Cinco etapas simples para implementar um esquema de estrela na Databricks com Delta Lake
Uma forma atualizada de obter consistentemente o melhor desempenho de bancos de dados de esquema em estrela usados em data warehouses e data marts com o Delta Lake
por Cary Moore, Lucas Bilbro e Brenner Heintz
- Use Tabelas Delta para criar suas tabelas de fatos e dimensões.
- Use o Liquid Clustering para fornecer o melhor tamanho de arquivo.
- Use o Liquid Clustering em suas tabelas de fatos.
Estamos atualizando este blog para mostrar aos desenvolvedores como aproveitar os recursos mais recentes do Databricks e os avanços no Spark.
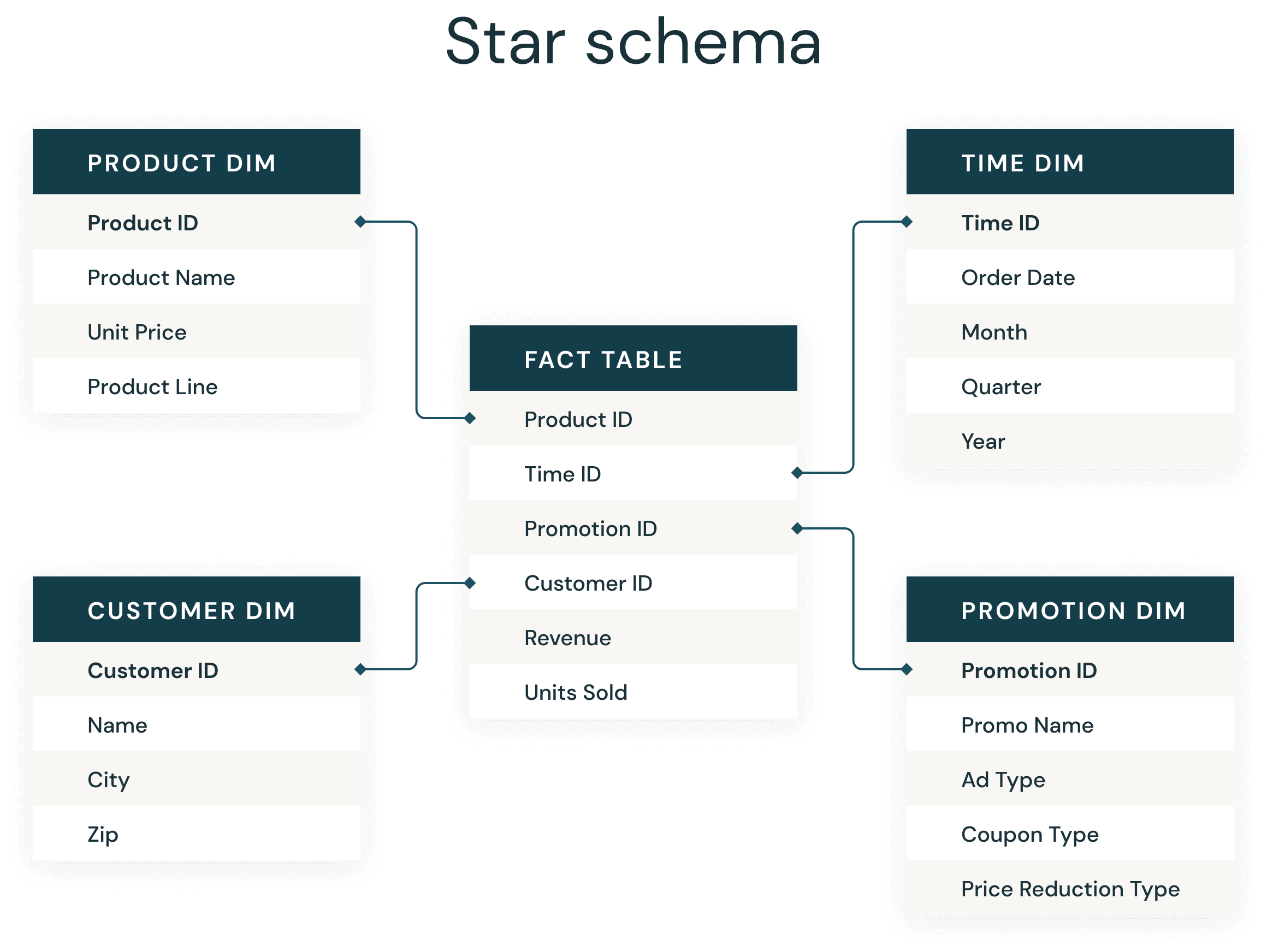
A maioria dos desenvolvedores de data warehouse está muito familiarizada com o sempre presente esquema em estrela. Introduzido por Ralph Kimball na década de 1990, um esquema em estrela é usado para desnormalizar dados de negócios em dimensões (como tempo e produto) e fatos (como transações em valores e quantidades). Um esquema em estrela armazena dados de forma eficiente, mantém o histórico e atualiza os dados, reduzindo a duplicação de definições de negócios repetitivas, o que o torna rápido para agregar e filtrar.
A implementação comum de um esquema estrela para dar suporte a aplicações de Business Intelligence tornou-se tão rotineira e bem-sucedida que muitos modeladores de dados podem praticamente fazê-la de olhos fechados. Na Databricks, produzimos tantas aplicações de dados e estamos constantemente procurando as melhores práticas para servirem como regra geral, uma implementação básica que garanta um excelente resultado.
Assim como em um data warehouse tradicional, existem algumas regras práticas simples a serem seguidas no Delta Lake que melhorarão significativamente seus joins de esquema estrela do Delta.
Aqui estão os passos básicos para o sucesso:
- Use Tabelas Delta para criar suas tabelas de fatos e dimensões
- Use o Liquid Clustering para fornecer o melhor tamanho de arquivo.
- Use o Liquid Clustering em suas tabelas de fatos
- Use o Liquid Clustering nas chaves e nos predicados prováveis da sua maior tabela de dimensão.
- Use a Otimização Preditiva para manter tabelas e coletar estatísticas
1. Use as Delta Tables para criar suas tabelas de fatos e de dimensão
Delta Lake é uma camada de formato de armazenamento aberto que facilita inserções, atualizações e exclusões e adiciona transações ACID às tabelas do seu data lake, simplificando a manutenção e as revisões. O Delta Lake também oferece a capacidade de executar poda dinâmica de arquivos para otimizar e acelerar as queries SQL.
A sintaxe é simples nos Databricks Runtimes 8.x e mais recentes (o runtime de Suporte de Longo Prazo atual é o 15.4), onde o Delta Lake é o formato de tabela padrão. Você pode criar uma tabela Delta usando SQL com o seguinte:
CREATE TABLE MY_TABLE (COLUMN_NAME STRING) CLUSTER BY (COLUMN_NAME);
Antes do runtime 8.x, o Databricks exigia a criação da tabela com a USING DELTA sintaxe.
Antes do runtime 8.x, o Databricks exigia a criação da tabela com a sintaxe USING DELTA.
2. Use o Liquid Clustering para garantir o melhor tamanho de arquivo
Dois dos maiores gargalos de tempo em uma consulta do Apache Spark™ são o tempo gasto na leitura de dados do armazenamento em nuvem e a necessidade de ler todos os arquivos subjacentes. Com o data skipping no Delta Lake, as consultas podem ler seletivamente apenas os arquivos Delta que contêm dados relevantes, economizando um tempo considerável. O data skipping pode ajudar com a poda de arquivos estática, a poda de arquivos dinâmica, a poda de partição estática e a poda de partição dinâmica.
Antes do Liquid Clustering, essa era uma configuração manual. Havia regras práticas para garantir que os arquivos tivessem o tamanho adequado e fossem eficientes para consulta. Agora, com o Liquid Clustering, os tamanhos dos arquivos são determinados e mantidos automaticamente com as rotinas de otimização.
Se você estiver lendo estes artigos (ou leu a versão anterior) e já criou tabelas com ZORDER, precisará recriar as tabelas com o Liquid Clustering.
Além disso, o Liquid Clustering otimiza para evitar arquivos muito pequenos ou muito grandes (distorção e balanceamento) e atualiza os tamanhos dos arquivos à medida que novos dados são anexados para manter suas tabelas otimizadas.
3. Use o Liquid Clustering em suas tabelas de fatos
Para melhorar a velocidade da query, o Delta Lake oferece suporte à capacidade de otimizar a disposição dos dados armazenados no armazenamento em cloud com o Liquid Clustering. Agrupe por colunas que você usaria em situações semelhantes a índices clusterizados no mundo dos bancos de dados, embora não sejam, na verdade, uma estrutura auxiliar. Uma tabela com liquid clustering agrupará os dados na definição CLUSTER BY para que linhas com valores de coluna semelhantes da definição CLUSTER BY sejam colocalizadas no conjunto ideal de arquivos.
A maioria dos sistemas de banco de dados introduziu a indexação como uma forma de melhorar o desempenho da query. Os índices são arquivos e, portanto, à medida que os dados aumentam de tamanho, eles podem se tornar outro problema de big data a ser resolvido. Em vez disso, o Delta Lake ordena os dados nos arquivos Parquet para tornar a seleção de intervalo no armazenamento de objetos mais eficiente. Combinado com o processo de coleta de estatísticas e o salto de dados, as tabelas com Liquid Clustering são semelhantes às operações de busca (seek) versus varredura (scan) em bancos de dados, que os índices resolveram, sem criar outro gargalo de compute para encontrar os dados que uma query está procurando.
Para tabelas com Liquid Clustering, a melhor prática é limitar o número de colunas na cláusula CLUSTER BY a 1-4. Escolhemos as chaves estrangeiras (usadas como chaves estrangeiras, mas não impostas como tal) das 3 maiores dimensões que eram grandes demais para serem transmitidas aos workers.
Por fim, o Liquid Clustering substitui a necessidade de ZORDER e particionamento. Portanto, se você usar o Liquid Clustering, não precisará mais (nem poderá) particionar explicitamente as tabelas com o Hive.
4. Use o Liquid Clustering nas chaves da sua dimensão maior e nos predicados prováveis
Como você está lendo este blog, provavelmente tem dimensões e uma chave substituta ou uma chave primária em suas tabelas de dimensão. Uma chave que é um big integer, validada e que se espera que seja única. Após o databricks runtime 10.4, as colunas de identidade foram disponibilizadas ao público em geral e fazem parte da CREATE TABLE sintaxe.
O Databricks também introduziu Chaves Primárias e Chaves Estrangeiras não impostas no Runtime 11.3 e que são visíveis em clusters e workspaces habilitados para o Unity Catalog.
Uma das dimensões com as quais estávamos trabalhando tinha mais de 1 bilhão de linhas e se beneficiou da omissão de arquivos e da eliminação dinâmica de arquivos após adicionarmos nossos predicados às tabelas clusterizadas. Nossas dimensões menores foram clusterizadas no campo de chave de dimensão e transmitidas no join para os fatos. Semelhante ao conselho sobre tabelas de fatos, limite o número de colunas no Cluster By de 1 a 4 campos na dimensão que têm maior probabilidade de serem incluídos em um filtro, além da chave.
Além do salto de arquivo e da facilidade de manutenção, o Liquid Clustering permite adicionar mais colunas do que o ZORDER e é mais flexível do que o particionamento no estilo Hive.
5. Analise a tabela para coletar estatísticas para o Adaptive Query Execution Optimizer e habilitar a Predictive Optimization
Um dos maiores avanços no Apache Spark™ 3.0 foi o Adaptive Query Execution, ou AQE, para abreviar. A partir do Spark 3.0, há três recursos principais no AQE, incluindo o coalescing de partições pós-shuffle, a conversão de sort-merge join para broadcast join e a otimização de skew join. Juntos, esses recursos permitem o desempenho acelerado de modelos dimensionais no Spark.
Para que o AQE saiba qual plano escolher para você, precisamos coletar estatísticas sobre as tabelas. Você faz isso emitindo o comando ANALYZE TABLE. Clientes relataram que a coleta de estatísticas da tabela reduziu significativamente a execução de consultas para modelos dimensionais, incluindo joins complexos.
ANALYZE TABLE MY_BIG_DIM COMPUTE STATISTICS FOR ALL COLUMNS
Você ainda pode aproveitar a tabela Analyze como parte de suas rotinas de carregamento, mas agora é melhor simplesmente habilitar a Otimização Preditiva em sua account, Catálogo e Esquema.
ALTER CATALOG [catalog_name] {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
ALTER {SCHEMA | DATABASE} schema_name {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
A otimização preditiva remove a necessidade de gerenciar manualmente as operações de manutenção para tabelas gerenciadas do Unity Catalog no Databricks.
Com a otimização preditiva ativada, o Databricks identifica automaticamente as tabelas que se beneficiariam de operações de manutenção e as executa para o usuário. As operações de manutenção são executadas apenas quando necessário, eliminando execuções desnecessárias e a sobrecarga associada ao acompanhamento e à solução de problemas de desempenho.
Atualmente, as Otimizações Preditivas executam Vacuum e Optimize em tabelas. Fique atento às atualizações da Otimização Preditiva e aguarde até que o recurso incorpore a análise de tabelas e a coleta de estatísticas, além de aplicar automaticamente as chaves de cluster líquidas.
Conclusão
Seguindo as diretrizes acima, as organizações podem reduzir os tempos de query. Em nosso exemplo, melhoramos o desempenho da query em 9 vezes no mesmo cluster. As otimizações reduziram bastante a E/S e garantiram que processássemos apenas os dados necessários. Também nos beneficiamos da estrutura flexível do Delta Lake, pois ele consegue escalar e lidar com os tipos de queries que serão enviadas ad hoc pelas ferramentas de Business Intelligence.
Desde a primeira versão deste blog, o Photon agora está ativado por padrão para nosso Databricks SQL Warehouse e está disponível em clusters All Purpose e Jobs. Saiba mais sobre Photon e o aumento de desempenho que ele fornecerá a todas as suas consultas Spark SQL com o Databricks.
Os clientes podem esperar que o desempenho de suas queries de ETL/ELT e SQL melhore ativando o Photon no Databricks Runtime. Combinando as melhores práticas descritas aqui, com o Databricks Runtime habilitado para Photon, você pode esperar alcançar um desempenho de consulta de baixa latência que pode superar os melhores cloud data warehouses.
Crie seu banco de dados de esquema em estrela com o Databricks SQL hoje mesmo.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.