Prêmios SIGMOD do Apache Spark e Photon Receive
por Reynold Xin e Matei Zaharia
Nesta semana, muitos dos engenheiros e pesquisadores mais influentes da comunidade de gestão de dados estão se reunindo presencialmente na Filadélfia para a conferência ACM SIGMOD, após dois anos de encontros virtuais. Como parte do evento, ficamos muito felizes em ver os dois prêmios a seguir:
- O Apache Spark recebeu o prêmio SIGMOD Systems Award
- O Databricks Photon recebeu o prêmio de Melhor Artigo da Indústria
Aproveitamos esta oportunidade para discutir o contexto por trás disso e como chegamos até aqui.
O que é o ACM SIGMOD e quais são os prêmios?
ACM SIGMOD significa Grupo de Interesse Especial em Gerenciamento de Dados da Association of Computing Machinery. Sabemos, é um nome longo. Todo mundo simplesmente chama de SIGMOD. É a conferência de maior prestígio para pesquisadores e engenheiros de banco de dados, pois muitas das ideias mais seminais no campo de bancos de dados, de column stores a otimizações de query, foram publicadas neste evento.
O Prêmio de Sistemas SIGMOD é concedido anualmente a um “sistema cujas contribuições técnicas tiveram impacto significativo na teoria ou prática de sistemas de gestão de dados em grande escala”. Esses sistemas tendem a ter aplicações de grande escala no mundo real, além de terem influenciado a forma como os futuros sistemas de banco de dados são projetados. Os vencedores anteriores incluem Postgres, SQLite, BerkeleyDB e Aurora.
O Prêmio de Melhor Artigo da Indústria é concedido anualmente a um artigo com base na combinação de impacto no mundo real, inovação e qualidade da apresentação.
A origem de dados e IA do Apache Spark
Há cerca de uma década, a Netflix iniciou uma competição chamada Netflix Prize, na qual anonimizaram sua vasta coleção de classificações de filmes de usuários e pediram aos competidores que criassem algoritmos para prever como os usuários classificariam os filmes. O troféu de US$ 1 milhão iria para a equipe com o melhor modelo do machine learning.
Um grupo de estudantes de doutorado da UC Berkeley decidiu competir. O primeiro desafio que eles enfrentaram foi que as ferramentas simplesmente não eram boas o suficiente. Para criar modelos melhores, eles precisavam de uma forma rápida e iterativa de limpar, analisar e processar grandes volumes de dados (que não cabiam no laptop de um estudante) e de um framework expressivo o suficiente para compor algoritmos de ML experimentais.
Os data warehouses, que eram o padrão para dados corporativos, não conseguiam lidar com os dados não estruturados e careciam de expressividade. Eles discutiram este desafio com outro doutorando, Matei Zaharia. Juntos, eles projetaram um novo framework de computação paralela chamado Spark, com uma estrutura de dados distribuída nova e inovadora chamada RDDs. O Spark permitiu que seus usuários executassem operações de dados em paralelo de forma rápida e concisa.
Ou, em outras palavras, é rápido para escrever código e rápido para execução. A rapidez na escrita é importante porque torna o programa mais compreensível e pode ser usada para compor algoritmos mais complexos com facilidade. A execução rápida significa que os usuários podem obter feedback mais rapidamente e criar seus modelos usando dados em constante crescimento.

Acontece que os estudantes não estavam sozinhos. Estes foram os primórdios das aplicações de dados e IA na indústria, e todos enfrentavam desafios semelhantes. Devido à demanda popular, o projeto foi transferido para a Apache Software Foundation e se tornou uma comunidade enorme.
Hoje, o Spark é o padrão de fato para processamento de dados e continua crescendo:
- Ele recebeu 45 milhões de downloads no mês passado, apenas no PyPI e no Maven Central. Isso representa um crescimento de 90% em downloads em relação ao ano anterior.
- É usado em pelo menos 204 países e regiões.
- Ele está classificado em 1º lugar entre as tecnologias mais bem pagas na pesquisa de desenvolvedores de 2021 do Stack Overflow.
O prêmio SIGMOD Systems Award é uma validação da adoção do projeto, bem como de sua influência sobre as futuras gerações de sistemas para que pensem em dados e IA como um pacote unificado.
Photon: novas cargas de trabalho e Lakehouse
À medida que o Apache Spark se tornou mais popular, descobrimos que as organizações queriam fazer mais do que processamento de dados em larga escala e machine learning com ele: elas queriam executar aplicações tradicionais e interativas de data warehousing nos mesmos datasets que usavam em outras partes de seus negócios, eliminando a necessidade de gerenciar vários sistemas de dados. Isso levou ao conceito de sistemas lakehouse: um único repositório de dados que pode fazer processamento em larga escala e consultas SQL interativas, combinando os benefícios dos sistemas de data warehouse e data lake.
Para dar suporte a esses tipos de casos de uso, desenvolvemos o Photon, um mecanismo de execução vetorizada rápido em C++ para cargas de trabalho Spark e SQL, que é executado por trás das interfaces de programação existentes do Spark. O Photon permite queries interativas muito mais rápidas, bem como muito maior alta simultaneidade do que o Spark, ao mesmo tempo que suporta as mesmas APIs e cargas de trabalho, incluindo aplicações SQL, Python e Java. Vimos ótimos resultados com o Photon em cargas de trabalho de todos os tamanhos, desde estabelecer o recorde mundial no benchmark de data warehouse em larga escala TPC-DS no ano passado até oferecer um desempenho 3x superior em queries pequenas e concorrentes.
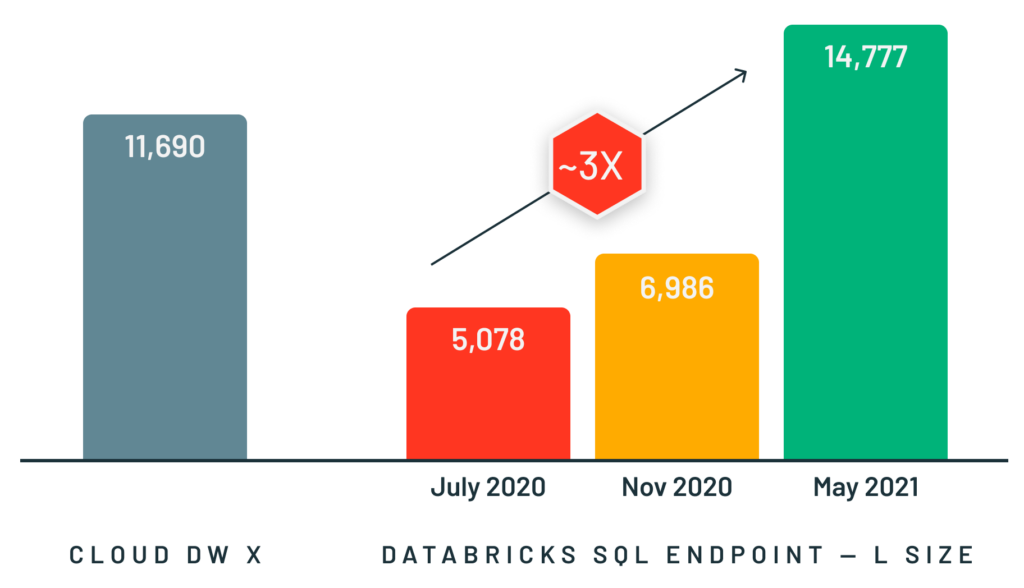
Projetar e implementar o Photon foi desafiador porque precisávamos que o motor mantivesse a expressividade e a flexibilidade do Spark (para suportar a ampla gama de aplicações), nunca fosse mais lento (para evitar regressões de desempenho) e fosse significativamente mais rápido em nossas cargas de trabalho alvo. Além disso, ao contrário de um mecanismo de data warehouse tradicional que pressupõe que todos os dados foram carregados em um formato proprietário, o Photon precisava funcionar no ambiente lakehouse, processando dados em formatos abertos, como Delta Lake e Apache Parquet, com o mínimo de suposições sobre o processo de ingestão (p. ex., disponibilidade de índices ou estatísticas de dados). Nosso artigo da SIGMOD descreve como enfrentamos esses desafios e muitos dos detalhes técnicos da implementação do Photon.
Ficamos entusiasmados ao ver este trabalho ser reconhecido como o Melhor Artigo da Indústria e esperamos que ele dê boas ideias a engenheiros e pesquisadores de banco de dados sobre o que é desafiador neste novo modelo de sistemas lakehouse. É claro que também estamos muito empolgados com o que nossos clientes fizeram com o Photon até agora — o novo engine já representa uma fração significativa da nossa carga de trabalho.
Se você estiver participando do SIGMOD, passe no estande da Databricks e diga olá. Adoraríamos conversar com você sobre o futuro dos sistemas de dados. Em troca, daremos a você uma camiseta “o melhor data warehouse é um lakehouse”!

Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.