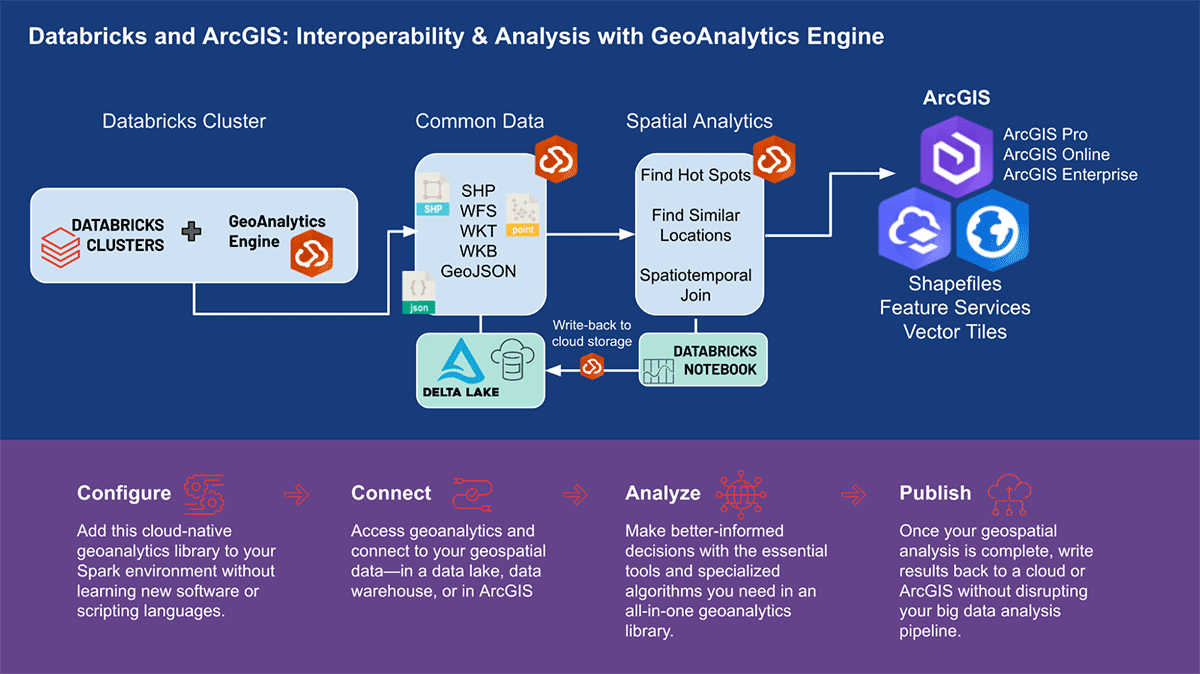
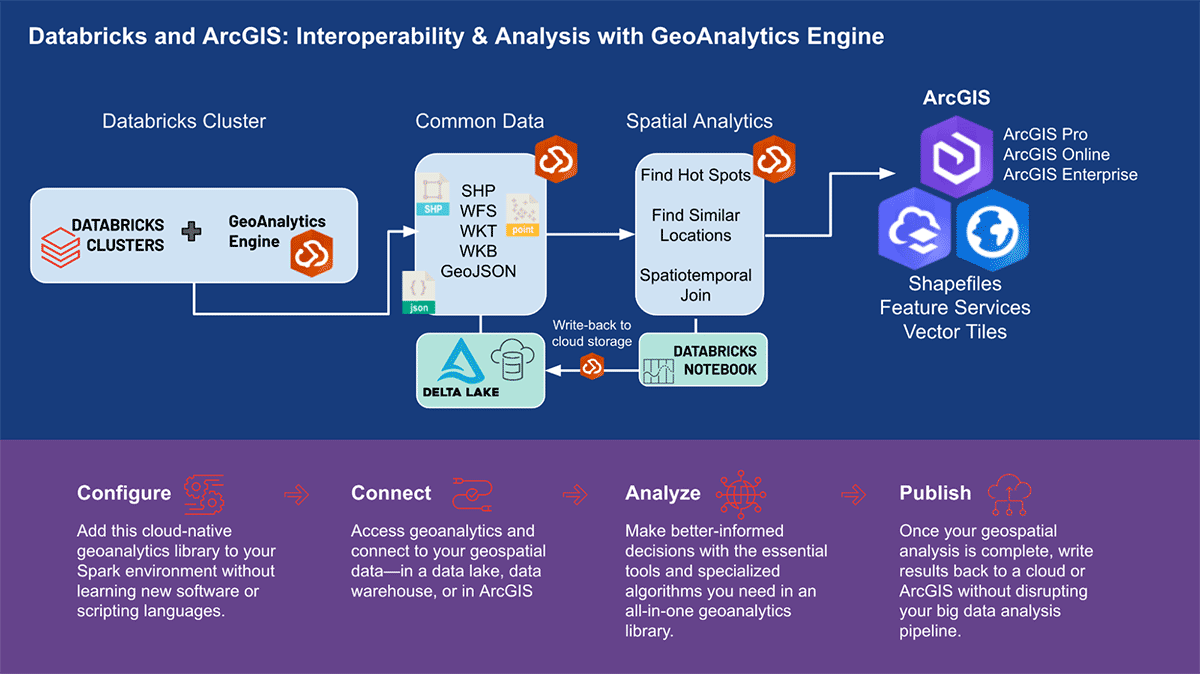
ArcGIS GeoAnalytics Engine no Databricks
Análise Geoespacial Escalável em um Fluxo de Trabalho de Ciência de Dados
por Kent Marten e Arif Masrur
Este é um post colaborativo da Esri e Databricks. Agradecemos as contribuições do Engenheiro de Soluções Sênior Arif Masrur, Ph.D. na Esri.
Avanços em big data permitiram que organizações de todos os setores abordassem questões científicas, sociais e de negócios críticas. O desenvolvimento de infraestrutura de big data auxilia analistas, engenheiros e cientistas de dados a enfrentar os principais desafios de trabalhar com big data - volume, velocidade, veracidade, valor e variedade. No entanto, o processamento e a análise de dados geoespaciais massivos apresentam seu próprio conjunto de desafios. Todos os dias, centenas de exabytes de dados com reconhecimento de localização são gerados. Esses conjuntos de dados contêm uma ampla gama de conexões e relacionamentos complexos entre entidades do mundo real, necessitando de ferramentas avançadas capazes de vincular efetivamente esses relacionamentos multifacetados por meio de operações otimizadas, como junções espaciais e espaciotemporais. Os inúmeros formatos geoespaciais que precisam ser ingeridos, verificados e padronizados para análise escalonada eficiente aumentam a complexidade.
Algumas das dificuldades de trabalhar com dados geográficos são abordadas pelo recentemente anunciado suporte para expressões H3 integradas no Databricks. No entanto, existem muitos casos de uso geoespacial, alguns dos quais são mais complexos ou centrados em geometria em vez de índices de grade. Os usuários podem trabalhar com uma variedade de ferramentas e bibliotecas na plataforma Databricks, aproveitando os inúmeros recursos do Lakehouse.
A Esri, fornecedora líder mundial de software GIS, oferece um conjunto abrangente de ferramentas, incluindo ArcGIS Enterprise, ArcGIS Pro e ArcGIS Online, para resolver os desafios de geoanálise mencionados. Organizações e profissionais de dados que usam Databricks precisam de acesso a ferramentas onde realizam seu trabalho diário fora do ambiente ArcGIS. É por isso que estamos entusiasmados em anunciar a primeira versão do ArcGIS GeoAnalytics Engine (doravante denominado GA Engine), que permite que cientistas de dados, engenheiros e analistas analisem seus dados geoespaciais dentro de seus ambientes de análise de big data existentes. Especificamente, este motor é um plugin para Apache Spark™ que estende dataframes com processamento e análise espacial muito rápidos, pronto para ser executado no Databricks.
Benefícios do ArcGIS GeoAnalytics Engine
O GA Engine da Esri permite que cientistas de dados acessem funções e ferramentas geoanalíticas dentro de seu ambiente Databricks. Os principais recursos do GA Engine são:
- Mais de 120 funções SQL espaciais — Crie geometrias, teste relacionamentos espaciais e mais usando sintaxe Python ou SQL
- Poderosas ferramentas de análise — Execute fluxos de trabalho comuns de análise espaciotemporal e estatística com apenas algumas linhas de código
- Indexação espacial automática — Execute junções espaciais otimizadas e outras operações imediatamente
- Interoperabilidade com fontes de dados GIS comuns — Carregue e salve dados de shapefiles, serviços de feição e tiles vetoriais
- Nativo da nuvem e nativo do Spark — Testado e pronto para instalação no Databricks
- Fácil de usar — Crie pipelines de big data com habilitação espacial usando uma API Python intuitiva que estende o PySpark
Funções SQL e ferramentas de análise
Atualmente, o GA Engine fornece mais de 120 funções SQL e mais de 15 ferramentas de análise espacial que suportam análise espacial e espaciotemporal avançada. Essencialmente, as funções do GA Engine estendem a API Spark SQL, permitindo consultas espaciais em colunas de DataFrame. Essas funções podem ser chamadas com funções Python ou em uma instrução de consulta PySpark SQL e permitem criar geometrias, operar em geometrias, avaliar relacionamentos espaciais, resumir geometrias e muito mais. Em contraste com as funções SQL que operam linha por linha usando uma ou duas colunas, as ferramentas do GA Engine estão cientes de todas as colunas em um DataFrame e usam todas as linhas para computar um resultado, se necessário. Esses amplos conjuntos de ferramentas de análise permitem gerenciar, enriquecer, resumir ou analisar conjuntos de dados inteiros.
|
|
O GA Engine é uma ferramenta analítica poderosa. No entanto, não se deve ofuscar a facilidade com que o GA Engine trabalha com formatos GIS comuns. A documentação do GA Engine inclui vários tutoriais para ler e escrever de e para Shapefiles e Serviços de Feição. A capacidade de processar dados geoespaciais usando formatos GIS fornece grande interoperabilidade entre Databricks e produtos Esri.
{kind=link}
Motor GA para diferentes casos de uso
Vamos revisar alguns cenários de uso de vários setores para mostrar como o GA Engine da ESRI lida com grandes quantidades de dados espaciais. O suporte para análise espacial e espaciotemporal escalonável tem como objetivo ajudar qualquer empresa a tomar decisões críticas. Em três domínios diversos de análise de dados - mobilidade, transações de consumidores e serviço público - nos concentraremos em revelar insights geográficos.
Análise de dados de mobilidade
Os dados de mobilidade estão em constante crescimento e podem ser divididos em duas categorias: movimento humano e movimento de veículos. Dados de mobilidade humana coletados de usuários de smartphones em áreas de serviço de telefonia móvel fornecem um olhar mais aprofundado sobre os padrões de atividade humana. Dados de movimento de milhões de veículos conectados fornecem informações ricas em tempo real sobre volumes de tráfego direcionais, fluxos de tráfego, velocidades médias, congestionamento e muito mais. Esses conjuntos de dados são tipicamente grandes (bilhões de registros) e complexos (centenas de atributos). Esses dados exigem análise espacial e espaciotemporal que vai além da análise espacial básica, com acesso imediato a ferramentas estatísticas avançadas e funções geoanalíticas especializadas.
Vamos começar analisando um exemplo de movimento humano com base em dados da Cell Analytics™ da Ookla®, parceira da Esri. A Ookla® coleta big data sobre desempenho de serviço sem fio global, cobertura e medições de sinal com base no aplicativo Speedtest®. Os dados incluem informações sobre o dispositivo de origem, conectividade da rede móvel, localização e timestamp. Neste caso, trabalhamos com um subconjunto de dados contendo aproximadamente 16 bilhões de registros. Com ferramentas não otimizadas para operações paralelas no Apache Spark™, a leitura desses dados de alto volume e sua habilitação para operações espaciotemporais poderiam incorrer em horas de tempo de processamento. Usando uma única linha de código com o GeoAnalytics Engine, esses dados podem ser ingeridos de arquivos parquet em poucos segundos.
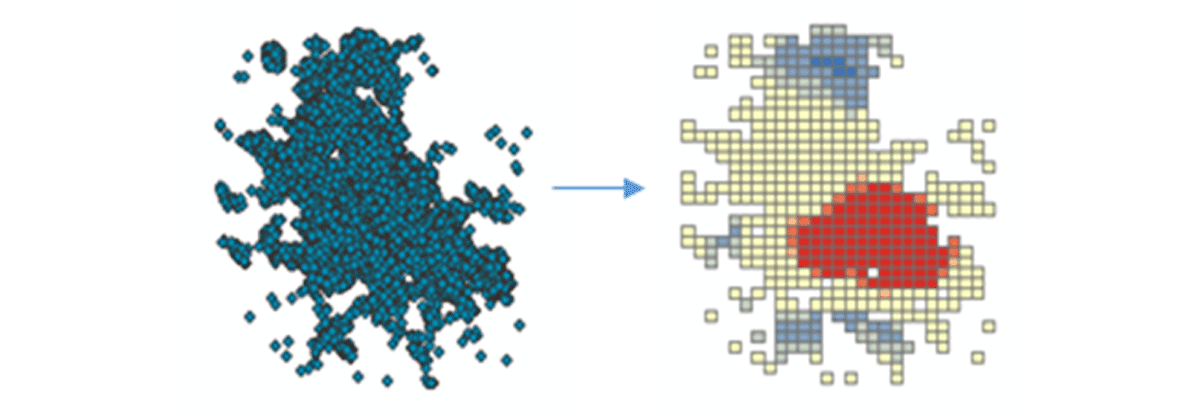
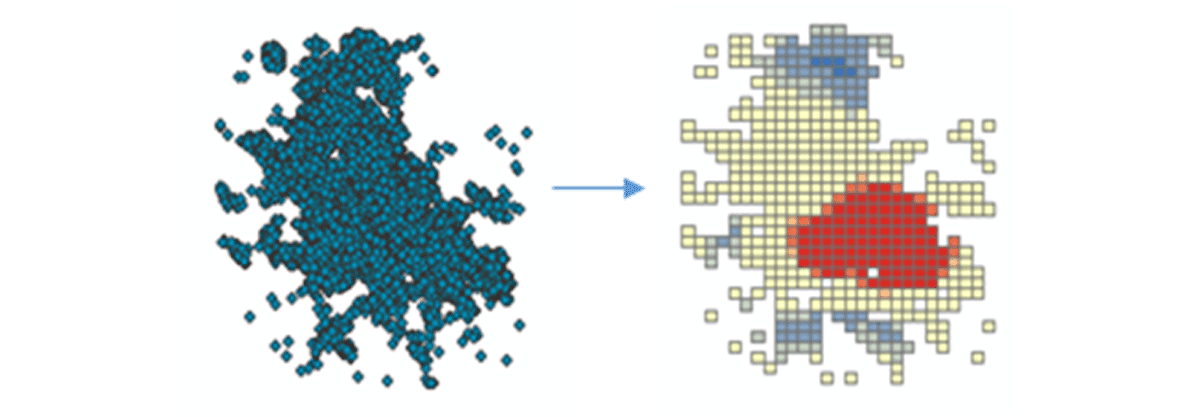
Para começar a extrair insights acionáveis, vamos mergulhar nos dados com uma pergunta simples: Qual é o padrão espacial de dispositivos móveis sobre os Estados Unidos continentais? Isso nos permitirá começar a caracterizar a presença e atividade humana. A ferramenta FindHotSpots pode ser usada para identificar clusters espaciais estatisticamente significativos de valores altos (hot spots) e valores baixos (cold spots).
{kind=link}
O DataFrame resultante de pontos de interesse foi visualizado e estilizado usando Matplotlib (Figura 2). Ele mostrou muitos registros de conexões de dispositivos (vermelho) em comparação com locais com baixa densidade de dispositivos conectados (azul) nos Estados Unidos continentais. Sem surpresas, as principais áreas urbanas indicaram uma maior densidade de dispositivos conectados.
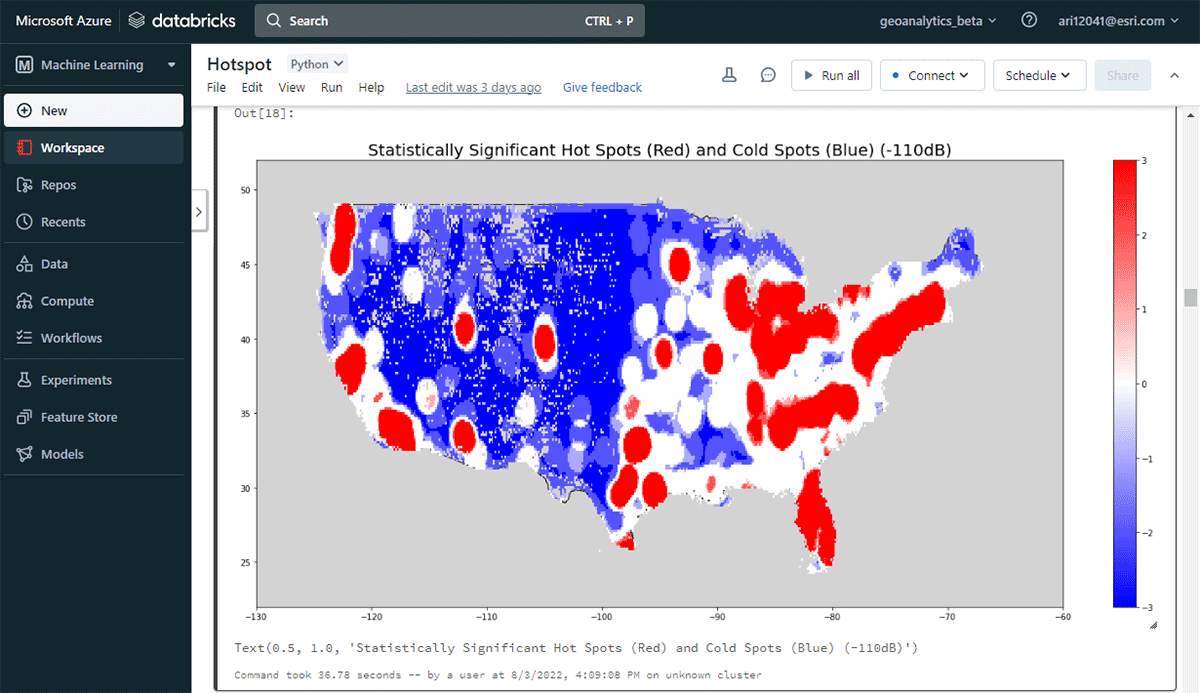
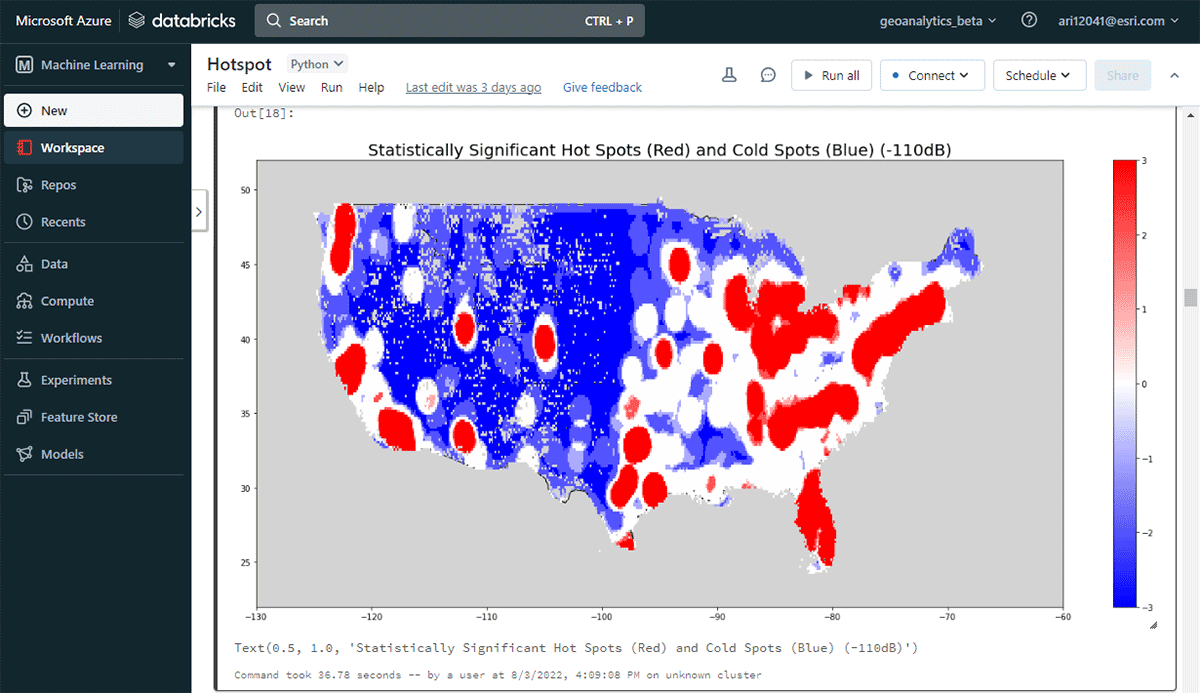{kind=link}
Em seguida, perguntamos: a intensidade do sinal da rede móvel segue um padrão homogêneo nos Estados Unidos? Para responder a isso, a ferramenta AggregatePoints foi usada para resumir as observações de dispositivos em agrupamentos hexagonais para identificar áreas com serviço celular particularmente forte e particularmente fraco (Figura 3). Usamos rsrp (reference signal received power) – um valor usado para medir a intensidade do sinal da rede móvel – para calcular a estatística média em agrupamentos de 15 km. Essa análise iluminou que a intensidade do sinal de serviço celular não é consistente - em vez disso, tende a ser mais forte ao longo das principais redes rodoviárias e áreas urbanas.
Além de plotar o resultado usando st_plotting, usamos o módulo arcgis, publicamos o DataFrame resultante como uma camada de feições no ArcGIS Online e criamos uma visualização interativa baseada em mapa.
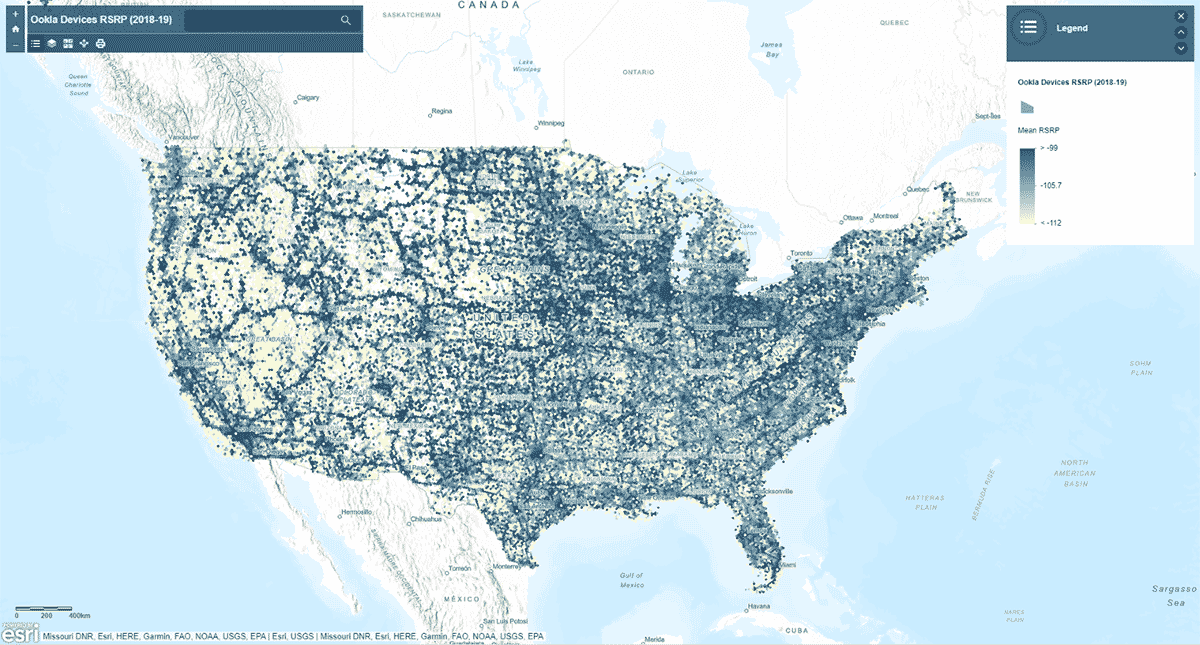
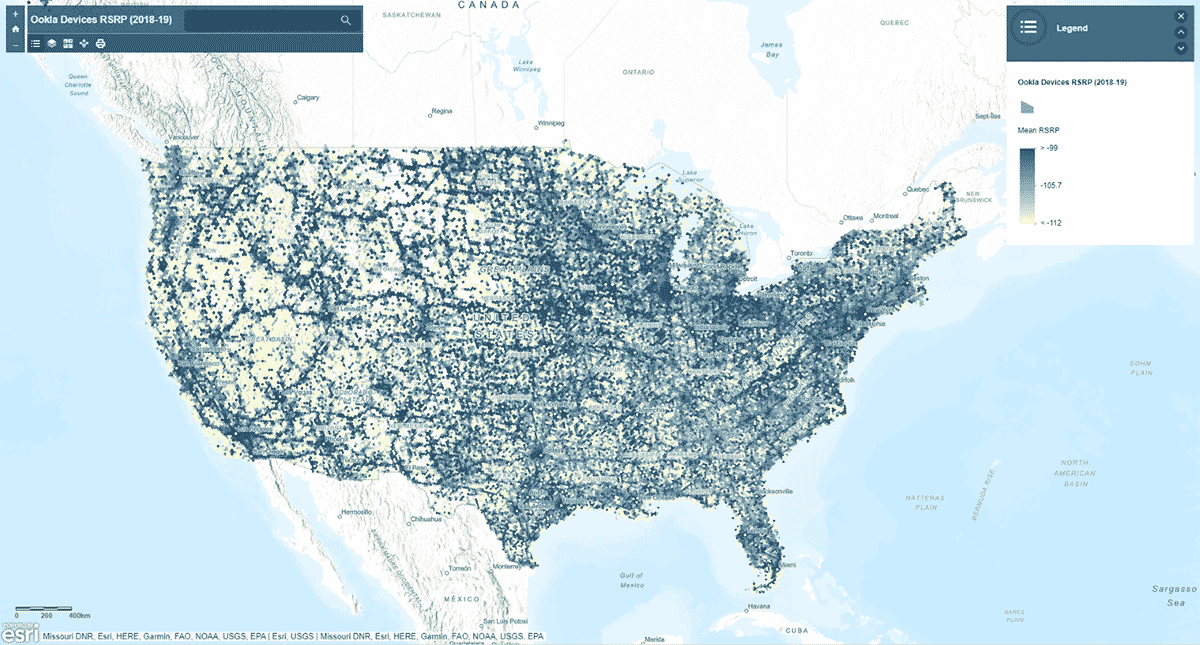{kind=link}
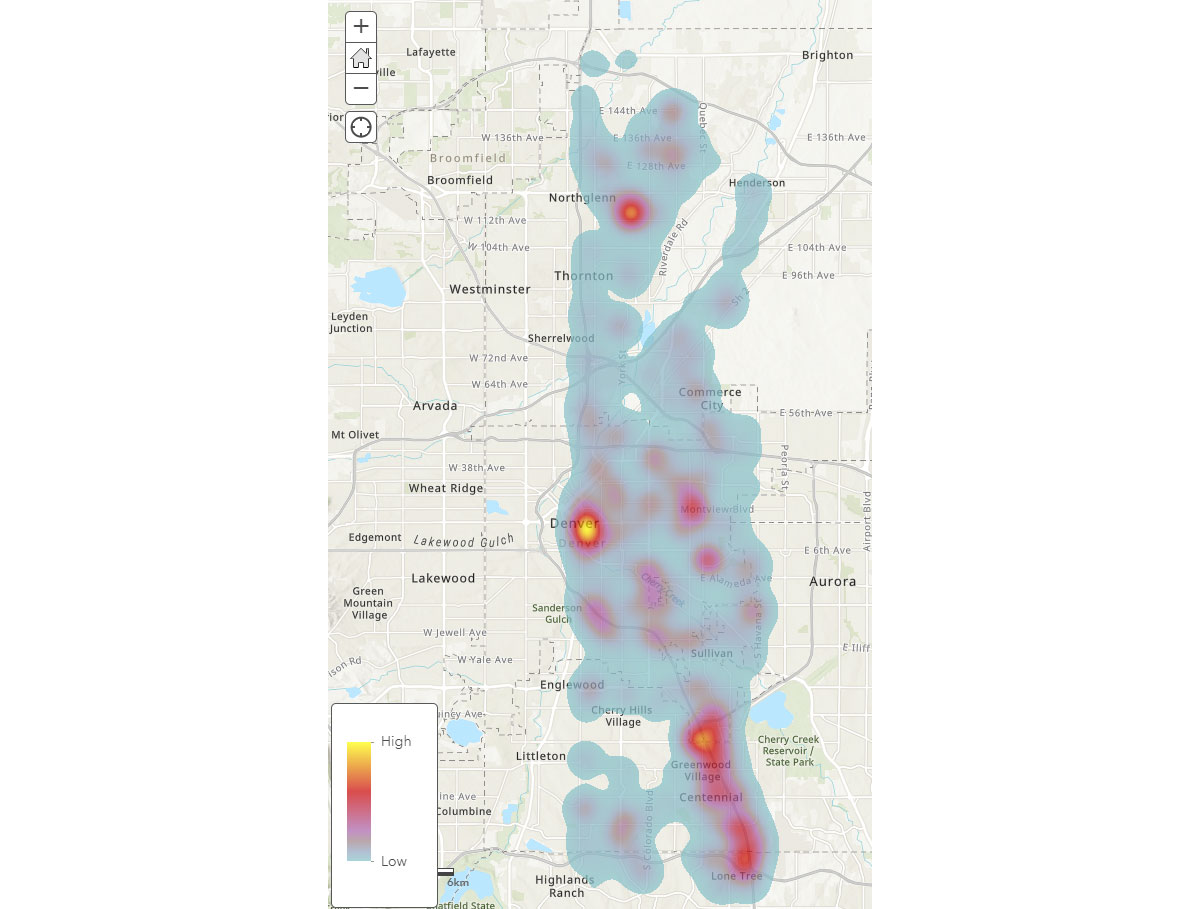
Agora que entendemos os padrões espaciais amplos de dispositivos móveis, como podemos obter insights mais profundos sobre os padrões de atividade humana? Onde as pessoas passam tempo? Para responder a isso, usamos o FindDwellLocations para procurar dispositivos em Denver, CO que permaneceram pelo menos 5 minutos na mesma localização geral em 31 de maio de 2019 (sexta-feira). Essa análise pode nos ajudar a entender locais com atividade mais prolongada, ou seja, destinos de consumidores, e separá-los da atividade geral de deslocamento.
O DataFrame result_dwell nos fornece dispositivos ou indivíduos que permaneceram em diferentes locais. O mapa de calor de duração de permanência na Figura 4 fornece uma visão geral de onde as pessoas passam seu tempo em Denver.
{kind=link}
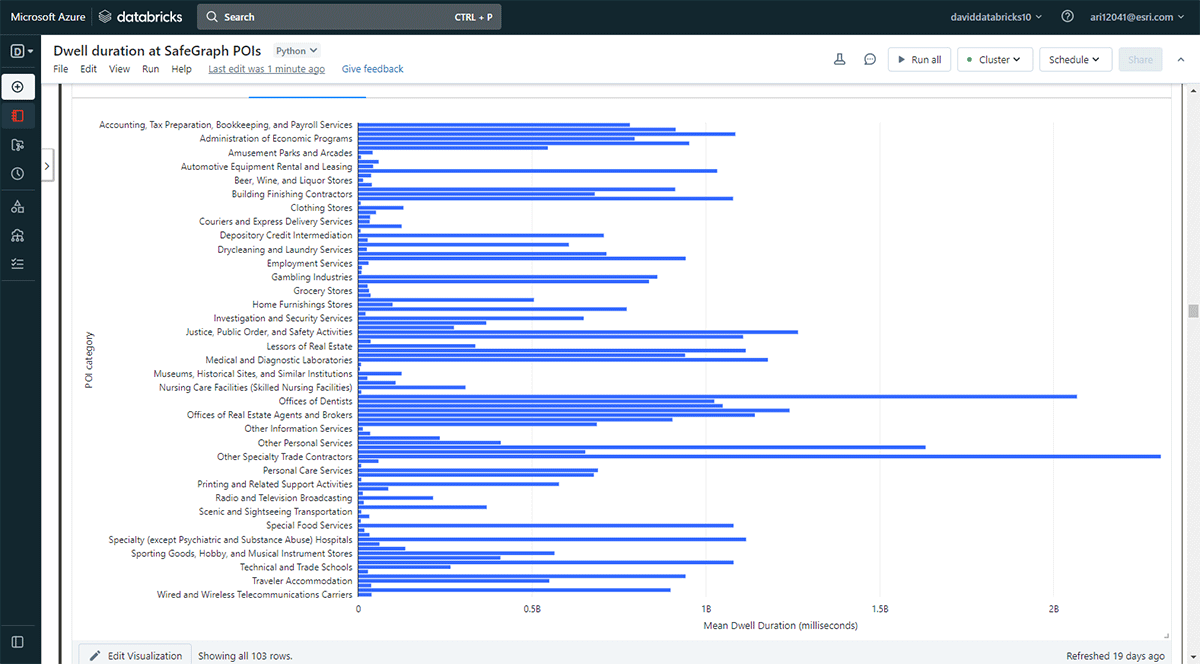
Também queríamos explorar os locais que as pessoas visitam por períodos mais longos. Para isso, usamos o Overlay para identificar quais pegadas de pontos de interesse (POI) dos dados de Geometria Geometry da SafeGraph se cruzaram com os locais de permanência (do DataFrame result_dwell) em 31 de maio de 2019. Usando a função groupBy, contamos os tempos de permanência dos dispositivos conectados para cada uma das principais categorias de POI. A Figura 5 destaca que alguns POIs urbanos em Denver coincidiram com tempos de permanência mais longos, incluindo lojas de material de escritório, papelaria e presentes, e escritórios de empreiteiros.
{kind=link}
Este fluxo de trabalho analítico de exemplo com dados da Cell AnalyticsTM pode ser aplicado ou adaptado para caracterizar as atividades das pessoas de forma mais específica. Por exemplo, poderíamos usar os dados para obter insights sobre o comportamento do consumidor em torno de locais de varejo. Quais restaurantes ou cafeterias esses dispositivos ou indivíduos visitaram depois de fazer compras no Walmart ou Costco? Além disso, esses conjuntos de dados podem ser úteis para gerenciar pandemias e desastres naturais. Por exemplo, as pessoas seguem as diretrizes de emergência de saúde pública durante uma pandemia? Quais locais urbanos podem ser os próximos focos de COVID-19 ou de má qualidade do ar induzida por incêndios florestais? Vemos disparidades nas mobilidades e atividades humanas devido à desigualdade de renda em uma escala geográfica mais ampla?
Análise de dados de transação
Dados agregados de transação em pontos de interesse contêm informações ricas sobre como e quando as pessoas gastam seu dinheiro em locais específicos. O grande volume e a velocidade desses dados exigem ferramentas analíticas espaciais avançadas para entender claramente o comportamento de gastos do consumidor: Como o comportamento do consumidor difere por geografia? Quais empresas tendem a se co-localizar para serem lucrativas? Quais mercadorias os consumidores compram em uma loja física (por exemplo, Walmart) em comparação com os produtos que compram online? O comportamento do consumidor muda durante eventos extremos como a COVID-19?
Essas perguntas podem ser respondidas usando dados do SafeGraph Spend e o GeoAnalytics Engine. Por exemplo, queríamos identificar como os padrões de deslocamento das pessoas foram impactados durante a COVID-19 nos Estados Unidos. Para isso, analisamos dados nacionais do SafeGraph Spend de 2020 e 2021. Abaixo, mostramos os gastos anuais (USD) dos consumidores em aluguel de carros corporativos, agregados aos condados dos EUA. Após publicar o DataFrame no ArcGIS Online, criamos um mapa interativo usando o widget Swipe do ArcGIS Web AppBuilder para explorar rapidamente quais condados apresentaram mudanças ao longo do tempo (Figura 6).
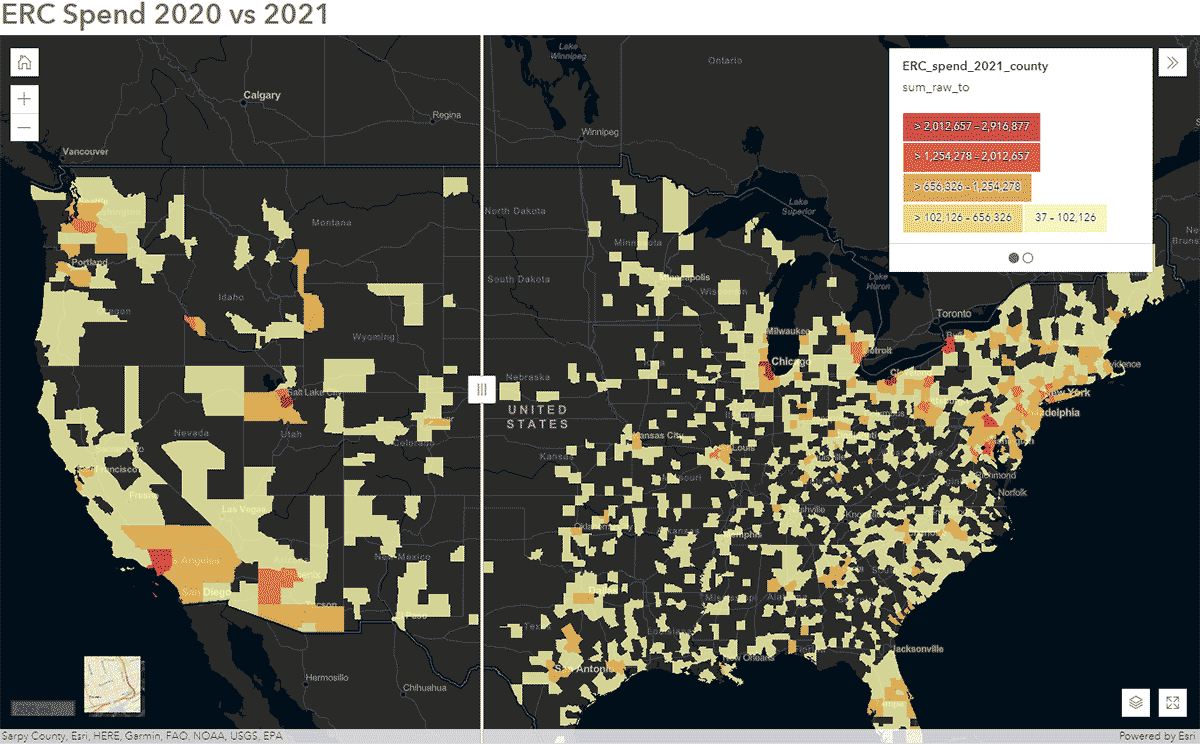
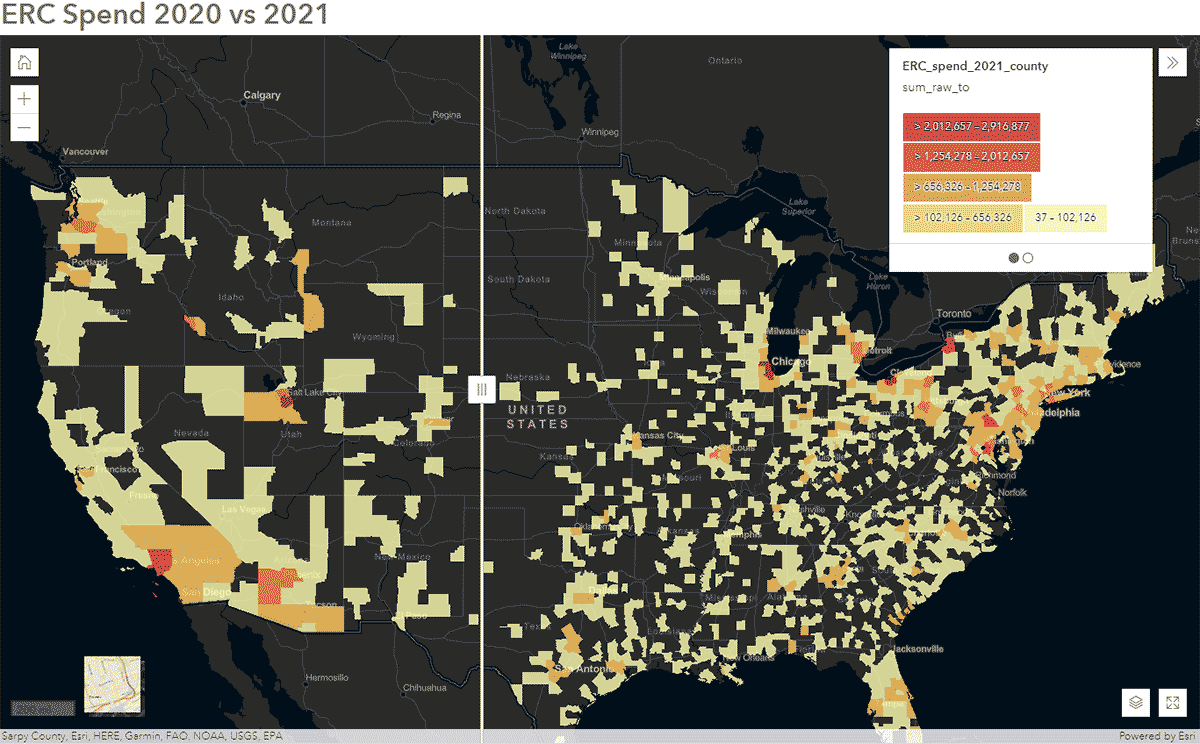{kind=link}
Em seguida, exploramos qual condado dos EUA teve o maior gasto online em um ano e outros condados com padrões de gastos de compras online semelhantes, considerando similaridades em população e padrões de venda de produtos agrícolas. Com base na filtragem de atributos do DataFrame de gastos, identificamos que Sacramento liderou a lista em gastos de compras online em 2020. Para analisar áreas semelhantes, usamos a ferramenta FindSimilarLocations para identificar condados que são mais semelhantes ou diferentes de Sacramento em termos de compras e gastos online, mas em relação a similaridades em população e agricultura (área total de terras cultivadas e vendas médias de produtos agrícolas) (Figura 7).
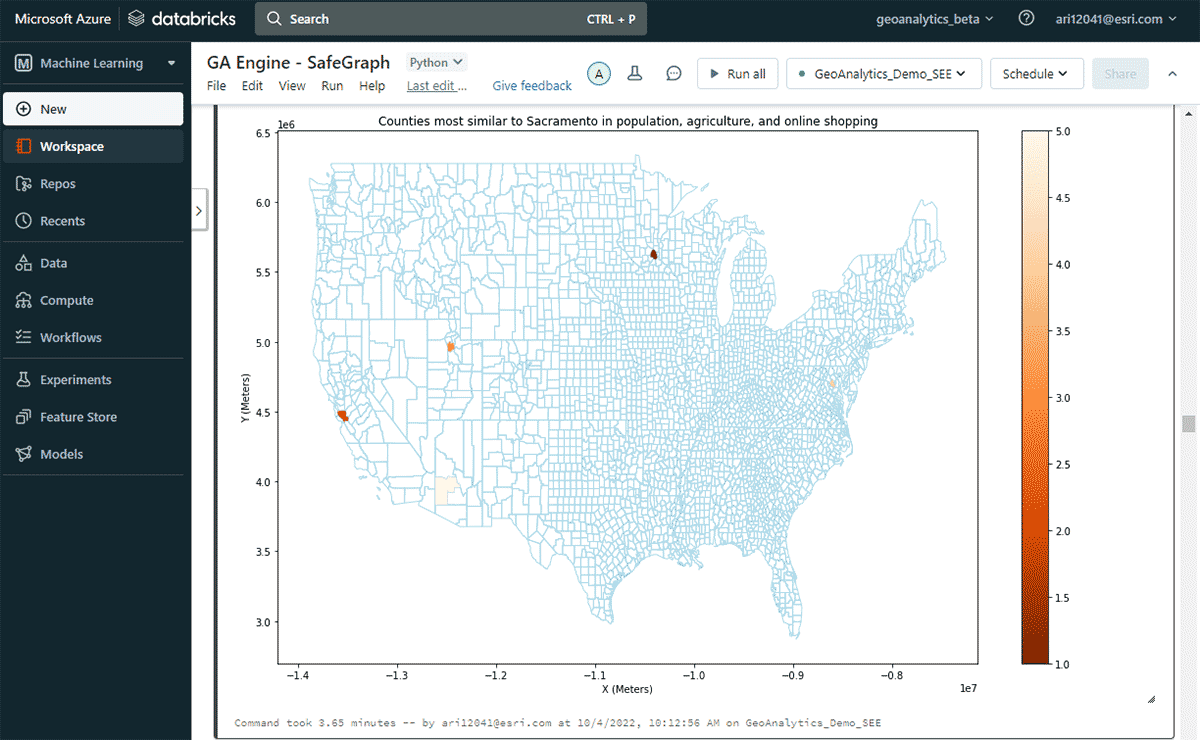
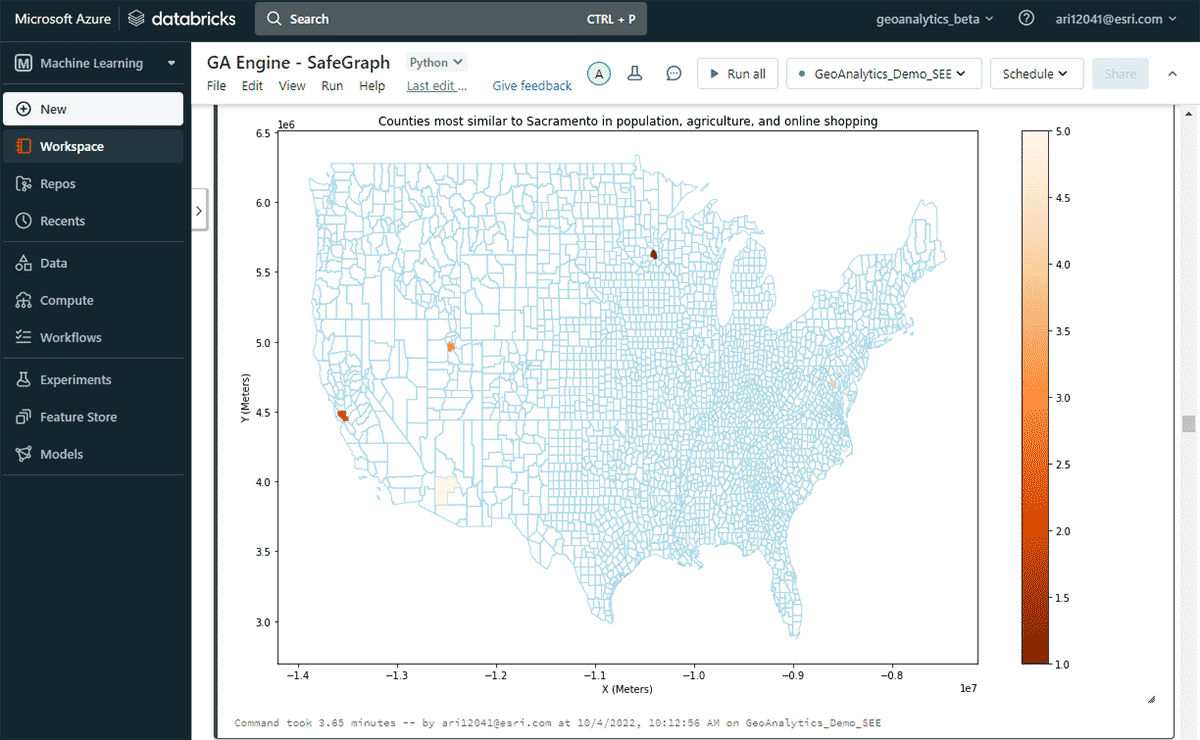{kind=link}
Análise de dados de serviços públicos
Conjuntos de dados de serviços públicos, como registros de chamadas 311, contêm informações valiosas sobre serviços não emergenciais prestados aos residentes. O monitoramento e a identificação oportunos de padrões espaço-temporais nesses dados podem ajudar os governos locais a planejar e alocar recursos para a resolução eficiente de chamadas 311.
Neste exemplo, nosso objetivo foi ler, processar/limpar e filtrar rapidamente ~27 milhões de registros de solicitações de serviço 311 de Nova York de 2010 a fevereiro de 2022, e então responder às seguintes perguntas para a área da cidade de Nova York:
- Quais são as áreas com os tempos médios de resposta 311 mais longos?
- Existem padrões nos tipos de reclamação com tempos médios de resposta longos?
Para responder à primeira pergunta, foram identificadas as chamadas com os tempos de resposta mais longos. Em seguida, os dados foram filtrados para incluir registros com duração maior que a média mais três desvios padrão.
Para responder à segunda pergunta de encontrar grupos significativos de reclamações, utilizamos a ferramenta GroupByProximity para procurar reclamações do mesmo tipo que estivessem a 500 pés e 5 dias uma da outra. Em seguida, filtramos por grupos com mais de 10 registros e criamos um casco convexo para cada grupo de reclamações, o que será útil para visualizar seus padrões espaciais (Figura 8). Usando st.plot() - um método de plotagem leve incluído no ArcGIS GeoAnalytics Engine - as geometrias armazenadas em um DataFrame podem ser visualizadas instantaneamente.
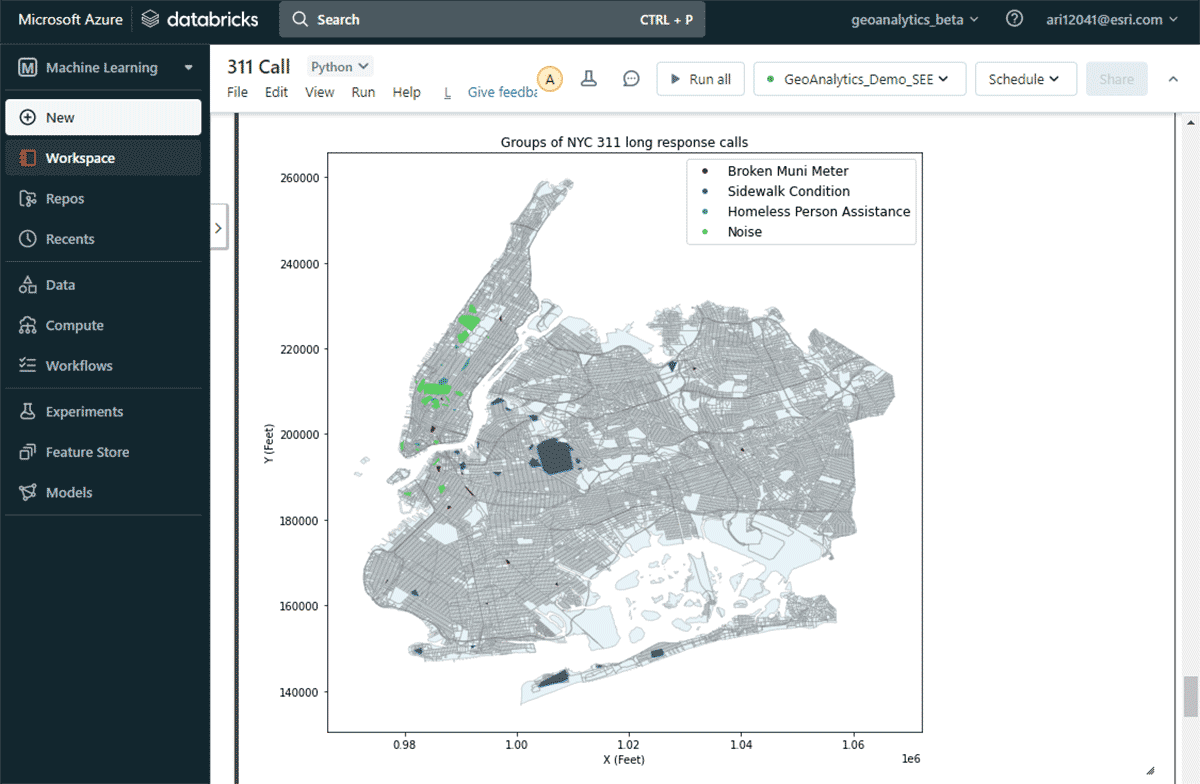
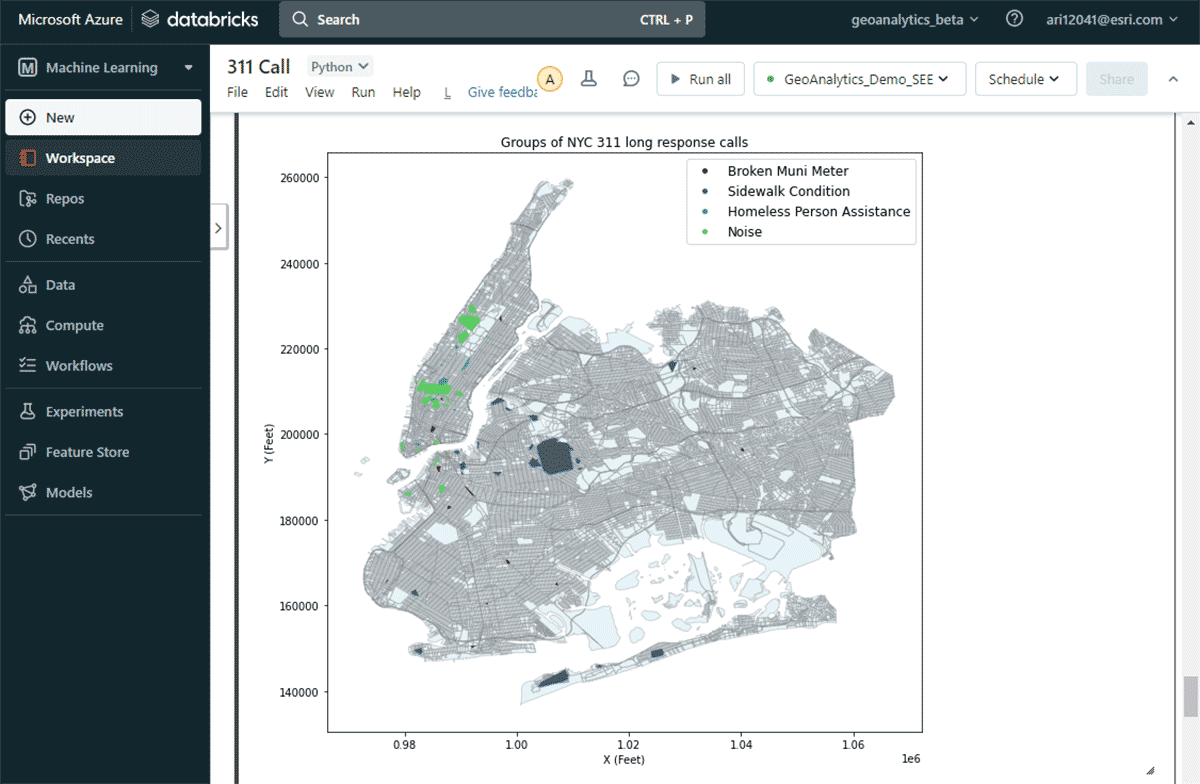{kind=link}
Com este mapa, foi fácil identificar as distribuições espaciais de diferentes tipos de reclamações na cidade de Nova York. Por exemplo, houve um número considerável de reclamações de barulho nas áreas central e inferior de Manhattan, enquanto as condições da calçada são uma preocupação maior em Brooklyn e Queens. Esses insights rápidos baseados em dados podem ajudar os tomadores de decisão a iniciar medidas acionáveis.
Benchmarks
O desempenho é um fator decisivo para muitos clientes que tentam escolher uma solução de análise. Testes de benchmark da Esri mostraram que o GA Engine oferece desempenho significativamente melhor ao executar análises espaciais de big data em comparação com pacotes de código aberto. Os ganhos de desempenho aumentam conforme o tamanho dos dados aumenta, portanto, os usuários verão um desempenho ainda melhor para conjuntos de dados maiores. Por exemplo, a tabela abaixo mostra os tempos de computação para uma tarefa de interseção espacial que une dois conjuntos de dados de entrada (pontos e polígonos) com tamanhos variados de até milhões de registros de dados. Cada cenário de junção foi testado em um cluster Databricks de máquina única e de várias máquinas.
| Entradas de Interseção Espacial | Tempo de Computação (segundos) | ||
|---|---|---|---|
| Conjunto de Dados Esquerdo | Conjunto de Dados Direito | Máquina Única | Múltiplas Máquinas |
| 50 polígonos | 6K pontos | 6 | 5 |
| 3K polígonos | 6K pontos | 10 | 5 |
| 3K polígonos | 2M pontos | 19 | 9 |
| 3K polígonos | 17M pontos | 46 | 16 |
| 220K polígonos | 17M pontos | 80 | 29 |
| 11M polígonos | 17M pontos | 515 (8.6 min) | 129 (2.1 min) |
| 11M polígonos | 19M pontos | 1.373 (22 min) | 310 (5 min) |
Arquitetura e Instalação
Antes de encerrar, vamos dar uma olhada na arquitetura do GeoAnalytics Engine e explorar como ele funciona. Como ele é nativo da nuvem e nativo do Spark, podemos usar facilmente a biblioteca GeoAnalytics em um ambiente Spark baseado na nuvem. Instalar a implantação do GeoAnalytics Engine no ambiente Databricks requer configuração mínima. Você carregará o módulo por meio de um arquivo JAR e ele será executado usando os recursos fornecidos pelo cluster.
A instalação tem 2 etapas básicas que se aplicam a AWS, Azure e GCP:
- Prepare o workspace
- Crie ou inicie um workspace Databricks
- Carregue o arquivo JAR do GeoAnalytics no DBFS
- Adicione e habilite um script de inicialização
- Crie um cluster
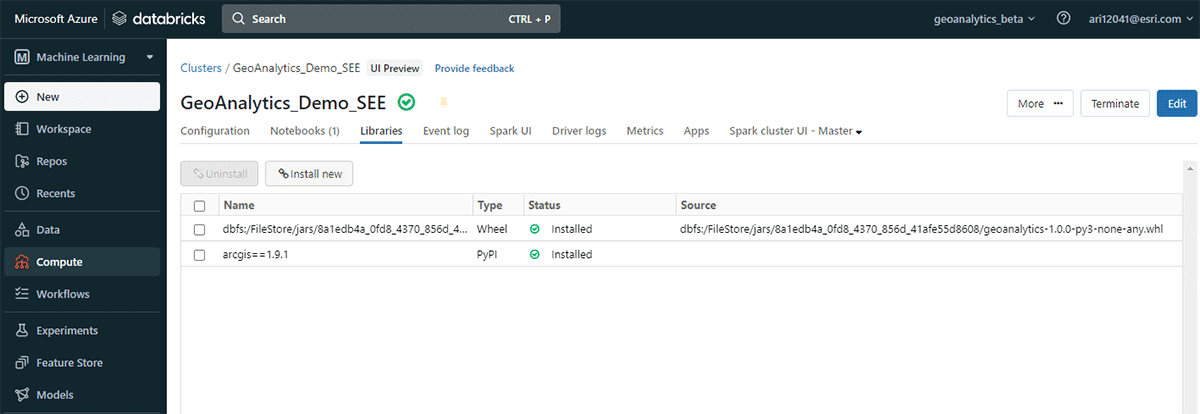
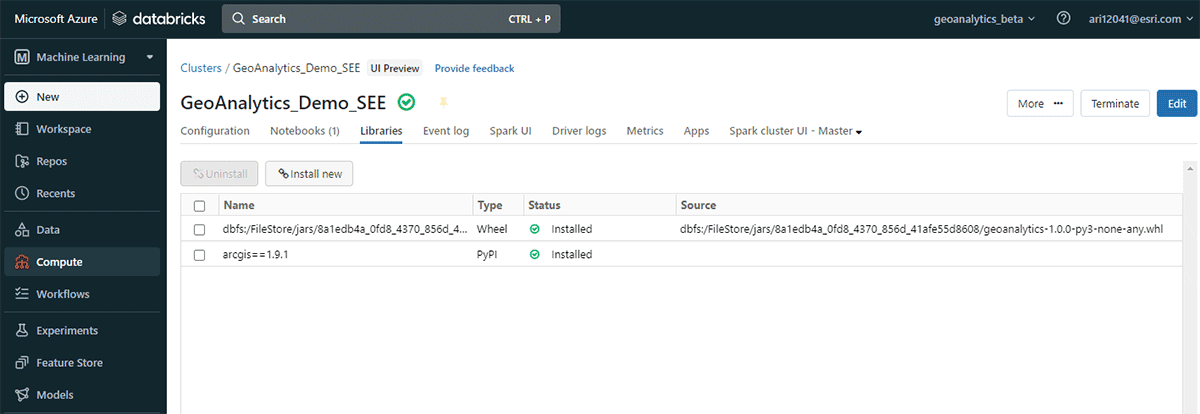{kind=link}
Após a instalação, os usuários analisarão usando um notebook Python conectado ao ambiente Spark. Você pode acessar instantaneamente os dados da Databricks Lakehouse Platform e realizar análises. Após a análise, você pode persistir os resultados gravando-os de volta em seu data lake, SQL Warehouse, serviços de BI (Business Intelligence) ou ArcGIS.
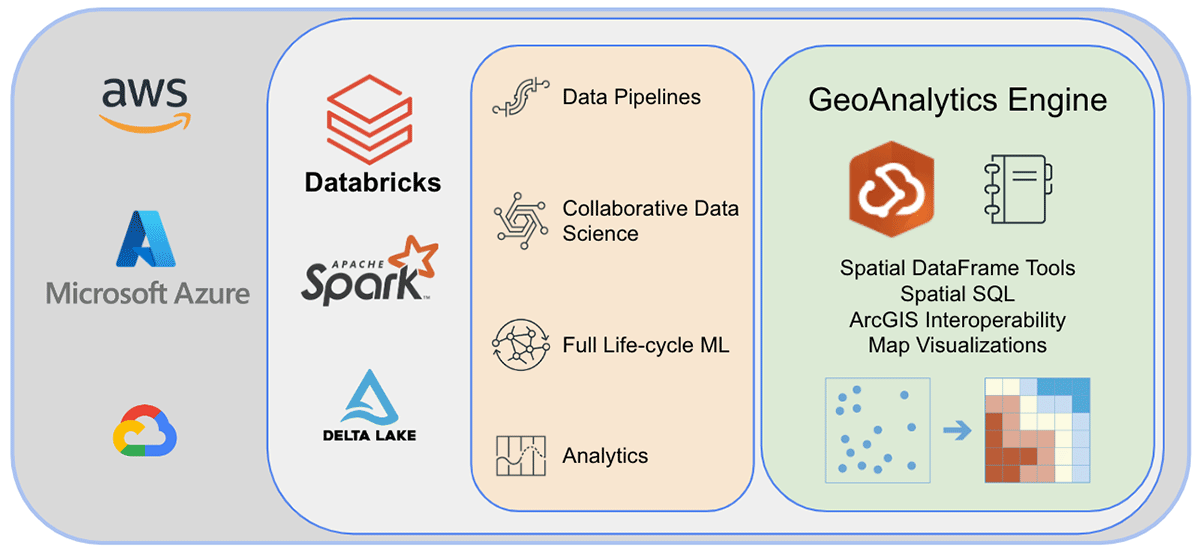
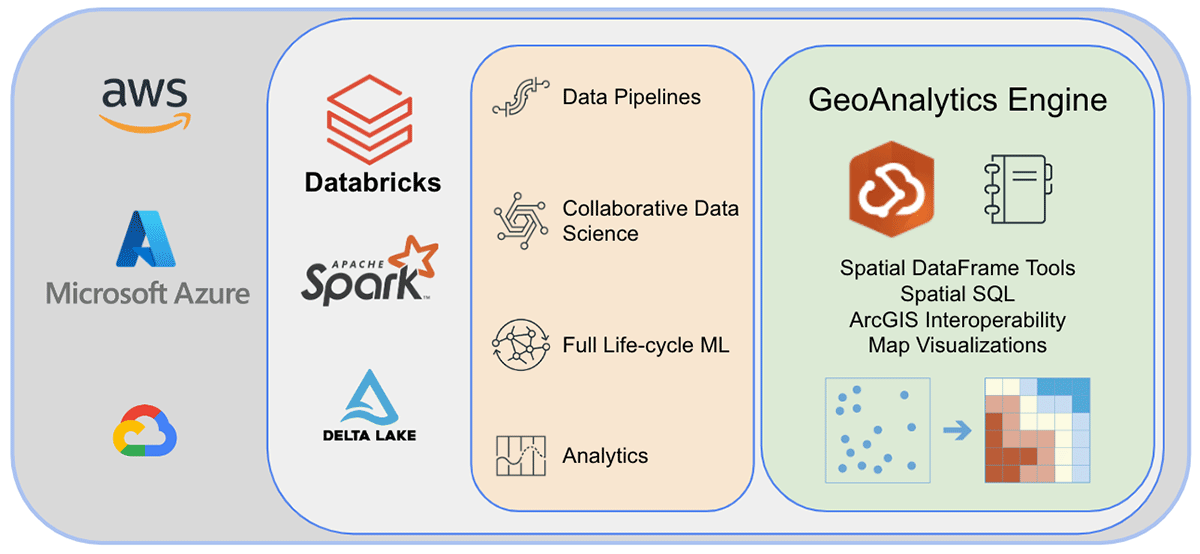{kind=link}
Próximos passos
Neste blog, apresentamos o poder do ArcGIS GeoAnalytics Engine no Databricks e demonstramos como podemos enfrentar juntos os casos de uso geoespaciais mais desafiadores. Consulte este Notebook da Databricks para referência detalhada dos exemplos mostrados acima. No futuro, o GeoAnalytics Engine será aprimorado com funcionalidades adicionais, incluindo exportação GeoJSON, suporte a H3 binning e algoritmos de clusterização como K-Nearest Neighbor.
O GeoAnalytics Engine funciona com Databricks em Azure, AWS e GCP. Entre em contato com suas equipes de contas Databricks e Esri para obter detalhes sobre a implantação da biblioteca GeoAnalytics em seu ambiente Databricks preferido. Para saber mais sobre o GeoAnalytics Engine e explorar como obter acesso a este poderoso produto, visite o site da Esri.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.