Acelerando a Inferência de LLM com Cache de Prompt para Modelos Open‑Source no Databricks
Inferência de LLM OSS mais rápida e segura com cache de prompt.
por Pei-Lun Liao, Asfandyar Qureshi, Roshan Regula, Bruce Fontaine, James Thomas e Chenyang Yu
- O cache de prompt reutiliza prefixos de prompt repetidos para que os LLMs rodem mais rápido. Ele reduz a latência e aumenta a taxa de transferência automaticamente.
- O Databricks agora suporta cache de prompt para modelos de código aberto em cargas de trabalho de lote, pagamento por token e provisionadas. Nenhuma configuração é necessária.
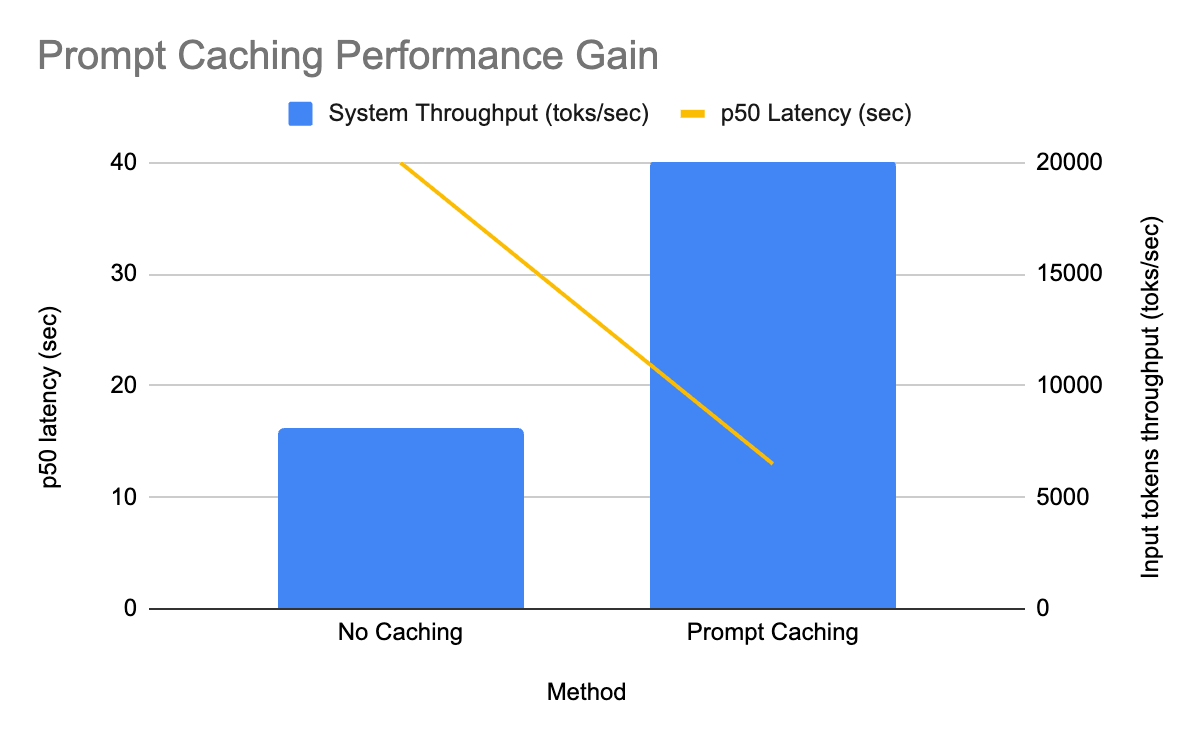
- Em produção no GPT-OSS, o cache de prompt aumentou a taxa de transferência em 2,5x e reduziu a latência P50 em 3x.
Por que o Cache de Prompt é Importante
A inferência de modelo de linguagem grande (LLM) frequentemente envolve prompts repetidos — pense no mesmo prompt de sistema ou instrução aparecendo em milhares de requisições. Reprocessar esse prefixo idêntico para cada chamada desperdiça ciclos de computação, aumenta a latência e eleva os custos.
O cache de prompt elimina essa redundância, proporcionando:
- Menor latência – o estágio de preenchimento pode ser pulado quando o cache é atingido.
- Maior taxa de transferência – mais tokens são processados por unidade de modelo.
O cache de prompt pode ser uma técnica poderosa para aumentar a qualidade de um modelo em domínios específicos sem comprometer a taxa de transferência de tokens do modelo. Consultas podem compartilhar um prompt de sistema grande e específico do domínio, com o custo de computação desse prompt compartilhado amortizado em todas essas consultas. Modelos de ponta, como Claude, usam prompts de sistema que têm muitos milhares de tokens de comprimento internamente. Além disso, em nossa pesquisa publicada recentemente, mostramos que a otimização automatizada de prompts permite que modelos de código aberto superem a qualidade de modelos de ponta para tarefas empresariais.
Disponibilidade de recursos
O Databricks já oferece cache de prompt integrado para modelos proprietários (GPT, Gemini, Claude). Agora, estendemos essa capacidade aos modelos de pesos abertos que alimentam nossas APIs de Modelo de Fundação (FMAPIs) para inferência em lote, pagamento por token e cargas de trabalho de taxa de transferência provisionada. Isso também se aplica a todos os serviços de nível superior alimentados por um modelo de fundação, por exemplo, Agent Bricks, Genie, Funções de IA.
O cache de prompt agora é suportado para os seguintes modelos OSS hospedados no Databricks:
- GPT‑OSS 20B e 120B
- Gemma 3 12B
- Llama 3.1 8B ajustado (via PEFT serving)
- Llama 3.1 8B e 3.3 70B
Continuaremos a implementar este recurso em nossos outros modelos. A segurança é uma preocupação de primeira classe no Databricks. Os caches de prompt são isolados, residem apenas em memória volátil e nunca são persistidos. Importante, o cache é implícito: os clientes não precisam configurar nada, nosso sistema foi construído para executar automaticamente o cache e o reuso de prompt para melhorar a taxa de transferência.
Impacto no Mundo Real: inferência em lote no GPT OSS
Implementamos o cache de prompt em nossos modelos GPT‑OSS primeiro e imediatamente vimos ganhos mensuráveis em um dos pipelines de inferência em lote de produção em larga escala:
- A taxa de transferência de tokens de entrada por réplica aumentou 2,5x
- A latência P50 foi reduzida em 3x
- Tudo isso com uma taxa de acerto de cache relativamente baixa de 30%
Conclusão
Ao reutilizar automaticamente caches de KV para prompts idênticos, o Databricks permite que você execute LLMs de código aberto de forma mais rápida, econômica e com maior segurança — tudo sem exigir nenhuma configuração adicional. Se você está servindo chat em tempo real, processando em lote grandes coleções de documentos ou construindo agentes de IA, o cache de prompt pode transformar um bom pipeline de inferência em um ótimo. Experimente em sua próxima implantação de modelo OSS e observe as métricas de desempenho subirem.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.