Databricks estabelece recorde oficial de desempenho para armazenamento de dados
por Reynold Xin e Mostafa Mokhtar
Hoje, temos o orgulho de anunciar que o Databricks SQL estabeleceu um novo recorde mundial no TPC-DS de 100 TB, o benchmark de desempenho de referência para data warehousing. O Databricks SQL superou o recorde anterior em 2,2 vezes. Diferentemente da maioria das outras notícias sobre benchmarks, este resultado foi formalmente auditado e revisado pelo conselho do TPC.
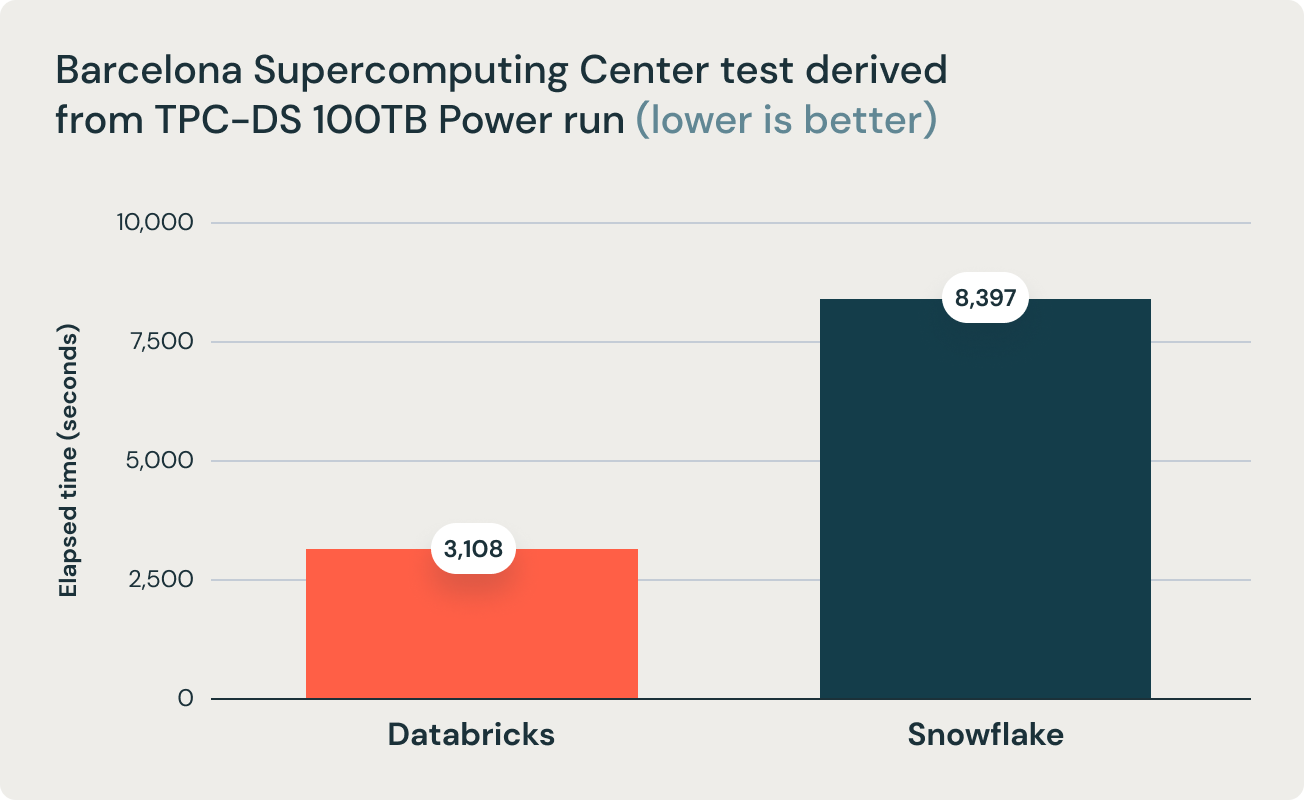
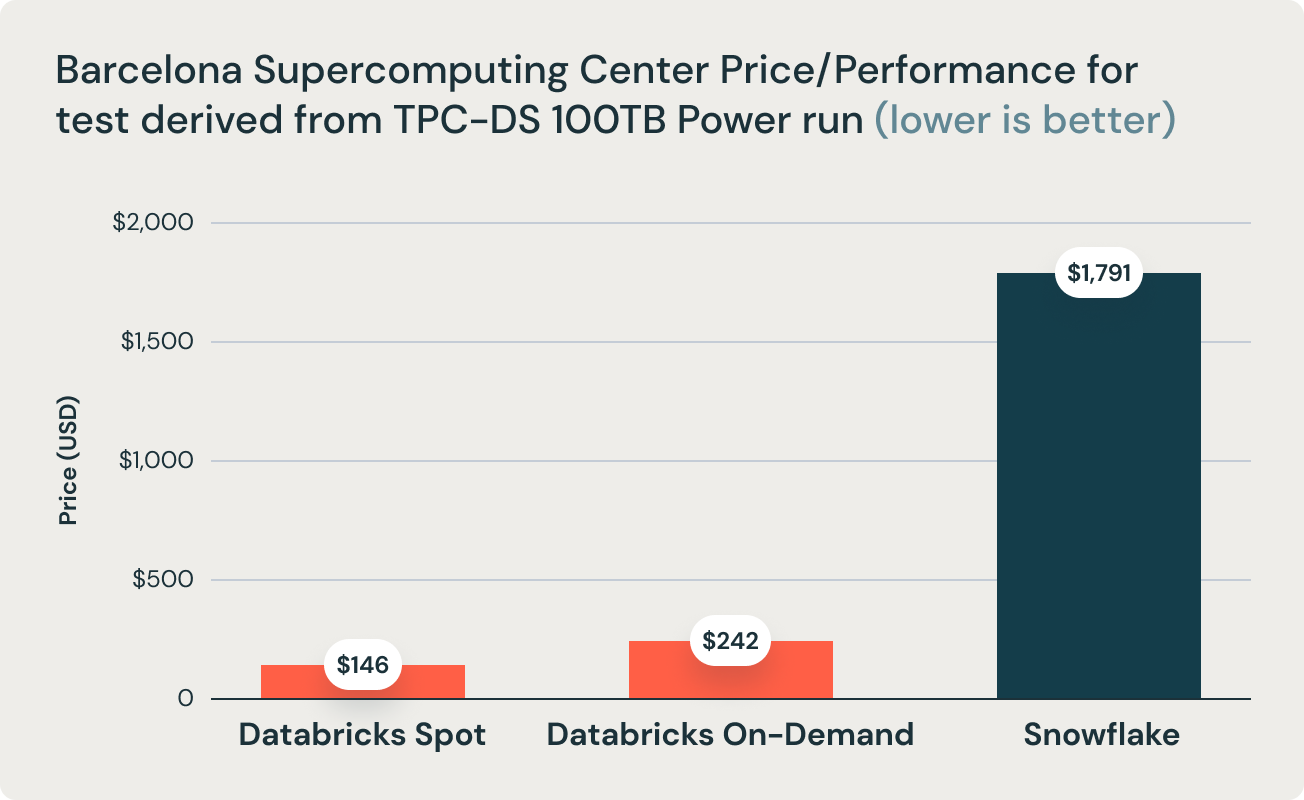
Esses resultados foram corroborados por pesquisas do Barcelona Supercomputing Center, que frequentemente executa benchmarks derivados do TPC-DS em data warehouses populares. A pesquisa mais recente deles fez o benchmark do Databricks e do Snowflake e descobriu que o Databricks foi 2,7x mais rápido e 12x melhor em termos de desempenho de preço. Este resultado validou a tese de que data warehouses como o Snowflake se tornam proibitivamente caros à medida que o tamanho dos dados aumenta em produção.
O Databricks tem desenvolvido rapidamente capacidades completas de data warehousing diretamente em data lakes, trazendo o melhor dos dois mundos em uma única arquitetura de dados apelidada de data lakehouse. Anunciamos nosso conjunto completo de capacidades de data warehousing como Databricks SQL em novembro de 2020. A questão em aberto desde então tem sido se uma arquitetura aberta baseada em um lakehouse pode oferecer o desempenho, a velocidade e o custo dos data warehouses clássicos. Este resultado prova, sem sombra de dúvida, que isso é possível e alcançável pela arquitetura lakehouse.
Em vez de apenas compartilhar os resultados, gostaríamos de aproveitar esta oportunidade para compartilhar com vocês a história de como alcançamos este nível de desempenho e o esforço que foi dedicado a isso. Mas vamos começar com os resultados:
Recorde mundial do TPC-DS
O Databricks SQL entregou 32.941.245 QphDS @ 100TB. Isso supera em 2,2x o recorde mundial anterior, mantido pelo sistema personalizado da Alibaba, que alcançou 14,861,137 QphDS @ 100TB. (A Alibaba tinha um sistema impressionante que dava suporte à maior plataforma de e-commerce do mundo). O Databricks SQL não só superou significativamente o recorde anterior, como o fez reduzindo o custo total do sistema em 10% (com base nos preços de tabela publicados, sem descontos).
É perfeitamente normal se você não souber o que a unidade QphDS significa. (Nós também não, sem olhar a fórmula.) O QphDS é a principal métrica do TPC-DS, que representa o desempenho de uma combinação de workloads, incluindo (1) carregamento do conjunto de dados, (2) processamento de uma sequência de queries (teste de potência), (3) processamento de vários transmissões de query concorrentes (teste de throughput) e (4) execução de funções de manutenção de dados que inserem e excluem dados.
A conclusão mencionada é corroborada pela equipe de pesquisa do Barcelona Supercomputing Center (BSC), que recentemente executou um benchmark diferente derivado do TPC-DS comparando Databricks SQL e Snowflake e descobriu que o Databricks SQL era 2,7x mais rápido do que uma configuração de tamanho semelhante do Snowflake.
O que é o TPC-DS?
O TPC-DS é um benchmark de data warehousing definido pelo Transaction Processing Performance Council (TPC). O TPC é uma organização sem fins lucrativos iniciada pela comunidade de bancos de dados no final dos anos 80, com foco na criação de benchmarks que emulam cenários do mundo real e, como resultado, podem ser usados objetivamente para medir o desempenho de sistemas de banco de dados. O TPC teve um impacto profundo no campo de bancos de dados, com "guerras de benchmarking" de uma década entre fornecedores estabelecidos como Oracle, Microsoft e IBM, que impulsionaram o campo.
O "DS" em TPC-DS significa "suporte à decisão". Ele inclui 99 queries de complexidade variável, desde agregações muito simples até mineração de padrões complexos. É um benchmark relativamente novo (o trabalho começou em meados dos anos 2000) para refletir a complexidade crescente da analítica. Na última década, aproximadamente, o TPC-DS se tornou o benchmark padrão de fato para data warehousing, adotado por praticamente todos os fornecedores.
No entanto, devido à sua complexidade, muitos sistemas de data warehouse, mesmo os criados pelos fornecedores mais estabelecidos, modificaram o benchmark oficial para que seus próprios sistemas tivessem um bom desempenho. (Alguns ajustes comuns incluem a remoção de certos recursos SQL, como rollups, ou a alteração da distribuição de dados para remover a assimetria). Este é um dos motivos pelos quais houve pouquíssimas submissões ao benchmark oficial TPC-DS, apesar de haver mais de 4 milhões de páginas na Internet sobre o TPC-DS. Os ajustes também aparentemente explicam por que a maioria dos fornecedores parece superar todos os outros fornecedores de acordo com seus próprios benchmarks.
Como fizemos isso?
Como mencionado anteriormente, havia questões em aberto sobre se era possível para o Databricks SQL superar os data warehouses em desempenho de SQL. A maioria dos desafios pode ser resumida nas quatro questões a seguir:
- Os data warehouses aproveitam formatos de dados proprietários e, como resultado, podem evoluí-los rapidamente, enquanto o Databricks (baseado no lakehouse) depende de formatos abertos (como Apache Parquet e Delta Lake) que não mudam tão rapidamente. Como resultado, os EDWs teriam uma vantagem inerente.
- Um excelente desempenho de SQL requer a arquitetura MPP (processamento massivamente paralelo), e o Databricks e o Apache Spark não eram MPP.
- A clássica compensação entre throughput e latência implica que um sistema pode ser ótimo para queries grandes (com foco em throughput) ou para queries pequenas (com foco em latência), mas não para ambos. Como o Databricks focava em queries grandes, tínhamos um desempenho ruim para queries pequenas.
- Mesmo que seja possível, o senso comum é que levaria uma década ou mais para construir um sistema de data warehouse. Não há como o progresso ser feito tão rapidamente.
No restante desta postagem no blog, vamos discuti-las uma por uma.
Formatos de dados proprietários vs. abertos
Um dos princípios fundamentais da arquitetura Lakehouse é o formato de armazenamento aberto. "Aberto" não apenas evita a dependência de fornecedor, mas também possibilita o desenvolvimento de um ecossistema de ferramentas independente do fornecedor. Um dos maiores benefícios dos formatos abertos é a padronização. Como resultado dessa padronização, a maioria dos dados corporativos está em data lakes abertos, e o Apache Parquet se tornou o padrão de fato para o armazenamento de dados. Ao trazer um desempenho de nível de data warehouse para formatos abertos, esperamos minimizar a movimentação de dados e simplificar a arquitetura de dados para cargas de trabalho de BI e IA.
Um ataque óbvio contra o "aberto" é que os formatos abertos são difíceis de mudar e, como resultado, difíceis de melhorar. Embora, na teoria, esse argumento faça sentido, na prática, ele não é preciso.
Primeiro, é definitivamente possível que os formatos abertos evoluam. O Parquet, o formato aberto mais popular para armazenamento de grandes volumes de dados, passou por várias iterações de melhorias. Uma das principais motivações para introduzirmos o Delta Lake foi adicionar recursos que eram difíceis de implementar na camada Parquet. O Delta Lake trouxe indexação e estatísticas adicionais para o Parquet.
Segundo, o sistema Databricks transcodifica automaticamente os dados brutos do Delta Lake e do Parquet para um formato mais eficiente ao carregar dados de armazenamentos de objetos para SSDs NVMe locais (sem intervenção do usuário). Isso permite mais oportunidades de otimização.
Dito isso, para a maioria das cargas de trabalho de data warehousing, o Delta Lake e o Parquet já fornecem otimizações suficientes em comparação com os formatos proprietários usados por data warehouses. Para essas cargas de trabalho, as oportunidades de otimização vêm principalmente da capacidade de processar as consultas mais rapidamente, em vez de escanear mais dados mais rapidamente. Na verdade, para o TPC-DS, consultar dados em cache em um formato interno mais otimizado é apenas 10% mais rápido do que consultar dados frios no S3 (descobrimos que isso é verdade tanto para os data warehouses que usamos como referência quanto para o Databricks).
Arquitetura MPP
Um equívoco comum é que os data warehouses empregam a arquitetura MPP, que é ótima para o desempenho de SQL, enquanto o Databricks não. A arquitetura MPP refere-se à capacidade de aproveitar vários nós para processar uma única query. É exatamente assim que o Databricks SQL é arquitetado. Ele não se baseia no Apache Spark, mas sim no Photon, uma reescrita completa de um mecanismo, construído do zero em C++, para hardware SIMD moderno e que faz processamento pesado de consultas paralelas. O Photon é, portanto, um mecanismo MPP.
Trade-off de throughput vs. latência
Throughput vs. latência é o trade-off clássico em sistemas de computador, o que significa que um sistema não pode obter alto throughput e baixa latência simultaneamente. Se um projeto favorece o throughput (por exemplo, agrupando dados em lote), ele teria que sacrificar a latência. No contexto de sistemas de dados, isso significa que um sistema não pode processar queries grandes e pequenas de forma eficiente ao mesmo tempo.
Não negamos que essa troca exista. Na verdade, frequentemente discutimos isso em nossos documentos de design técnico. No entanto, os sistemas de ponta atuais, incluindo o nosso e todos os warehouses populares, estão longe da fronteira ideal tanto em termos de throughput quanto de latência.
Consequentemente, é totalmente possível criar um novo design e implementação que melhore simultaneamente tanto sua throughput quanto sua latência. Foi exatamente assim que construímos quase todas as nossas key tecnologias facilitadoras nos últimos dois anos: Photon, Delta Lake e muitas outras tecnologias de ponta melhoraram o desempenho de queries grandes e pequenas, elevando o patamar para um novo recorde de desempenho.
Tempo e foco
Finalmente, o senso comum é que levaria pelo menos uma década para um sistema de banco de dados amadurecer. Dado o foco recente do Databricks no Lakehouse (para suportar cargas de trabalho SQL), seria necessário um esforço adicional para que o SQL tivesse um bom desempenho. Isso é válido, mas deixe-nos explicar como fizemos isso muito mais rápido do que se poderia esperar.
Em primeiro lugar, este investimento não começou há apenas um ou dois anos. Desde a criação da Databricks, temos investido em várias tecnologias fundamentais para dar suporte a workloads de SQL que também beneficiariam workloads de IA na Databricks. Isso inclui um otimizador de query completo baseado em custo, um mecanismo de execução vetorizado nativo e vários recursos, como funções de janela. A grande maioria dos workloads na Databricks é executada por meio delas, graças à API DataFrame do Spark, que mapeia para seu mecanismo de SQL, e por isso esses componentes tiveram anos de testes e otimização. O que não fizemos tanto foi enfatizar os workloads de SQL. A mudança de posicionamento em direção ao Lakehouse é recente, impulsionada pelo desejo de nossos clientes de simplificar suas arquiteturas de dados.
Em segundo lugar, o modelo SaaS acelerou os ciclos de desenvolvimento de software. No passado, a maioria dos fornecedores tinha ciclos de lançamento anuais e, depois, outro ciclo de vários anos para que os clientes instalassem e adotassem o software. Em SaaS, nossa equipe de engenharia pode criar um novo design, implementá-lo e lançá-lo para um subconjunto de clientes em questão de dias. Esse ciclo de desenvolvimento mais curto permitiu que as equipes recebessem feedback rapidamente e inovassem com mais rapidez.
Em terceiro lugar, o Databricks poderia trazer um foco significativamente maior para este problema, tanto em termos de capacidade de liderança quanto de capital. As tentativas anteriores de construir um novo sistema de data warehouse foram feitas por Startups ou por uma nova equipe dentro de uma grande empresa. Nunca houve uma startup de banco de dados tão bem financiada quanto a Databricks (mais de US$ 3,5 bilhões arrecadados) para atrair o talento necessário para construir isso. Um novo esforço dentro de uma grande empresa seria apenas mais um esforço e não teria a atenção total da liderança.
Tínhamos uma situação única aqui: inicialmente, nos concentramos em estabelecer nosso negócio não em data warehousing, mas em campos relacionados (ciência de dados e IA) que compartilhavam muitos dos problemas tecnológicos comuns. Esse sucesso inicial nos permitiu financiar a formação da equipe de SQL mais agressiva da história; em um curto período, montamos uma equipe com ampla experiência em data warehouse, um feito que levaria cerca de uma década para muitas outras empresas. Entre eles estão engenheiros e projetistas principais de alguns dos sistemas de dados de maior sucesso, incluindo Amazon Redshift; BigQuery do Google, F1 (sistema de data warehouse interno do Google) e Procella (sistema de data warehouse interno do YouTube); Oracle; IBM DB2; e Microsoft SQL Server.
Em resumo, leva vários anos para desenvolver um ótimo desempenho de SQL. Não apenas aceleramos esse processo aproveitando nossas circunstâncias únicas, mas também o começamos anos atrás, embora não tenhamos feito alarde sobre o plano.
Cargas de trabalho reais de clientes
Estamos animados em ver esses resultados de benchmark validados por nossos clientes. Mais de 5.000 organizações globais vêm utilizando a Databricks Lakehouse Platform para resolver alguns dos problemas mais difíceis do mundo. Por exemplo:
- A Bread Finance é uma plataforma de pagamentos orientada por tecnología com casos de uso de big data, como relatórios financeiros, detecção de fraudes, risco de crédito, estimativa de perdas e um mecanismo de recomendação de funnel completo. Na Databricks Lakehouse Platform, eles conseguem passar de trabalhos em lote noturnos para a ingestão quase em tempo real e reduzir o tempo de processamento de dados em 90%. Além disso, a plataforma de dados pode escalar para 140x o volume de dados com apenas 1,5x o custo.
- A shell está usando nossa plataforma lakehouse para permitir que centenas de analistas de dados executem queries rápidas em datasets em escala de petabytes usando ferramentas de BI padrão, o que eles consideram um "divisor de águas".
- A Regeneron está acelerando a identificação de alvos de medicamentos, fornecendo percepções mais rápidas para biólogos computacionais ao reduzir o tempo de execução de queries em todo o seu dataset de 30 minutos para 3 segundos – uma melhoria de 600x.
Resumo
O Databricks SQL, construído sobre a arquitetura Lakehouse, é o data warehouse mais rápido do mercado e oferece o melhor preço/desempenho. Agora você pode obter um ótimo desempenho em todos os seus dados com baixa latência assim que novos dados são ingeridos, sem precisar exportar para um sistema diferente.
Isso é uma prova da visão do Lakehouse de levar o desempenho de data warehousing de classe mundial para os data lakes. É claro que não construímos apenas um data warehouse. A arquitetura Lakehouse oferece a capacidade de cobrir todas as cargas de trabalho de dados, desde o armazenamento de dados até a ciência de dados e o aprendizado de máquina.
Mas ainda não terminamos. Reunimos a melhor equipe do mercado, e eles estão trabalhando duro para entregar o próximo avanço em desempenho. Além do desempenho, também estamos trabalhando em uma infinidade de melhorias na facilidade de uso e na governança. Aguarde mais novidades nossas no próximo ano.
O TPC não audita nem valida os resultados de benchmarks derivados do TPC-DS e não considera os resultados de benchmarks derivados comparáveis aos resultados publicados do TPC-DS.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.