Announcing Native Lakehouse Sync
Opening Lakebase data to models, analytics, and other engines
- Native Lakehouse Sync (Public Preview) replicates Lakebase Postgres data into Unity Catalog managed tables automatically, with no pipelines or external compute.
- Traditional CDC stacks break under agent-driven workloads. Because Lakebase and the Lakehouse share the same open storage, sync becomes a native database property with zero Postgres performance impact, no added cost, and automatic schema propagation.
- Live ML features grounded in current app state, operational data as the Bronze layer of a medallion architecture with full SCD Type 2 history, and built-in audit capture for every change.
Today we are excited to announce the Public Preview of Native Lakehouse Sync, a core capability of Databricks Lakebase that replicates Lakebase data to Unity Catalog managed tables, without any pipelines or external compute. Native Lakehouse Sync is available in all Lakebase regions on AWS and Azure.
Why we built it
Applications used to run on a single operational database. As use cases expanded, one database stopped being enough. Analytics, ML, and search all live outside the operational database, meaning data has to move.
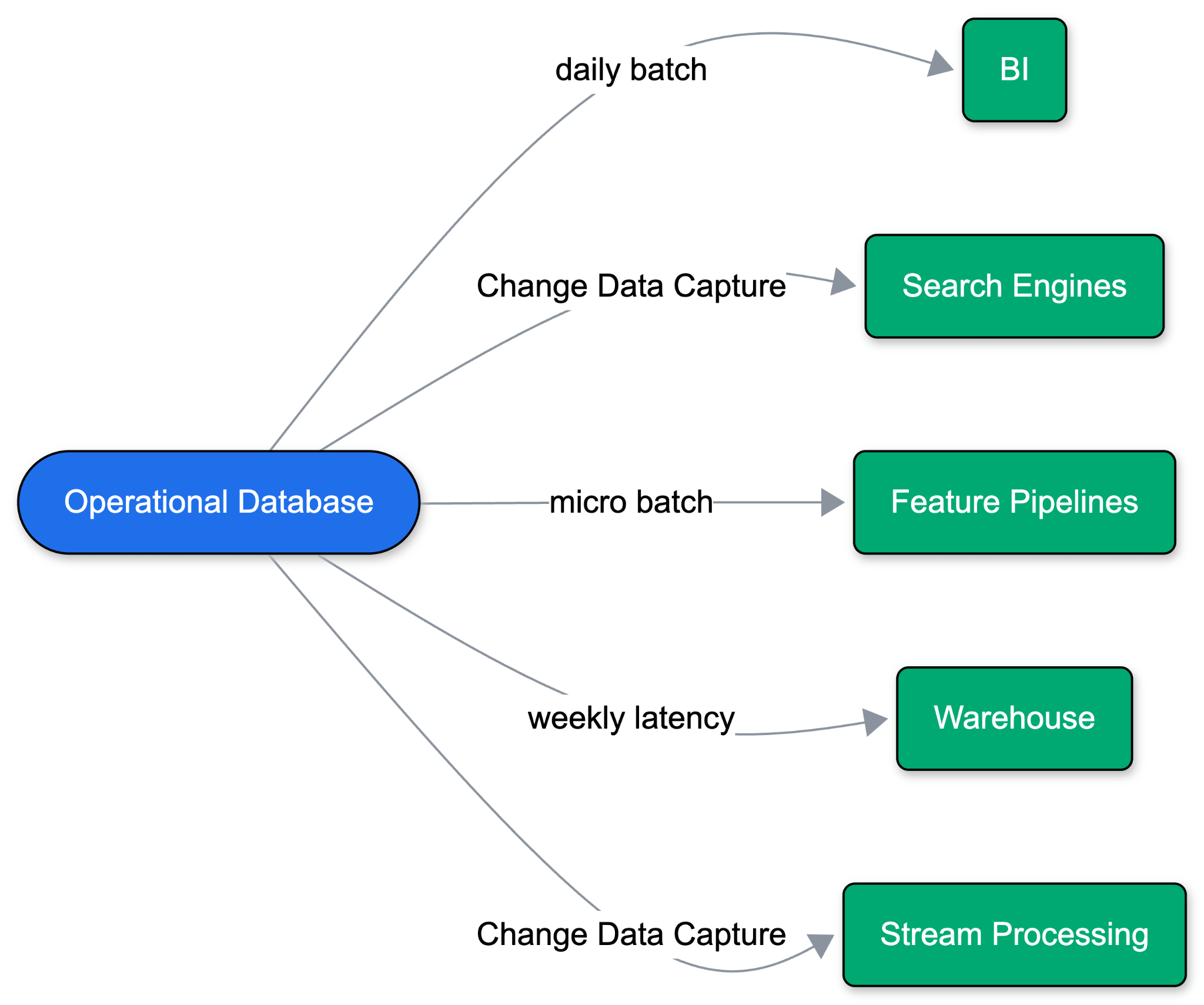
Historically, this meant daily batch dumps to a warehouse, which eventually evolved into Change Data Capture (CDC). Hyperscalers packaged this as ‘managed' syncs ("zero-ETL"), deploying data pipelines alongside the database. But these managed syncs rely on legacy assumptions: always-on workloads, stable schemas, predictable query volumes, and a single destination warehouse. The problem compounds with every new destination of data: operational performance degrades, schema drifts, and points of failure multiply across the stack.
Agent-first development breaks this model entirely. Agents branch data rapidly to iterate safely, scale to zero between tasks, and spin up short-lived environments. Managing a custom pipeline for every branch and every destination simply doesn’t scale.
Plumbing into a warehouse is the wrong approach. Downstream consumers are rarely just dashboards anymore; they are embedding models, LLMs, prediction services, and feature pipelines. Open table formats like Delta Lake and Apache Iceberg™ provide the ideal primitive: storing data once in cheap object storage to power every workload without duplication. It's a known known: you need a Lakehouse, and you want fresh operational data inside it.
But writing operational data into a Lakehouse created new challenges. Teams were forced to configure Postgres replication slots, Debezium connectors, stream processing engines to write into open formats, and separate compute just to optimize the tables. Every hop adds a point of failure.
Sync as a property of Lakebase
Lakebase is built on a fundamentally different assumption: an operational database should run on the exact same open, low-cost cloud storage as your Lakehouse. Because OLTP and OLAP share this unified storage foundation, we can eliminate the ETL pipeline entirely. Data movement becomes a native property of the database itself.
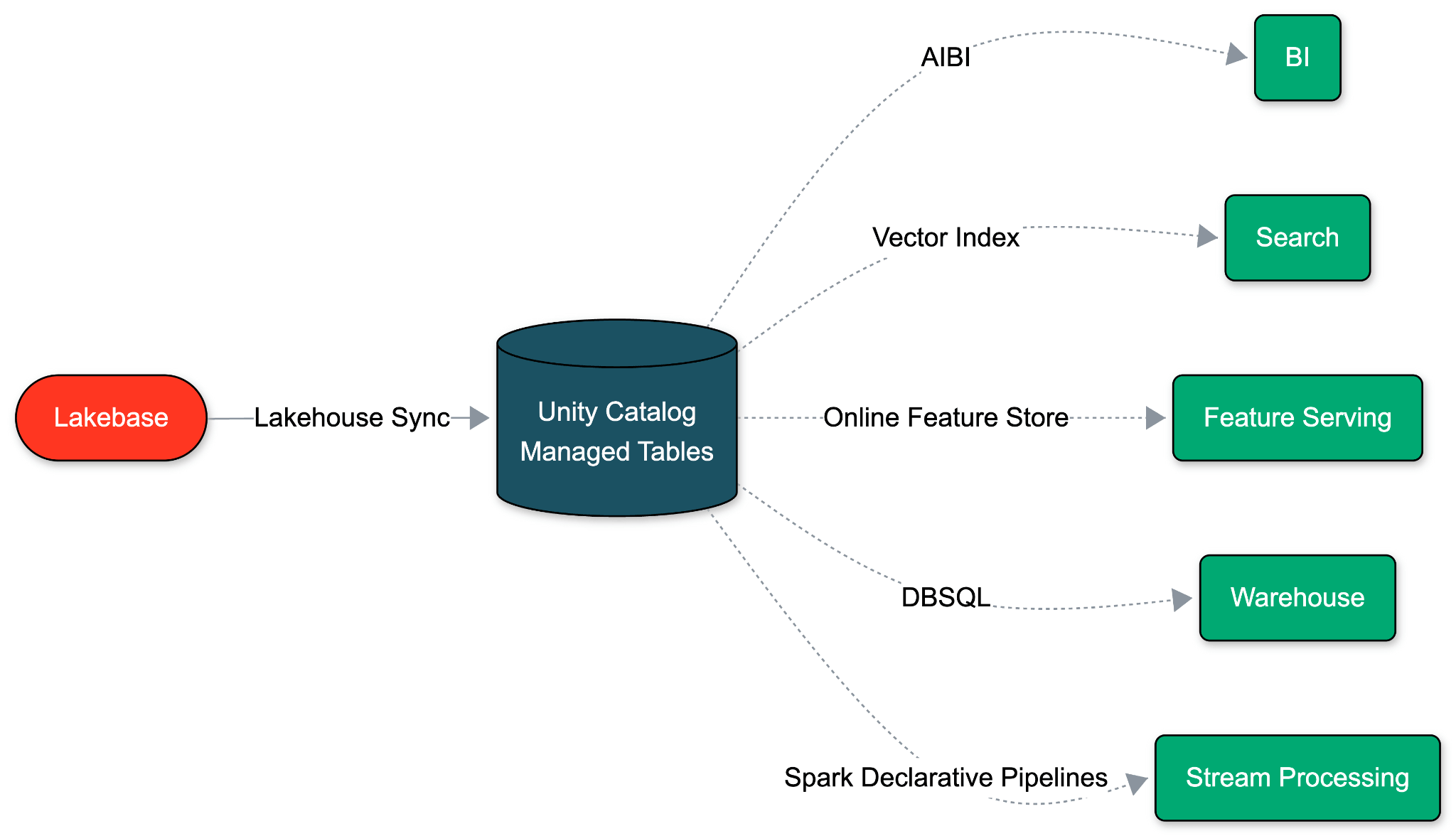
With Native Lakehouse Sync, Lakebase decodes its Write-Ahead-Log (WAL) and writes directly to Unity Catalog Managed Tables. A single schema-level toggle enables it in under a minute. This sync has zero impact on Postgres performance, and no additional cost. And since Databricks controls both ends, schema changes flow automatically, eliminating the drift and lag.
Agent-first from end to end
Agents build apps on Lakebase. Agents like Databricks Genie analyze the data. To keep this entire lifecycle autonomous, Native Lakehouse Sync is built as a core property of Lakebase. It inherits the exact behaviors agents need to operate seamlessly:
- Scale-to-zero: Sync pauses when the database scales to zero and resumes from the last LSN upon waking.
- Zero compute management: Sync is a native part of Lakebase. All monitoring and observability stay within your Lakebase Project.
- Automatic schema propagation: Schema changes flow automatically. Adding a column propagates instantly. Dropping a column retains it on the destination. Agents never have to recreate the sync.
Lakehouse primitives on the destination side
Because the destination is a Unity Catalog managed table, every Lakehouse capability is available on synced data from the moment it lands.
- AI-native analytics: Immediately available for querying, analysis, and pipeline generation by agents like Databricks Genie and Genie Code.
- Universal readability: Readable by Databricks SQL, Apache Spark, Lakeflow Spark Declarative Pipelines, ML notebooks, and any tool speaking Delta or Iceberg.
- Unified governance: Lineage, access policies, tags, and audits are inherited from Unity Catalog.
- Automatic optimization: Predictive Optimization and Liquid Clustering apply with zero setup.
- Default versioning: Every insert, update, and delete lands as SCD Type 2 history. Audit logs, rewinds, and CDF semantics are built in.
What you can build with Native Lakehouse Sync
Together, these source and destination behaviors unlock three patterns that previously required a custom Change Data Capture (CDC) stack:
Agentic memory and live ML features. Application writes land in Unity Catalog within a minute, so models retrain and score against the current state of the application without a separate ingestion pipeline.
Operational data in the medallion architecture. Use Lakebase as the Bronze Tables in the medallion architecture. High-velocity updates happen in Postgres, and the full change history flows into the Lakehouse automatically as SCD Type 2.
Compliance and audit. Every insert, update, and delete is captured as a history row in Unity Catalog. No application-side history tracking, no separate audit pipeline.
Get started
Native Lakehouse Sync is in Public Preview. Spinning up a Lakebase is instant. Toggle sync on a schema once, and every existing and future table will appear in Unity Catalog within a minute
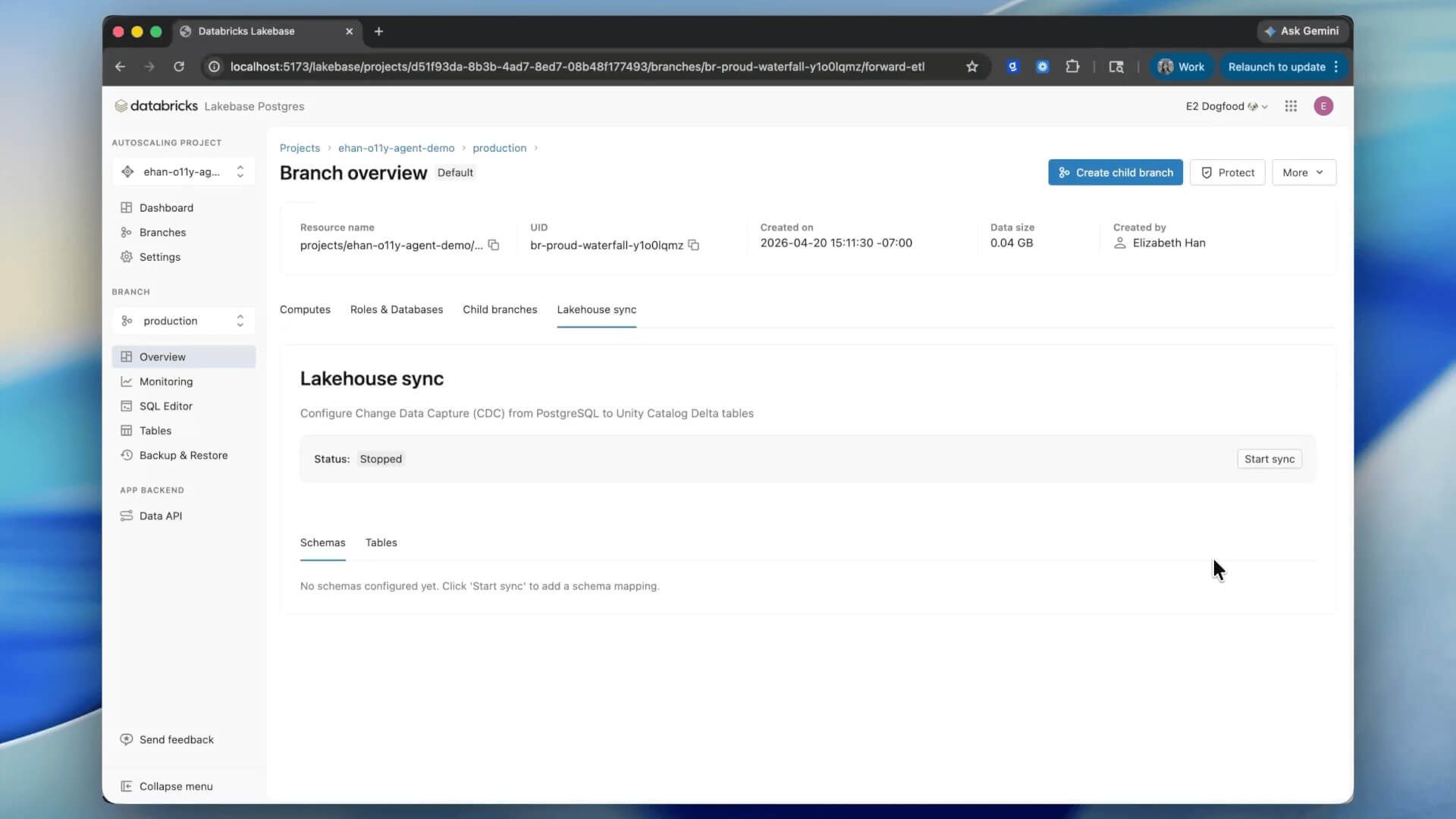
Lakebase is built on the exact same open data foundation as the Lakehouse. Native Lakehouse Sync makes that vision a reality, allowing Lakebase data to flow into open formats automatically without a separate pipeline.
The next step: bringing that same openness from the Lakehouse to Lakebase tables. Stay tuned.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.