Construção de Agentes Empresariais de última geração 90x mais baratos com a Otimização Automática de Solicitações
por Arnav Singhvi, Ivan Zhou, Erich Elsen, Krista Opsahl-Ong, Michael Bendersky, Matei Zaharia, Xing Chen, Omar Khattab, Xiangrui Meng e Simon Favreau-Lessard
Databricks Agent Bricks é uma plataforma para construir, avaliar, e implantar agentes de IA de nível de produção para fluxos de trabalho empresariais. Nosso objetivo é ajudar os clientes a alcançar o equilíbrio ótimo de qualidade-custo na fronteira de Pareto para suas tarefas específicas do domínio e melhorar continuamente seus agentes que raciocinam com seus próprios dados. Para apoiar isso, desenvolvemos benchmarks centrados na empresa e realizamos avaliações empíricas em agentes que medem precisão e eficiência de atendimento, refletindo os verdadeiros equilíbrios que as empresas enfrentam na produção.
Dentro de nosso amplo conjunto de ferramentas de otimização de agentes, este post se concentra na otimização automatizada de prompts, uma técnica que utiliza pesquisa iterativa e estruturada orientada por sinais de feedback da avaliação para melhorar automaticamente os prompts. Demonstramos como podemos:
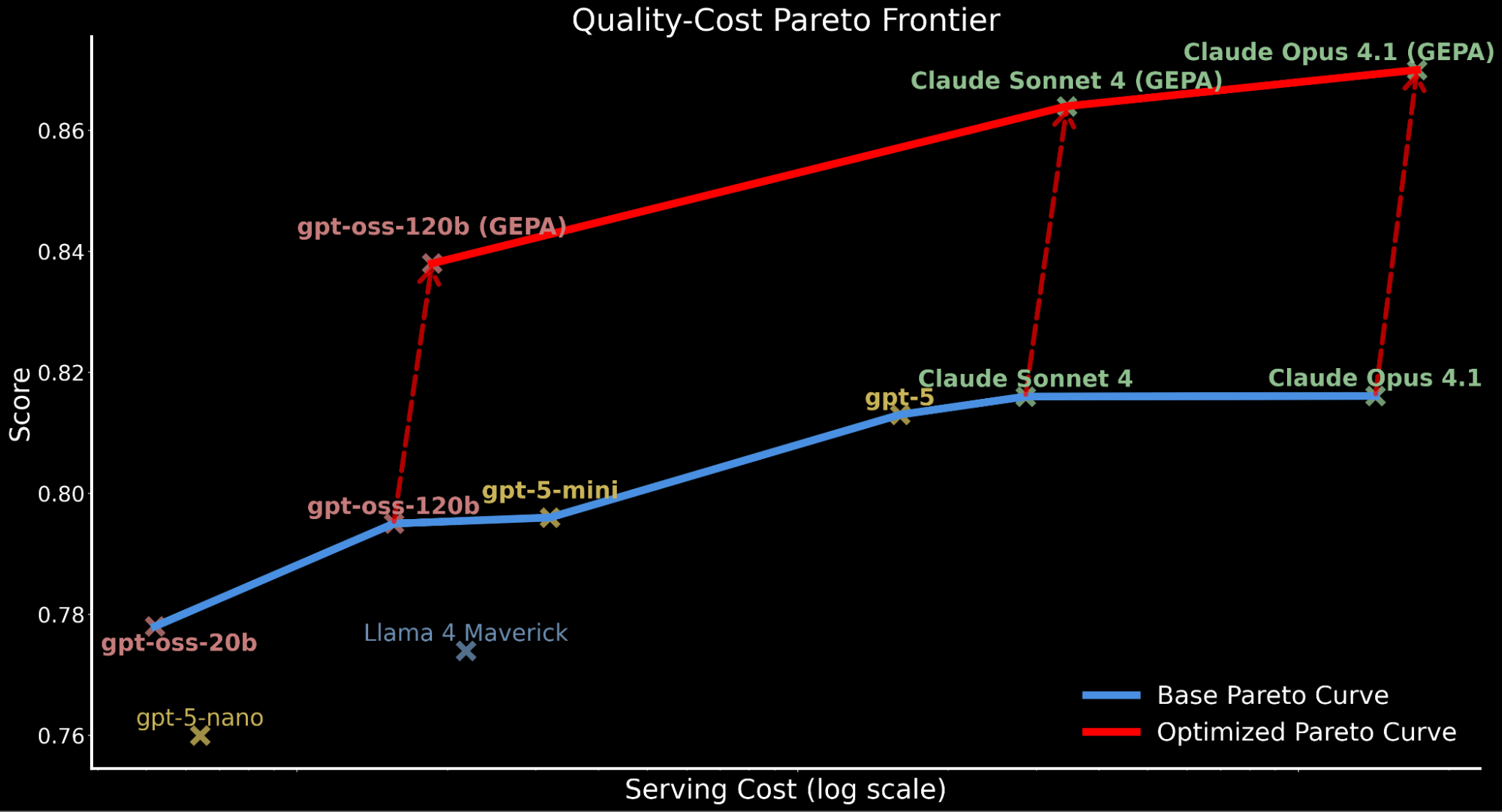
- Permitir que modelos de código aberto ultrapassem a qualidade dos modelos de fronteira para tarefas corporativas: utilizando GEPA, uma técnica de otimização de prompts recém-lançada resultante da pesquisa Databricks e UC Berkeley, apresentamos como o gpt-oss-120b supera os modelos proprietários de última geração Claude Sonnet 4 e Claude Opus 4.1 em ~3% enquanto é aproximadamente 20x e 90x mais barato para servir, respectivamente (veja o gráfico de fronteira de Pareto abaixo).
- Elevar ainda mais os modelos proprietários de fronteira: aplicamos a mesma abordagem aos principais modelos proprietários, aumentando a performance base do Claude Opus 4.1 e Claude Sonnet 4 em 6-7% , alcançando um novo desempenho de última geração.
- Oferecer uma relação superior de qualidade-custo em comparação com o SFT: a otimização automática de prompts oferece um desempenho equiparável, ou melhor, do que o ajuste fino supervisionado (SFT), ao mesmo tempo que reduz os custos de serviço em 20%. Também mostramos que a otimização de prompts e o SFT podem trabalhar juntos para melhorar ainda mais o desempenho.
Nas seções que seguem, abordaremos
- como avaliamos o desempenho do agente IA na extração de informações como um caso de uso principal e por que isso importa para os fluxos de trabalho empresariais;
- uma visão geral de como a otimização de promp funciona, os tipos de benefícios que ela pode desbloquear, especialmente em cenários onde a sintonização fina não é prática, e ganhos de desempenho em nossa pipeline de avaliação;
- para contextualizar esses ganhos, mediremos o impacto da otimização de prompts e analisaremos a economia por trás dessas técnicas;
- Comparação de desempenho com fine-tuning supervisionado (SFT), destacando o tradeoff superior de qualidade-custo através da otimização de prompts;
- considerações finais e próximos passos, especialmente como você pode começar a aplicar estas técnicas diretamente com Databricks Agent Bricks para construir os melhores agentes de IA voltados para implantação empresarial real.
Avaliação das LLMs mais recentes no IE Bench
Extração de Informações (IE) é um recurso central do Agent Bricks, convertendo fontes não estruturadas como PDFs ou documentos digitalizados em registros estruturados. Apesar do rápido progresso nas capacidades de IA gerativa, IE permanece difícil em escala empresarial:
- Documentos são extensos e cheios de jargão específico do domínio
- Os esquemas são complexos, hierárquicos e contêm ambiguidades
- Etiquetas são frequentemente ruidosas e inconsistentes
- A tolerância operacional para erro na extração é baixa
- Requisito de alta confiabilidade e eficiência de custos para grandes cargas de trabalho de inferência
Como resultado, observamos que o desempenho pode variar amplamente por domínio e complexidade da tarefa, portanto, construir os sistemas certos de IA composta para IE em diferentes casos de uso requer uma avaliação minuciosa das diferentes capacidades do agente de IA.
Para explorar isso, desenvolvemos IE Bench, uma suíte de avaliação abrangente que abrange vários domínios empresariais do mundo real como finanças, jurídico, comércio e saúde. O benchmark reflete desafios complexos do mundo real, incluindo documentos que ultrapassam 100 páginas, abrangendo entidades de extração com mais de 70 campos e esquemas hierárquicos com vários níveis aninhados. Relatamos avaliações no conjunto de teste retido do benchmark para fornecer uma medida confiável de desempenho no mundo real.
Nós benchmarked a última geração de modelos de código aberto servidos via Databricks Foundation Models API, incluindo o novo lançamento da série gpt-oss, bem como os principais modelos proprietários de vários fornecedores, incluindo a última família GPT-5.1
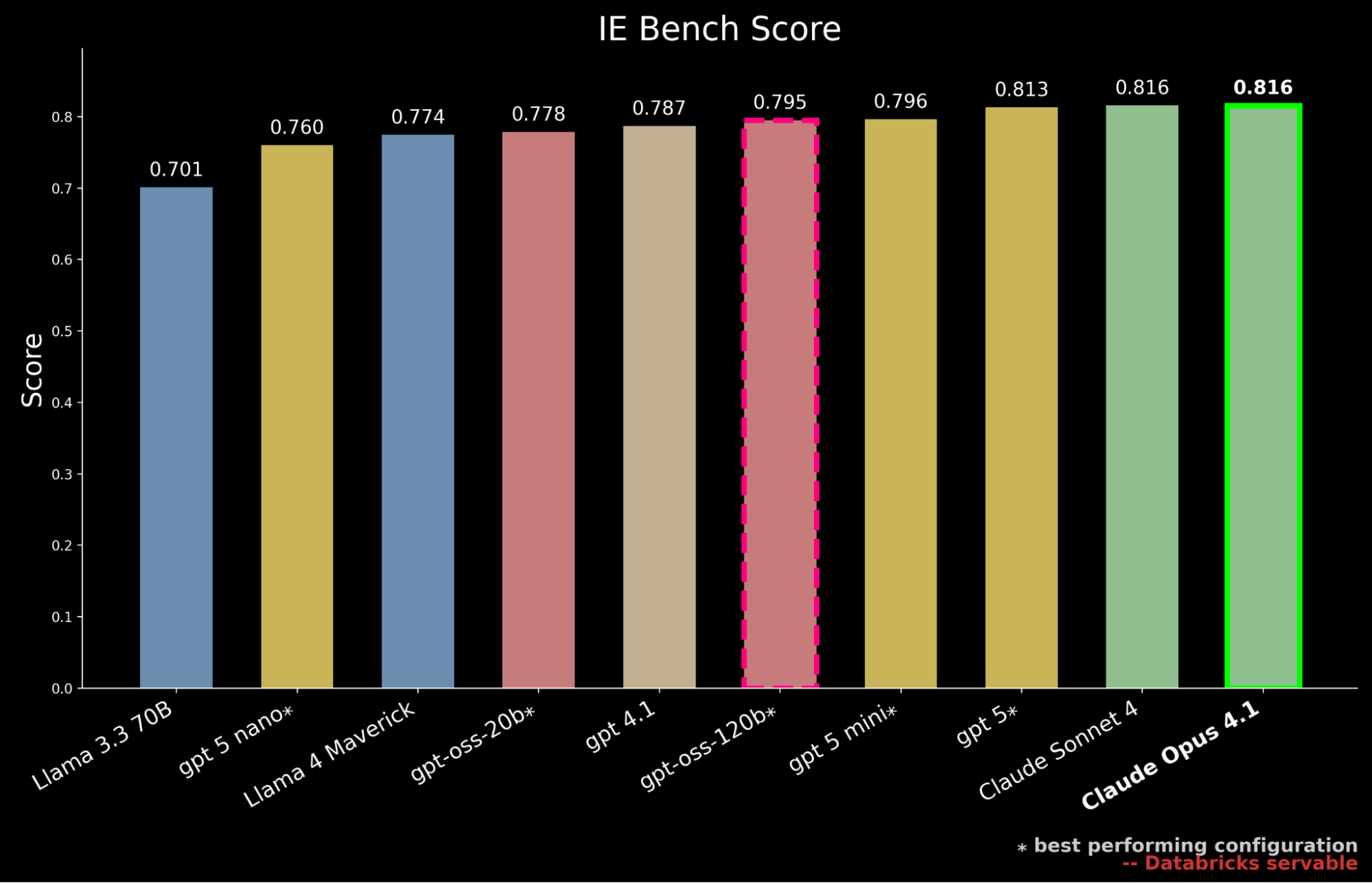
Nossos resultados mostram que o gpt-oss-120b é o modelo de código aberto de melhor desempenho no IE Bench, superando a performance anterior do estado da arte de código aberto do Llama 4 Maverick por ~3% enquanto se aproxima do nível de desempenho do gpt-5-mini, marcando um avanço significativo para os modelos de código aberto. No entanto, ainda fica atrás do desempenho do modelo de fronteira proprietário, ficando atrás de gpt-5, Claude Sonnet 4 e Claude Opus 4.1—que alcançam a pontuação mais alta no benchmark.
No entanto, em ambientes corporativos, o desempenho também deve ser ponderado contra o custo de servir. Contextualizamos ainda mais nossas descobertas anteriores, destacando que o gpt-oss-120b atinge o desempenho do gpt-5-mini enquanto custa aproximadamente 50% do custo de serviço. 2 Os modelos de fronteira proprietários são em grande parte mais caros, com o gpt-5 custando ~10x o custo de servir do gpt-oss-120b, Claude Sonnet 4 at ~20x e Claude Opus 4.1 at ~90x.
Para ilustrar a relação custo-benefício entre os modelos, plotamos a fronteira de Pareto abaixo, mostrando o desempenho baseline de todos os modelos antes de qualquer melhoria.
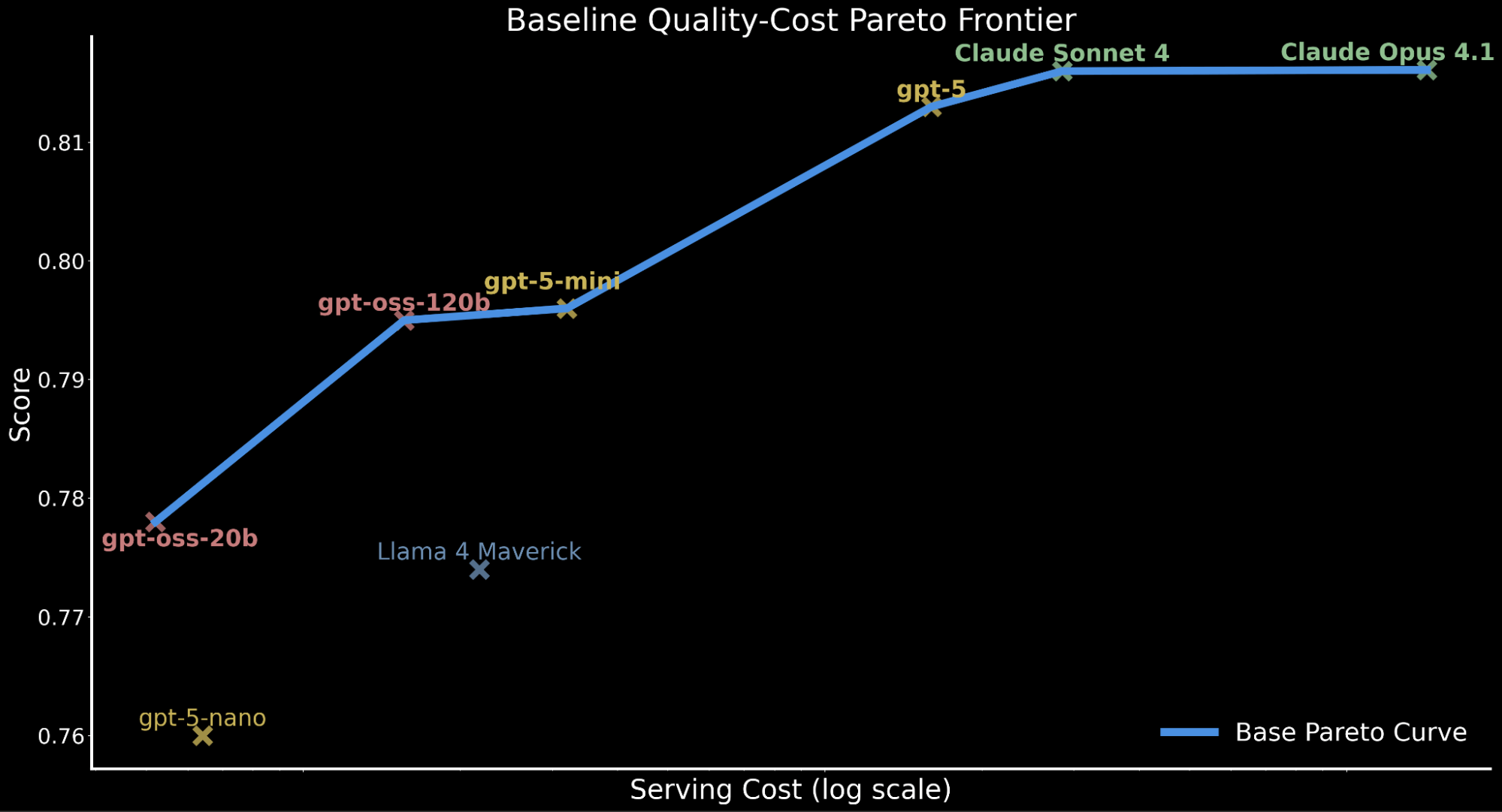
Esta relação custo-benefício tem grandes implicações para cargas de trabalho empresariais que necessitam de inferência em grande escala que devem considerar orçamento de computação e taxa de serviço, enquanto mantém a precisão performática.
Isso motiva nossa exploração: podemos elevar o gpt-oss-120b à qualidade de ponta mantendo sua eficiência de custo? Se sim, isso proporcionaria um desempenho líder na fronteira de Pareto de custo-qualidade, sendo possível para adoção empresarial na Databricks.
Otimizando modelos de código aberto para superar o desempenho de modelos de fronteira
Exploramos a otimização do prompt como um método sistemático para melhorar o desempenho do modelo. A engenharia de prompts manual pode proporcionar ganhos, mas geralmente depende de expertise no domínio e experimentação com tentativa e erro. Esta complexidade cresce ainda mais em sistemas de IA compostos que integram múltiplas chamadas LLM e ferramentas externas que devem ser otimizadas juntas, tornando a afinação manual do prompt impraticável para escalar ou manter em pipelines de produção.
A otimização de solicitações oferece uma abordagem diferente, aproveitando a busca estruturada orientada por sinais de feedback para melhorar automaticamente as solicitações. Esses otimizadores são agnósticos ao pipeline e são capazes de otimizar conjuntamente várias solicitações interdependentes em pipelines de múltiplas etapas, tornando essas técnicas robustas e adaptáveis em sistemas de IA compostos e tarefas diversas.
Para testar isso, aplicamos algoritmos de otimização de prompts automatizados, especificamente MIPROv2, SIMBA e GEPA, um novo otimizador de prompts oriundo de pesquisas da Databricks e UC Berkeley que combina reflexão baseada em linguagem com busca evolutiva para melhorar os sistemas de IA. Aplicamos esses algoritmos para avaliar como a otimização de prompts pode diminuir a lacuna entre o modelo de código aberto de melhor desempenho, gpt-oss-120b, e os modelos de fronteira de código fechado de última geração.
Consideramos as seguintes configurações de otimizadores de prompts automáticos em nossa exploração
Cada técnica de otimização do prompt depende de um modelo otimizador para refinar diferentes aspectos do prompt para um modelo alvo. Dependendo do algoritmo, o modelo otimizador pode gerar exemplos de few-shot a partir de rastros inicializados para aplicar aprendizado no contexto e/ou propor e melhorar as instruções da tarefa através de algoritmos de busca que realizam reflexão iterativa usando feedback para mutar e selecionar melhores prompts em todos os testes de otimização. Essas percepções são destiladas em prompts melhorados para o modelo alvo usar durante a inferência no momento do serviço. Embora o mesmo LLM possa ser usado para ambos os papéis, também experimentamos o uso de um "modelo de desempenho superior" como o modelo otimizador para explorar se a orientação de maior qualidade pode impulsionar ainda mais o desempenho do modelo aluno.
Construindo com base em nossas descobertas anteriores do gpt-oss-120b como o principal modelo de código aberto no IE Bench, consideramos isso como nossa base de modelo estudante para explorar melhorias adicionais.
Ao otimizar o gpt-oss-120b, consideramos duas configurações:
- gpt-oss-120b (optimizer) → gpt-oss-120b (estudante)
- Claude Sonnet 4 (otimizador) → gpt-oss-120b (estudante)
Uma vez que Claude Sonnet 4 alcança um desempenho líder no IE Bench sobre o gpt-oss-120b, e é relativamente mais barato em comparação com o Claude Opus 4.1 com desempenho semelhante, exploramos a hipótese de se a aplicação de um modelo de otimizador mais forte pode produzir um melhor desempenho para o gpt-oss-120b.
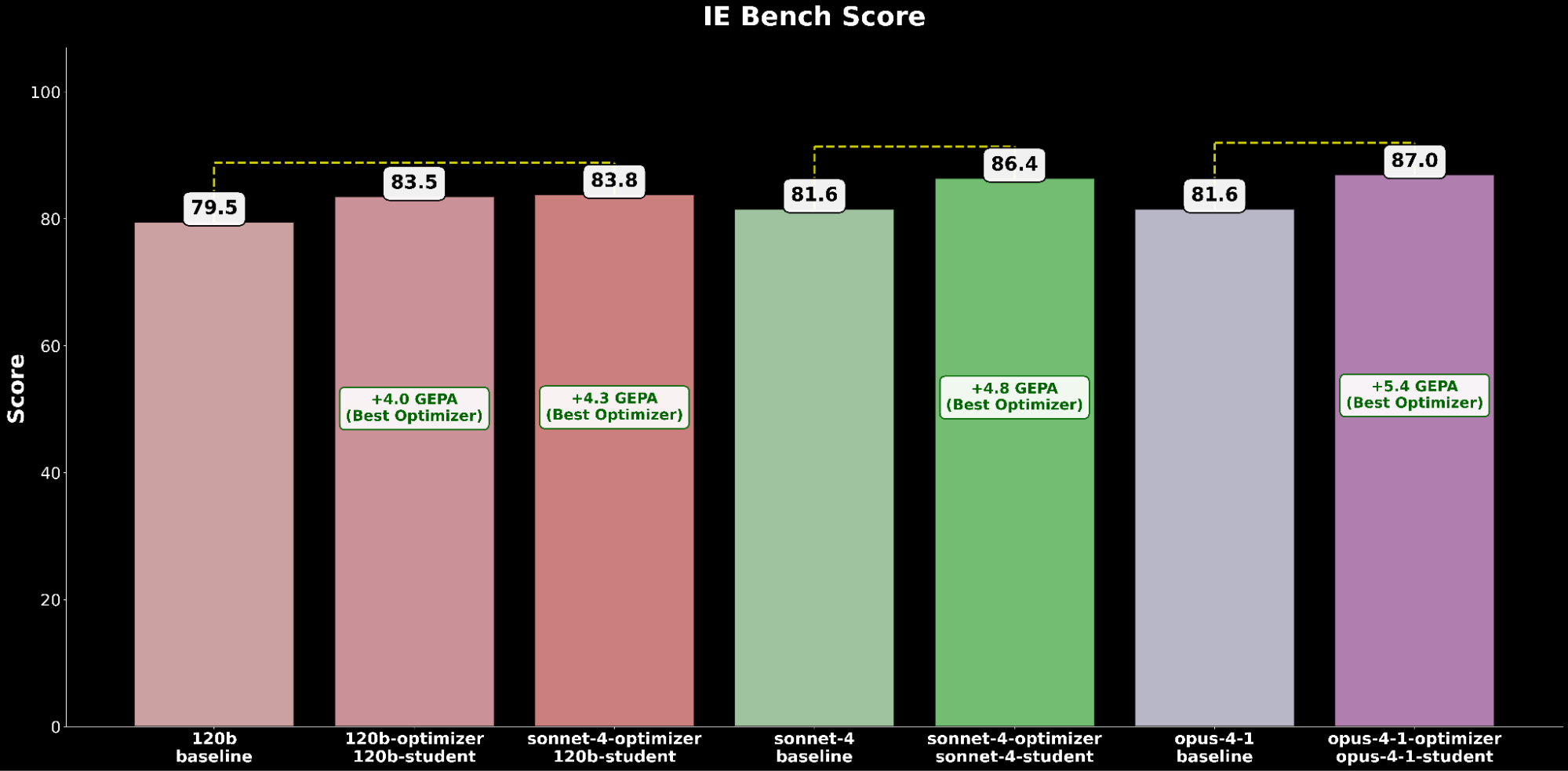
Avaliamos cada configuração entre as técnicas de otimização e comparamos com a linha de base respectiva do gpt-oss-120b:
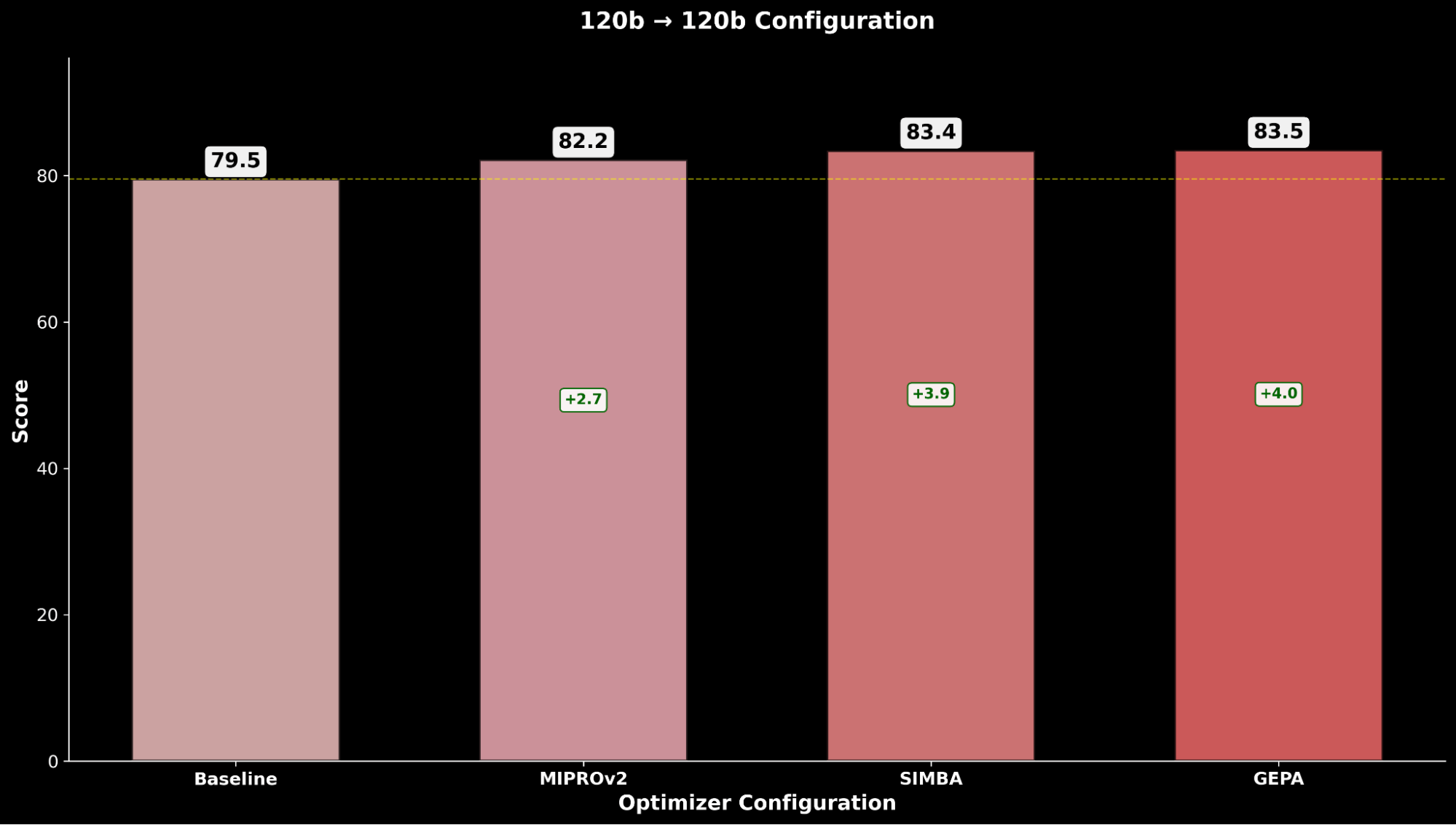
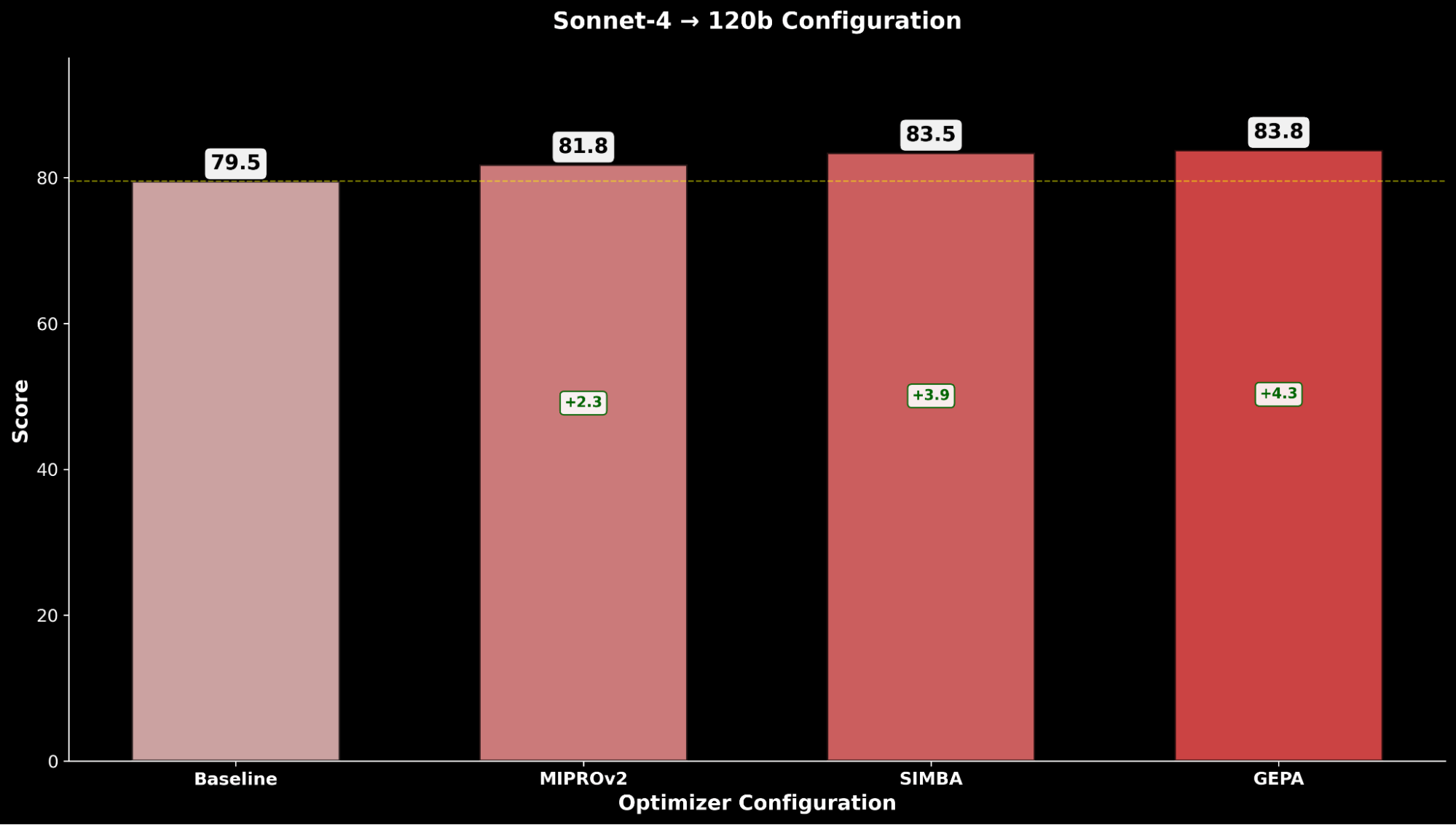
Através do IE Bench, descobrimos que a otimização do gpt-oss-120b com o Claude Sonnet 4 como modelo otimizador alcança a maior melhoria sobre o desempenho da linha de base do gpt-oss-120b, com uma melhoria significativa de +4,3 pontos sobre a linha de base e uma melhoria de +0,3 pontos sobre a otimização do gpt-oss-120b com o próprio como modelo otimizador, destacando a elevação através do uso de um modelo otimizador mais forte.
Comparamos a melhor configuração do gpt-oss-120b otimizada pelo GEPA contra os modelos de fronteira do Claude:
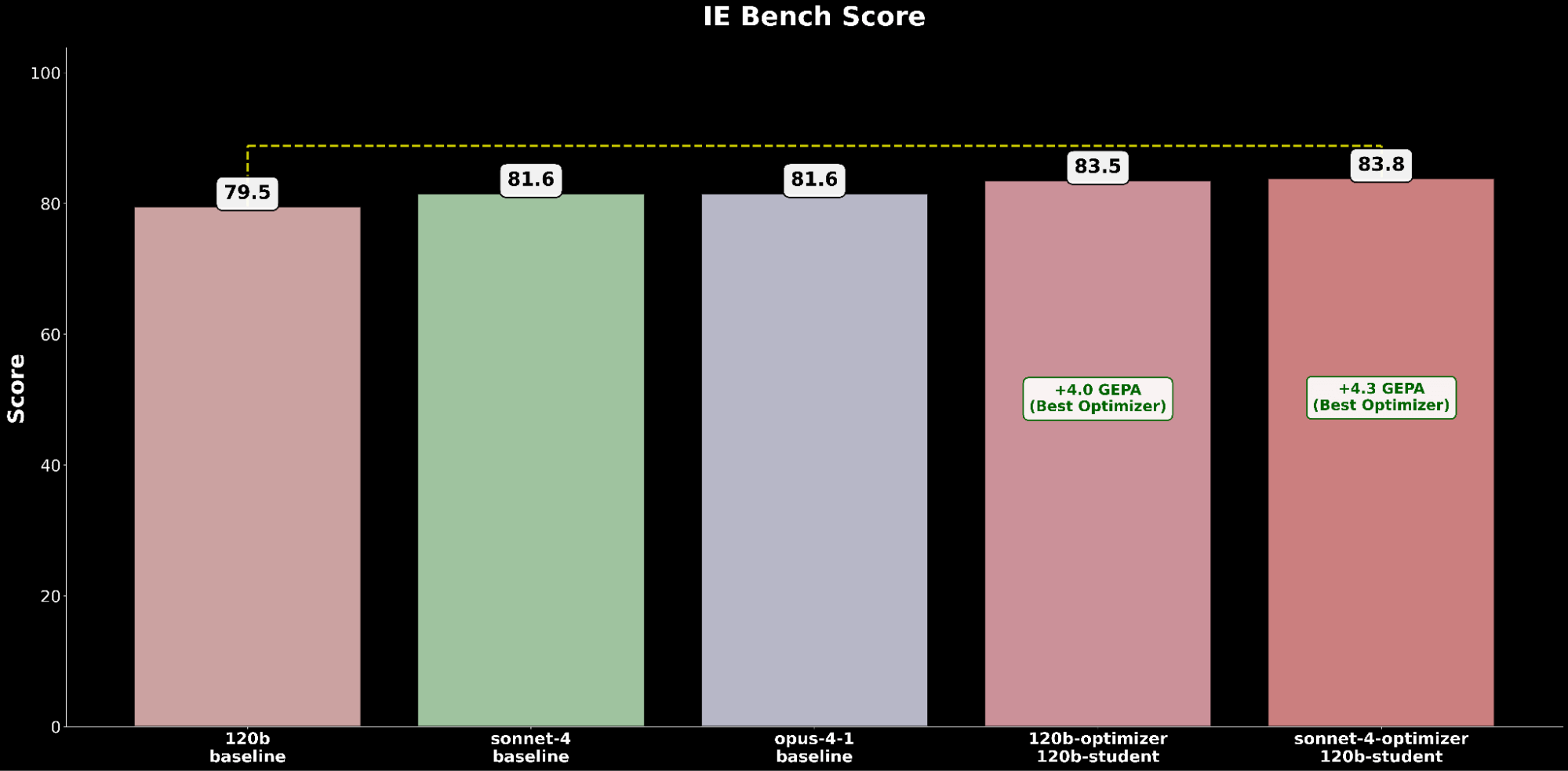
A configuração otimizada do gpt-oss-120b supera o desempenho baseline de ponta do Claude Opus 4.1 com um ganho absoluto de +2,2, destacando os benefícios da otimização automática de prompts para elevar um modelo de código aberto para superar modelos proprietários de liderança em capacidades de IE.
Otimizar modelos de fronteira para aumentar ainda mais o teto de desempenho
À medida que vemos a importância da otimização automatizada de prompts, exploramos se a aplicação do mesmo princípio aos principais modelos de fronteira Claude Sonnet 4 e Claude Opus 4.1 pode impulsionar ainda mais a fronteira de desempenho alcançável para o IE Bench.
Ao otimizar cada modelo proprietário, consideramos as seguintes configurações:
- Claude Sonnet 4 (otimizador) → Claude Sonnet 4 (aluno)
- Claude Opus 4.1 (otimizador) → Claude Opus 4.1 (aprendiz)
Escolhemos considerar as configurações padrão do modelo otimizador, pois esses modelos já definem a fronteira de desempenho.
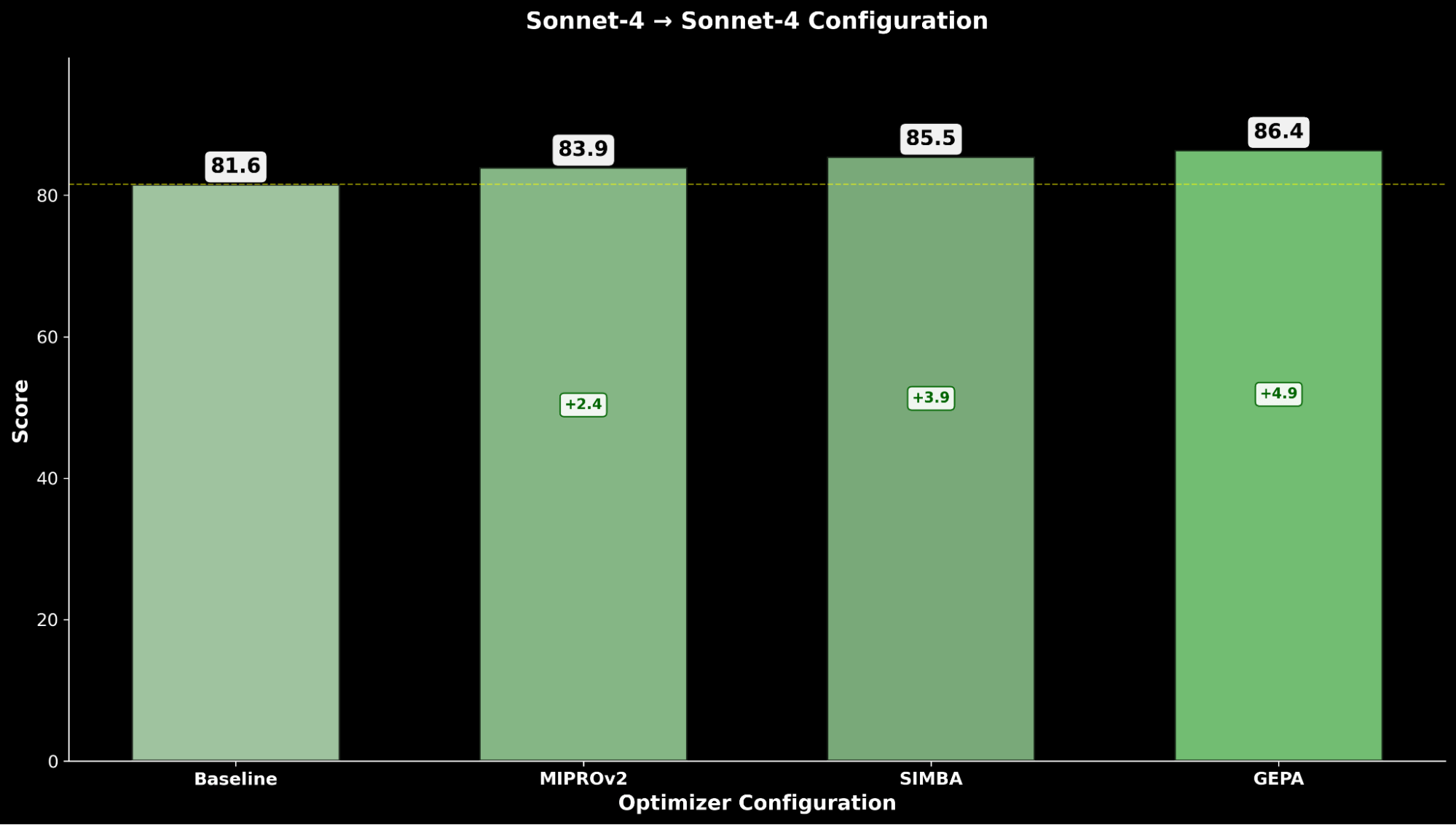
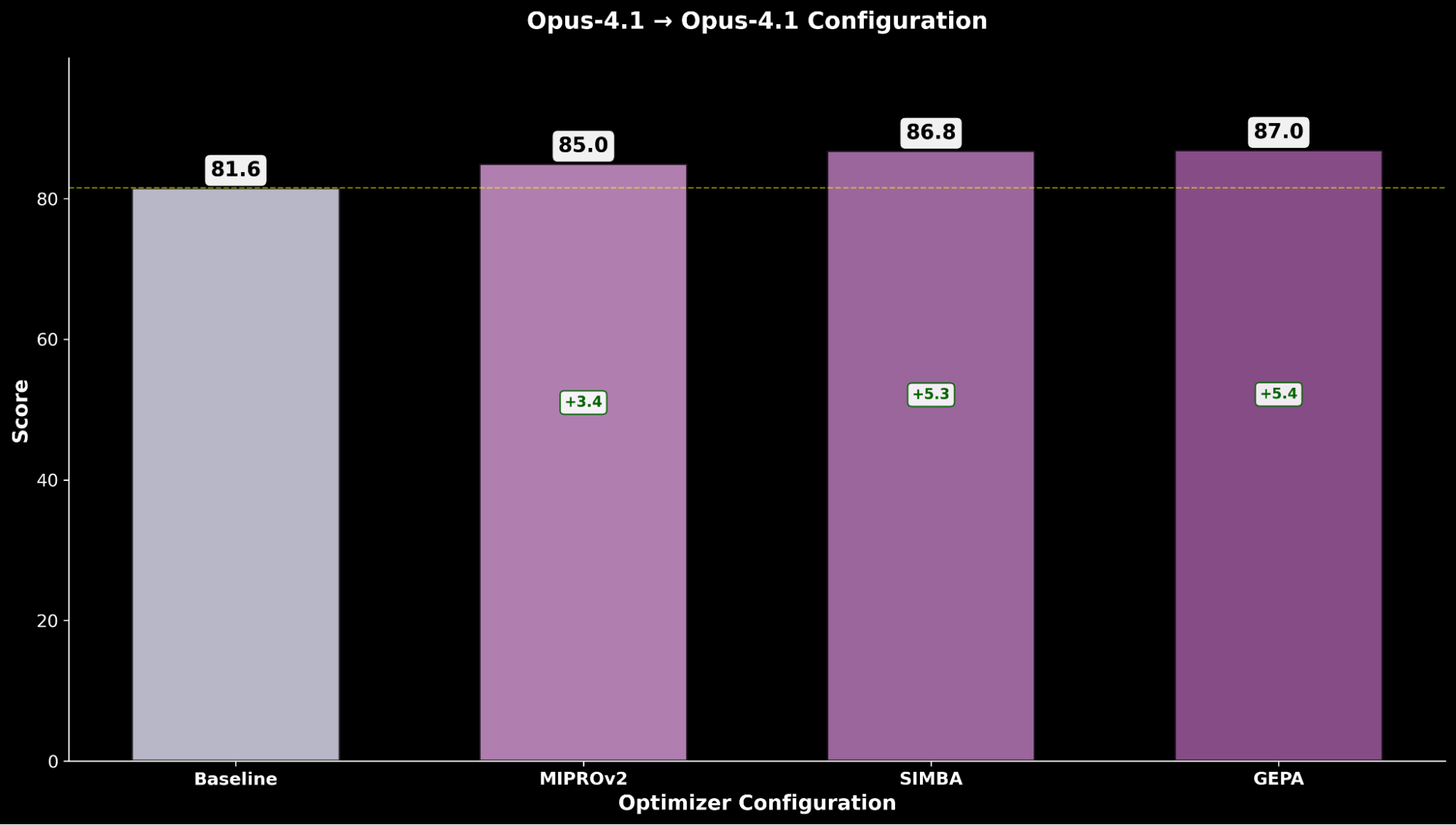
Otimizando o Claude Sonnet 4, é obtida uma melhoria de +4.8 sobre o desempenho base, enquanto o Claude Opus 4.1 otimizado alcança o melhor desempenho geral, com uma significativa melhoria de +6.4 pontos sobre o desempenho de ponta anterior.
Agregando resultados de experimentos, observamos uma tendência consistente de a otimização automática de prompts proporcionar ganhos significativos de desempenho em todos os modelos de desempenho base.
Em avaliações de modelos de código aberto e de código fechado, descobrimos consistentemente que o GEPA é o otimizador de melhor desempenho, seguido pelo SIMBA e depois pelo MIPRO, desbloqueando ganhos de qualidade significativos usando a otimização automática do prompt.
No entanto, ao considerar o custo, observamos que o GEPA tem um overhead de tempo de execução relativamente mais alto (como a exploração de otimização pode levar na ordem de O(3x) mais chamadas de LLM (~2-3 hrs) do que MIPRO e SIMBA (~1 hr))3 durante essa análise empírica do IE Bench. Portanto, levamos em conta a eficiência de custo e atualizamos nossa fronteira de Pareto de qualidade-custo, incluindo o desempenho otimizado dos modelos.
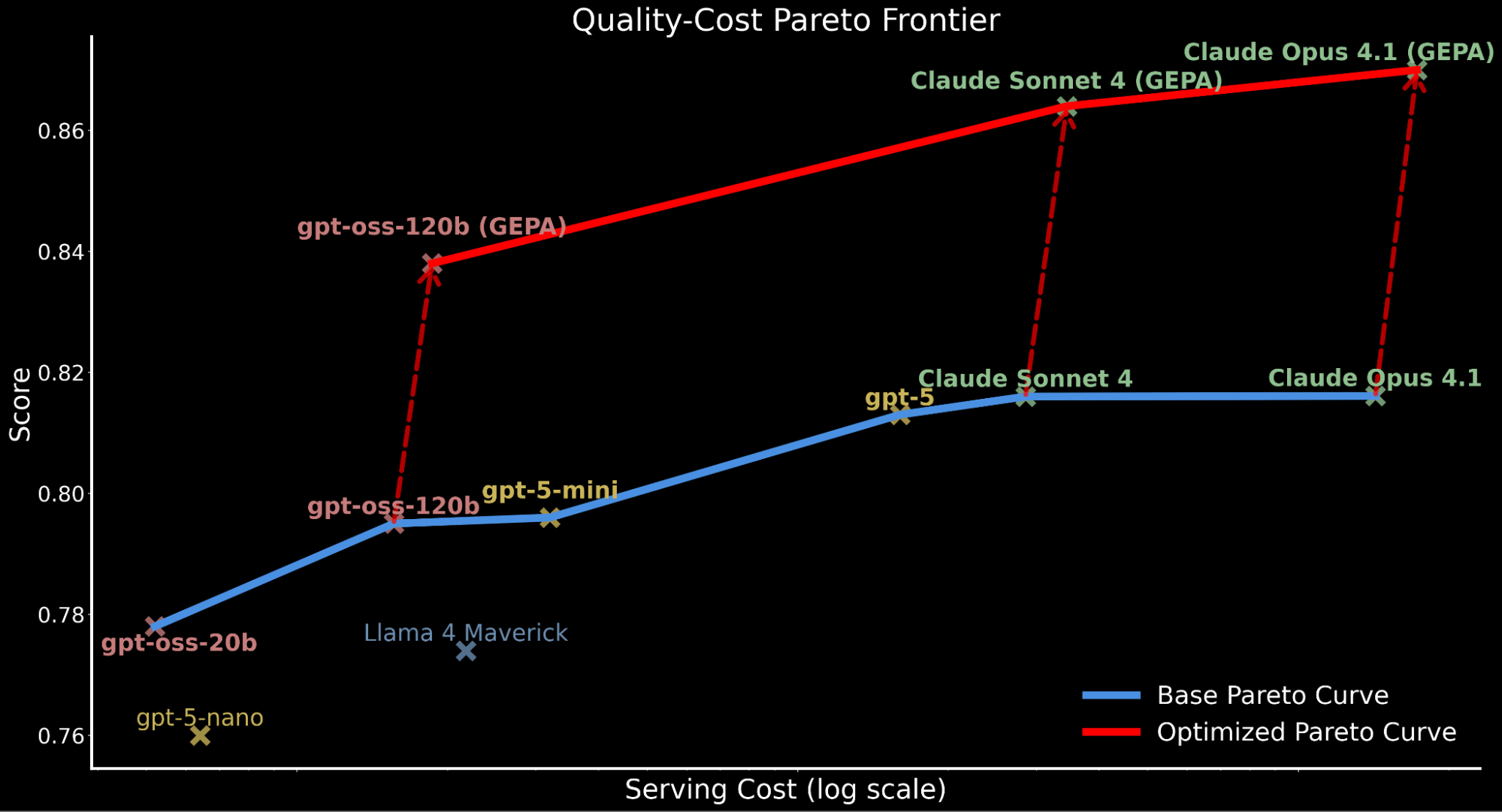
Destacamos como a aplicação da otimização de prompts automáticos desloca toda a curva de Pareto para cima, estabelecendo uma nova eficiência de última geração:
- O gpt-oss-120b otimizado pelo GEPA supera o desempenho base do Claude Sonnet 4 e Claude Opus 4.1 enquanto é 22x e 90x mais barato.
- Para clientes que priorizam a qualidade em detrimento do custo, o Claude Opus 4.1 otimizado pelo GEPA leva a um novo desempenho de referência, destacando ganhos poderosos para modelos de fronteira que não podem ser ajustados.
- Atribuímos o aumento total do custo de atendimento contabilizado para modelos otimizados pela GEPA aos prompts mais longos e detalhados em comparação com o prompt base produzido pela otimização
Ao aplicar otimizações automáticas de prompt a agentes, exibimos uma solução que cumpre os princípios básicos do Agent Bricks de alto desempenho e eficiência de custo.
Comparação com o SFT
O Afinação Supervisionada (SFT) é frequentemente considerada o método padrão para melhorar o desempenho do modelo, mas como se compara à otimização automatizada de prompts?
Para responder a isso, realizamos um experimento em um subconjunto do IE Bench, escolhendo o gpt 4.1 para avaliar o desempenho da SFT e a otimização automática de prompt (Excluímos o gpt-oss e o gpt-5 destas comparações, pois os modelos não foram lançados no momento da avaliação).
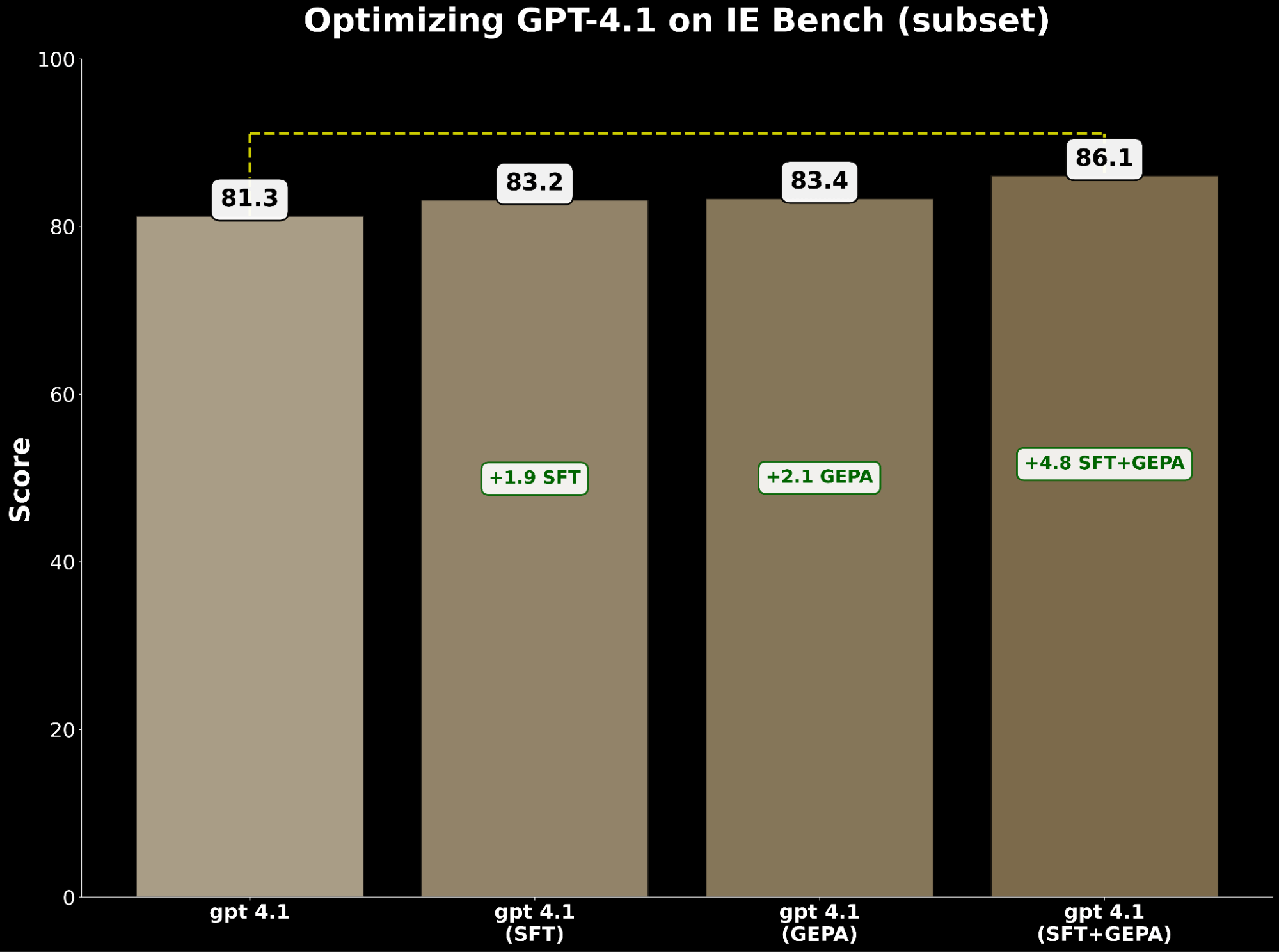
Tanto o SFT quanto a otimização de solicitações melhoram independentemente o gpt-4.1. Especificamente:
- SFT gpt-4.1 ganhou +1.9 pontos sobre a base.
- O gpt-4.1 otimizado pelo GEPA ganhou +2.1 pontos, ultrapassando ligeiramente o SFT.
Isso demonstra que a otimização de prompts pode igualar - e até superar - as melhorias do afinação supervisionada.
Inspirados por BetterTogether, uma técnica que considera a otimização de prompts alternados e o ajuste fino do peso do modelo para melhorar o desempenho do LLM, aplicamos o GEPA em cima do SFT e alcançamos um ganho de +4,8 pontos em relação à linha de base - destacando o forte potencial de compor essas técnicas em conjunto.
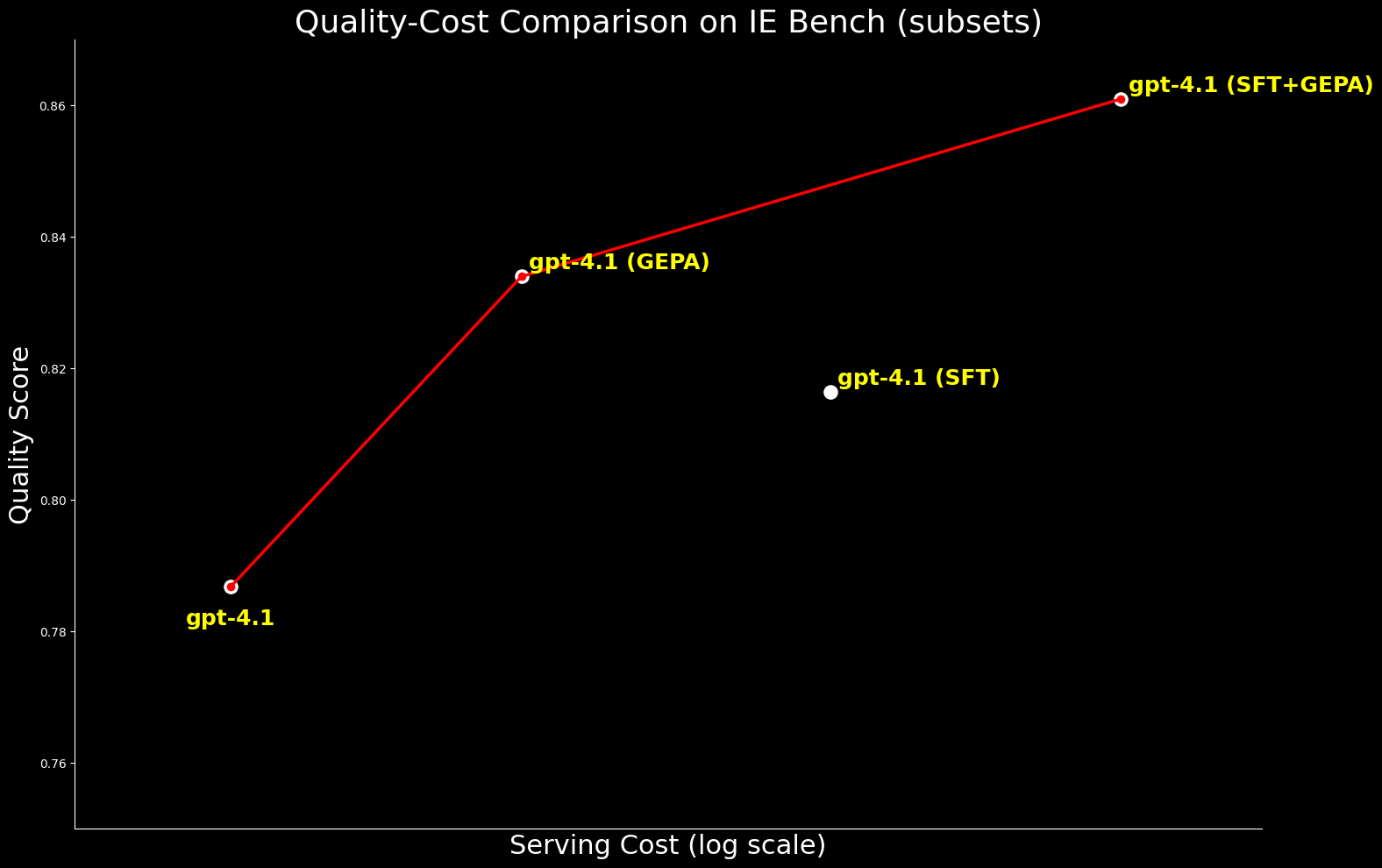
Do ponto de vista de custo, o gpt-4.1 otimizado pelo GEPA é ~20% mais barato para servir do que o gpt-4.1 otimizado pelo SFT, enquanto oferece melhor qualidade. Isso destaca que o GEPA oferece um equilíbrio de qualidade-custo premium sobre o SFT. Além disso, podemos maximizar a qualidade absoluta combinando GEPA com SFT, que apresenta um desempenho 2,7% superior ao SFT em si, mas a um custo de serviço ~22% mais alto.4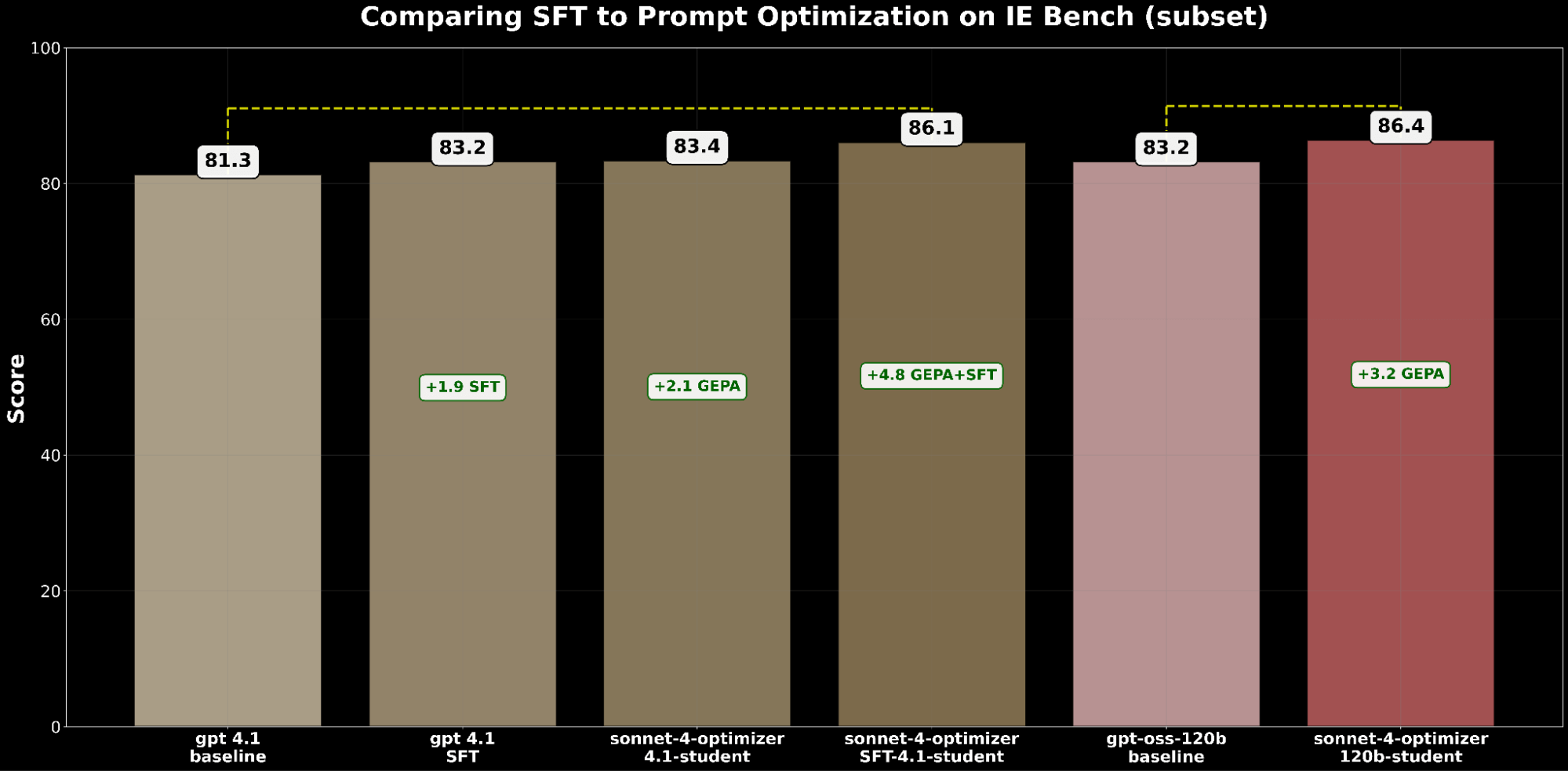
Ampliamos a comparação para o gpt-oss-120b para examinar a fronteira entre qualidade e custo. Embora o gpt-4.1 otimizado pelo SFT+GEPA se aproxime — ficando a 0,3% do desempenho do gpt-oss-120b otimizado pelo GEPA — este último oferece a mesma qualidade com custo de serviço 15x menor, tornando-o muito mais prático e atraente para implantação em larga escala.

Juntas, essas comparações destacam os fortes ganhos de desempenho possibilitados pela otimização GEPA - seja usada sozinha ou em combinação com o SFT. Elas também destacam a excepcional eficiência de qualidade-custo do gpt-oss-120b quando otimizado com GEPA.
Custo de Vida
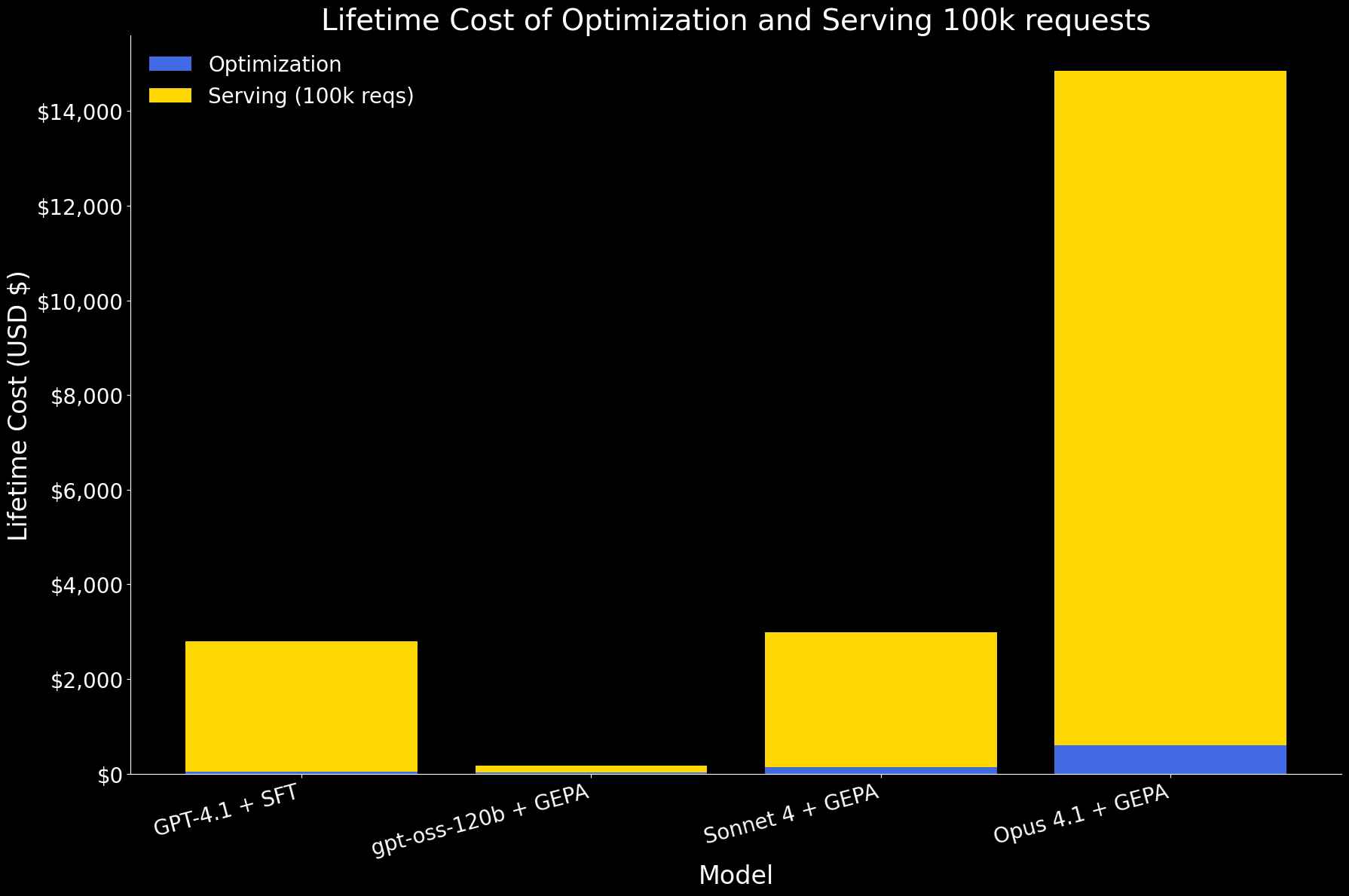
Para avaliar a otimização em termos reais, consideramos o custo vitalício para os clientes. O objetivo da otimização não é apenas melhorar a acurácia, mas também produzir um agente eficiente que possa atender a pedidos em produção. Isso torna essencial olhar tanto para o custo da otimização quanto para o custo de atender grandes volumes de pedidos.
No primeiro gráfico abaixo, mostramos o custo de vida de otimizar um agente e atender a 100 mil solicitações, dividido em componentes de otimização e serviço. Nessa escala, o serviço domina o custo total. Entre os modelos:
- gpt-oss-120b com GEPA é de longe o mais eficiente, com custos uma ordem de magnitude menor para otimização e serviço.
- GPT 4.1 com SFT e Sonnet 4 com GEPA têm custos vitalícios semelhantes.
- Opus 4.1 com GEPA é o mais caro, principalmente devido ao seu alto preço de serviço.
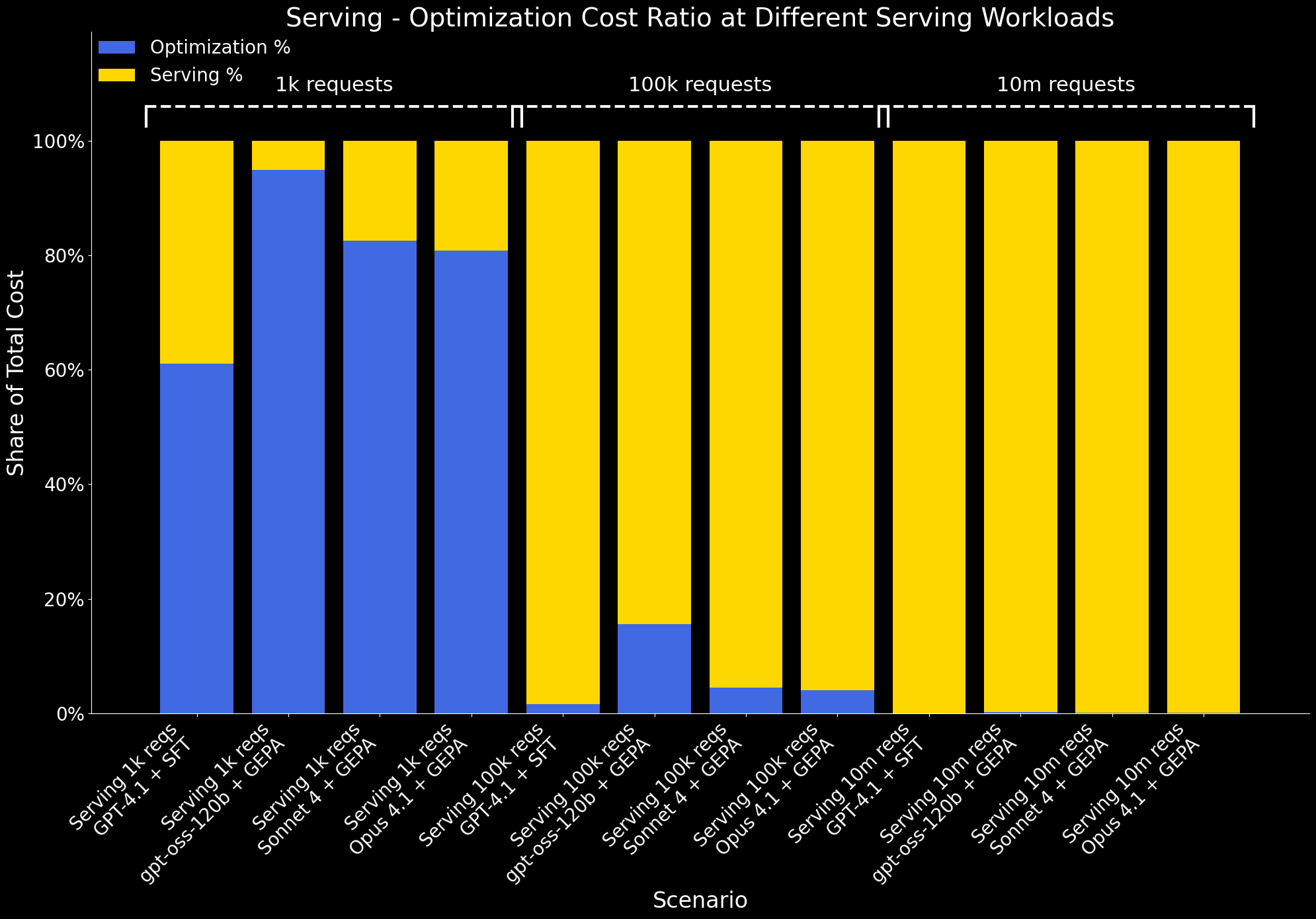
Também examinamos como a proporção de custo de otimização para custo de serviço muda em diferentes escalas de trabalho:
- Em 1k de carga de trabalho de atendimento, os custos de atendimento são mínimos, então a otimização representa uma grande parcela do custo total.
- Com 100 mil solicitações, os custos de atendimento aumentam significativamente, e o excesso de otimização é amortizado. Nesta escala, o benefício da otimização - melhor desempenho a menor custo de atendimento - claramente supera seu custo único.
- Em 10M de solicitações, os custos de otimização tornam-se insignificantes em comparação com os custos de atendimento e já não são visíveis no gráfico.
Resumo
Neste post de blog, demostramos que a otimização automática de solicitações é um poderoso instrumento para avançar no desempenho do LLM em tarefas de IA empresarial:
- Desenvolvemos o IE Bench, uma suíte de avaliação abrangente que abrange domínios do mundo real e captura desafios complexos de extração de informações.
- Ao aplicar otimização automática de prompt GEPA, elevamos o desempenho do modelo de código aberto líder gpt-oss-120b para superar o desempenho do modelo proprietário de última geração Claude Opus 4.1 em ~3% enquanto é 90 vezes mais barato para servir.
- A mesma técnica se aplica a modelos proprietários de fronteira, aumentando o Claude Sonnet 4 e o Claude Opus 4.1 em 6-7%.
- Em comparação com a Afinação Supervisionada (SFT), a otimização GEPA oferece uma relação custo-benefício superior para uso empresarial. Ele fornece desempenho equivalente ou superior ao SFT, enquanto reduz os custos de atendimento em 20%.
- A análise de custo vitalício mostra que, ao atender em escala (por exemplo, 100k pedidos), o custo único de otimização é rapidamente amortizado e os benefícios superam em muito o custo. Notavelmente, o GEPA no gpt-oss-120b proporciona um custo vitalício de ordem de magnitude inferior em comparação com outros modelos de fronteira, tornando-o uma escolha altamente atraente para agentes de IA corporativos.
Considerando tudo, nossos resultados mostram que a otimização de prompt altera a fronteira de Pareto de qualidade-custo para sistemas de IA corporativos, aumentando tanto o desempenho quanto a eficiência.
A otimização automática de solicitações, juntamente com o previamente publicado TAO, RLVR, e ALHF, agora está disponível no Agent Bricks. O princípio central do Agent Bricks é ajudar as empresas a construir agentes que raciocinem corretamente sobre seus dados e alcançarem qualidade de última geração e eficiência de custo em tarefas específicas do domínio. Ao unificar avaliação, otimização automática e implantação regulada, o Agent Bricks permite que seus agentes se adaptem aos seus dados e tarefas, aprendam com o feedback e melhorem continuamente as tarefas específicas do seu domínio empresarial. Nós encorajamos os clientes a experimentar a Extração de Informações e outras capacidades do Agent Bricks para otimizar agentes para seus próprios casos de uso empresariais.
1 Para ambas as séries de modelos gpt-oss e gpt-5, seguimos as melhores práticas do formato Harmony da OpenAI que insere o esquema JSON alvo na mensagem do desenvolvedor para gerar uma saída estruturada.
Também realizamos uma ablação nos diferentes esforços de raciocínio para a série gpt-oss (baixo, médio, alto) e a série gpt-5 (mínimo, baixo, médio, alto), e relatamos o melhor desempenho de cada modelo em todos os esforços de raciocínio.
2 Para as estimativas de custos de atendimento, usamos os preços publicados pelos plataformas dos provedores de modelos (OpenAI e Anthropic para modelos proprietários) e da Artificial Analysis para modelos de código aberto. Os custos são calculados aplicando-se esses preços às distribuições de tokens de entrada e saída observadas no IE Bench, dando-nos o custo total de atendimento para cada modelo.
3 O tempo de execução real da otimização automática de prompt é difícil de estimar, pois depende de muitos fatores. Aqui estamos dando uma estimativa aproximada baseada em nossa experiência empírica.
4 Estimamos o custo de atendimento do SFT gpt-4.1 usando o preço do modelo ajustado publicado pela OpenAI. Para modelos otimizados pela GEPA, calculamos o custo de atendimento com base no uso medido de tokens de entrada e saída dos prompts otimizados.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.