Anunciando a Sincronização Nativa do Lakehouse a partir do Lakebase
Abrindo dados do Lakebase para modelos, análises e outros motores
- A Sincronização Nativa do Lakehouse (Prévia Pública) replica dados do Lakebase Postgres em tabelas gerenciadas do Unity Catalog automaticamente, sem pipelines ou computação externa.
- Pilhas tradicionais de CDC quebram sob cargas de trabalho orientadas por agentes. Como o Lakebase e o Lakehouse compartilham o mesmo armazenamento aberto, a sincronização se torna uma propriedade nativa do banco de dados com impacto zero no desempenho do Postgres, sem custo adicional e propagação automática de esquema.
- Recursos de ML ao vivo baseados no estado atual do aplicativo, dados operacionais como a camada Bronze de uma arquitetura medallion com histórico SCD Tipo 2 completo e captura de auditoria integrada para cada alteração.
Hoje, temos o prazer de anunciar a Prévia Pública da Sincronização Nativa do Lakehouse, uma capacidade central do Lakebase Postgres que replica dados do Lakebase em tabelas gerenciadas do Unity Catalog, sem pipelines ou computação externa. A Sincronização Nativa do Lakehouse está disponível em todas as regiões do Lakebase na AWS e Azure.
Por que criamos
Aplicações costumavam rodar em um único banco de dados operacional. À medida que os casos de uso se expandiram, um banco de dados deixou de ser suficiente. Análises, ML e busca vivem fora do banco de dados operacional, o que significa que os dados precisam se mover.
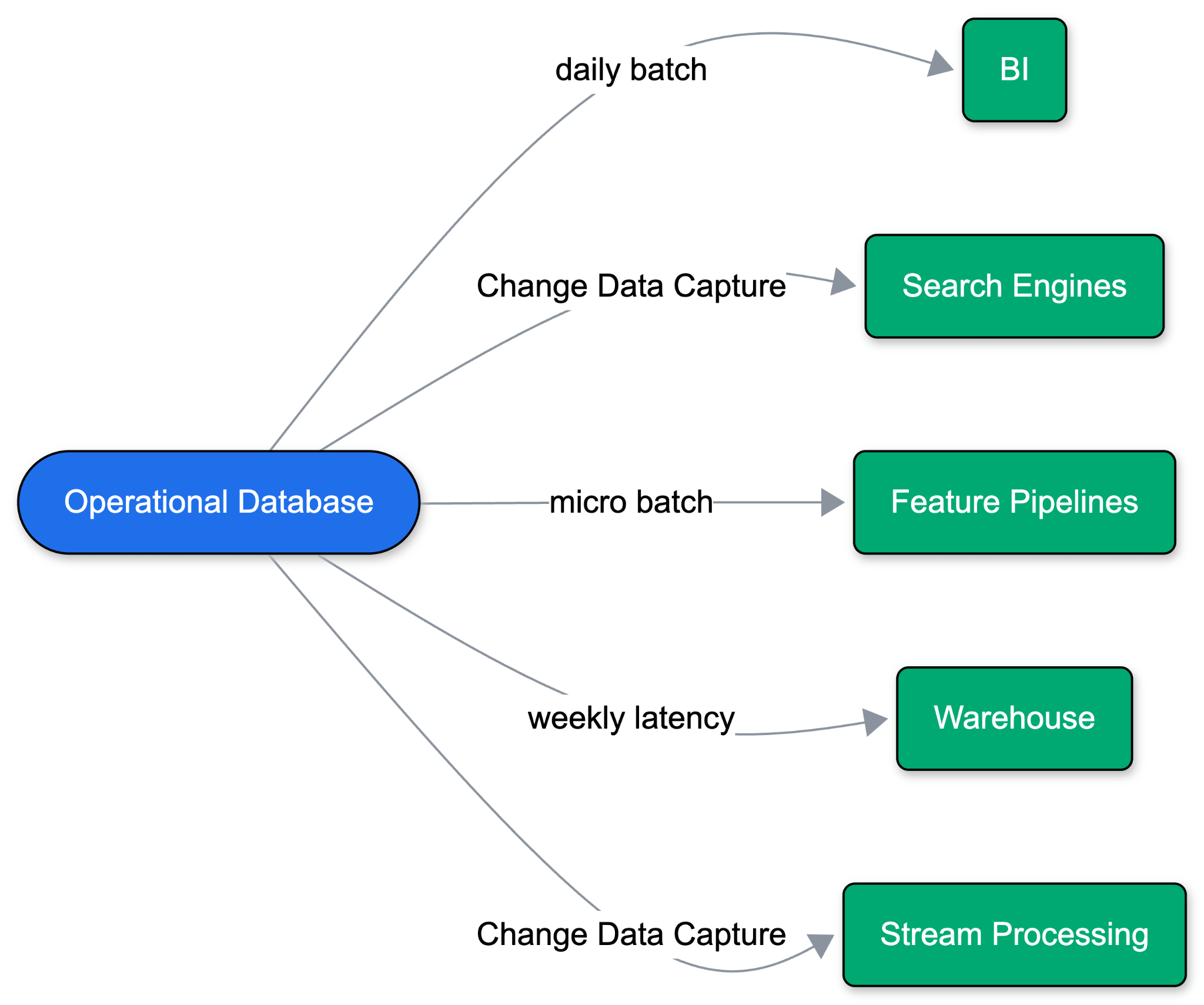
Historicamente, isso significava dumps diários em lote para um data warehouse, que eventualmente evoluíram para Captura de Dados de Alteração (CDC). Hyperscalers empacotaram isso como sincronizações 'gerenciadas' ("zero-ETL"), implantando pipelines de dados ao lado do banco de dados. Mas essas sincronizações gerenciadas dependem de suposições legadas: cargas de trabalho sempre ativas, esquemas estáveis, volumes de consulta previsíveis e um único data warehouse de destino. O problema se agrava a cada novo destino de dados: o desempenho operacional degrada, os esquemas se desviam e os pontos de falha se multiplicam em toda a pilha.
O desenvolvimento baseado em agentes quebra completamente esse modelo. Agentes ramificam dados rapidamente para iterar com segurança, escalar para zero entre tarefas e iniciar ambientes de curta duração. Gerenciar um pipeline personalizado para cada ramificação e cada destino simplesmente não escala.
Conectar-se a um data warehouse é a abordagem errada. Consumidores downstream raramente são apenas dashboards; eles estão incorporando modelos, LLMs, serviços de previsão e pipelines de recursos. Formatos de tabela abertos como Delta Lake e Apache Iceberg™ fornecem o primitivo ideal: armazenar dados uma vez em armazenamento de objetos barato para alimentar todas as cargas de trabalho sem duplicação. É um fato conhecido: você precisa de um Lakehouse e deseja dados operacionais recentes dentro dele.
Mas escrever dados operacionais em um Lakehouse criou novos desafios. As equipes foram forçadas a configurar slots de replicação do Postgres, conectores Debezium, motores de processamento de streaming para escrever em formatos abertos e computação separada apenas para otimizar as tabelas. Cada salto adiciona um ponto de falha.
Sincronização como uma propriedade do Lakebase
Lakebase é construído sobre uma suposição fundamentalmente diferente: um banco de dados operacional deve rodar no mesmo armazenamento em nuvem aberto e de baixo custo que seu Lakehouse. Como OLTP e OLAP compartilham essa base de armazenamento unificada, podemos eliminar completamente o pipeline ETL. O movimento de dados se torna uma propriedade nativa do próprio banco de dados.
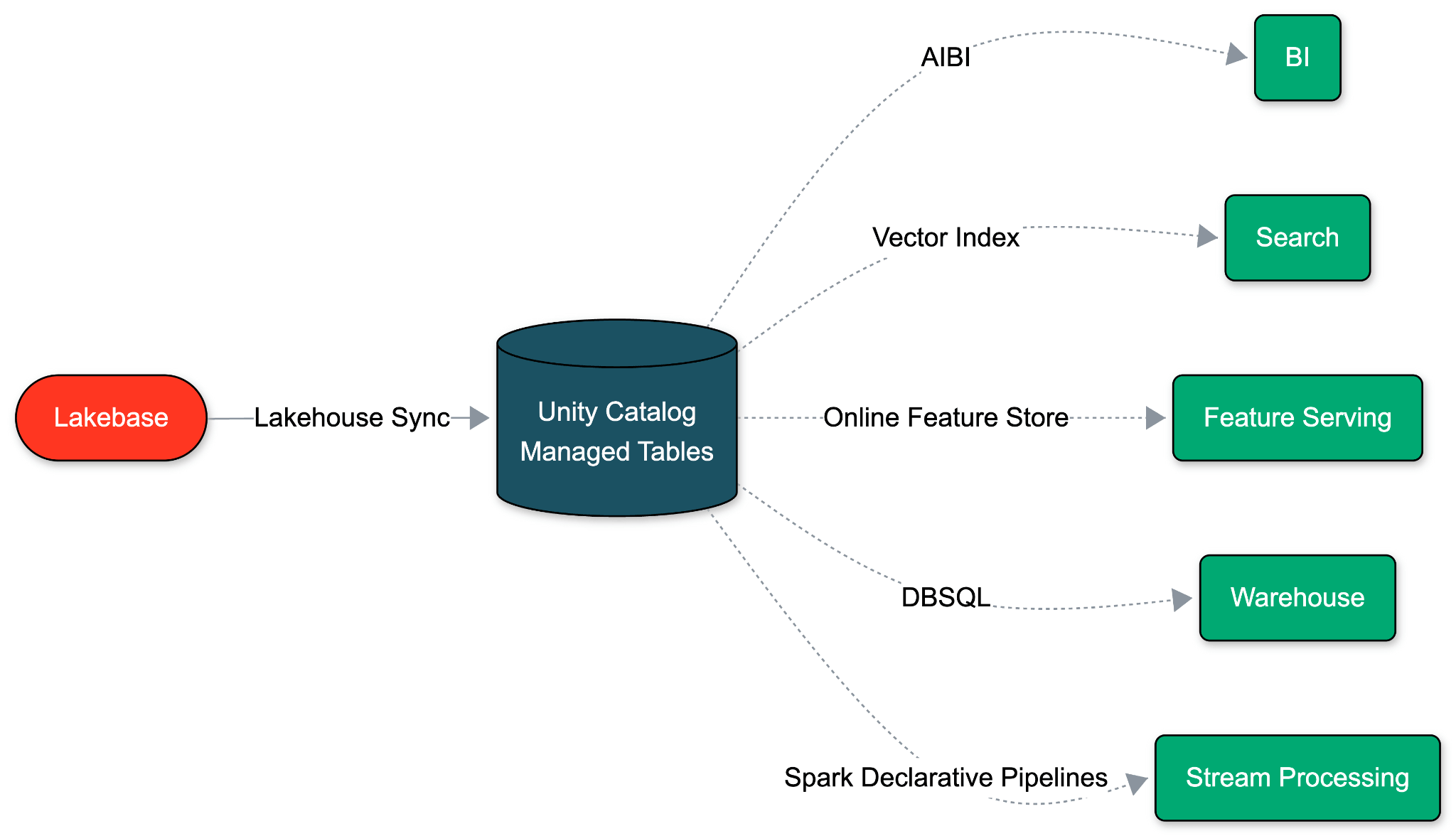
Com a Sincronização Nativa do Lakehouse, o Lakebase decodifica seu Write-Ahead-Log (WAL) e escreve diretamente nas Tabelas Gerenciadas do Unity Catalog. Uma única configuração de nível de esquema a habilita em menos de um minuto. Esta sincronização tem impacto zero no desempenho do Postgres e nenhum custo adicional. E como a Databricks controla ambas as pontas, as alterações de esquema fluem automaticamente, eliminando desvios e atrasos.
Agente-primeiro de ponta a ponta
Agentes constroem aplicativos no Lakebase. Agentes como o Databricks Genie analisam os dados. Para manter todo esse ciclo de vida autônomo, a Sincronização Nativa do Lakehouse é construída como uma propriedade central do Lakebase. Ela herda os comportamentos exatos que os agentes precisam para operar sem problemas:
- Escala para zero: A sincronização pausa quando o banco de dados escala para zero e retoma a partir do último LSN ao acordar.
- Gerenciamento de computação zero: A sincronização é uma parte nativa do Lakebase. Todo o monitoramento e observabilidade permanecem dentro do seu Projeto Lakebase.
- Propagação automática de esquema: Alterações de esquema fluem automaticamente. Adicionar uma coluna se propaga instantaneamente. Remover uma coluna a mantém no destino. Agentes nunca precisam recriar a sincronização.
Primitivos do Lakehouse no lado do destino
Como o destino é uma tabela gerenciada do Unity Catalog, todas as capacidades do Lakehouse estão disponíveis nos dados sincronizados a partir do momento em que chegam.
- Análises nativas de IA: Imediatamente disponíveis para consulta, análise e geração de pipelines por agentes como Databricks Genie e Genie Code.
- Legibilidade universal: Legível por Databricks SQL, Apache Spark, Pipelines Declarativos Spark Lakeflow, notebooks de ML e qualquer ferramenta que fale Delta ou Iceberg.
- Governança unificada: Linhagem, políticas de acesso, tags e auditorias são herdadas do Unity Catalog.
- Otimização automática: Otimização Preditiva e Clusterização Líquida se aplicam com configuração zero.
- Versionamento padrão: Cada inserção, atualização e exclusão é registrada como histórico SCD Tipo 2. Logs de auditoria, retrocessos e semântica CDF estão integrados.
O que você pode construir com a Sincronização Nativa do Lakehouse
Juntos, esses comportamentos de origem e destino desbloqueiam três padrões que anteriormente exigiam uma pilha personalizada de Captura de Dados de Alteração (CDC):
Memória de agente e recursos de ML ao vivo. Gravações de aplicativos chegam ao Unity Catalog em um minuto, para que os modelos retreinem e pontuem com base no estado atual do aplicativo sem um pipeline de ingestão separado.
Dados operacionais na arquitetura medallion. Use o Lakebase como as Tabelas Bronze na arquitetura medallion. Atualizações de alta velocidade ocorrem no Postgres, e todo o histórico de alterações flui para o Lakehouse automaticamente como SCD Tipo 2.
Conformidade e auditoria. Cada inserção, atualização e exclusão é capturada como uma linha de histórico no Unity Catalog. Sem rastreamento de histórico no lado do aplicativo, sem pipeline de auditoria separado.
Comece
Sincronização Nativa do Lakehouse está em Prévia Pública. Iniciar um Lakebase é instantâneo. Ative a sincronização em um esquema uma vez, e todas as tabelas existentes e futuras aparecerão no Unity Catalog em um minuto
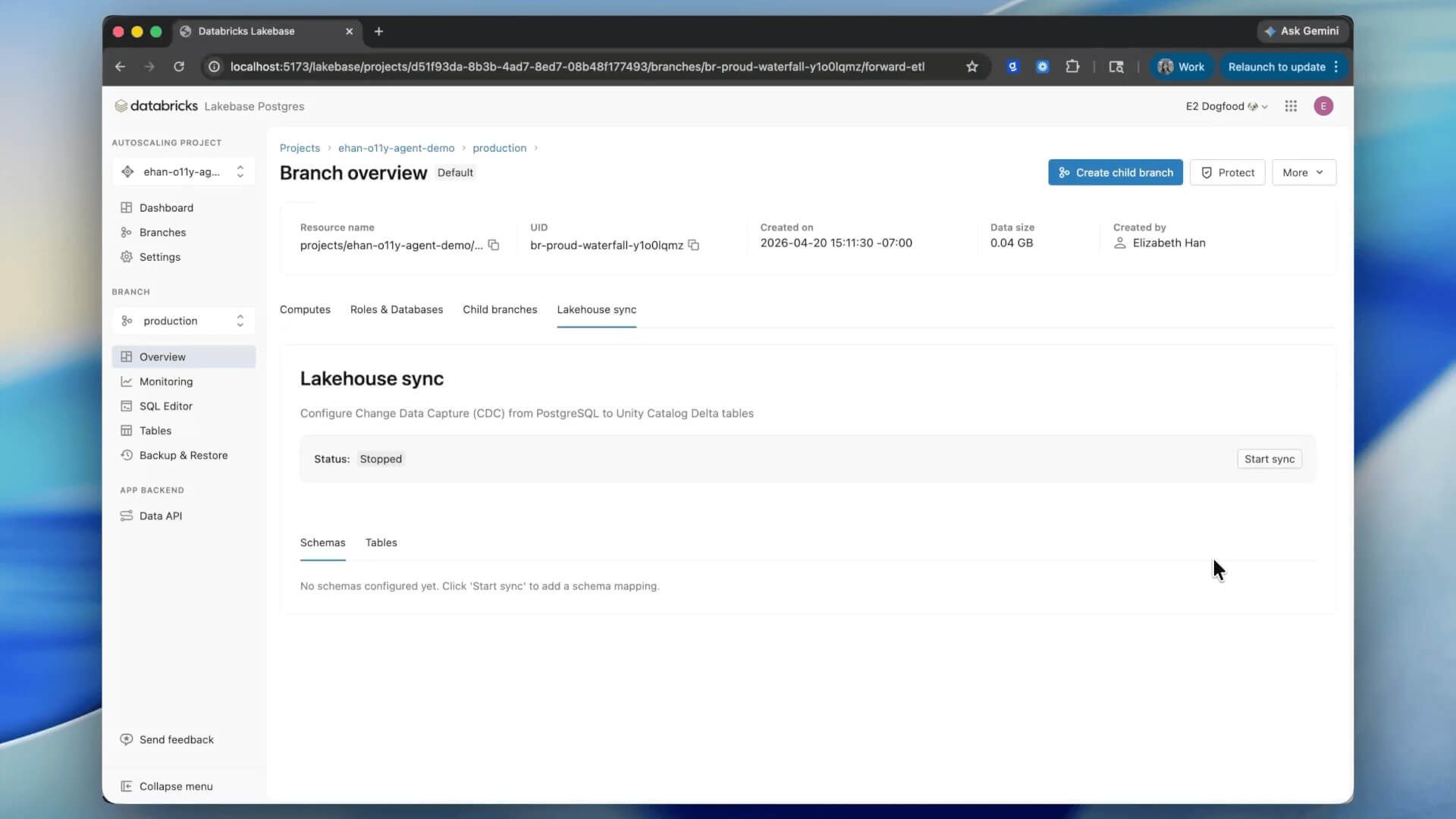
O Lakebase é construído sobre a mesma base de dados aberta do Lakehouse. A Sincronização Nativa do Lakehouse torna essa visão uma realidade, permitindo que os dados do Lakebase fluam para formatos abertos automaticamente, sem um pipeline separado.
O próximo passo: trazer essa mesma abertura do Lakehouse para as tabelas do Lakebase. Fique atento.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.