Anunciando o ecossistema de armazenamento da Databricks: governando o patrimônio de dados corporativos, onde quer que ele esteja
Impulsionado pelo OpenSharing de código aberto, nosso novo ecossistema de parceiros de armazenamento leva a Databricks Data Intelligence Platform diretamente para sua infraestrutura híbrida e on-premises — sem copiar um único byte.
por Rupal Jain e Denis Dubeau
- O desafio: As organizações precisam manter grandes volumes de dados on-premises, em nuvens privadas e em ambientes de borda para atender a rigorosos requisitos regulatórios e de soberania de dados, manter baixa latência na borda ou lidar com a imensa gravidade dos dados — tudo isso enquanto levam AI e governança em nuvem modernas para esses ambientes.
- O que é: O Databricks Storage Ecosystem conecta nativamente plataformas de armazenamento híbridas e on-premises ao Databricks usando o protocolo OpenSharing. Isso permite que as organizações estabeleçam uma governança de dados centralizada e escalem GenAI em toda a sua infraestrutura híbrida.
- O resultado: Usando uma arquitetura zero-copy, as empresas podem executar Databricks Serverless Compute, Genie e LLMs diretamente em seus conjuntos de dados on-premises sem copiar um único arquivo. Isso transforma instantaneamente dados isolados em ativos ativos e prontos para AI para casos de uso avançados, como treinar modelos em dados de engenharia confidenciais ou analisar telemetria de rede no local.
Os dados que não podem ser movidos
Durante anos, a estratégia de dados corporativos era simples: mover tudo para a nuvem. Migrar os data lakes e os data warehouses para a nuvem, e a governança viria em seguida. Era uma história perfeita — até deixar de ser.
Hoje, algumas das empresas mais sofisticadas do mundo estão nos dizendo claramente: elas não podem — e não vão — mover todos os seus dados para a nuvem. Fabricantes líderes de semicondutores estão treinando modelos em conjuntos de dados de engenharia confidenciais que nunca devem sair de suas instalações. Empresas de trading globais possuem volumes massivos de dados históricos de tick, nos quais os custos de saída da nuvem tornam a migração impossível. Bancos de primeira linha adotaram estratégias "Hybrid Forever", modernizando o armazenamento local enquanto mantêm uma soberania de dados rigorosa. Grandes empresas farmacêuticas realizam milhões de experimentos diários de medicamentos em ambientes de dados locais na escala de petabytes, sujeitos a controles regulatórios rígidos.
Esses não são casos isolados. Eles representam uma mudança estrutural na forma como as empresas pensam sobre dados: de "Migrar Tudo" para "Governar Tudo".
Os fatores determinantes são reais e cumulativos:
- Soberania de dados e regulamentação: Organizações de serviços financeiros, saúde e governamentais operam sob mandatos — GDPR, HIPAA, NIS2, regras de residência de dados específicas do setor — que exigem que os dados permaneçam em jurisdições específicas ou em ambientes isolados. A migração para a nuvem não é uma opção; ela é legalmente proibida para determinados conjuntos de dados.
- Gravidade de dados e custos: Na escala de petabytes e exabytes, a viabilidade econômica da migração para a nuvem deixa de existir completamente. Taxas de saída, custos de armazenamento e o próprio volume de dados tornam o modelo de "mover uma única vez" financeiramente insustentável. Alguns dos maiores varejistas do mundo estão ativamente repatriando cargas de trabalho de análise da nuvem de volta para a infraestrutura local justamente por esse motivo.
- Latência e cargas de trabalho de borda (edge): Cargas de trabalho de varejo, manufatura e telecomunicações exigem acesso de baixa latência a dados locais e de borda. Provedores de telecomunicações coletam diariamente enormes volumes de telemetria de rede localmente para alimentar operações de rede baseadas em AI que não toleram o tempo de ida e volta da nuvem.
- AI em dados escuros (dark data): Grandes volumes de dados de backup, arquivos não estruturados e conjuntos de dados secundários — que representam centenas de exabytes em toda a empresa — contêm um valor imenso para AI que nunca foi aproveitado porque a governança não os alcançava.
O sinal é claro. Recebemos solicitações de centenas de clientes pedindo explicitamente conectividade de armazenamento local e híbrido com o Unity Catalog. O mercado de Armazenamento Definido por Software (SDS) representa centenas de bilhões de dólares em 2026, e os parceiros corporativos que gerenciam esse patrimônio — que coletivamente possuem mais de 2 Zettabytes de dados sob gestão — estão desenvolvendo soluções conosco.
Apresentando o Ecossistema de Armazenamento da Databricks
Hoje, temos o prazer de anunciar o Ecossistema de Armazenamento Definido por Software (SDS) da Databricks — uma nova categoria de parceiros criada especialmente para levar a Databricks Intelligence Platform aos dados corporativos onde quer que eles estejam: localmente, em nuvens privadas e em ambientes de borda. Se a sua empresa gerencia petabytes de dados nessas plataformas hoje, você não precisa mais escolher entre sua infraestrutura de armazenamento existente fora da nuvem e a Databricks AI.
Por muito tempo, as empresas tiveram que escolher entre a infraestrutura de armazenamento local em que confiam e a AI nativa da nuvem que desejam criar. Forçar os clientes a migrar volumes massivos de dados usando pipelines complexos apenas para desbloquear essa inteligência é um modelo falho. Ao unir esses parceiros líderes do setor, estamos acabando com esse dilema e levando a Databricks Intelligence diretamente para onde os dados corporativos estão. Mas este lançamento é apenas o começo. Estamos construindo a base para garantir que, em breve, todos os dados híbridos — estruturados ou não estruturados — estejam instantaneamente prontos para a AI generativa, sem nunca precisar copiar um único byte. —Stephen Orban, SVP, Parcerias de Produtos e Ecossistema, Databricks
No coração deste ecossistema está o OpenSharing, um protocolo de código aberto para compartilhamento de dados seguro e governado. Nossos parceiros de armazenamento estão implementando servidores OpenSharing para expor seus ambientes de dados diretamente ao Databricks Serverless Compute. O caminho é simples: o parceiro de armazenamento disponibiliza um endpoint OpenSharing, você o conecta ao Unity Catalog e ganha instantaneamente acesso seguro e governado aos seus dados locais no Databricks, sem necessidade de migração de dados.
Essa integração oferece um catálogo único e unificado em todo o seu ambiente híbrido. Agora, os clientes podem usar o Databricks Serverless Compute, o Genie, o AgentBricks e o treinamento de modelos para consultar e analisar dados que nunca saem do local. O resultado? Zero movimentação de dados, sem duplicação de dados e risco zero de conformidade.
Isso não é apenas um plano para o futuro. Os clientes já podem testar essas integrações hoje mesmo. Os parceiros que desenvolvem essas integrações seguem o Partner Well-Architected Framework — um modelo técnico que abrange critérios de arquitetura, segurança e certificação.
Os clientes querem eliminar os silos de dados e unificar todo o seu patrimônio de dados e AI — incluindo grandes volumes de dados que ainda residem localmente. Graças aos parceiros de armazenamento local que utilizam o protocolo de código aberto Open Sharing, os clientes agora podem unificar, governar e analisar perfeitamente todo o seu patrimônio de dados no Databricks Unity Catalog — liberando todo o valor de seus dados na Databricks Data Intelligence Platform. —Jonathan Keller, VP, Gerenciamento de Produtos, Databricks
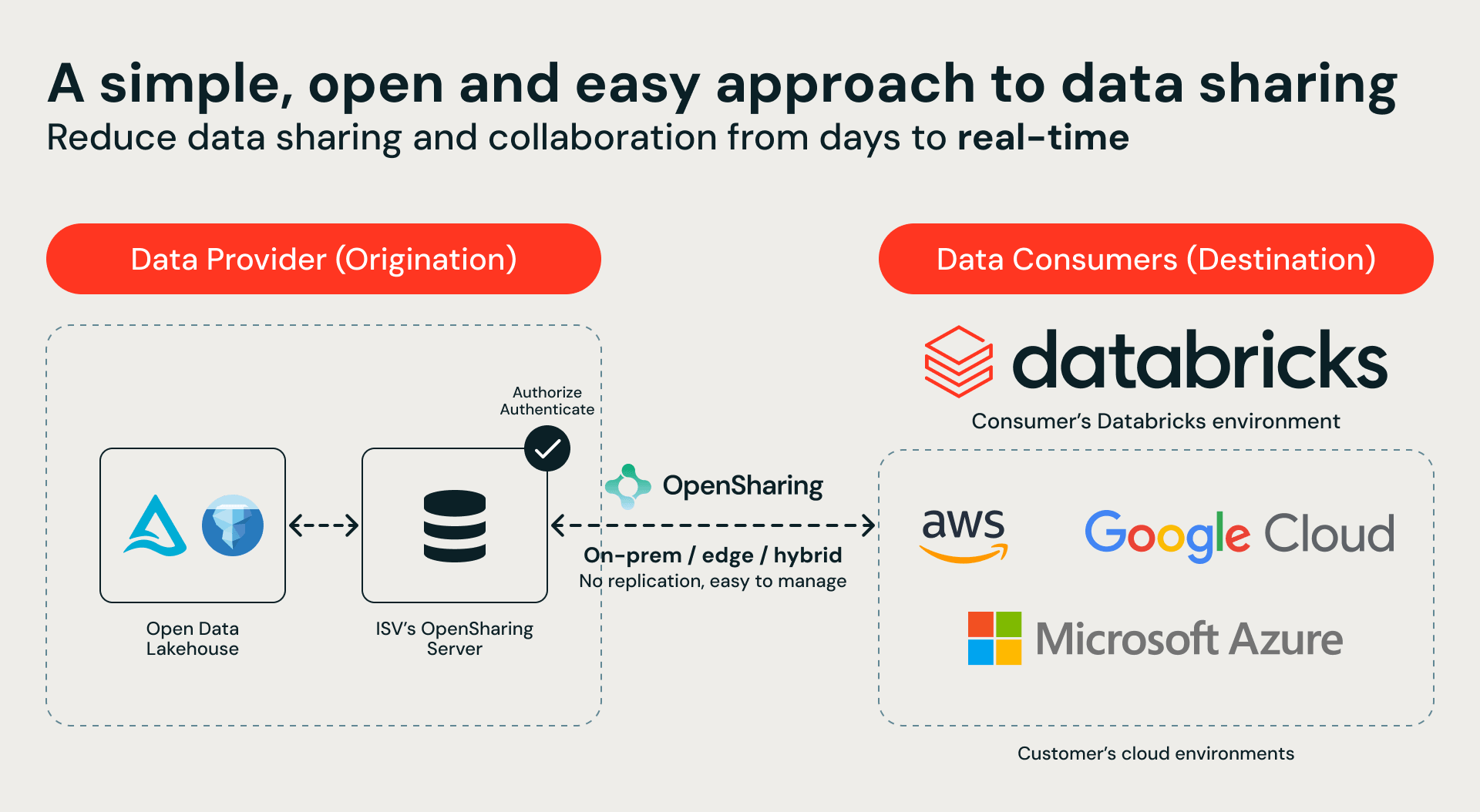
Nossos parceiros de lançamento
Temos o orgulho de anunciar integrações com os seguintes provedores de armazenamento líderes do setor:

MinIO — Disponibilidade Geral (GA) (demonstração, blog)
O MinIO AIStor é a ponte que conecta perfeitamente a Databricks Data Intelligence Platform aos dados corporativos que não podem ser movidos para a nuvem. Ao implementar nativamente o protocolo aberto Open Sharing na camada de armazenamento, o AIStor elimina a complexidade e permite que os clientes da Databricks consultem com eficiência tabelas locais ativas do Apache Iceberg™️ e Delta sob a governança total do Unity Catalog. Ele estende o Serverless Compute, o Genie e o Agent Bricks para dados locais, levando todo o poder da Databricks Platform para os dados mais críticos de uma empresa.
As iniciativas de AI e análise de dados são frequentemente limitadas por onde os dados residem, especialmente em ambientes com requisitos rígidos de segurança, soberania ou operacionais. Ao trazer o OpenSharing nativo para o AIStor, estamos permitindo que as organizações exponham seus dados com segurança onde quer que eles estejam, ao mesmo tempo em que oferecemos à Databricks um acesso contínuo por meio de padrões abertos. Isso remove uma grande barreira entre os dados corporativos e a AI, permitindo que as organizações ativem dados anteriormente inacessíveis para AI, análises e aplicações baseadas em agentes sem comprometer o controle. —Ugur Tigli, Chief Technology Officer, MinIO
Everpure (anteriormente Pure Storage) — Private Preview (demonstração, blog)
A Everpure e a Databricks permitem que as organizações usem dados locais diretamente na nuvem, eliminando a necessidade de replicação ou duplicaç�ão de dados. Isso é fornecido por meio de um conector OpenSharing que conecta os dados no armazenamento de objetos aos workspaces principais da Databricks de maneira segura e controlada.
A Everpure e a Databricks permitem que as organizações acessem e analisem dados locais diretamente da nuvem, sem a necessidade de replicação ou duplicação. Mover dados continuamente entre ambientes é caro e insustentável em escala. Os clientes buscam uma abordagem mais simples que equilibre custo, conformidade e soberania de dados, ao mesmo tempo em que reduz a complexidade operacional. —Chadd Kenney, VP de Gerenciamento de Produtos, Everpure
Qumulo — Private Preview em julho de 2026 (blog)
A Qumulo integrou o OpenSharing ao seu novo NeuralSearch, permitindo que os clientes compartilhem com segurança dados armazenados na Qumulo com o Databricks em ambientes locais, em nuvem e de borda — sem replicação, custos extras ou complexidade. Usando o NeuralSearch, os usuários podem descobrir datasets relevantes, incluindo conteúdo não estruturado, por meio de consultas em linguagem natural e compartilhar perfeitamente essas tabelas selecionadas com o Databricks via OpenSharing.
As organizações não podem mais arcar com os custos, a complexidade e os atrasos da cópia de grandes volumes de datasets entre ambientes apenas para dar suporte a AI e analytics. Ao combinar o Qumulo NeuralSearch com o Databricks OpenSharing, os clientes podem descobrir, governar e compartilhar com segurança dados tabulares e não estruturados em data centers locais, locais de borda e nuvens públicas – em tempo real, sem mover os dados em si. Juntos, estamos ajudando as organizações a acelerar iniciativas de AI, unificar a governança e obter insights mais rápidos a partir de dados distribuídos globalmente, mantendo uma única fonte da verdade. —Brandon Whitelaw, SVP e Head of Product na Qumulo
VAST Data — Private Preview em agosto de 2026
VAST Data está estendendo o VAST AI Operating System com suporte ao OpenSharing para ajudar as empresas a conectar os fluxos de trabalho do Databricks com dados que residem em infraestruturas locais e híbridas – sem a necessidade de migração ou movimentação massiva de dados. A integração dará aos clientes mais flexibilidade para acessar, processar e operacionalizar dados em ambientes de nuvem, data center e infraestrutura de AI emergente, ao mesmo tempo em que oferece suporte a cargas de trabalho modernas de AI híbrida e analytics.
A infraestrutura de AI está se tornando fundamentalmente híbrida. Os clientes desejam cada vez mais a capacidade de processar dados onde fizer mais sentido do ponto de vista econômico e operacional, mantendo o acesso contínuo entre os ambientes. O suporte ao OpenSharing estende a capacidade do VAST AI Operating System de conectar os fluxos de trabalho do Databricks com dados que residem em infraestruturas locais e em nuvem para aplicações modernas de AI e analytics. Ao contrário das plataformas de armazenamento tradicionais, a VAST combina serviços de dados, processamento distribuído e orquestração de infraestrutura de AI em um sistema operacional unificado para dados de AI em escala. —John Mao, Vice President, Global Technology Alliances na VAST Data
Próximos passos
Integrações em breve
Além dos nossos parceiros de lançamento, o ritmo em todo o ecossistema de armazenamento continua a acelerar. Garantimos o compromisso de Cohesity, Commvault, HPE, NetApp, Nutanix e Rubrik para criar integrações nativas até o final do ano.
Coletivamente, esses parceiros, juntamente com os parceiros de lançamento, gerenciam centenas de exabytes de dados corporativos, abrangendo mídias não estruturadas de alto desempenho, arquivos de backup secundários, armazenamento em nuvem de excelente custo-benefício e ambientes de nuvem privada hiperconvergente.
Desbloqueando dados não estruturados
O lançamento de hoje estabelece os dados estruturados e tabulares como totalmente governados e acessíveis em todo esse ecossistema. Mas sabemos que uma grande oportunidade está nos dados não estruturados: imagens, PDFs, vídeos, exames médicos, simulações de engenharia e arquivos de backup que representam a maior parte dos dados corporativos sob gestão — e a matéria-prima para a próxima geração de pipelines de RAG e modelos com ajuste fino.
Estamos trabalhando ativamente para estender o protocolo OpenSharing com as APIs de Volumes — expondo arquivos não estruturados de armazenamento local diretamente para o Databricks para cargas de trabalho de GenAI. Com essa novidade, os parceiros que gerenciam grandes volumes de dados não estruturados — de arquivos de mídia e imagem a repositórios de backup corporativos — desbloquearão uma classe totalmente nova de casos de uso de AI para seus clientes.
Isso é o que significa governar tudo.
Participe do ecossistema
Se você é um fornecedor de armazenamento interessado em criar uma integração com o OpenSharing, visite o Partner Well Architected Framework ou entre em contato com a equipe de parceiros do Databricks para começar.
Se você é um cliente corporativo que deseja conectar sua infraestrutura de armazenamento local ao Databricks, entre em contato com sua equipe de conta para saber mais.
A era de "Migrar tudo" acabou. A era de "Governar tudo" começa hoje.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.