How to Speed Up Data Flow Between Databricks and SAS
by Oleg Mikhov and Satish Garla
This is a collaborative post between Databricks and T1A. We thank Oleg Mikhov, Solutions Architect at T1A, for his contributions.
This is the first post in a series of blogs on the best practices of bringing together Databricks Lakehouse Platform and SAS. A previous Databricks blog post introduced Databricks and PySpark to SAS developers. In this post, we discuss ways for exchanging data between SAS and Databricks Lakehouse Platform and ways to speed up the data flow. In future posts, we will explore building efficient data and analytics pipelines involving both technologies.
Data-driven organizations are rapidly adopting the Lakehouse platform to keep up with the constantly growing business demands. Lakehouse platform has become a new norm for organizations wanting to build data platforms and architecture. The modernization entails moving data, applications, or other business elements to the cloud. However, the transition to the cloud is a gradual process and it is business-critical to continue leveraging legacy investments for as long as possible. With that in mind, many companies tend to have multiple data and analytics platforms, where the platforms coexist and complement each other.
One of the combinations we see is the use of SAS with the Databricks Lakehouse. There are many benefits of enabling the two platforms to efficiently work together, such as:
- Greater and scalable data storage capabilities of cloud platforms
- Greater computing capacity using technologies, such as Apache Spark™, natively built with parallel processing capabilities
- Achieve greater compliance with data governance and management using Delta Lake
- Lower the cost of data analytics infrastructure with simplified architectures
Some common data science and data analysis use cases and reasons observed are:
- SAS practitioners leverage SAS for its core statistical packages to develop advanced analytics output that meets regulatory requirements while they use Databricks Lakehouse for data management, ELT types of processing, and data governance
- Machine learning models developed in SAS are scored on massive amounts of data using parallel processing architecture of Apache Spark engine in the Lakehouse platform
- SAS data analysts gain faster access to large amounts of data in the Lakehouse Platform for ad-hoc analysis and reporting using Databricks SQL endpoints and high bandwidth connectors
- Ease cloud modernization and migration journey by establishing a hybrid workstream involving both cloud architecture and on-prem SAS platform
However, a key challenge of this coexistence is how the data is performantly shared between the two platforms. In this blog, we share best practices implemented by T1A for their customers and benchmark results comparing different methods of moving data between Databricks and SAS.
Scenarios
The most popular use case is a SAS developer trying to access data in the lakehouse. The analytics pipelines involving both technologies require data flow in both directions: data moved from Databricks to SAS and data moved from SAS to Databricks.
- Access Delta Lake from SAS: A SAS user wants to access big data in Delta Lake using the SAS programming language.
- Access SAS datasets from Databricks: A Databricks user wants to access SAS datasets, generally the sas7bdat datasets as a DataFrame to process in Databricks pipelines or store in Delta Lake for enterprise-wide access.
In our benchmark tests, we used the following environment setup:
- Microsoft Azure as the cloud platform
- SAS 9.4M7 on Azure (single node Standard D8s v3 VM)
- Databricks runtime 9.0, Apache Spark 3.1.2 (2 nodes Standard DS4v2 cluster)
Figure 1 shows the conceptual architecture diagram with the components discussed. Databricks Lakehouse sits on Azure Data Lake storage with Delta Lake medallion architecture. SAS 9.4 installed on Azure VM connects to Databricks Lakehouse to read/write data using connection options discussed in the following sections.
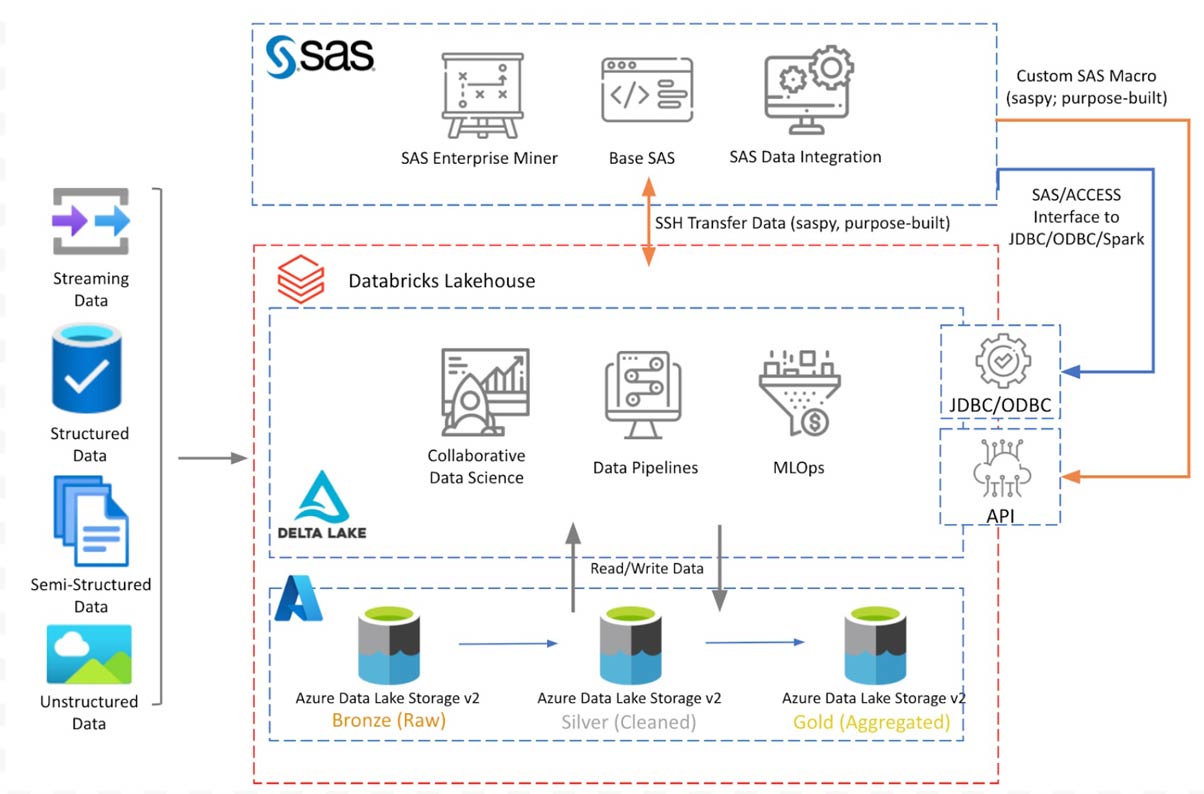
The diagram above shows a conceptual architecture of Databricks deployed on Azure. The architecture will be similar on other cloud platforms. In this blog, we only discuss the integration with the SAS 9.4 platform. In a later blog post, we will extend this discussion to access lakehouse data from SAS Viya.
Access Delta Lake from SAS
Imagine that we have a Delta Lake table that needs to be processed in a SAS program. We want the best performance when accessing this table, while also avoiding any possible issues with data integrity or data types compatibility. There are different ways to achieve data integrity and compatibility. Below we discuss a few methods and compare them on ease of use and performance.
In our testing, we used the eCommerce behavior dataset (5.67GB, 9 columns, ~ 42 mill records) from Kaggle.
Data Source Credit: eCommerce behavior data from multi category store and REES46 Marketing Platform.
Tested methods
1. Using SAS/ACCESS Interface connectors
Traditionally, SAS users leverage SAS/ACCESS software to connect to external data sources. You can either use a SAS LIBNAME statement pointing to the Databricks cluster or use the SQL pass-through facility. At present for SAS 9.4, there are three connection options available.
SAS/ACCESS Interface to Spark has been recently loaded with capabilities with exclusive support to Databricks clusters. See this video for a short demonstration. The video mentions SAS Viya but the same is applicable to SAS 9.4.
Code samples on how to use these connectors can be found in this git repository: T1A Git - SAS Libraries Examples.
2. Using saspy package
The open-source library, saspy, from SAS Institute allows Databricks Notebook users to run SAS statements from a Python cell in the notebook to execute code in the SAS server, as well as to import and export data from SAS datasets to Pandas DataFrame.
Since the focus of this section is accessing lakehouse data by a SAS programmer using SAS programming, this method was wrapped in a SAS macro program similar to the purpose-built integration method discussed next.
To achieve better performance with this package, we tested the configuration with a defined char_length option (details available here). With this option, we can define lengths for character fields in the dataset. In our tests using this option brought an additional 15% increase in performance. For the transport layer between environments, we used the saspy configuration with an SSH connection to the SAS server.
3. Using a purpose-built integration
Although the two methods mentioned above have their upsides, the performance can be improved further by addressing some shortcomings, discussed in the next section (Test Results), of the previous methods. With that in mind, we developed a SAS macro-based integration utility with a prime focus on performance and usability for SAS users. The SAS macro can be easily integrated into existing SAS code without any knowledge about Databricks platform, Apache Spark or Python.
The macro orchestrates a multistep process using Databricks API:
- Instruct the Databricks cluster to query and extract data per the provided SQL query and cache the results in DBFS, relying on its Spark SQL distributed processing capabilities.
- Compress and securely transfer the dataset to the SAS server (CSV in GZIP) over SSH
- Unpack and import data into SAS to make it available to the user in the SAS library. At this step, leverage column metadata from Databricks data catalog (column types, lengths, and formats) for consistent, correct and efficient data presentation in SAS
Note that for variable-length data types, the integration supports different configuration options, depending on what best fits the user requirements such as,
- need for using a configurable default value
- profiling to 10,000 rows (+ add headroom) to identify the largest value
- profiling the entire column in the dataset to identify the largest value
A simplified version of the code is available here T1A Git - SAS DBR Custom Integration.
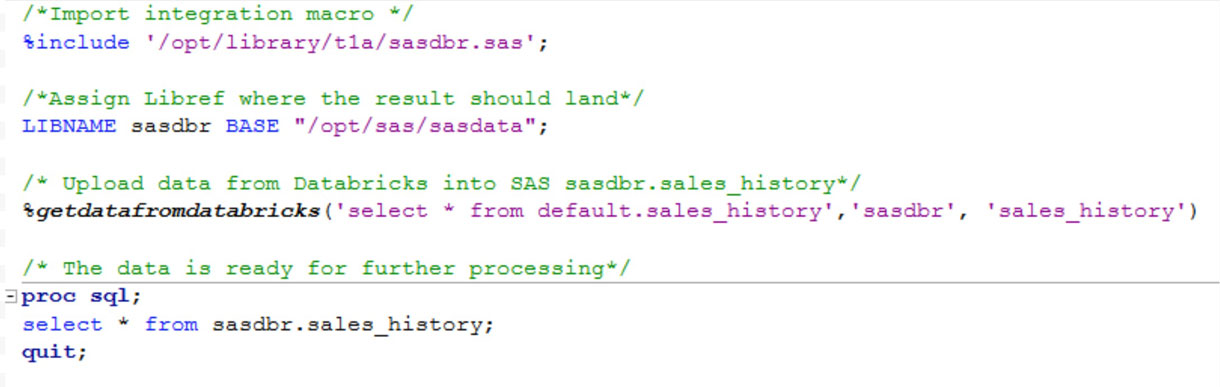
The end-user usage of this SAS macro looks as shown below, and takes three inputs:
- SQL query, based on which data will be extracted from Databricks
- SAS libref where the data should land
- Name to be given to the SAS dataset
Test results
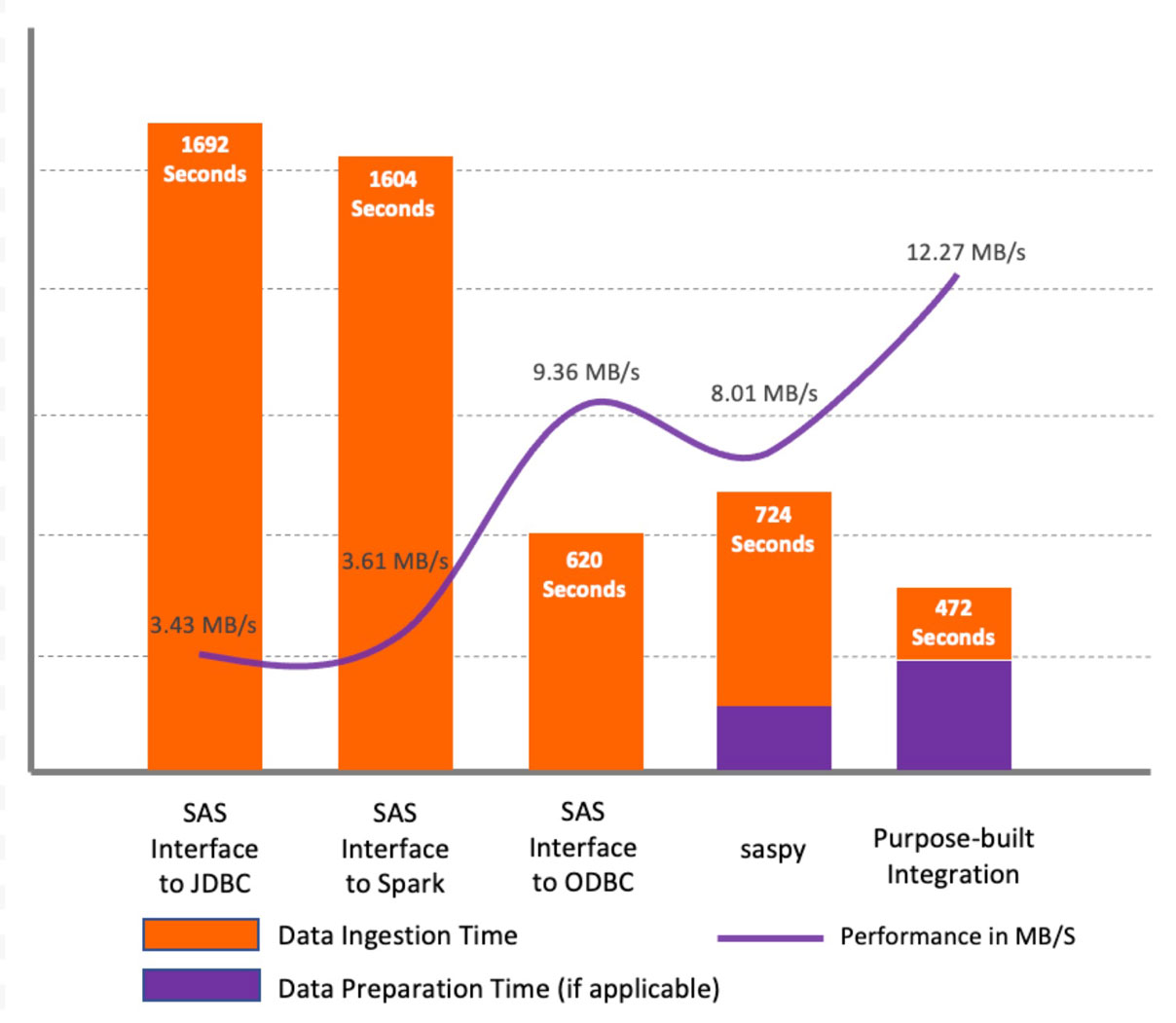
As shown in the plot above, for the test dataset, the results show that SAS/ACCESS Interface to JDBC and SAS/ACCESS Interface to Apache Spark showed similar performance and performed lower compared to other methods. The main reason for that is the JDBC methods do not profile character columns in datasets in order to set proper column length in the SAS dataset. Instead, they define the default length for all character column types (String and Varchar) as 765 symbols. That causes not only performance issues during initial data retrieval but for all further processing. Plus it consumes significant additional storage. In our tests, for the source dataset of 5.6 GB, we ended with a 216 GB file in the WORK library. However, with the SAS/ACCESS Interface to ODBC, the default length was 255 symbols, which resulted in a significant performance increase.
Using SAS/ACCESS Interface methods is the most convenient option for existing SAS users. There are some important considerations when you use these methods
- Both solutions support implicit query pass-through but with some limitations:
- SAS/ACCESS Interface to JDBC/ODBC support only pass-through for PROC SQL statements
- In addition to PROC SQL pass-through SAS/ACCESS Interface to Apache Spark supports pass-through for most of the SQL functions. This method also allows pushing common SAS procedures to Databricks clusters.
- The issue with setting the length for the character columns described before. As a workaround, we suggest using the DBSASTYPE option to explicitly set column length for SAS tables. This will help with further processing of the dataset but won’t affect the initial retrieval of the data from Databricks
- SAS/ACCESS Interface to Apache Spark/JDBC/ODBC does not allow combining tables from different Databricks databases (schemas) assigned as different libnames in the same query (joining them) with the pass-through facility. Instead, it will cause exporting entire tables in SAS and processing in SAS. As a workaround, we suggest creating a dedicated schema in Databricks that will contain views based on tables from different databases (schemas).
Using the saspy method showed slightly better performance compared to SAS/ACCESS Interface to JDBC/Spark methods, however, the main drawback is that saspy library only works with pandas DataFrames and it puts a significant load on the Apache Spark driver program and requires the entire DataFrame to be pulled into memory.
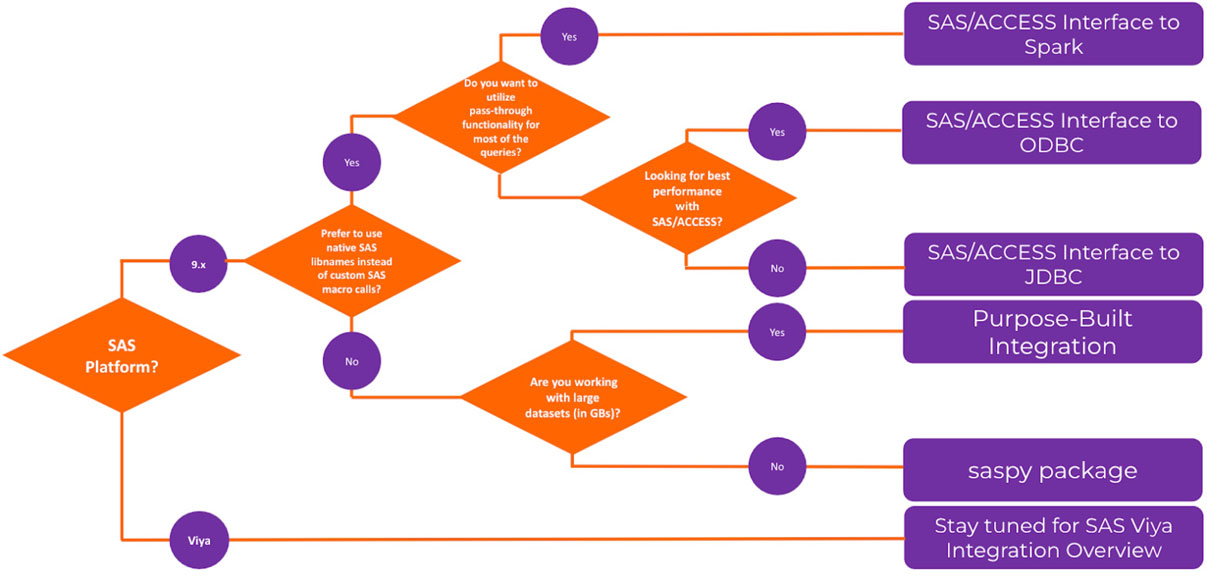
The purpose-built integration method showed the best performance compared to other tested methods. Figure 3 shows a flow chart with high-level guidance in choosing from the methods discussed.
Access SAS datasets from Databricks
This section addresses the need by Databricks developers to ingest a SAS dataset into Delta Lake and make it available in Databricks for business intelligence, visual analytics, and other advanced analytics use cases while some of the previously described methods are applicable here, some additional methods are discussed.
In the test, we start with a SAS dataset (in sas7bdat format) on the SAS server, and in the end, we have this dataset available as Spark DataFrame (if the lazy invocation is applicable we force to load data in a DataFrame and measure the overall time) in Databricks.
We used the same environment and the same dataset for this scenario that was used in the previous scenario. The tests do not consider the use case where a SAS user writes a dataset into Delta Lake using SAS programming. This involves taking into consideration cloud provider tools and capabilities which will be discussed in a later blog post.
Tested methods
1. Using the saspy package from SAS
The sd2df method in the saspy library converts a SAS dataset to a pandas DataFrame, using SSH for data transfer. It offers several options for staging storage (Memory, CSV, DISK) during the transfer. In our test, the CSV option, which uses PROC EXPORT csv file and pandas read_csv() methods, which is the recommended option for large data sets, showed the best performance.
2. Using pandas method
Since early releases pandas allowed users to read sas7bdat files using pandas.read_sas API. The SAS file should be accessible to the python program. Commonly used methods are FTP, HTTP, or moving to cloud object storage such as S3. We rather used a simpler approach to move a SAS file from the remote SAS server to the Databricks cluster using SCP.
3. Using spark-sas7bdat
Spark-sas7bdat is an open-source package developed specifically for Apache Spark. Similar to the pandas.read_sas() method, the SAS file must be available on the filesystem. We downloaded the sas7bdat file from a remote SAS Server using SCP.
4. Using a purpose-built integration
Another method that was explored is using conventional techniques with a focus on balancing convenience and performance. This method abstracts away core integrations and is made available to the user as a Python library which is executed from the Databricks Notebook.
- Use saspy package to execute a SAS macro code (on a SAS server) which does the following
- Export sas7bdat to CSV file using SAS code
- Compress the CSV file to GZIP
- Move the compressed file to the Databricks cluster driver node using SCP
- Decompresses the CSV file
- Reads CSV file to Apache Spark DataFrame
Test results
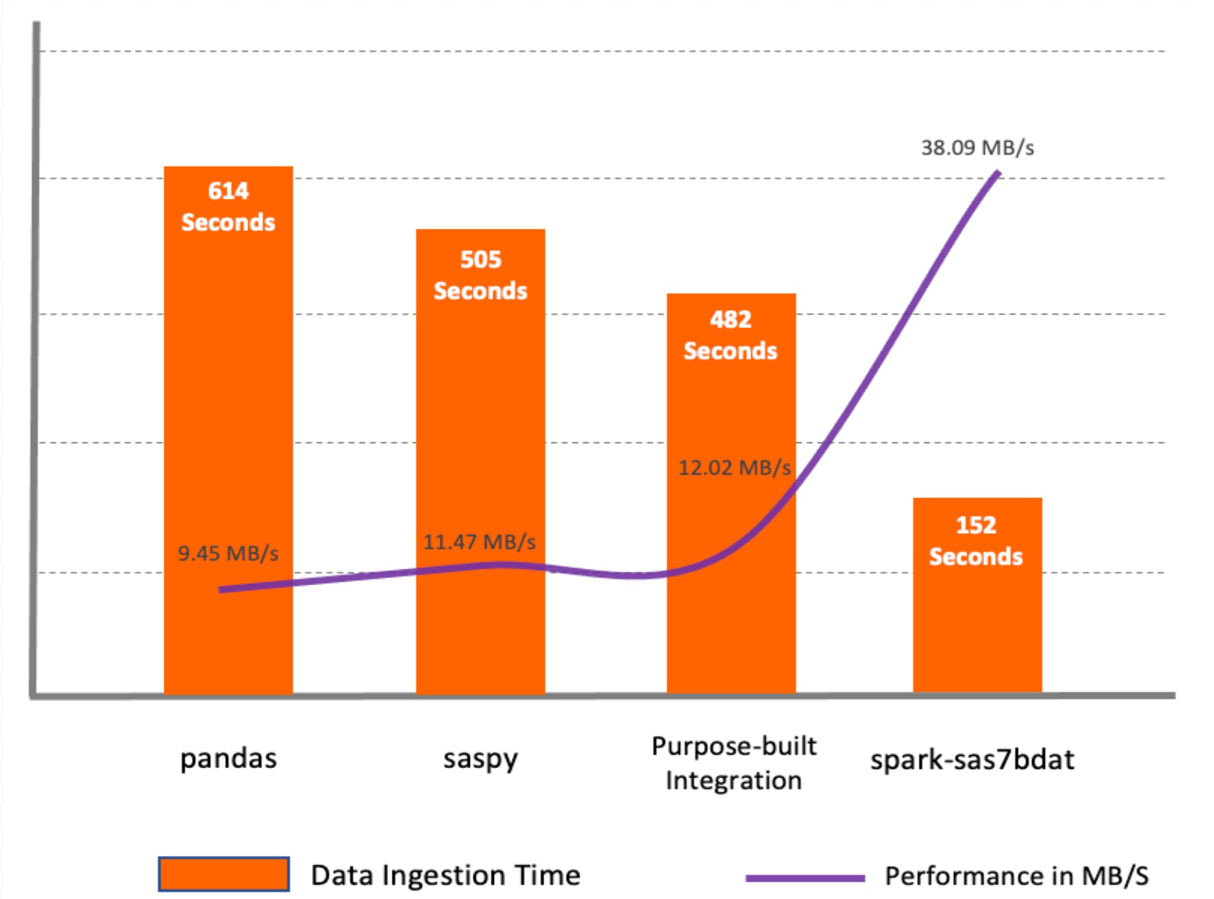
The spark-sas7bdat showed the best performance among all the methods. This package takes full advantage of parallel processing in Apache Spark. It distributes blocks of sas7bdat files on worker nodes. The major drawback of this method is that sas7bdat is a proprietary binary format, and the library was built based on reverse engineering of this binary format, so it doesn’t support all types of sas7bdat files, as well as it isn’t officially (commercially) vendor-supported.
The saspy and pandas methods are similar in the way that they are both built for a single node environment and both read data to pandas DataFrame requiring an additional step before having the data available as a Spark DataFrame.
The purpose-built integration macro showed better performance compared to saspy and pandas because it reads data from CSV through Apache Spark APIs. However, it doesn’t beat the performance of the spark-sas7bdat package. The purpose-built method can be convenient in some cases as it allows adding intermediate data transformations on the SAS server.
Conclusion
More and more enterprises are gravitating towards building a Databricks Lakehouse and there are multiple ways of accessing data from the Lakehouse via other technologies. This blog discusses how SAS developers, data scientists and other business users can leverage the data in the Lakehouse and write the results to the cloud. In our experiment, we tested several different methods of reading and writing data between Databricks and SAS. The methods vary not only by performance but by convenience and additional capabilities that they provide.
For this test, we used the SAS 9.4M7 platform. SAS Viya supports most of the discussed approaches but also provides additional options. If you’d like to learn more about the methods or other specialized integration approaches not covered here, feel free to reach out to us at Databricks or databricks@t1a.com.
In the upcoming posts in this blog series, we will discuss best practices in implementing integrated data pipelines, end-to-end workflows, using SAS and Databricks and how to leverage SAS In-Database technologies for scoring SAS models in Databricks clusters.
SAS® and all other SAS Institute Inc. product or service names are registered trademarks or trademarks of SAS Institute Inc. in the USA and other countries. ® indicates USA registration.
Get started
Try the course, Databricks for SAS Users, on Databricks Academy to get a basic hands-on experience with PySpark programming for SAS programming language constructs and contact us to learn more about how we can assist your SAS team to onboard their ETL workloads to Databricks and enable best practices.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.