Anunciando a disponibilidade geral da API Python Data Source
Libere a conectividade de dados personalizada com a simplicidade do Python
- Os desenvolvedores agora podem criar conectores Spark personalizados usando Python, integrando-se a diversas fontes de dados através do rico ecossistema Python.
- A API de Fonte de Dados do Python oferece suporte a cargas de trabalho em lote (batch) e de streaming, permitindo pipelines de ingestão de dados em tempo real em fontes estruturadas e não estruturadas e gravação em destinos.
- Com a integração do Unity Catalog da Databricks, os desenvolvedores podem governar, proteger e operacionalizar dados externos com linhagem de dados, controle de acesso e capacidade de auditoria.
- Use os sinks do Declarative Pipeline, implementados como uma fonte de dados Python, para transmitir registros para serviços externos com o Declarative Pipelines.
Temos o prazer de anunciar a Disponibilidade Geral (GA) da API de Fonte de Dados do PySpark para o Apache Spark™ 4.0 no Databricks Runtime (DBR) 15.4 LTS e superior. Este recurso poderoso permite que os desenvolvedores criem conectores de dados personalizados com o Spark usando Python puro. Ele simplifica a integração com fontes de dados externas e não nativas do Spark, abrindo novas possibilidades para pipelines de dados e workflows de machine learning.
Por que isso importa
Hoje em dia, os dados são ingeridos de inúmeras fontes: algumas estruturadas, outras não estruturadas e dados multimodais, como imagens e vídeos. O Spark suporta nativamente os formatos padrão de Fonte de Dados v1 (DSv1) e Fonte de Dados v2 (DSv2), como Delta, Iceberg, Parquet, JSON, CSV e JDBC. No entanto, não oferece suporte integrado para muitas outras fontes, como Google Sheets, APIs REST, datasets do HuggingFace, tweets do X ou sistemas internos proprietários. Embora o DSv1/DSv2 possa ser tecnicamente estendido para implementar essas fontes, o processo é excessivamente complexo e muitas vezes desnecessário para casos de uso leves.
E se você precisar ler ou gravar dados em outras fontes de dados personalizadas para o seu caso de uso, ou se o seu pipeline de ETL para um caso de uso de machine learning precisar consumir esses dados para treinar um modelo? É exatamente essa a lacuna que a API de Fonte de Dados do Python preenche.
Neste blog, vamos explorar como você pode escrever fontes de dados personalizadas no PySpark. Com esta API, você pode incluir facilmente diversos conjuntos de dados não nativos do Spark em seus pipelines de processamento de dados para seu caso de uso específico. Também exploraremos alguns exemplos de fontes de dados personalizadas. Mas, primeiro, vamos entender o porquê e o quê.
O que é a API Python Data Source?
Inspirada no amor das pessoas por escrever em Python e na facilidade de instalar pacotes com o pip, a API Python Data Source facilita a criação de leitores e gravadores personalizados para o Spark usando Python. Esta API libera o acesso a qualquer fonte de dados, eliminando a necessidade de desenvolvimento complexo de DSv1 e DSv2 ou do conhecimento dos componentes internos do Spark, que antes eram necessários para conectores personalizados.
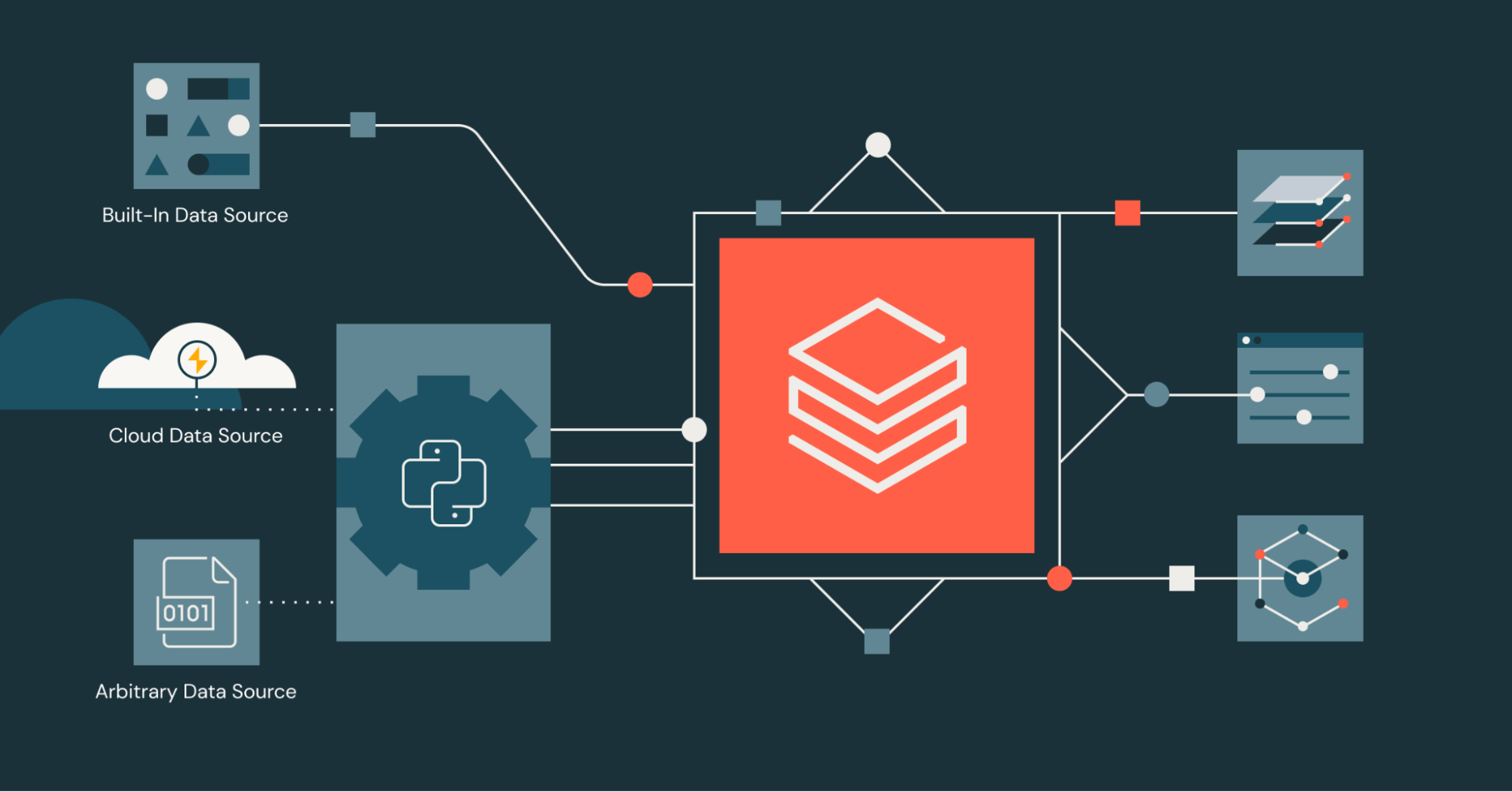
Quais são os principais recursos e benefícios?
Há vários benefícios importantes em usar fontes de dados Python.
1. Implementação puramente em Python
Considere primeiro a abordagem pythônica. A API Python Data Source remove as barreiras do desenvolvimento de conectores mais complicados baseados em JVM. Engenheiros de dados que criam pipelines de ETL complexos usando inúmeras fontes de dados em Python agora podem aproveitar suas habilidades existentes em Python para criar conectores personalizados sem precisar se aprofundar nas complexidades internas do Spark.
2. Suporte para operações em lote (batch) e de streaming
A API oferece suporte a leituras em lote (batch) e de streaming, permitindo que você crie conectores que lidam com vários padrões de acesso a dados:
- Leitura em lote: extrair dados de APIs, bancos de dados ou outras fontes em uma única operação
- Leitura de streaming: ingira dados continuamente de fontes baseadas em eventos ou em tempo real
- Gravação em lote (batch) e de streaming: grave no coletor de dados (data sink), incluindo coletores (sinks) do Declarative Pipeline.
3. Acessibilidade do SQL
Assim como qualquer fonte de dados compatível no Spark SQL, você pode acessar sua fonte de dados Python personalizada com a mesma facilidade a partir do Spark SQL. Depois que uma fonte de dados for carregada como um DataFrame, você poderá salvá-la como uma visualização temporária ou uma tabela gerenciada e persistente do Unity Catalog. Isso permite que você incorpore suas fontes de dados personalizadas em suas análises SQL posteriores.
4. Integração simplificada com serviços externos
Você pode se conectar facilmente a sistemas externos passando suas opções personalizadas, como chaves de API, endpoints ou outras configurações, usando a API DataFrame. Isso dá a você controle total sobre o comportamento do seu conector. Veja os exemplos do mundo real abaixo para obter mais detalhes.
5. Ecossistema de conectores impulsionado pela comunidade
Desde o lançamento da versão de prévia, a comunidade já começou a criar conectores valiosos com a API Python Data Source:
- Conectores de exemplo: implementações de referência para APIs REST, variantes de CSV e muito mais (repositório do GitHub)
- Conector do HuggingFace: acesso direto a datasets do HuggingFace (repositório do GitHub)
6. Velocidade sem complexidade
A API de Fonte de Dados do Python foi projetada não apenas para ser fácil de usar, mas também para ser rápida. Ela é construída sobre o Apache Arrow, um formato de dados em memória otimizado para o processamento rápido de dados. Isso significa que seus dados podem ser movidos entre seu conector personalizado e o Spark com sobrecarga mínima, tornando a ingestão e a gravação muito mais rápidas.
Casos de uso de fontes de dados Python no mundo real
Vamos explorar casos de uso do mundo real para alimentar dados em seus pipelines usando fontes de dados Python.
Integrações de API personalizadas
Primeiro, vamos analisar como você pode se beneficiar da integração de APIs REST.
Muitas equipes de engenharia de dados estão criando conectores personalizados para extrair dados de APIs REST e usá-los em transformações posteriores. Em vez de escrever um código personalizado para buscar os dados, salvá-los em disco ou na memória e depois carregá-los no Spark, você pode usar a API de Fonte de Dados do Python para pular essas etapas.
Com uma fonte de dados personalizada, você pode ler dados diretamente de uma API em um Spark DataFrame, e nenhum armazenamento intermediário é necessário. Por exemplo, veja como buscar a saída completa de uma chamada de API REST e carregá-la diretamente no Spark.
A fonte de dados da API REST e sua implementação completa estão disponíveis aqui como um exemplo de referência.
Integração com o Unity Catalog
A segunda integração é com catálogos de dados. Mais desenvolvedores nas empresas estão recorrendo a catálogos de dados, como o Unity Catalog, para armazenar seus ativos de IA e dados em um repositório central para governança e segurança de dados centralizadas. À medida que essa segunda tendência continua, seus jobs de pipeline de dados devem ser capazes de ler e gravar nesses ativos de dados de maneira segura e controlada.
Você pode ler dados diretamente dessas fontes de dados personalizadas e gravar em tabelas do Unity Catalog, trazendo governança, segurança e capacidade de descoberta para dados de qualquer fonte:
Essa integração garante que os dados de suas fontes especializadas possam ser devidamente governados e protegidos pelo Unity Catalog.
Integração de pipeline de Machine Learning
A terceira integração é com conjuntos de dados externos de machine learning. Cientistas de dados usam a API Python Data Source para se conectar diretamente a conjuntos de dados especializados de Machine Learning (ML) e repositórios de modelos. O HuggingFace tem inúmeros conjuntos de dados com curadoria explícita para treinar e testar modelos clássicos de ML.
Para buscar este dataset como um DataFrame do Spark, você pode usar o conector do HuggingFace. Este conector aproveita o poder da API de Fonte de Dados do Python para buscar facilmente ativos de ML que podem ser integrados ao seu pipeline de dados.
Depois de buscados, o Spark DataFrame apropriado pode ser usado com o algoritmo de machine learning relevante para treinar, testar e avaliar o modelo. Simples.
Para mais exemplos, confira o HuggingFace DataSource Connector.
Processamento de streaming com fontes personalizadas
Além disso, como um quarto ponto de integração, as fontes de dados de streaming fazem parte dos seus pipelines de ETL diários tanto quanto as fontes estáticas em armazenamento. Você também pode criar aplicações de streaming com fontes personalizadas que ingerem dados continuamente.
Aqui está um trecho de código para uma fonte de dados personalizada do Spark para streaming de dados de rastreamento de aeronaves em tempo real da API OpenSky Network. A OpenSky Network, uma rede de receptores mantida pela comunidade, coleta dados de vigilância de tráfego aéreo e os oferece como dados abertos para pesquisadores e entusiastas. Para ver uma implementação completa desta fonte de dados de streaming personalizada, confira o código-fonte no GitHub aqui.
Integração de pipeline declarativo
Finalmente, como engenheiro de dados, você pode integrar facilmente as Python Data Sources com a integração do Declarative Pipeline.
Leitura de fonte de dados personalizada
Em um pipeline declarativo, a ingestão de dados da fonte de dados personalizada funciona da mesma forma que em Jobs regulares do Databricks.
Escrita em serviços externos via Custom Data Source
Neste blog de exemplo, Alex Ott demonstra como a nova API de Sinks para Declarative Pipelines permite que você use um objeto sink que aponta para uma tabela Delta externa ou outros destinos de streaming, como o Kafka, como uma fonte de dados integrada.
No entanto, você também pode gravar em um sink personalizado implementado como uma fonte de dados Python. Em nossa fonte de dados Python personalizada no código abaixo, criamos um sink usando a sink API e o usamos como o objeto “sink”. Depois de definidos e desenvolvidos, você pode anexar fluxos. Você pode consultar a implementação completa deste código aqui.
Criando seus conectores personalizados
Para começar a usar a API Python Data Source para criar seu conector personalizado, siga estes quatro passos:
- Verifique se você tem o Spark 4.0 ou o Databricks Runtime 15.4 LTS ou posterior: a API de fonte de dados Python está disponível no DBR 15.4 LTS e superior, ou use o Databricks Serverless Generic Compute.
- Use o modelo de implementação: consulte as classes base no módulo pyspark.sql.datasource.
- Registre seu conector: torne seu conector detectável em seu workspace do Databricks.
Use seu conector: seu conector pode ser usado assim como qualquer fonte de dados integrada.
Histórias de sucesso de clientes usando a API de Fonte de Dados do Python
Na Shell, os engenheiros de dados muitas vezes precisavam combinar dados de fontes integradas do Spark como o Apache Kafka com fontes externas acessadas por meio de APIs REST ou SDKs. Isso levou a um código personalizado pontual ou sob medida que era difícil de manter e inconsistente entre as equipes. O diretor de tecnologia digital da Shell observou que isso desperdiçava tempo e adicionava complexidade.
“Escrevemos muitas APIs REST legais, incluindo para casos de uso de streaming, e adoraríamos simplesmente usá-las como fonte de dados no Databricks em vez de escrevermos todo o código de infraestrutura por conta própria.” — Bryce Bartmann, diretor de tecnologia digital, Shell
Para aproveitar suas APIs REST legais, a solução para os engenheiros de dados da Shell foi usar a nova API de fonte de dados personalizada do Python para implementar suas APIs REST como uma fonte de dados. Isso permitiu que os desenvolvedores tratassem APIs e outras fontes não padrão como fontes de dados Spark de primeira classe. Com abstrações orientadas a objetos, ficou mais fácil inserir uma lógica personalizada de forma limpa — sem mais código de ligação bagunçado.
Conclusão
Em resumo, a API Python Data Source do PySpark permite que desenvolvedores Python tragam dados personalizados para o Apache Spark™ usando o familiar e adorável Python, combinando simplicidade e desempenho sem exigir conhecimento aprofundado dos componentes internos do Spark. Seja para se conectar a APIs REST, acessar conjuntos de dados de machine learning como o HuggingFace ou fazer streaming de dados de plataformas sociais, esta API simplifica o desenvolvimento de conectores personalizados com uma interface limpa e Pythônica. Ela contorna a complexidade dos conectores baseados em JVM e dá às equipes de dados a flexibilidade para criar, registrar e usar suas fontes diretamente no PySpark e no SQL.
Ao suportar cargas de trabalho em lote e de streaming e se integrar com o Unity Catalog, a API garante que seus dados externos permaneçam governados e acessíveis. De pipelines de ML em tempo real a análises ou ingestão de dados, a API Python Data Source transforma o Spark em uma plataforma de dados extensível.
Roteiro futuro
À medida que a API de Fonte de Dados do Python continua a evoluir, estamos animados com várias melhorias futuras:
- Column Pruning e Filter Pushdown: recursos mais sofisticados para otimizar a transferência de dados, movendo a filtragem e a seleção de colunas para mais perto da fonte
- Suporte para estatísticas personalizadas: permite que os conectores forneçam estatísticas específicas da fonte para melhorar o planejamento e a otimização de consultas
- Melhor observabilidade e capacidade de depuração: ferramentas de log aprimoradas para simplificar o desenvolvimento e a solução de problemas de conectores
- Biblioteca de exemplos expandida: mais implementações de referência para fontes de dados e padrões de uso conhecidos
- Otimizações de desempenho: Melhorias contínuas para reduzir a sobrecarga de serialização e aumentar a taxa de transferência
Experimente hoje mesmo
A API de Fonte de Dados do Python está em disponibilidade geral hoje em toda a Databricks Intelligence Platform, incluindo o Databricks Runtime 15.4 LTS e superior e os Ambientes Serverless.
Comece a criar conectores personalizados para integrar qualquer fonte de dados com seu data Lakehouse! E para saber como outras pessoas implementaram o Python DataSource, ouça estas palestras apresentadas no Data + AI Summit de 2025:
- Quebrando barreiras: criando conectores de fonte de dados personalizados do Apache Spark™ 4.0 com Python
- Criação de um leitor de stream PySpark personalizado com o PySpark 4.0
- Simplifique a ingestão e a saída de dados com a nova API de fonte Python
Quer saber mais? Entre em contato para uma demonstração personalizada da API de fonte de dados Python ou explore nossa documentação para começar.
Documentação e Recursos
- Documentação da Python Data Source
- Declarative Pipelines
- Sinks com Pipelines Declarativos
- Repositório de conectores de exemplo
- Conector HuggingFace
- Uso eficiente dos recursos mais recentes do Declarative Pipelines para casos de uso de cibersegurança
- Receitas do Delta Live Tables: consumindo do Azure Event Hubs usando as credenciais de serviço do Unity Catalog
- Nova API de fonte de dados para PySpark
- Fonte de dados Apache Spark™ para datasets de IA do HugginFace
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.