Práticas recomendadas para avaliação de LLM de aplicativos RAG
Um estudo de caso sobre o bot de documentação da Databricks
Os chatbots são o caso de uso mais amplamente adotado para aproveitar os poderosos recursos de chat e raciocínio dos modelos de linguagem grandes (LLM). A arquitetura de geração aumentada por recuperação (RAG) está rapidamente se tornando o padrão da indústria para o desenvolvimento de chatbots porque combina os benefícios de uma base de conhecimento (através de um banco de vetores) e modelos generativos (por exemplo, GPT-3.5 e GPT-4) para reduzir alucinações, manter informações atualizadas e aproveitar o conhecimento específico do domínio. No entanto, avaliar a qualidade das respostas do chatbot continua sendo um problema não resolvido atualmente. Sem padrões da indústria definidos, as organizações recorrem à avaliação humana (rotulagem) – o que é demorado e difícil de escalar.
Aplicamos a teoria à prática para ajudar a formar as melhores práticas para a avaliação automatizada de LLMs, para que você possa implantar aplicativos RAG em produção de forma rápida e com confiança. Este blog representa a primeira de uma série de investigações que estamos realizando no Databricks para fornecer aprendizados sobre a avaliação de LLMs. Toda a pesquisa nesta postagem foi conduzida por Quinn Leng, Engenheiro de software Sênior no Databricks e criador do Assistente de IA da documentação da Databricks.
Desafios da autoavaliação na prática
Recentemente, a comunidade de LLMs tem explorado o uso de “LLMs como juízes” para avaliação automatizada, com muitos usando LLMs poderosos como o GPT-4 para fazer a avaliação das saídas de seus LLMs. O artigo de pesquisa do grupo lmsys explora a viabilidade e os prós e contras de usar vários LLMs (GPT-4, ClaudeV1, GPT-3.5) como juiz para tarefas de escrita, matemática e conhecimento de mundo.
Apesar de toda essa ótima pesquisa, ainda há muitas questões não respondidas sobre como aplicar juízes LLM na prática:
- Alinhamento com a avaliação humana: especificamente para um chatbot de perguntas e respostas de documentos, até que ponto a avaliação de um juiz LLM reflete a preferência humana real em termos de correção, legibilidade e abrangência das respostas?
- Acurácia por meio de exemplos: Qual é a eficácia de fornecer alguns exemplos de avaliação para o juiz LLM e o quanto isso aumenta a confiabilidade e a reutilização do juiz LLM em diferentes métricas?
- Escalas de avaliação apropriadas: Qual escala de avaliação é recomendada, uma vez que diferentes frameworks usam diferentes escalas de avaliação (por exemplo, AzureML usa de 0 a 100, enquanto langchain usa escalas binárias)?
- Aplicabilidade em diferentes casos de uso: Com a mesma métrica de avaliação (por exemplo, correção), até que ponto a métrica de avaliação pode ser reutilizada em diferentes casos de uso (p. ex., bate-papo casual, resumo de conteúdo, geração aumentada por recuperação)?
Aplicação de autoavaliação eficaz para aplicações de RAG
Exploramos as opções possíveis para as perguntas descritas acima no contexto de nosso próprio aplicativo de chatbot na Databricks. Acreditamos que nossas descobertas se generalizam e, portanto, podem ajudar sua equipe a avaliar efetivamente chatbots baseados em RAG a um custo menor e com maior velocidade:
- O LLM-como-juiz concorda com a avaliação humana em mais de 80% dos julgamentos. O uso de LLMs-como-juízes para nossa avaliação de chatbot baseado em documentos foi tão eficaz quanto o de juízes humanos, correspondendo à pontuação exata em mais de 80% dos julgamentos e ficando a uma distância de 1 ponto na pontuação (usando uma escala de 0 a 3) em mais de 95% dos julgamentos.
- Economize custos usando o GPT-3.5 com exemplos. O GPT-3.5 pode ser usado como um juiz LLM se você fornecer exemplos para cada pontuação de avaliação. Devido ao limite de tamanho do contexto, só é prático usar uma escala de avaliação de baixa precisão. Usar o GPT-3.5 com exemplos em vez do GPT-4 reduz o custo do juiz LLM em 10x e aumenta a velocidade em mais de 3x.
- Use escalas de avaliação de baixa precisão para facilitar a interpretação. Descobrimos que pontuações de avaliação de baixa precisão, como 0, 1, 2, 3 ou até mesmo binárias (0, 1), conseguem manter em grande parte a precisão em comparação com escalas de maior precisão, como de 0 a 10,0 ou de 0 a 100,0, ao mesmo tempo que torna consideravelmente mais fácil fornecer rubricas de avaliação tanto para anotadores humanos quanto para juízes LLM. Usar uma escala de menor precisão também permite a consistência das escalas de avaliação entre diferentes juízes LLM (por exemplo, entre GPT-4 e claude2).
- As aplicações RAG exigem seus próprios benchmarks. Um modelo pode ter um bom desempenho em um benchmark especializado publicado (por exemplo, conversa casual, matemática ou escrita criativa), mas isso não garante um bom desempenho em outras tarefas (por exemplo, responder a perguntas a partir de um determinado contexto). Os benchmarks só devem ser usados se o caso de uso corresponder, ou seja, uma aplicação RAG só deve ser avaliada com um benchmark de RAG.
Com base em nossa pesquisa, recomendamos o seguinte procedimento ao usar um juiz LLM:
- Use uma escala de avaliação de 1 a 5
- Use o GPT-4 como um juiz de LLM sem exemplos para entender as regras de avaliação
- Mude seu juiz LLM para o GPT-3.5 com um exemplo por pontuação
Nossa metodologia para estabelecer as melhores práticas
O restante desta postagem apresentará a série de experimentos que realizamos para formar estas melhores práticas.
Configuração do experimento
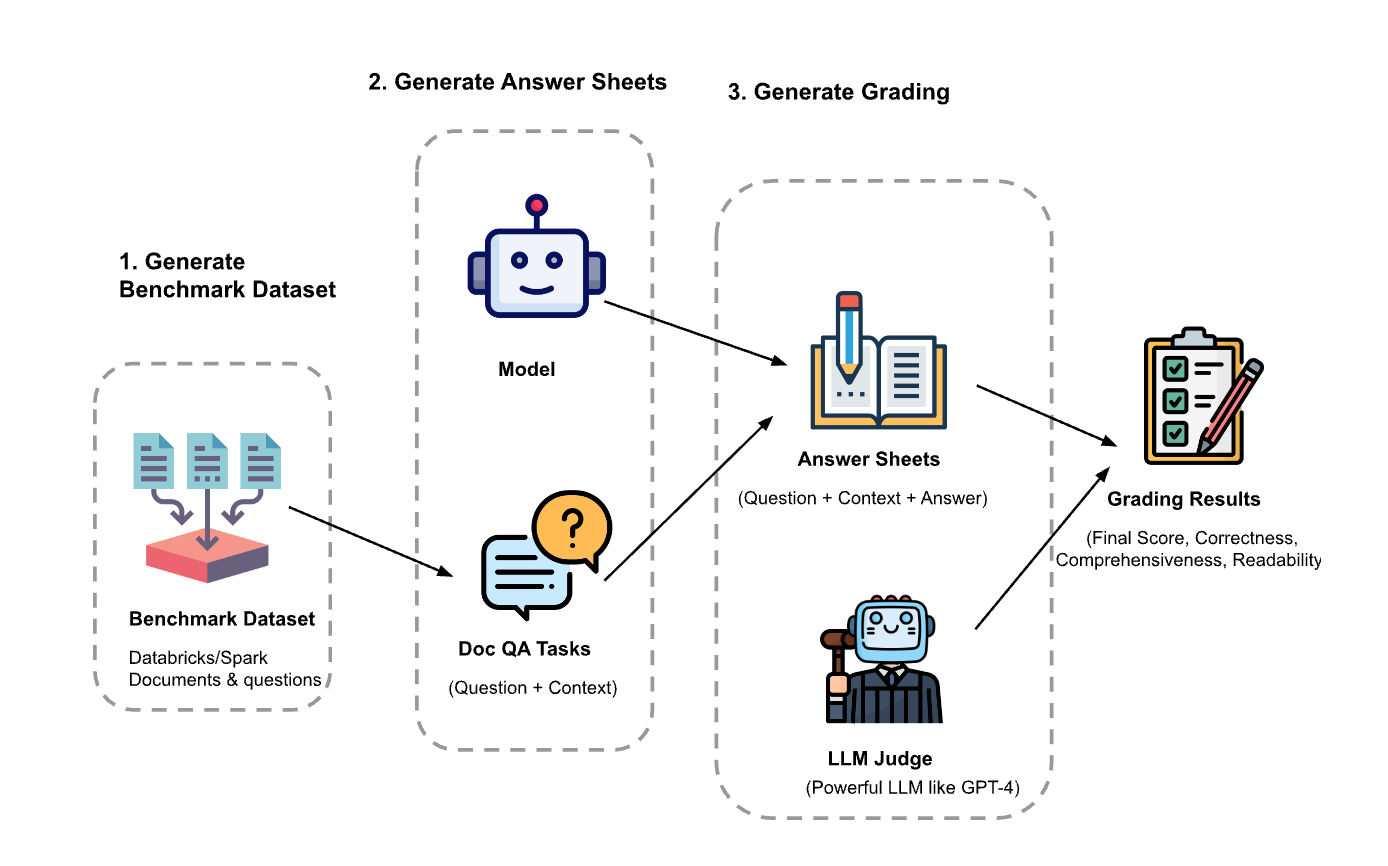
O experimento tinha três passos:
Geração do dataset de avaliação: Criamos um dataset a partir de 100 perguntas e do contexto de documentos da Databricks. O contexto representa (trechos de) documentos que são relevantes para a pergunta.

- Gerar folhas de respostas: Usando o dataset de avaliação, solicitamos a diferentes modelos de linguagem que gerassem respostas e armazenamos os pares de pergunta-contexto-resposta em um dataset chamado “folhas de respostas”. Nesta investigação, usamos GPT-4, GPT-3.5, Claude-v1, Llama2-70b-chat, Vicuna-33b e mpt-30b-chat.
- Geração de notas: Com as folhas de respostas, usamos vários LLMs para gerar notas e as justificativas para elas. As notas são uma pontuação composta de Correção (peso: 60%), Abrangência (peso: 20%) e Legibilidade (peso: 20%). Escolhemos este esquema de ponderação para refletir nossa preferência pela Correção nas respostas geradas. Outras aplicações podem ajustar esses pesos de forma diferente, mas esperamos que a Correção continue sendo um fator dominante.
Além disso, as seguintes técnicas foram usadas para evitar o viés posicional e melhorar a confiabilidade:
- Baixa temperatura (temperatura 0.1) para garantir a reprodutibilidade.
- Avaliação de resposta única em vez de comparação par a par.
- Cadeia de pensamentos para que o LLM raciocine sobre o processo de avaliação antes de atribuir a pontuação final.
- Geração few-shot em que o LLM recebe vários exemplos na rubrica de avaliação para cada valor de pontuação em cada fator (Correção, Abrangência, Legibilidade).
Experimento 1: Alinhamento com a Avaliação Humana
Para confirmar o nível de concordância entre anotadores humanos e juízes de LLM, enviamos folhas de resposta (escala de avaliação de 0 a 3) do gpt-3.5-turbo e do vicuna-33b para uma empresa de rotulagem para coletar rótulos humanos e, em seguida, comparamos o resultado com a saída de avaliação do GPT-4. Abaixo estão os resultados:
Juízes humanos e GPT-4 podem alcançar uma concordância acima de 80% na pontuação de correção e legibilidade. E se diminuirmos o requisito para uma diferença de pontuação menor ou igual a 1, o nível de concordância pode chegar a acima de 95%.
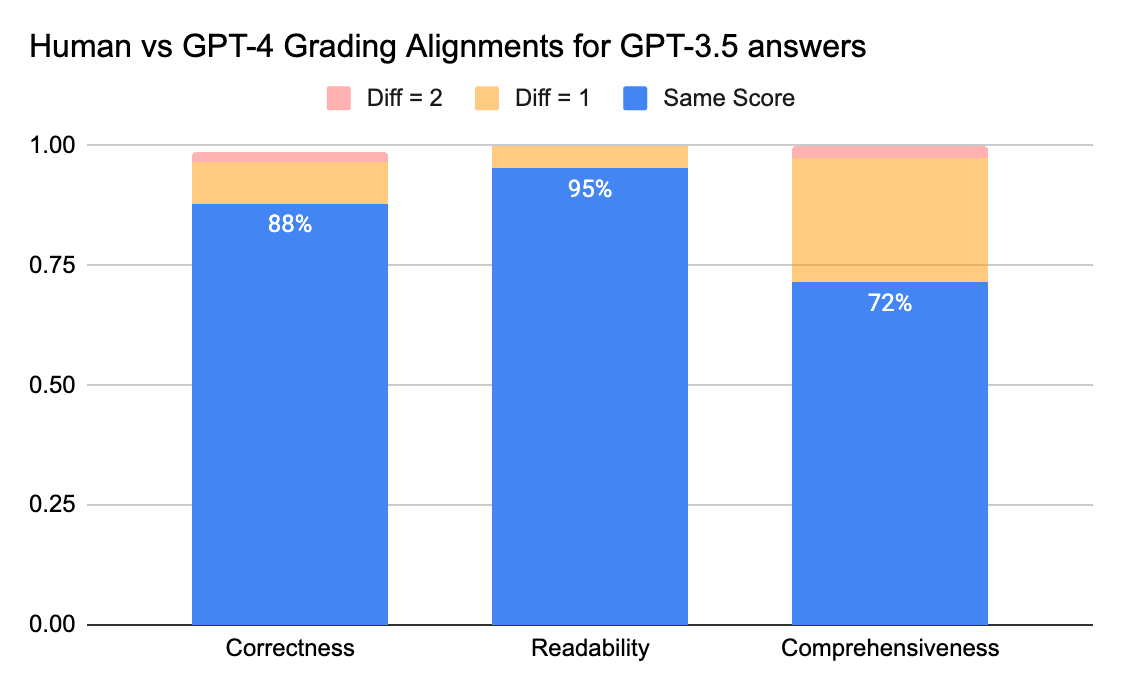
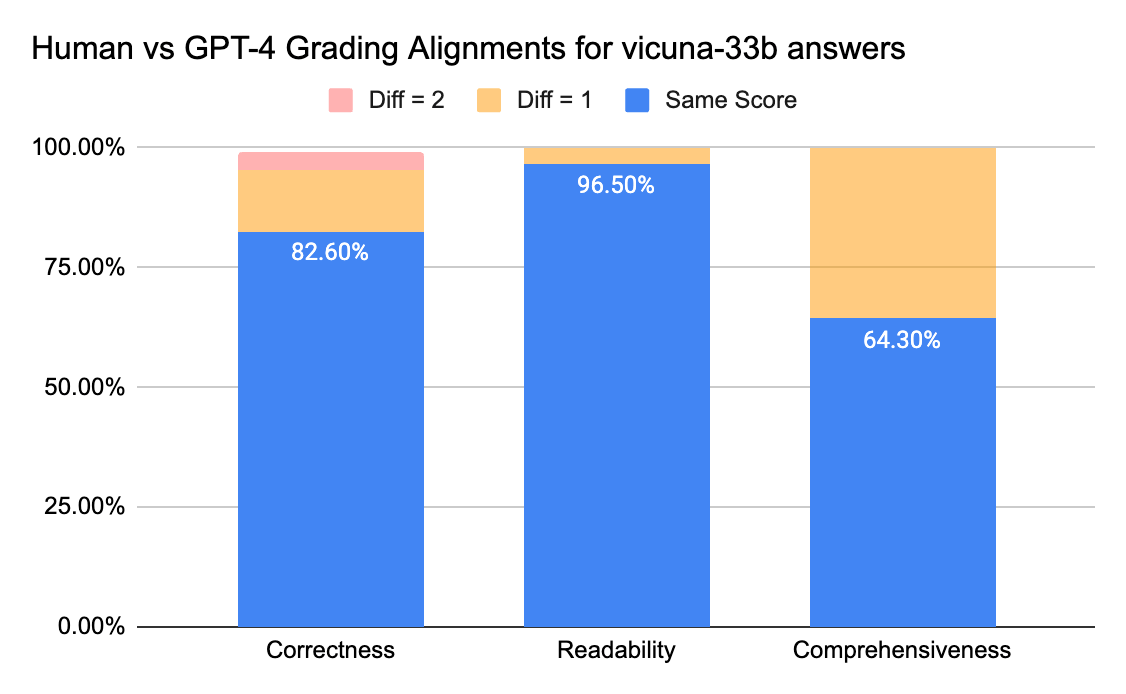
A métrica de Abrangência tem menos alinhamento, o que corresponde ao que ouvimos dos stakeholders de negócios, que compartilharam que “abrangente” parece mais subjetivo do que métricas como Correção ou Legibilidade.
Experimento 2: Acurácia por meio de exemplos
O artigo da lmsys usa este prompt para instruir o juiz LLM a avaliar com base na utilidade, relevância, precisão, profundidade, criatividade e nível de detalhe da resposta. No entanto, o artigo não compartilha detalhes sobre a rubrica de avaliação. Em nossa pesquisa, descobrimos que muitos fatores podem afetar significativamente a pontuação final, por exemplo:
- A importância de diferentes fatores: Utilidade, Relevância, Acurácia, Profundidade, Criatividade
- A interpretação de fatores como Utilidade é ambígua
- Se fatores diferentes conflitarem entre si, onde uma resposta é útil, mas não é precisa
Desenvolvemos uma rubrica para instruir um juiz LLM para uma determinada escala de avaliação, tentando o seguinte:
- Prompt original: Abaixo está o prompt original usado no artigo do lmsys:
|
Adaptamos o prompt original do artigo lmsys para emitir nossas métricas sobre correção, abrangência e legibilidade, e também para solicitar que o juiz forneça uma justificativa de uma linha antes de dar cada pontuação (para se beneficiar do raciocínio em cadeia de pensamento). Abaixo estão a versão zero-shot do prompt, que não fornece nenhum exemplo, e a versão few-shot do prompt, que fornece um exemplo para cada pontuação. Em seguida, usamos as mesmas folhas de respostas como entrada e comparamos os resultados avaliados dos dois tipos de prompt.
- Aprendizagem zero-shot: exige que o LLM avaliador emita nossas métricas sobre correção, abrangência e legibilidade, e também solicita que o avaliador forneça uma justificativa de uma linha para cada pontuação.
- Aprendizado com poucos exemplos: Adaptamos o prompt de zero-shot para fornecer exemplos explícitos para cada pontuação na escala. O novo prompt:
Com este experimento, aprendemos várias coisas:
- Usar o prompt de Few Shots com o GPT-4 não fez uma diferença óbvia na consistência dos resultados. Quando incluímos a rubrica de avaliação detalhada com exemplos, não vimos uma melhoria perceptível nos resultados de avaliação do GPT-4 em diferentes modelos de LLM. Curiosamente, isso causou uma pequena variação no intervalo das pontuações.
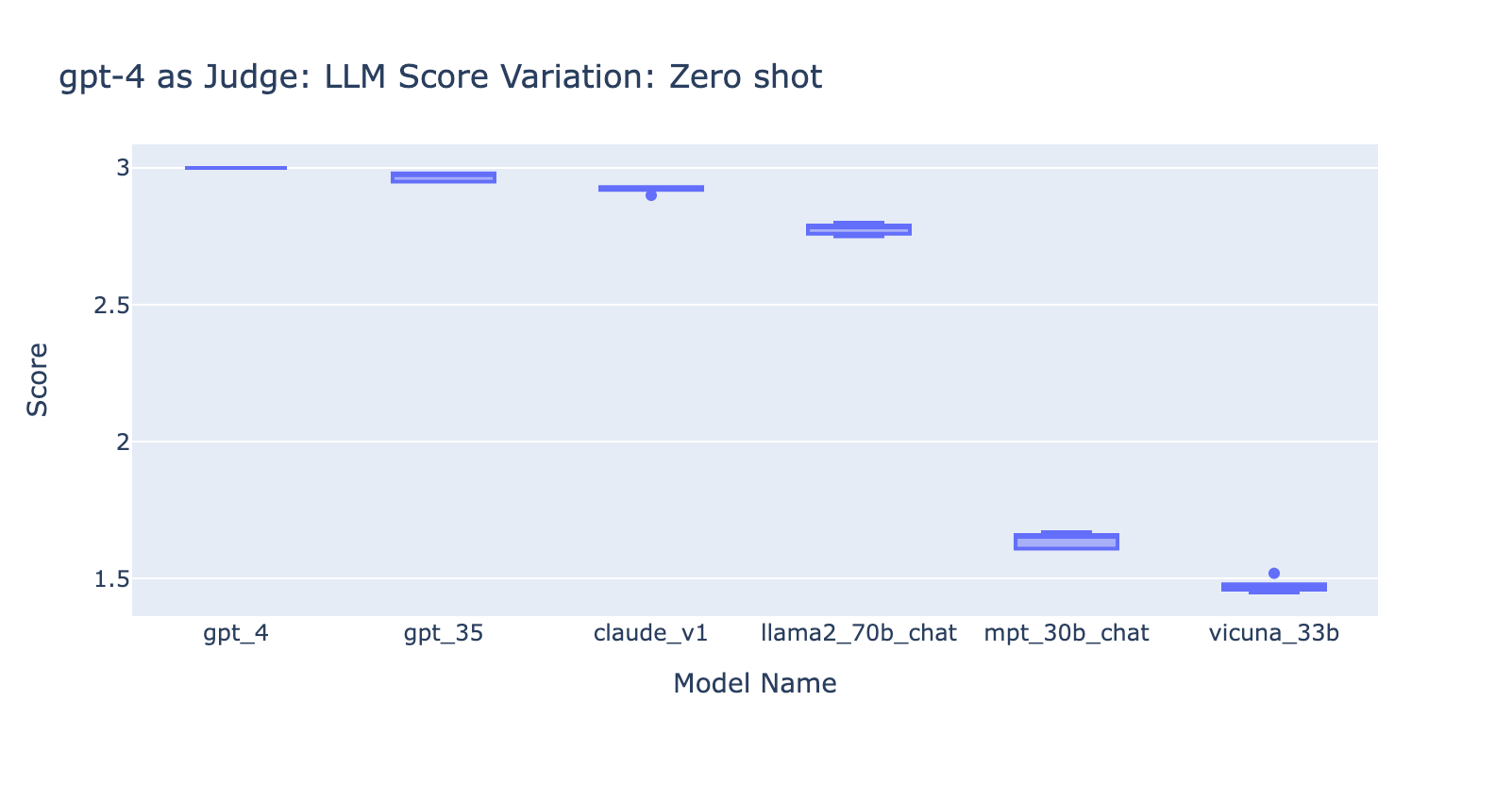
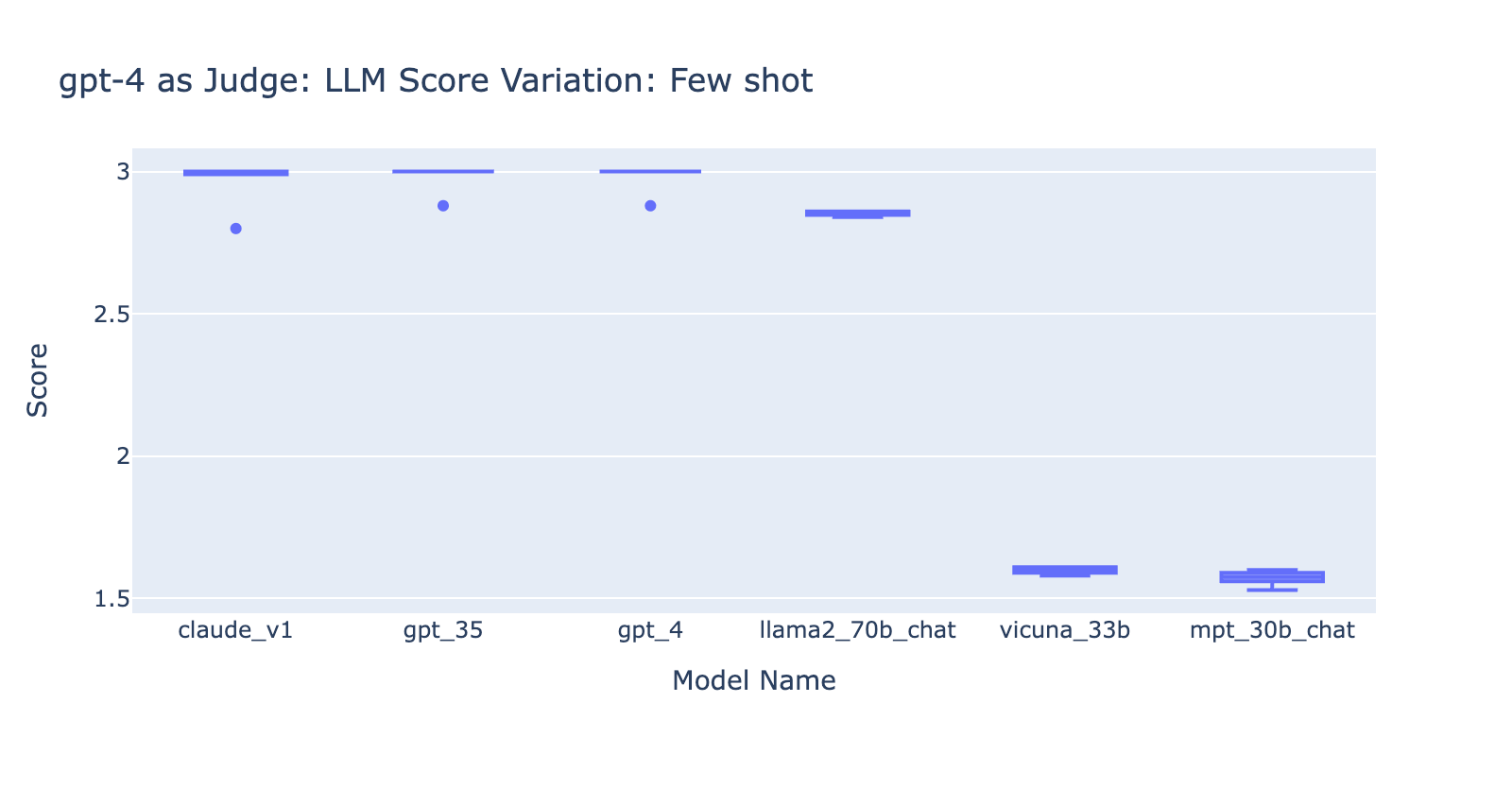
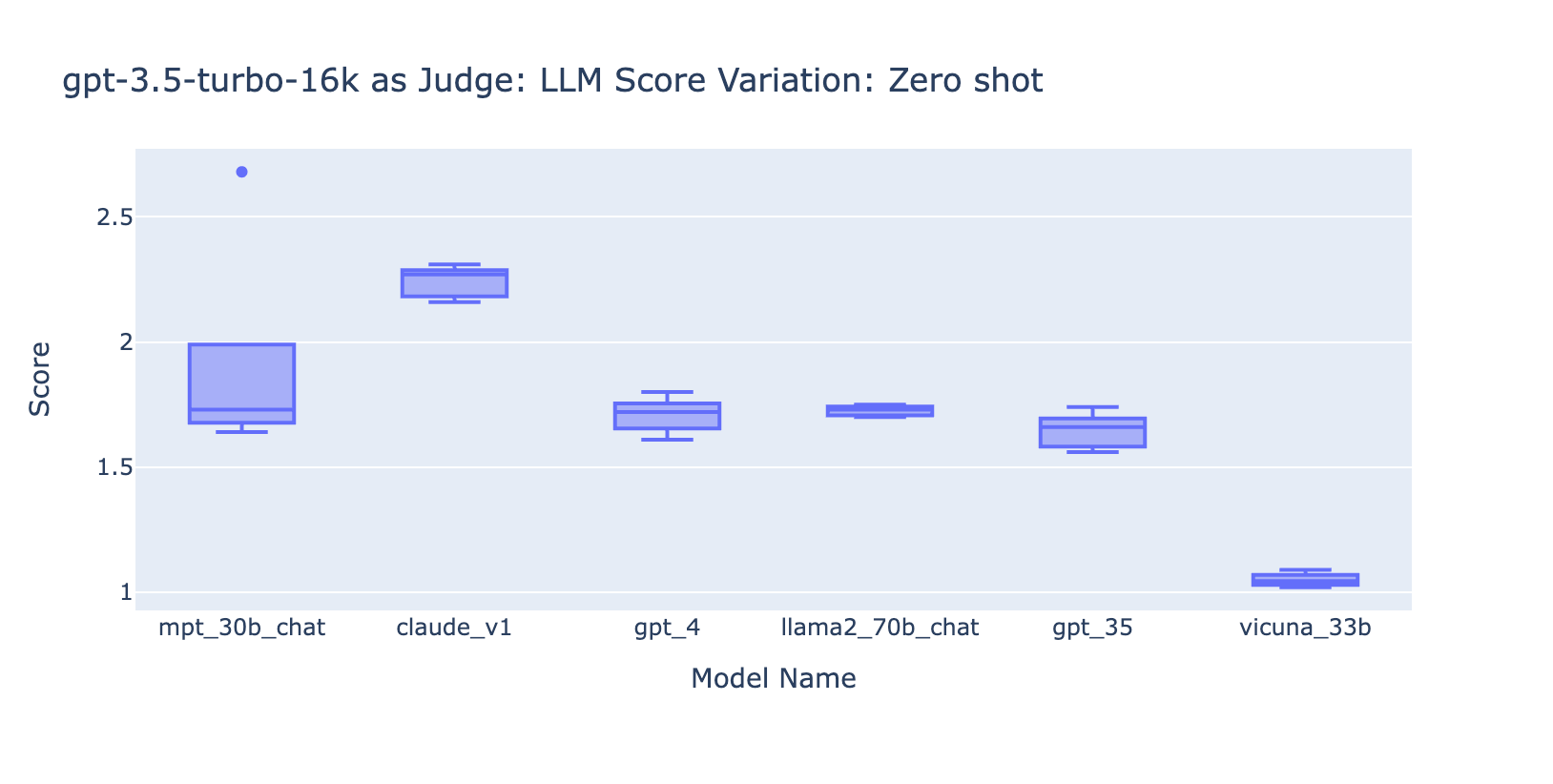
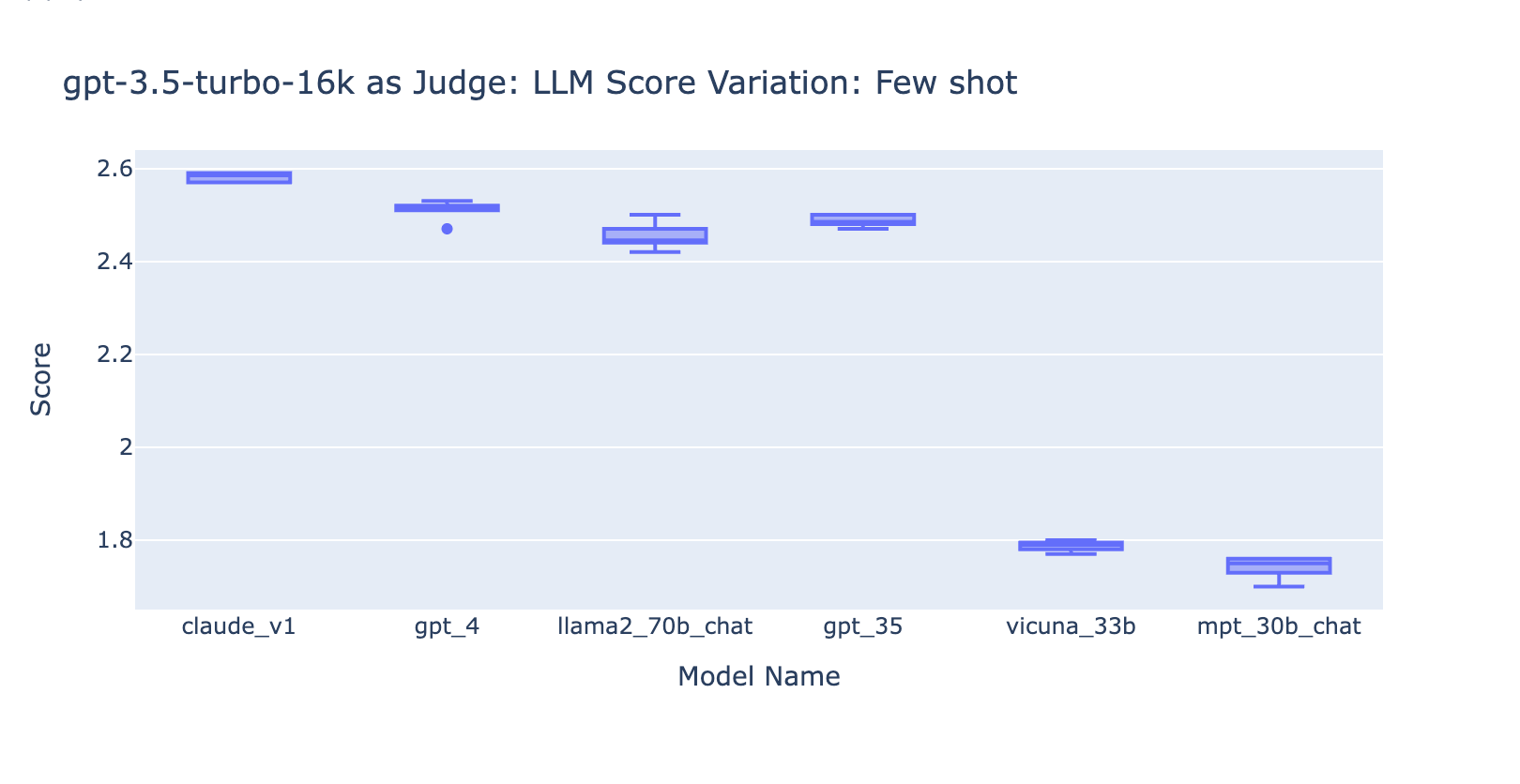
- Incluir alguns exemplos para o GPT-3.5-turbo-16k melhora significativamente a consistência das pontuações e torna o resultado utilizável. A inclusão de uma rubrica/exemplos detalhados de avaliação tem uma melhoria muito óbvia no resultado da avaliação do GPT-3.5 (gráfico à direita). Embora o valor real da pontuação média seja ligeiramente diferente entre o GPT-4 e o GPT-3.5 (pontuação 3.0 vs. 2.6), a classificação e a precisão permanecem razoavelmente consistentes.
- Pelo contrário, (captura de tela à esquerda) o uso do GPT-3.5 sem uma rubrica de avaliação gera resultados muito inconsistentes e é completamente inutilizável.
- Observe que estamos usando o GPT-3.5-turbo-16k em vez de GPT-3.5-turbo já que o prompt pode ser maior que 4k tokens.
Experimento 3: Escalas de notas apropriadas
O artigo LLM-as-judge usa uma escala não inteira de 0 a 10 (ou seja, float) para a escala de avaliação; em outras palavras, ele usa uma rubrica de alta precisão para a pontuação final. Descobrimos que essas escalas de alta precisão causam problemas downstream com o seguinte:
- Consistência: avaliadores, tanto humanos quanto LLM, tiveram dificuldade em manter o mesmo padrão para a mesma pontuação ao avaliar em alta precisão. Como resultado, descobrimos que as pontuações de saída são menos consistentes entre os juízes se você passar de escalas de baixa precisão para escalas de alta precisão.
- Explicabilidade: Além disso, se quisermos fazer a validação cruzada dos resultados avaliados pelo LLM com os resultados avaliados por humanos, devemos fornecer instruções sobre como classificar as respostas. É muito difícil fornecer instruções precisas para cada “pontuação” em uma escala de avaliação de alta precisão. Por exemplo, qual é um bom exemplo de uma resposta com pontuação 5,1 em comparação com 5,6?
Experimentamos várias escalas de avaliação de baixa precisão para fornecer orientação sobre a “melhor” a ser usada e, por fim, recomendamos uma escala de números inteiros de 0 a 3 ou 0 a 4 (se você quiser manter a escala Likert). Testamos as escalas 0-10, 1-5, 0-3 e 0-1 e aprendemos o seguinte:
- A avaliação binária funciona para métricas simples como “usabilidade” ou “bom/ruim”.
- Em escalas como 0-10, é difícil criar critérios de distinção entre todas as pontuações.
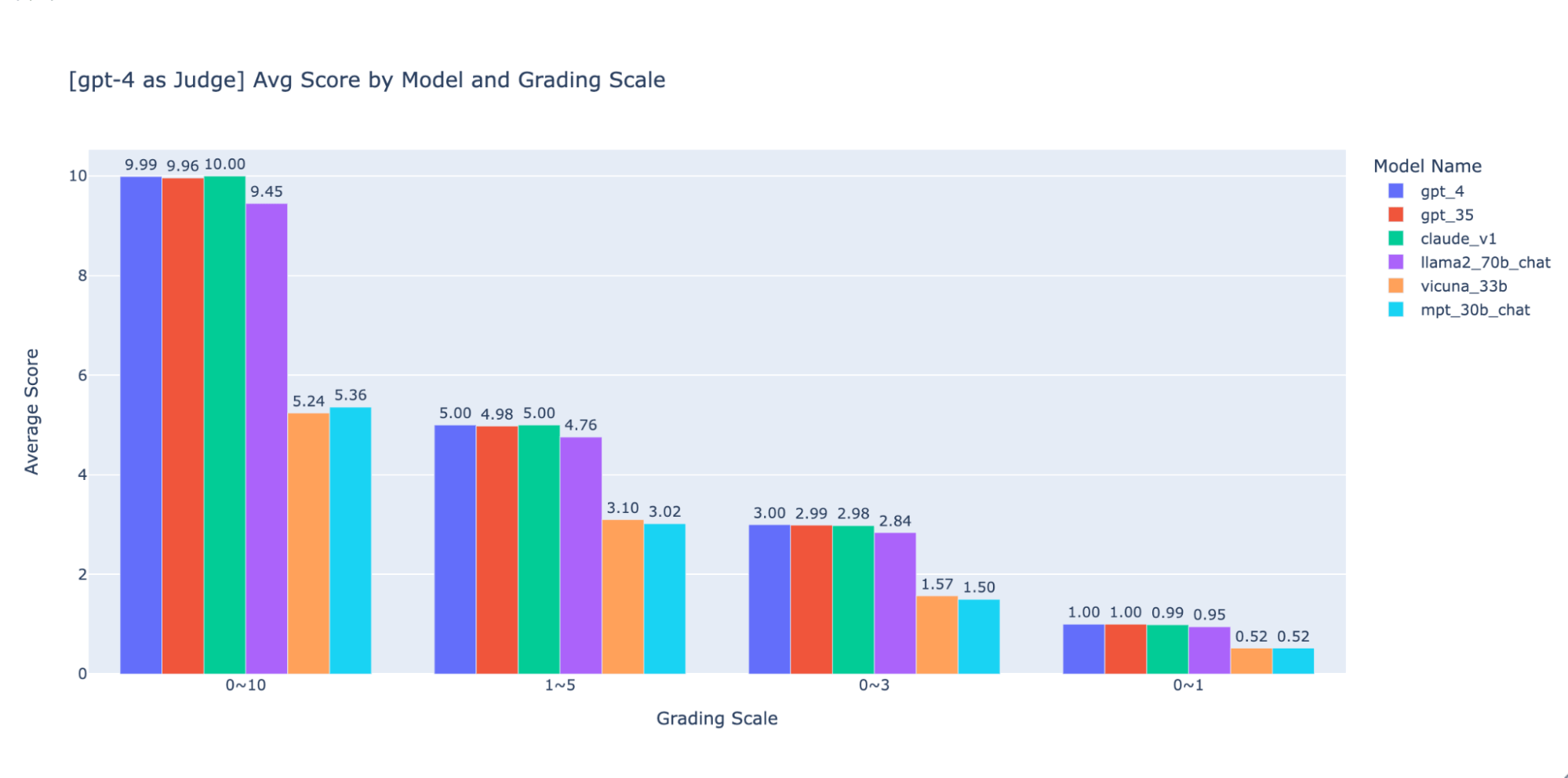
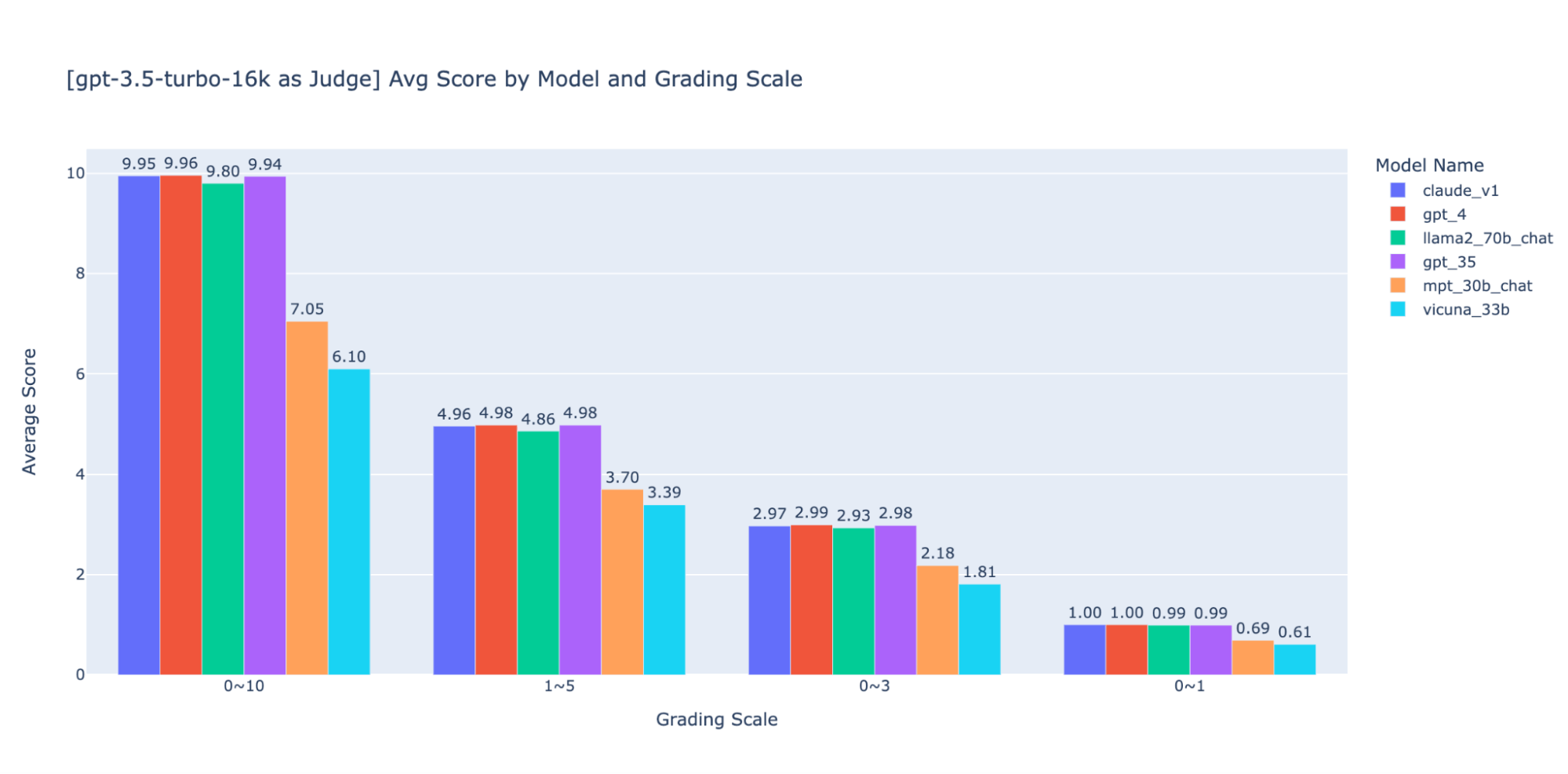
Como mostrado nos gráficos acima, tanto o GPT-4 quanto o GPT-3.5 conseguem manter uma classificação consistente dos resultados usando diferentes escalas de notas de baixa precisão. Portanto, usar uma escala de notas mais baixa, como 0~3 ou 1~5, pode equilibrar a precisão com a explicabilidade)
Portanto, recomendamos 0-3 ou 1-5 como escala de avaliação para facilitar o alinhamento com os rótulos humanos, raciocinar sobre os critérios de pontuação e fornecer exemplos para cada pontuação no intervalo.
Experimento 4: aplicabilidade em diferentes casos de uso
O artigo LLM-as-judge mostra que tanto o julgamento do LLM quanto o humano classificam o modelo Vicuna-13B como um concorrente próximo do GPT-3.5:
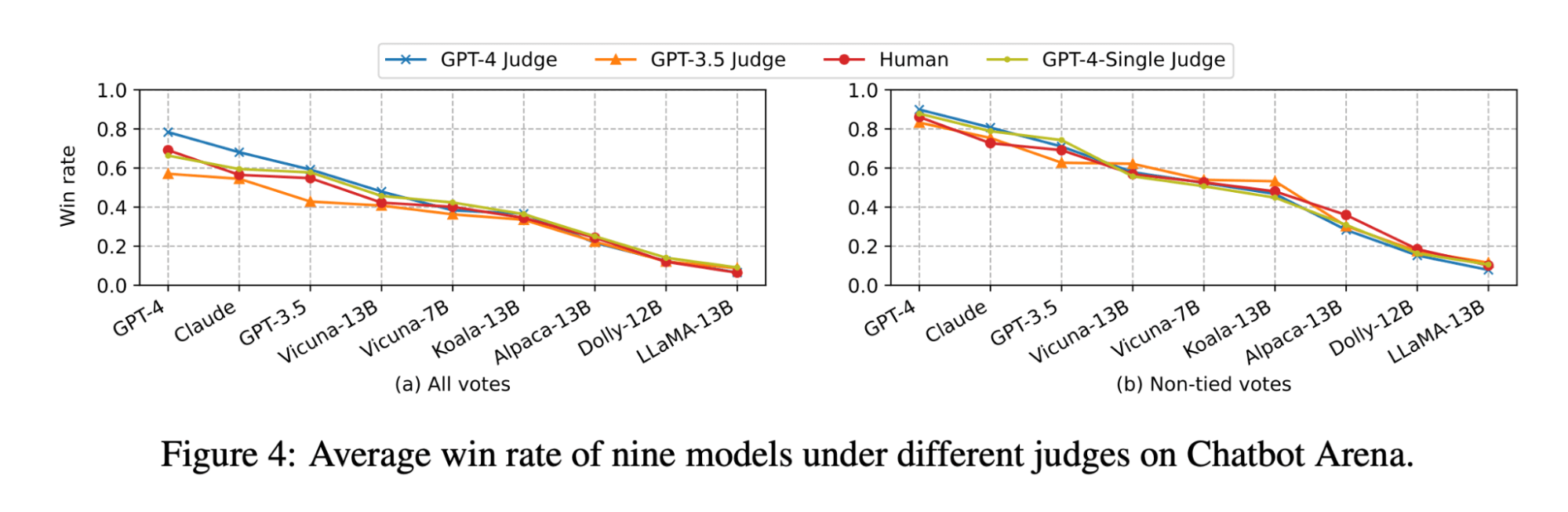
(A figura foi retirada da Figura 4 do artigo LLM-as-judge: https://arxiv.org/pdf/2306.05685.pdf )
No entanto, quando fizemos o benchmark do conjunto de modelos para nossos casos de uso de Q&A em documentos, descobrimos que até mesmo o modelo Vicuna-33B, que é muito maior, tem um desempenho notavelmente pior que o do GPT-3.5 ao responder a perguntas com base no contexto. Esses resultados também são confirmados pelo GPT-4, GPT-3.5 e por avaliadores humanos (conforme mencionado no Experimento 1), que concordam que o Vicuna-33B está tendo um desempenho pior que o GPT-3.5.
Analisamos mais de perto o dataset de benchmark proposto pelo artigo e descobrimos que as 3 categorias de tarefas (escrita, matemática, conhecimento) não refletem ou contribuem diretamente para a capacidade do modelo de sintetizar uma resposta com base em um contexto. Em vez disso, intuitivamente, os casos de uso de Q&A em documentos precisam de benchmarks de compreensão de leitura e de seguimento de instruções. Portanto, os resultados da avaliação não podem ser transferidos entre casos de uso e precisamos criar benchmarks específicos para cada caso de uso para avaliar adequadamente o quão bem um modelo pode atender às necessidades do cliente.
Use o MLflow para aproveitar nossas melhores práticas
Com os experimentos acima, exploramos como diferentes fatores podem afetar significativamente a avaliação de um chatbot e confirmamos que o LLM como juiz pode refletir em grande parte as preferências humanas para o caso de uso de perguntas e respostas sobre documentos. No Databricks, estamos desenvolvendo a API de Avaliação do MLflow para ajudar sua equipe a avaliar com eficácia seus aplicativos de LLM com base nessas descobertas. O MLflow 2.4 introduziu a API de Avaliação para LLMs para comparar lado a lado a saída de texto de vários modelos, o MLflow 2.6 introduziu métricas baseadas em LLM para avaliação, como toxicidade e perplexidade, e estamos trabalhando para oferecer suporte ao LLM-como-juiz em um futuro próximo!
Enquanto isso, compilamos abaixo a lista de recursos que usamos como referência em nossa pesquisa:
- Repository Doc_qa
- O código e os dados que usamos para realizar os experimentos
- Artigo de pesquisa LLM-as-Judge do grupo lmsys
- O artigo é a primeira pesquisa sobre o uso de LLM como avaliador para casos de uso de bate-papo casual e explora extensivamente a viabilidade e os prós e contras do uso de LLM (GPT-4, ClaudeV1, GPT-3.5) como avaliador para tarefas de escrita, matemática e conhecimento de mundo.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.