Retrospectiva de 2025: Databricks SQL, mais rápido para cada carga de trabalho
Analítica e cargas de trabalho de AI mais rápidas, mesmo com o aumento da escala de dados, governança de dados e uso.
por Tad Rosenberg, Jeremy Lewallen, Mostafa Mokhtar, Chris Stevens e Ina Felsheim
- Em 2025, o Databricks SQL proporcionou um desempenho até 40% mais rápido em cargas de trabalho de produção, com melhorias aplicadas automaticamente.
- Queries aprimoradas em BI, ETL, analítica espacial e IA, mesmo com dados governados e compartilhados em vigor e com alta simultaneidade.
- Todos os ganhos estão disponíveis hoje no Databricks SQL Serverless, melhorando o desempenho e a eficiência de custos para cargas de trabalho existentes sem ajustes ou reescritas.
Para a maioria das equipes de dados, o desempenho não se trata mais de um ajuste único. Trata-se de ter analítica mais rápida à medida que os dados, os usuários e a governança escalam, sem aumentar os custos.
Com o Databricks SQL (DBSQL), essa expectativa já vem incorporada à plataforma. Em 2025, o desempenho médio das cargas de trabalho de produção melhorou em até 40%, sem necessidade de ajustes, reescrita de queries ou intervenção manual.
A história vai além de um único benchmark. O desempenho melhorou em toda a plataforma, desde carregamentos de painel mais rápidos e pipelines mais eficientes até queries que permanecem responsivas mesmo com governança e dados compartilhados em vigor, enquanto as funções de analítica geoespacial e AI continuam a escalar sem complexidade adicional.
O objetivo continua simples: acelerar as cargas de trabalho e reduzir o custo total por padrão. Com o DBSQL Serverless, as tabelas gerenciadas do Unity Catalog e a otimização preditiva, as melhorias são aplicadas automaticamente em todo o seu ambiente, para que as cargas de trabalho existentes se beneficiem à medida que o mecanismo evolui.
Esta postagem detalha os ganhos de desempenho oferecidos em 2025 no mecanismo de query, Unity Catalog, Delta Sharing, armazenamento, SQL espacial e funções de IA.
Desempenho de query rápido em qualquer carga de trabalho
O Databricks SQL mede o desempenho usando milhões de queries de clientes reais que são executadas repetidamente em produção. Por meio do acompanhamento de como essas cargas de trabalho mudam ao longo do tempo, medimos o impacto real das melhorias e otimizações da plataforma, em vez de benchmarks isolados.
Em 2025, o Databricks SQL proporcionou ganhos de desempenho consistentes em todos os principais tipos de carga de trabalho. Essas melhorias são aplicadas por default por meio de otimizações no nível do mecanismo, como Predictive Query Execution e Photon Vectorized Shuffle, sem exigir alterações de configuração.
- Cargas de trabalho exploratórias apresentaram os maiores ganhos, rodando em média 40% mais rápido e permitindo que analistas e cientistas de dados iterem mais rapidamente em grandes datasets.
- As cargas de trabalho de Business Intelligence melhoraram em cerca de 20%, resultando em dashboards mais responsivos e análises interativas mais fluidas sob simultaneidade.
- As cargas de trabalho de ETL também se beneficiaram, executando aproximadamente 10% mais rápido e encurtando os Runtimes do pipeline sem retrabalho.
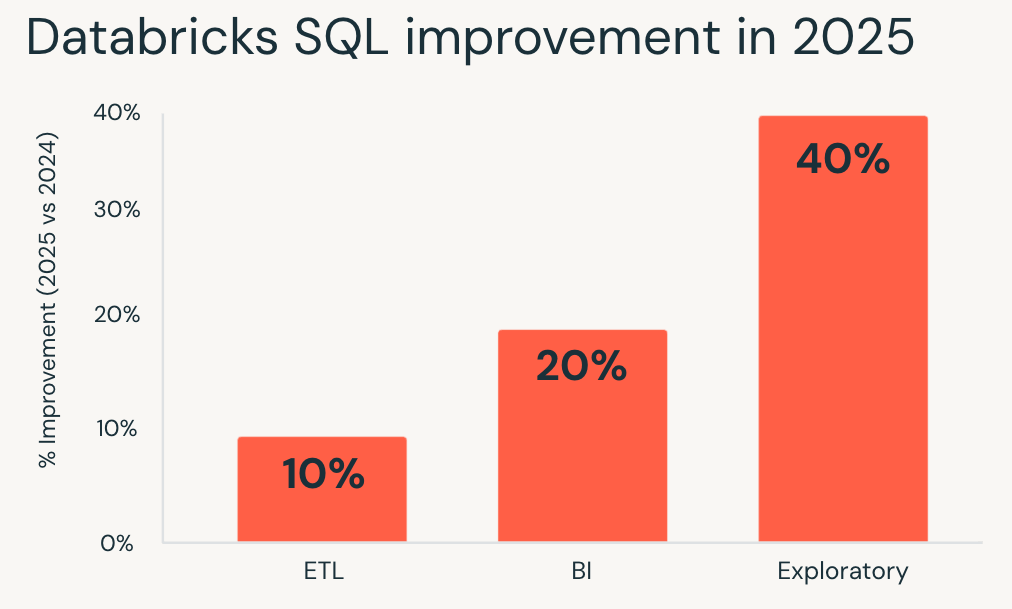
Se você avaliou o Databricks SQL pela última vez há um ano, suas cargas de trabalho existentes já estão rodando mais rápido hoje.
Analítica que se mantém rápida conforme a governança escala com o Unity Catalog
À medida que os acervos de dados crescem, a governança geralmente se torna uma fonte oculta de latência. Verificações de permissão, acesso a metadados e consultas de linhagem podem desacelerar as queries, especialmente em ambientes interativos e de alta simultaneidade.
Em 2025, o Unity Catalog reduziu significativamente essa sobrecarga. A latência de ponta a ponta do catálogo melhorou em até 10x, impulsionada por otimizações no serviço de catálogo, na pilha de rede, no cliente do Databricks Runtime e nos serviços dependentes.
O resultado é visível onde mais importa:
- Painéis permanecem responsivos mesmo com controles de acesso refinados.
- Workloads de alta simultaneidade são escalonados sem gargalos de acesso a metadados.
- A analítica interativa parece mais rápida à medida que os usuários exploram dados governados em escala.
As equipes não precisam mais escolher entre governança forte e desempenho. Com o Unity Catalog, a analítica permanece rápida à medida que a governança se expande para mais dados e mais usuários.
Delta Sharing, dados compartilhados com o desempenho de dados nativos
O compartilhamento de dados entre equipes ou organizações tradicionalmente tem um custo. As queries em tabelas compartilhadas geralmente eram executadas mais lentamente, e as otimizações eram aplicadas de forma desigual em comparação com os dados nativos.
Em 2025, o Databricks SQL eliminou essa lacuna. Por meio de melhorias na execução de consultas e na propagação de estatísticas, as consultas em tabelas compartilhadas via Delta Sharing foram executadas até 30% mais rápido, alinhando o desempenho de dados compartilhados ao de tabelas nativas.

Essa mudança é mais importante em cenários onde dados externos precisam se comportar como dados internos. Marketplaces de dados, analítica entre organizações e relatórios orientados por parceiros agora podem ser executados em datasets compartilhados sem sacrificar a interatividade ou a previsibilidade.
Com o Delta Sharing, as equipes podem compartilhar amplamente dados governados enquanto preservam as expectativas de desempenho para analítica moderna.
Menor custo de armazenamento, otimizações automáticas integradas
À medida que os volumes de dados crescem, a eficiência do armazenamento se torna uma parte maior do custo total. A compactação desempenha um papel fundamental, mas a escolha de formatos e o gerenciamento de migrações tradicionalmente adicionaram sobrecarga operacional.
Em 2025, o Databricks tornou a compressão Zstandard o default para todas as novas Tabelas Gerenciadas do Unity Catalog. O Zstandard é um formato de compressão de código aberto que oferece até 40% de economia nos custos de armazenamento em comparação com formatos mais antigos, sem degradar o desempenho das consultas.

Esses benefícios se aplicam automaticamente a novas tabelas, e as tabelas existentes também podem ser migradas para Zstandard, com ferramentas de migração simples chegando em breve. Grandes tabelas de fatos, datasets de longa retenção e domínios em rápido crescimento obtêm reduções de custo imediatas sem alterações na forma como as queries são escritas ou executadas.
O resultado é um custo de armazenamento menor por default, entregue sem sacrificar o desempenho ou adicionar novos passos de ajuste.
Analítica geoespacial sem sistemas especializados
A analítica geoespacial exige muito da execução de queries. joins espaciais, consultas de intervalo e cálculos geométricos consomem muitos recursos computacionais e, em escala, geralmente exigem sistemas especializados ou um ajuste cuidadoso.
Em 2025, o Databricks SQL melhorou significativamente o desempenho para essas cargas de trabalho. As consultas de SQL espacial ficaram até 17 vezes mais rápidas, impulsionado por otimizações no nível do motor, como indexação de árvore R, junções espaciais otimizadas no Photon e otimização inteligente de junção por intervalo.
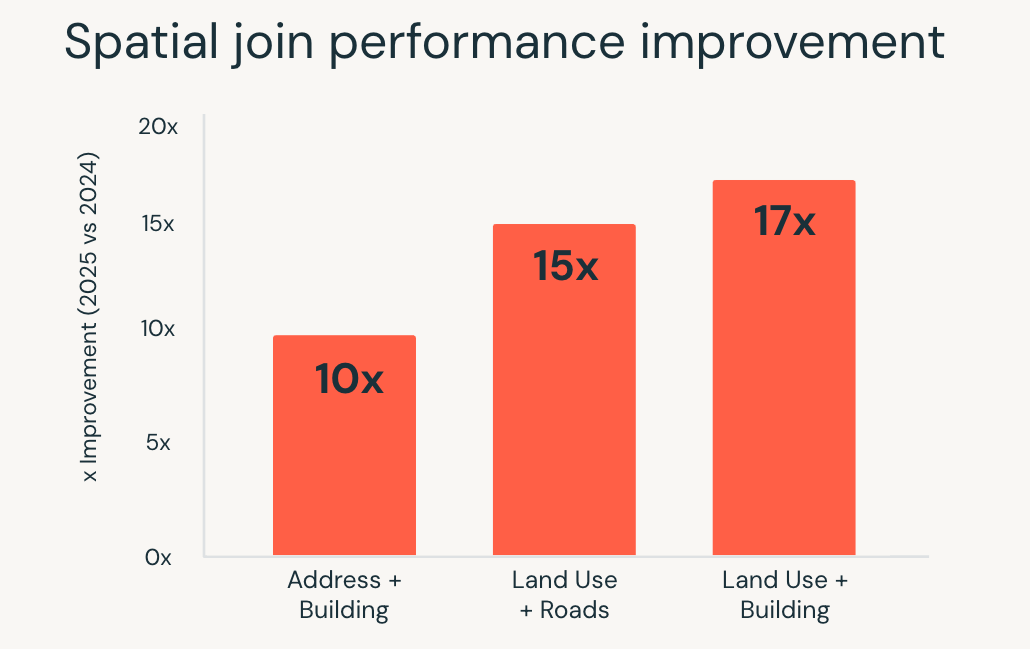
Essas melhorias permitem que as equipes trabalhem com dados de localização usando SQL padrão, enquanto o motor lida com a complexidade da execução automaticamente. Casos de uso como analítica de localização em tempo real, geofencing em grande escala e enriquecimento geográfico são executados de forma mais rápida e consistente à medida que os volumes de dados crescem.
A analítica espacial não exige mais ferramentas separadas ou otimização manual. Workloads geoespaciais complexos são escalonados diretamente no Databricks SQL.
Funções de IA, IA escalável diretamente no SQL
A aplicação de IA aos dados tradicionalmente exigia trabalho fora do warehouse. Classificação de texto, análise de documentos e tradução muitas vezes significavam construir pipelines separados, gerenciar a infraestrutura do modelo e integrar os resultados de volta aos fluxos de trabalho de analítica.
As AI Functions simplificam esse modelo, trazendo a IA diretamente para o SQL. Em 2025, o Databricks SQL expandiu significativamente a escala e o desempenho desses recursos. A nova infraestrutura otimizada para lotes proporcionou um desempenho até 85 vezes mais rápido para funções como ai_classify, ai_summarize e ai_translate, permitindo que grandes trabalhos em lote, que antes levavam horas, fossem concluídos em minutos.
O Databricks também introduziu a ai_parse_document e a otimizou rapidamente para escala. Modelos desenvolvidos especificamente para a compreensão de documentos, hospedados no Databricks Model Serving, proporcionaram um desempenho até 30 vezes mais rápido em comparação com alternativas de uso geral, tornando prático o processamento de grandes volumes de conteúdo não estruturado diretamente nos fluxos de trabalho de analítica.
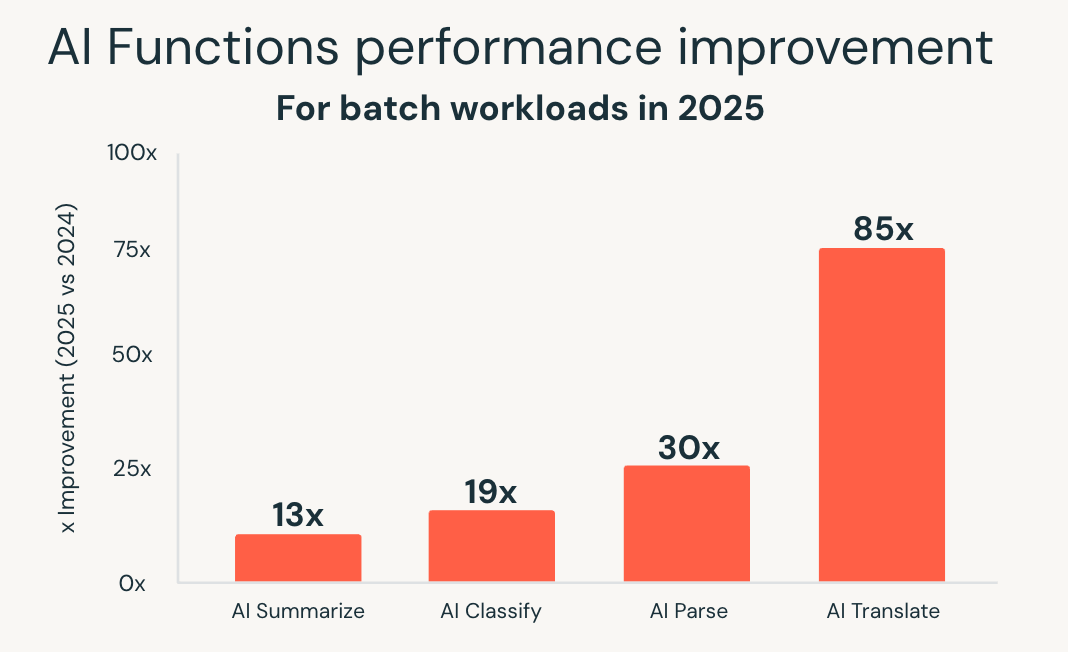
Essas melhorias permitem o processamento inteligente de documentos, a extração de percepções de dados não estruturados e a análise preditiva usando interfaces SQL familiares. As cargas de trabalho de AI são escalonadas juntamente com as cargas de trabalho de analítica, sem a necessidade de sistemas separados ou pipelines personalizados.
Com as AI Functions, o Databricks SQL se estende além da analítica para cargas de trabalho com tecnologia de AI, preservando a simplicidade e as expectativas de desempenho do warehouse.
Introdução
Todas essas melhorias já estão disponíveis no Databricks SQL Serverless, sem necessidade de ativação ou configuração.
Se você ainda não experimentou o DBSQL Serverless, crie um warehouse serverless e comece a fazer consultas. As cargas de trabalho existentes se beneficiam imediatamente, com melhorias de desempenho e custo aplicadas automaticamente à medida que a plataforma continua a evoluir.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.