formas de acelerar o fluxo de dados. Em posts futuros, exploraremos a construção de pipelines eficientes de dados e analytics envolvendo ambas as tecnologias.
Organizações orientadas por dados estão adotando rapidamente a plataforma Lakehouse para acompanhar as crescentes demandas de negócios. A plataforma Lakehouse se tornou a nova norma para organizações que desejam construir plataformas e arquiteturas de dados. A modernização implica mover dados, aplicações ou outros elementos de negócios para a nuvem. No entanto, a transição para a nuvem é um processo gradual e é crucial para os negócios continuar aproveitando os investimentos legados pelo maior tempo possível. Com isso em mente, muitas empresas tendem a ter múltiplas plataformas de dados e analytics, onde as plataformas coexistem e se complementam.
Uma das combinações que vemos é o uso do SAS com a Databricks Lakehouse. Existem muitos benefícios em permitir que as duas plataformas trabalhem juntas de forma eficiente, como:
- Capacidades de armazenamento de dados maiores e escaláveis das plataformas de nuvem
- Maior capacidade de computação usando tecnologias, como Apache Spark™, nativamente construídas com capacidades de processamento paralelo
- Alcançar maior conformidade com governança e gerenciamento de dados usando Delta Lake
- Reduzir o custo da infraestrutura de análise de dados com arquiteturas simplificadas
Alguns casos de uso e razões comuns de ciência de dados e análise de dados observados são:
- Profissionais de SAS utilizam o SAS por seus pacotes estatísticos principais para desenvolver resultados de análise avançada que atendem aos requisitos regulatórios, enquanto usam a Databricks Lakehouse para gerenciamento de dados, processamento do tipo ELT e governança de dados
- Modelos de machine learning desenvolvidos em SAS são pontuados em grandes volumes de dados usando a arquitetura de processamento paralelo do motor Apache Spark na plataforma Lakehouse
- Analistas de dados SAS obtêm acesso mais rápido a grandes volumes de dados na Lakehouse Platform para análise ad-hoc e relatórios usando endpoints Databricks SQL e conectores de alta largura de banda
- Facilitar a jornada de modernização e migração para a nuvem estabelecendo um fluxo de trabalho híbrido envolvendo arquitetura de nuvem e plataforma SAS on-premise
No entanto, um desafio chave dessa coexistência é como os dados são compartilhados de forma performática entre as duas plataformas. Neste blog, compartilhamos as melhores práticas implementadas pela T1A para seus clientes e resultados de benchmark comparando diferentes métodos de movimentação de dados entre Databricks e SAS.
Cenários
O caso de uso mais popular é um desenvolvedor SAS tentando acessar dados no lakehouse. Os pipelines de analytics envolvendo ambas as tecnologias exigem fluxo de dados em ambas as direções: dados movidos do Databricks para SAS e dados movidos do SAS para Databricks.
- Acessar Delta Lake do SAS: Um usuário SAS deseja acessar big data no Delta Lake usando a linguagem de programação SAS.
- Acessar datasets SAS do Databricks: Um usuário Databricks deseja acessar datasets SAS, geralmente os datasets sas7bdat como um DataFrame para processar em pipelines Databricks ou armazenar no Delta Lake para acesso em toda a empresa.
Em nossos testes de benchmark, usamos a seguinte configuração de ambiente:
- Microsoft Azure como a plataforma de nuvem
- SAS 9.4M7 no Azure (VM Standard D8s v3 de nó único)
- Databricks runtime 9.0, Apache Spark 3.1.2 (cluster Standard DS4v2 de 2 nós)
A Figura 1 mostra o diagrama conceitual da arquitetura com os componentes discutidos. Databricks Lakehouse reside no Azure Data Lake storage com arquitetura de medalhão Delta Lake. O SAS 9.4 instalado em uma VM Azure se conecta à Databricks Lakehouse para ler/escrever dados usando opções de conexão discutidas nas seções seguintes.
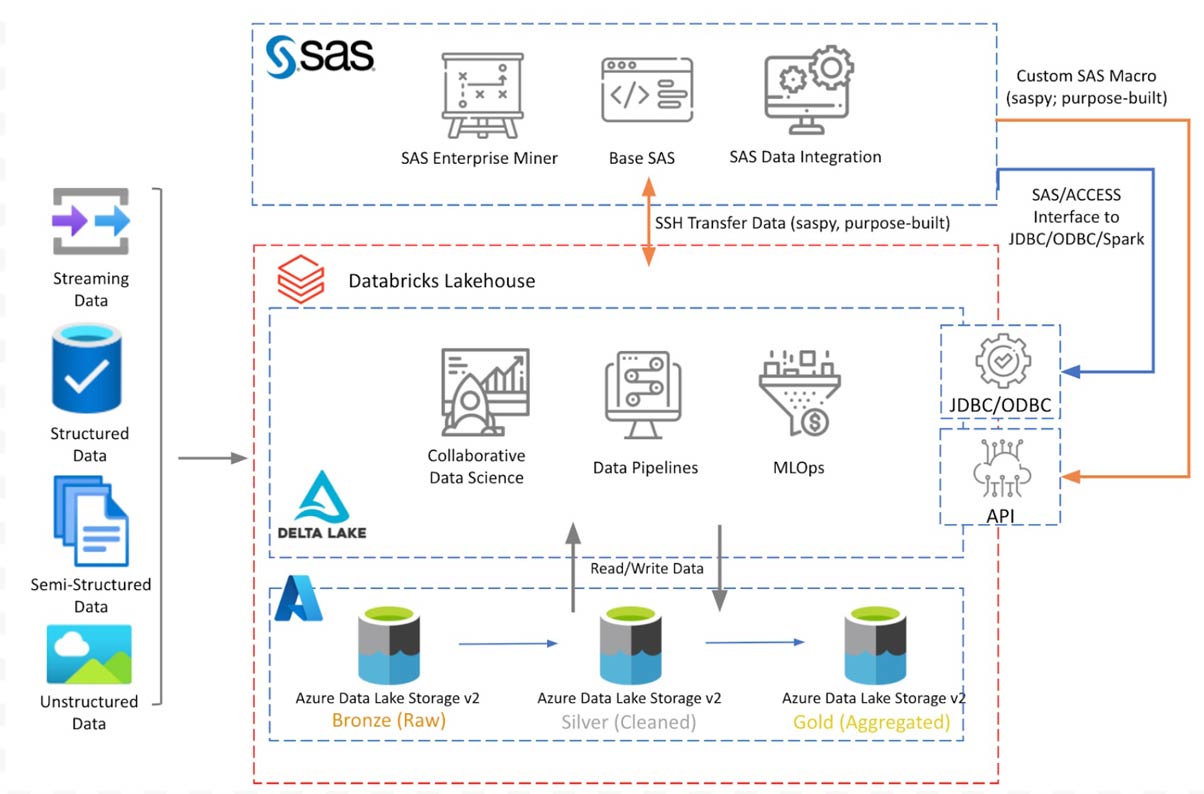
O diagrama acima mostra uma arquitetura conceitual do Databricks implantado no Azure. A arquitetura será semelhante em outras plataformas de nuvem. Neste blog, discutimos apenas a integração com a plataforma SAS 9.4. Em um post futuro, estenderemos essa discussão para acessar dados do lakehouse a partir do SAS Viya.
Acessar Delta Lake do SAS
Imagine que temos uma tabela Delta Lake que precisa ser processada em um programa SAS. Queremos o melhor desempenho ao acessar essa tabela, evitando também quaisquer problemas possíveis com integridade de dados ou compatibilidade de tipos de dados. Existem diferentes maneiras de alcançar integridade e compatibilidade de dados. Abaixo discutimos alguns métodos e os comparamos em facilidade de uso e desempenho.
Em nossos testes, usamos o conjunto de dados de comportamento de e-commerce (5,67 GB, 9 colunas, ~ 42 milhões de registros) do Kaggle.
Crédito da Fonte de Dados: Dados de comportamento de e-commerce de loja multicanal e REES46 Marketing Platform.
Métodos testados
1. Usando conectores da Interface SAS/ACCESS
Tradicionalmente, usuários SAS utilizam o software SAS/ACCESS para se conectar a fontes de dados externas. Você pode usar uma instrução LIBNAME do SAS apontando para o cluster Databricks ou usar a facilidade de passagem de SQL. Atualmente, para SAS 9.4, existem três opções de conexão disponíveis.
Exemplos de código sobre como usar esses conectores podem ser encontrados neste repositório git: T1A Git - Exemplos de Bibliotecas SAS.
2. Usando o pacote saspy
A biblioteca de código aberto, saspy, do SAS Institute permite que usuários do Databricks Notebook executem instruções SAS de uma célula Python no notebook para executar código no servidor SAS, bem como importar e exportar dados de datasets SAS para Pandas DataFrame.
Como o foco desta seção é o acesso a dados do lakehouse por um programador SAS usando programação SAS, este método foi encapsulado em um programa macro SAS semelhante ao método de integração desenvolvido especificamente, discutido a seguir.
Para obter melhor desempenho com este pacote, testamos a configuração com uma opção char_length definida (detalhes disponíveis aqui). Com essa opção, podemos definir comprimentos para campos de caracteres no dataset. Em nossos testes, o uso dessa opção trouxe um aumento adicional de 15% no desempenho. Para a camada de transporte entre ambientes, usamos a configuração saspy com uma conexão SSH ao servidor SAS.
3. Usando uma integração desenvolvida especificamente
Embora os dois métodos mencionados acima tenham suas vantagens, o desempenho pode ser ainda mais aprimorado abordando algumas deficiências, discutidas na próxima seção (Resultados do Teste), dos métodos anteriores. Com isso em mente, desenvolvemos uma utilidade de integração baseada em macro SAS com foco principal em desempenho e usabilidade para usuários SAS. A macro SAS pode ser facilmente integrada ao código SAS existente sem nenhum conhecimento sobre a plataforma Databricks, Apache Spark ou Python.
A macro orquestra um processo de várias etapas usando a API Databricks:
- Instrua o cluster Databricks a consultar e extrair dados de acordo com a consulta SQL fornecida e a armazenar em cache os resultados no DBFS, aproveitando suas capacidades de processamento distribuído do Spark SQL.
- Compacte e transfira com segurança o conjunto de dados para o servidor SAS (CSV em GZIP) via SSH
- Descompacte e importe os dados para o SAS para torná-los disponíveis ao usuário na biblioteca SAS. Nesta etapa, aproveite os metadados de coluna do catálogo de dados Databricks (tipos de coluna, comprimentos e formatos) para uma apresentação de dados consistente, correta e eficiente no SAS
Observe que, para tipos de dados de comprimento variável, a integração suporta diferentes opções de configuração, dependendo do que melhor se adapta aos requisitos do usuário, como:
- Necessidade de usar um valor padrão configurável
- Análise de até 10.000 linhas (+ margem de manobra) para identificar o maior valor
- Análise da coluna inteira no conjunto de dados para identificar o maior valor
Uma versão simplificada do código está disponível aqui T1A Git - SAS DBR Custom Integration.
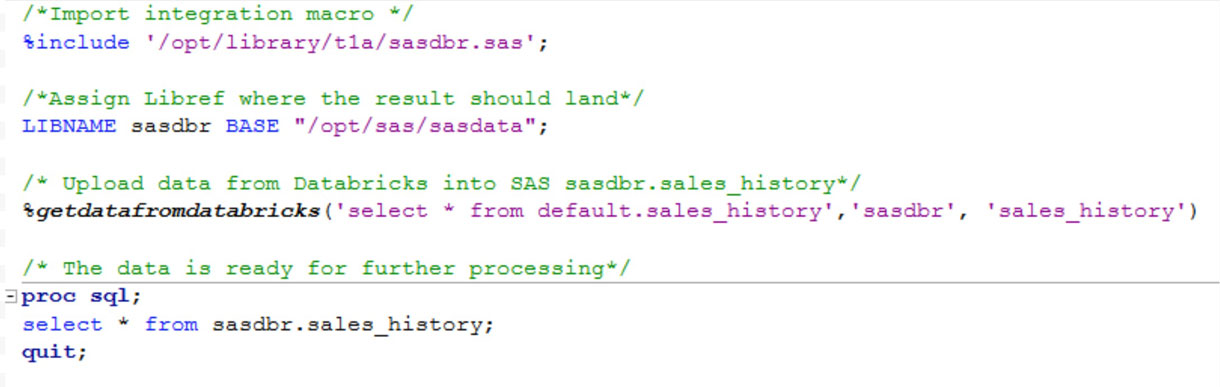
O uso pelo usuário final desta macro SAS é mostrado abaixo e requer três entradas:
- Consulta SQL, com base na qual os dados serão extraídos do Databricks
- Libref SAS onde os dados devem ser salvos
- Nome a ser dado ao conjunto de dados SAS
Resultados do teste
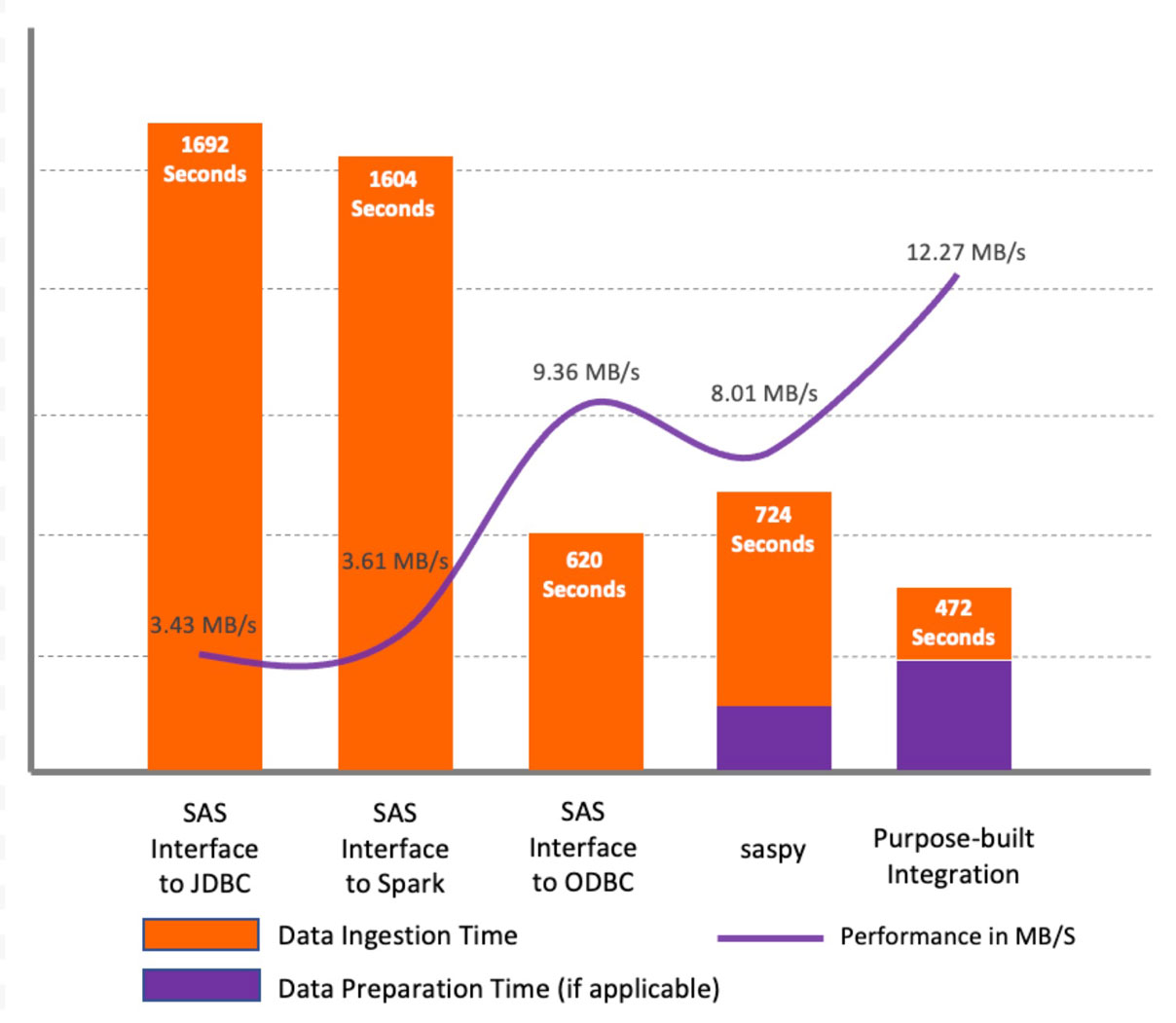
Conforme mostrado no gráfico acima, para o conjunto de dados de teste, os resultados indicam que o SAS/ACCESS Interface to JDBC e o SAS/ACCESS Interface to Apache Spark apresentaram desempenho semelhante e inferior em comparação com outros métodos. A principal razão para isso é que os métodos JDBC não analisam colunas de caracteres em conjuntos de dados para definir o comprimento correto da coluna no conjunto de dados SAS. Em vez disso, eles definem o comprimento padrão para todos os tipos de coluna de caracteres (String e Varchar) como 765 símbolos. Isso causa não apenas problemas de desempenho durante a recuperação inicial dos dados, mas para todo o processamento posterior. Além disso, consome armazenamento adicional significativo. Em nossos testes, para o conjunto de dados de origem de 5,6 GB, terminamos com um arquivo de 216 GB na biblioteca WORK. No entanto, com o SAS/ACCESS Interface to ODBC, o comprimento padrão foi de 255 símbolos, o que resultou em um aumento significativo de desempenho.
O uso dos métodos SAS/ACCESS Interface é a opção mais conveniente para usuários SAS existentes. Existem algumas considerações importantes ao usar esses métodos:
- Ambas as soluções suportam passagem implícita de consulta, mas com algumas limitações:
- SAS/ACCESS Interface to JDBC/ODBC suporta apenas passagem para instruções PROC SQL
- Além da passagem PROC SQL, SAS/ACCESS Interface to Apache Spark suporta passagem para a maioria das funções SQL. Este método também permite o envio de procedimentos SAS comuns para clusters Databricks.
- O problema com a definição do comprimento das colunas de caracteres descrito anteriormente. Como solução alternativa, sugerimos usar a opção DBSASTYPE para definir explicitamente o comprimento da coluna para tabelas SAS. Isso ajudará no processamento posterior do conjunto de dados, mas não afetará a recuperação inicial dos dados do Databricks
- SAS/ACCESS Interface to Apache Spark/JDBC/ODBC não permite combinar tabelas de diferentes bancos de dados Databricks (esquemas) atribuídos como librefs diferentes na mesma consulta (juntando-as) com o recurso de passagem. Em vez disso, isso causará a exportação de tabelas inteiras no SAS e o processamento no SAS. Como solução alternativa, sugerimos a criação de um esquema dedicado no Databricks que conterá visualizações baseadas em tabelas de diferentes bancos de dados (esquemas).
O uso do método saspy mostrou um desempenho ligeiramente melhor em comparação com os métodos SAS/ACCESS Interface to JDBC/Spark, no entanto, a principal desvantagem é que a biblioteca saspy funciona apenas com DataFrames pandas e coloca uma carga significativa no programa driver do Apache Spark, exigindo que todo o DataFrame seja carregado na memória.
O método de integração desenvolvida para fins específicos mostrou o melhor desempenho em comparação com outros métodos testados. A Figura 3 mostra um fluxograma com orientações de alto nível para escolher entre os métodos discutidos.
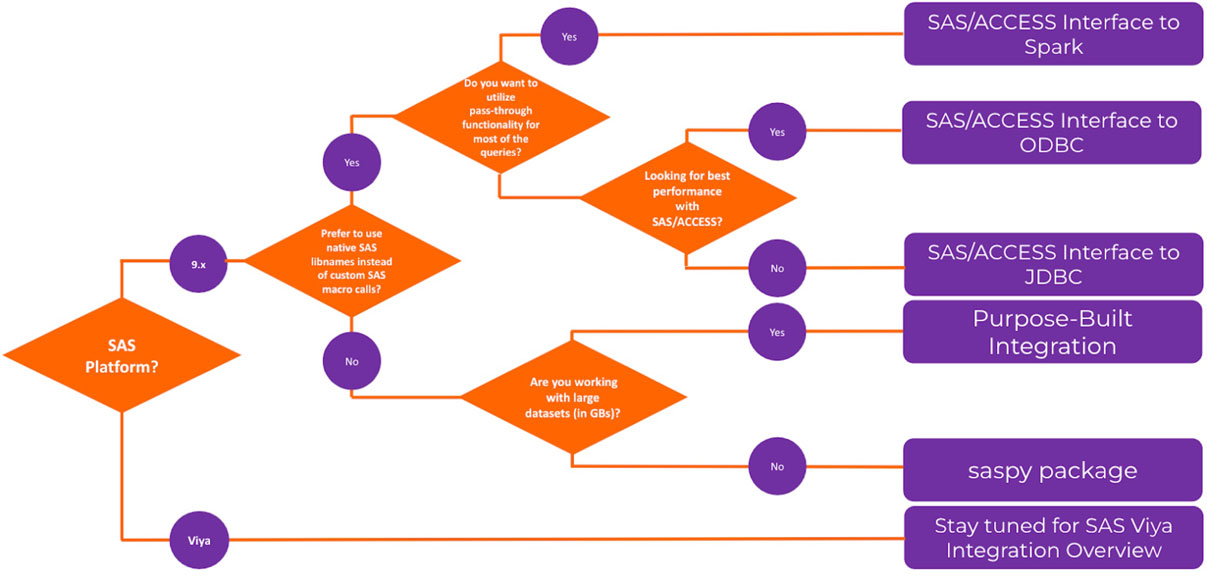
Acessar conjuntos de dados SAS do Databricks
Esta seção aborda a necessidade de desenvolvedores Databricks ingerirem um conjunto de dados SAS no Delta Lake e disponibilizá-lo no Databricks para business intelligence, análise visual e outros casos de uso de análise avançada. Embora alguns dos métodos descritos anteriormente sejam aplicáveis aqui, alguns métodos adicionais são discutidos.
No teste, começamos com um conjunto de dados SAS (no formato sas7bdat) no servidor SAS e, no final, temos esse conjunto de dados disponível como Spark DataFrame (se a invocação preguiçosa for aplicável, forçamos o carregamento dos dados em um DataFrame e medimos o tempo total) no Databricks.
Usamos o mesmo ambiente e o mesmo conjunto de dados para este cenário que foi usado no cenário anterior. Os testes não consideram o caso de uso em que um usuário SAS grava um conjunto de dados no Delta Lake usando programação SAS. Isso envolve levar em consideração as ferramentas e capacidades do provedor de nuvem, que serão discutidas em um post de blog posterior.
Métodos testados
1. Usando o pacote saspy do SAS
O método sd2df na biblioteca saspy converte um conjunto de dados SAS em um pandas DataFrame, usando SSH para transferência de dados. Ele oferece várias opções de armazenamento de staging (Memória, CSV, DISK) durante a transferência. Em nosso teste, a opção CSV, que usa o arquivo CSV PROC EXPORT e os métodos pandas read_csv(), que é a opção recomendada para grandes conjuntos de dados, mostrou o melhor desempenho.
2. Usando o método pandas
Desde as primeiras versões, o pandas permite que os usuários leiam arquivos sas7bdat usando a API pandas.read_sas. O arquivo SAS deve estar acessível ao programa Python. Métodos comumente usados são FTP, HTTP ou mover para armazenamento de objetos na nuvem, como S3. Usamos uma abordagem mais simples para mover um arquivo SAS do servidor SAS remoto para o cluster Databricks usando SCP.
3. Usando spark-sas7bdat
Spark-sas7bdat é um pacote de código aberto desenvolvido especificamente para Apache Spark. Semelhante ao método pandas.read_sas(), o arquivo SAS deve estar disponível no sistema de arquivos. Baixamos o arquivo sas7bdat de um servidor SAS remoto usando SCP.
4. Usando uma integração desenvolvida para fins específicos
Outro método explorado é o uso de técnicas convencionais com foco no equilíbrio entre conveniência e desempenho. Este método abstrai integrações principais e é disponibilizado ao usuário como uma biblioteca Python que é executada a partir do Notebook Databricks.
- Use o pacote saspy para executar um código de macro SAS (em um servidor SAS) que faz o seguinte:
- Exportar sas7bdat para arquivo CSV usando código SAS
- Compactar o arquivo CSV para GZIP
- Mover o arquivo compactado para o nó driver do cluster Databricks usando SCP
- Descompactar o arquivo CSV
- Ler o arquivo CSV para o DataFrame Apache Spark
Resultados do teste
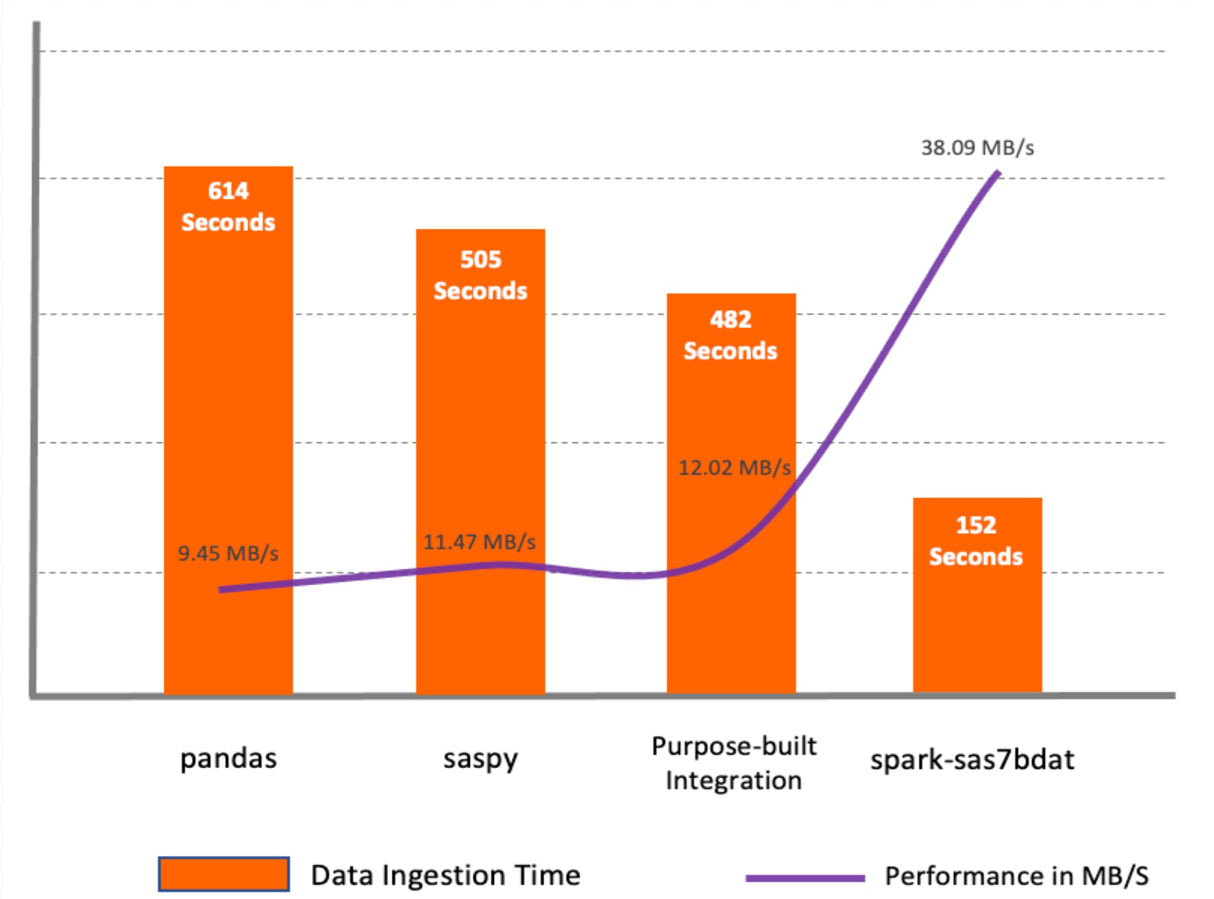
O spark-sas7bdat apresentou o melhor desempenho entre todos os métodos. Este pacote aproveita ao máximo o processamento paralelo no Apache Spark. Ele distribui blocos de arquivos sas7bdat em nós de trabalho. A principal desvantagem deste método é que sas7bdat é um formato binário proprietário, e a biblioteca foi construída com base na engenharia reversa deste formato binário, portanto, não suporta todos os tipos de arquivos sas7bdat, além de não ter suporte oficial (comercial) do fornecedor.
Os métodos saspy e pandas são semelhantes no sentido de que ambos são construídos para um ambiente de nó único e ambos leem dados para um pandas DataFrame, exigindo uma etapa adicional antes que os dados estejam disponíveis como um Spark DataFrame.
A macro integração desenvolvida para fins específicos apresentou melhor desempenho em comparação com saspy e pandas porque lê dados de CSV através das APIs do Apache Spark. No entanto, não supera o desempenho do pacote spark-sas7bdat. O método desenvolvido para fins específicos pode ser conveniente em alguns casos, pois permite adicionar transformações de dados intermediárias no servidor SAS.
Conclusão
Cada vez mais empresas estão migrando para a construção de um Databricks Lakehouse e existem várias maneiras de acessar dados do Lakehouse por meio de outras tecnologias. Este blog discute como desenvolvedores SAS, cientistas de dados e outros usuários de negócios podem aproveitar os dados no Lakehouse e gravar os resultados na nuvem. Em nosso experimento, testamos vários métodos diferentes de leitura e gravação de dados entre Databricks e SAS. Os métodos variam não apenas em desempenho, mas também em conveniência e recursos adicionais que fornecem.
Para este teste, usamos a plataforma SAS 9.4M7. O SAS Viya suporta a maioria das abordagens discutidas, mas também oferece opções adicionais. Se você quiser saber mais sobre os métodos ou outras abordagens de integração especializadas não abordadas aqui, sinta-se à vontade para entrar em contato conosco em Databricks ou databricks@t1a.com.
Nas próximas postagens desta série de blogs, discutiremos as melhores práticas na implementação de pipelines de dados integrados, fluxos de trabalho de ponta a ponta, usando SAS e Databricks e como aproveitar as tecnologias In-Database da SAS para pontuação de modelos SAS em clusters Databricks.
SAS® e todos os outros nomes de produtos ou serviços da SAS Institute Inc. são marcas registradas ou marcas comerciais da SAS Institute Inc. nos EUA e em outros países. ® indica registro nos EUA.
Comece
Experimente o curso Databricks para Usuários SAS, na Databricks Academy, para obter uma experiência prática básica com programação PySpark para construções de linguagem de programação SAS e entre em contato conosco para saber mais sobre como podemos ajudar sua equipe SAS a migrar suas cargas de trabalho de ETL para o Databricks e habilitar as melhores práticas.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.