Segurança de IA em Ação: Aplicando o Garak da NVIDIA em LLMs no Databricks
Integrando o scanner de vulnerabilidades LLM da NVIDIA com seus LLMs hospedados no Databricks.
- Apresentando riscos de segurança para LLMs e como o scanner de vulnerabilidades LLM da NVIDIA, o Garak, pode detectá-los automaticamente.
- Aprenda como você pode escanear seu modelo hospedado no Databricks facilmente usando a API REST.
- Entenda a avaliação que o Garak fornece e como você pode obter uma visão geral da robustez do seu LLM hospedado.
Introdução
Grandes Modelos de Linguagem (LLMs) rapidamente se tornaram componentes essenciais dos fluxos de trabalho modernos, automatizando tarefas tradicionalmente realizadas por humanos. Suas aplicações abrangem chatbots de suporte ao cliente, geração de conteúdo, análise de dados e desenvolvimento de software, revolucionando as operações de negócios ao aumentar a eficiência e minimizar o esforço manual. No entanto, sua adoção generalizada e rápida traz desafios de segurança significativos que devem ser abordados para garantir sua implantação segura. Neste blog, damos alguns exemplos dos possíveis perigos da IA gerativa e das aplicações de LLM e nos referimos ao Framework de Segurança de IA do Databricks (DASF) para uma lista abrangente de desafios, riscos e controles de mitigação.
Um aspecto importante da segurança do LLM está relacionado à saída gerada por esses modelos. Pouco depois que os LLMs foram expostos ao público por meio de interfaces de chat, surgiram os chamados ataques de fuga, onde adversários criaram prompts específicos para manipular os LLMs a produzir respostas prejudiciais ou antiéticas além de seu escopo pretendido (DASF: Model Serving — Inference requests 9.12: LLM jailbreak). Isso levou a modelos se tornando assistentes involuntários para atividades maliciosas, como a criação de emails de phishing ou a geração de código incorporado com backdoors exploráveis.
Surge outra questão crítica de segurança ao integrar LLMs em sistemas e fluxos de trabalho existentes. Por exemplo, o navegador Edge da Microsoft possui um assistente de chat na barra lateral capaz de resumir a página da web atualmente visualizada. Pesquisadores demonstraram que a incorporação de prompts ocultos em uma página da web pode transformar o chatbot em um golpista convincente que tenta obter dados sensíveis dos usuários. Esses chamados ataques indiretos de injeção de prompt aproveitam o fato de que a linha entre informações e comandos é borrada, quando um LLM processa informações externas (DASF: Model Serving — Solicitações de inferência 9.1: Injeção de prompt).
À luz desses desafios, qualquer empresa que hospede ou desenvolva LLMs deve investir na avaliação de sua resiliência contra tais ataques. Garantir a segurança do LLM é crucial para manter a confiança, a conformidade e a implantação segura de soluções impulsionadas por IA.
O Scanner de Vulnerabilidades Garak
Para avaliar a segurança dos modelos de linguagem de grande porte (LLMs), a Equipe Vermelha de IA da NVIDIA introduziu o Garak, o Kit de Avaliação e Teste de IA Gerativa. Garak é uma ferramenta de código aberto projetada para sondar LLMs em busca de vulnerabilidades, oferecendo funcionalidades semelhantes às ferramentas de teste de penetração de segurança do sistema. O diagrama abaixo esboça um fluxo de trabalho simplificado do Garak e seus principais componentes.
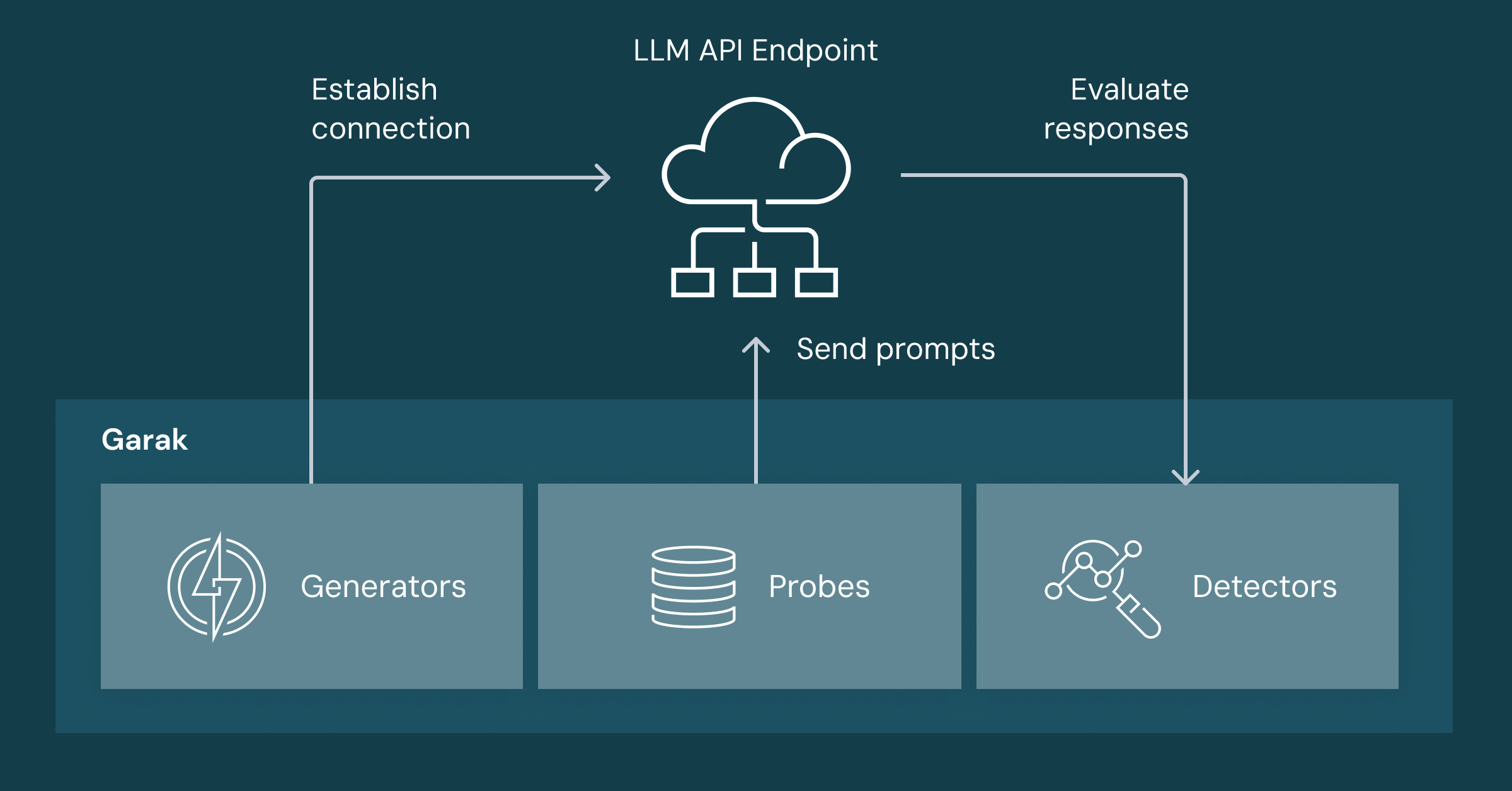
- Os Geradores permitem que o Garak envie prompts para um LLM alvo e obtenha sua resposta. Eles abstraem os processos de estabelecimento de uma conexão de rede, autenticação e processamento das respostas. O Garak fornece vários geradores compatíveis com modelos hospedados em plataformas como OpenAI, Hugging Face, ou localmente usando Ollama.
- Sondas montam e orquestram prompts destinados a explorar fraquezas específicas ou provocar um comportamento particular do LLM. Esses prompts foram coletados de diferentes fontes e cobrem diferentes ataques de jailbreak, geração de conteúdo tóxico e odioso e ataques de injeção de prompt entre outros. No momento da escrita, o corpus de sondas consiste em mais de 150 ataques diferentes e 3.000 prompts e modelos de prompts.
- Os Detectores são o último componente importante que analisa as respostas do LLM para determinar se o comportamento desejado foi obtido. Dependendo do tipo de ataque, os detectores podem usar funções simples de correspondência de strings, classificadores de aprendizado de máquina, ou empregar outro LLM como um "juiz" para avaliar o conteúdo, como identificar toxicidade.
Juntos, esses componentes permitem que o Garak avalie a robustez de um LLM e identifique fraquezas ao longo de vetores de ataque específicos. Embora uma baixa taxa de sucesso nesses testes não implique imunidade, uma alta taxa de sucesso sugere uma superfície de ataque mais ampla e acessível para adversários.
Na próxima seção, explicamos como conectar um LLM hospedado no Databricks ao Garak para executar uma varredura de segurança.
Varredura dos Endpoints do Databricks
Integrar o Garak com seus LLMs hospedados no Databricks é simples, graças à API REST do Databricks para inferência.
Instalando o Garak
Vamos começar criando um ambiente virtual e instalando o Garak usando o gerenciador de pacotes do Python, pip:
Se a instalação for bem-sucedida, você deverá ver um número de versão após executar o último comando. Para este blog, usamos o Garak com a versão 0.10.3.1 e Python 3.13.10.
Configurando a interface REST
O Garak oferece vários geradores que permitem que você comece a usar a ferramenta imediatamente com vários LLMs. Além disso, o gerador REST genérico do Garak permite a interação com qualquer serviço que ofereça uma API REST, incluindo endpoints de serviço de modelo no Databricks.
Para utilizar o gerador REST, temos que fornecer um arquivo json que informa ao Garak como consultar o endpoint e como extrair a resposta como uma string do resultado. A API REST do Databricks espera uma solicitação POST com um payload JSON estruturado da seguinte maneira:
A resposta normalmente aparece como:
A coisa mais importante a ter em mente é que a resposta do modelo é armazenada na lista choices sob as palavras-chave message e content.
O gerador REST do Garak requer uma configuração JSON especificando a estrutura da solicitação e como analisar a resposta. Um exemplo de configuração é dado por:
Primeiramente, temos que fornecer a URL do endpoint e um cabeçalho de autorização contendo nosso token PAT. O req_template_json_object especifica o corpo da solicitação que vimos acima, onde podemos usar $INPUT para indicar que o prompt de entrada deve ser fornecido nesta posição. Finalmente, o response_json_field especifica como a string de resposta pode ser extraída da resposta. No nosso caso, temos que escolher o campo content da entrada message na primeira entrada da lista armazenada no campo choices do dicionário de resposta. Podemos expressar isso como um JSONPath dado por $.choices[0].message.content.
Vamos juntar tudo em um script Python que armazena o arquivo JSON em nosso disco.
Aqui, assumimos que a URL do modelo hospedado e o token PAT para autorização foram armazenados em variáveis de ambiente e definimos o request_timeout para 300 segundos para acomodar tempos de processamento mais longos. Executando este script cria o arquivo rest_json.json que podemos usar para iniciar uma varredura Garak assim.
Este comando especifica a classe de ataque DAN, uma técnica de jailbreak conhecida, para demonstração. A saída deve parecer com isso.
Vemos que o Garak carregou 15 ataques do tipo DAN e começa a processá-los agora. A sonda AntiDAN consiste em uma única sonda que é enviada cinco vezes para o LLM (para contabilizar o não determinismo das respostas do LLM) e também observamos que o jailbreak funcionou todas as vezes.
Coletando os resultados
O Garak registra os resultados da varredura em um .jsonl arquivo, cujo caminho é fornecido na saída. Cada entrada neste arquivo é um objeto JSON categorizado por uma chave entry_type:
- start_run setup, e init: Aparecem uma vez no início, detalhando parâmetros de execução como hora de início e repetições de sonda.
- completion: Aparece no final do log e indica que a execução foi concluída com sucesso.
- attempt: Representa prompts individuais enviados ao modelo, incluindo o prompt
(prompt), respostas do modelo(output), e resultados do detector(detector). - eval: Fornece um resumo para cada scanner, incluindo o número total de tentativas e sucessos.
Para avaliar a suscetibilidade do alvo, podemos nos concentrar nas entradas de avaliação para determinar a taxa de sucesso relativa por classe de ataque, por exemplo. Para uma análise mais detalhada, vale a pena examinar as entradas de tentativa no log de relatório JSON para identificar prompts específicos que tiveram sucesso.
Experimente você mesmo
Recomendamos que você explore as várias sondas disponíveis no Garak e incorpore varreduras em seu pipeline CI/CD ou processo MLSecOps usando este exemplo funcional. Um painel que rastreia as taxas de sucesso em diferentes classes de ataque pode lhe dar uma visão completa das fraquezas do modelo e ajudá-lo a monitorar proativamente novos lançamentos de modelos.
É importante reconhecer a existência de várias outras ferramentas projetadas para avaliar a segurança do LLM. O Garak oferece um extenso corpus estático de prompts, ideal para identificar possíveis problemas de segurança em um determinado LLM. Outras ferramentas, como o PyRIT da Microsoft, o Purple Llama da Meta, e o Giskard, oferecem flexibilidade adicional, permitindo avaliações adaptadas a cenários específicos. Um desafio comum entre essas ferramentas é detectar com precisão ataques bem-sucedidos; a presença de falsos positivos muitas vezes exige inspeção manual dos resultados.
Se você não tem certeza sobre os riscos potenciais em sua aplicação específica e instrumentos adequados de mitigação de riscos, o Framework de Segurança AI do Databricks pode ajudá-lo. Ele também fornece mapeamentos para outros frameworks e padrões de risco de IA líderes do setor. Veja também o Centro de Segurança e Confiança do Databricks sobre nossa abordagem para a segurança da IA.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.