A New Era of Databases: Lakebase
by Ali Ghodsi, Stas Kelvich, Heikki Linnakangas, Nikita Shamgunov, Arsalan Tavakoli-Shiraji, Patrick Wendell, Reynold Xin and Matei Zaharia
For decades, databases have been the backbone of software: quietly powering everything from ecommerce checkout flows to enterprise resource planning. Every piece of software in the world, every application, every workflow, every AI-generated line of code ultimately depends on a database underneath. Along the way, we’ve completely reinvented how applications are built, but the underlying databases have changed very little since the 1980s. They largely build on architectures that predate the modern cloud and suffer from the following:
- Fragile & costly operations: Traditional databases are considered one of the most delicate pieces of infrastructure, and operating them reliably typically requires an army of specialists to “walk on eggshells”. They bundle compute and storage into a rigid, monolithic unit. This forces teams to provision for peak capacity, leading to expensive idle resources. When load spikes above the provisioned capacity, databases can become unresponsive. Worse, simple maintenance tasks like snapshotting a database or running a GDPR cleanup query can potentially bring the entire database down.
- Clunky development experience: Traditional databases clash with the modern, agile development workflows. For code, it takes less than a second to create a git branch for development that’s a fully isolated clone of the codebase. For databases, it takes many minutes if not hours to provision one, and taking a high fidelity clone of the production database is very costly and risks bringing the production database down. The rise of AI-driven development has only intensified this pressure. AI agents need to spin up temporary, isolated environments instantly for experimentation.
- Extreme Vendor Lock-in: Database migrations are one of the scariest technical projects in any organization. The monolithic architecture means that the only way to get data in or out is through the database engine itself. This imposes significant vendor lock-in, making organizations deeply dependent on the specific vendor.
It’s time for databases to evolve.
What is a Lakebase?
New systems are beginning to emerge that address the limitations of traditional databases. A Lakebase is a new, open architecture that combines the best elements of transactional databases with the flexibility and economics of the data lake. Lakebases are enabled by a fundamentally new design: separating compute from storage and placing the database’s data directly in low-cost cloud storage (“lake”) in open formats, while allowing the transactional compute layer to run independently on top.
This separation is the core breakthrough. Traditional databases bundle CPU and storage together into one monolithic system that must be provisioned, managed, and paid for as a single large machine. Lakebase splits these layers apart. Data lives openly in the lake, while the database engine becomes a fully managed, serverless compute layer (e.g. Postgres) that can scale instantly. This architecture eliminates much of the cost, complexity, and lock-in that have defined databases for decades, and it is especially powerful for modern AI and agent-driven workloads, where developers want to launch many instances, experiment freely, and pay only for what they use.
A Lakebase has the following key features:
Storage is separated from compute: Data is stored cheaply in cloud object stores (“lake”), while compute runs independently and elastically. This enables massive scale, high concurrency, and the ability to scale all the way down to zero in under a second (something not possible in legacy database systems), eliminating the need to keep expensive database machines running idle.
Unlimited, low-cost, durable storage: With data living in the lake, storage becomes essentially infinite and dramatically cheaper than traditional database systems that require fixed-capacity infrastructure. And its storage is backed by the durability of cloud object storage (e.g., S3), offering 99.999999999% durability by default. This is far superior to the traditional database setup of having replicas for storage redundancy (most frequently asynchronously updated, meaning that there is a chance of data loss in many configurations in case of double-faults).
Elastic, serverless Postgres compute: Lakebase provides fully managed, serverless Postgres that scales up instantly with demand and scales down when idle. Costs align directly with usage, making it ideal for bursty workloads, development environments, and AI agents spinning up temporary instances.
Instant branching, cloning, and recovery: Databases can be branched and cloned the way developers branch code. Even petabyte-scale databases can be copied in seconds, enabling fast experimentation, safe rollbacks, and instant restoration without operational overhead.
Unified transactional and analytical workloads: Lakebase integrates seamlessly with the Lakehouse, sharing the same storage layer across OLTP and OLAP. This makes it possible to run real-time analytics, machine learning, and AI-driven optimization directly on transactional data without moving or duplicating it.
Open and multicloud by design: Data stored in open formats avoids proprietary lock-in and enables true portability across AWS, Azure, and beyond. Built-in multicloud flexibility supports disaster recovery, long-term freedom, and stronger economics over time.
These are the key attributes of Lakebase. Enterprise-grade transactional systems require additional capabilities such as security, governance, auditing, and high availability — but with a Lakebase, these features only need to be implemented and managed once, on a single open foundation. Lakebase represents the next evolution of databases: transactional systems rebuilt for the cloud, for developers, and for the AI era.
Database Architecture Evolution
To understand why a new era is needed, it is helpful to look at how database architecture has evolved over the last fifty years. We view this evolution in three distinct generations:
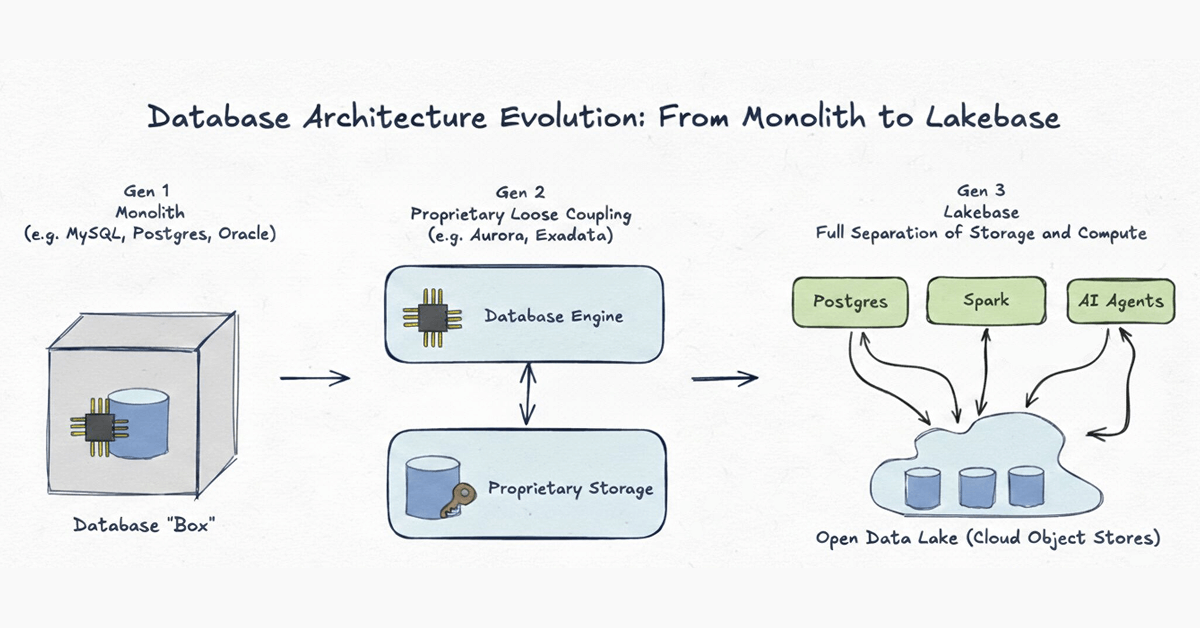
Generation 1: Monolith
Examples: MySQL, Postgres, classic Oracle
Database systems started as absolute monoliths. In the pre-cloud era, the network was the slowest part of any system. The only way to design a high-performance database was to tightly bind the compute (CPU/RAM) and the storage (disk) together inside a single physical machine. While this made sense for the hardware limitations of the 1980s, it created a rigid cage where data was trapped in proprietary formats and scaling meant buying a bigger box.
Generation 2: Proprietary Loose Coupling of Storage
Examples: Aurora, Oracle Exadata
As cloud infrastructure improved, vendors physically separated storage from compute, moving storage into proprietary backend tiers. These systems were engineering marvels that pushed the boundaries of throughput. However, they didn't go far enough. The separation was purely an internal optimization. Because the data remains locked inside a proprietary format accessible only by a single engine, Gen 2 systems suffer from structural dead ends:
- Single engine chokehold: Data is accessible only through the primary database engine, which becomes the bottleneck. It’s difficult for AI agents or analytical engines accessing the data at scale.
- Analytical friction: Because you cannot have separate OLAP engines access the database files directly at scale, running analytical queries remains difficult and typically requires complex ETL to move data out.
- Cloud lock-in: The storage layer is often tightly coupled to the specific cloud provider’s proprietary infrastructure. This makes multi-cloud interoperability difficult and renders true cross-cloud High Availability and Disaster Recovery (HADR) impossible. If the vendor’s region fails, your data is stuck.
We think these systems are in a transitional state towards the ultimate 3rd generation.
Generation 3: Lakebase - Open Storage on the Lake
A Lakebase takes decoupled architecture to its ultimate, logical conclusion. Like Gen 2, it separates compute from storage, but with a critical difference: both the storage infrastructure and the data formats are completely open.
Building on top of this architecture, it can solve the aforementioned 3 challenges:
- Better reliability and lower cost through simpler operations: Common operations such as provisioning, scaling up, down, branching, snapshotting, recovery can be completed in seconds. Expensive queries can be run on different elastic compute instances without impacting production traffic.
- Git-like Developer Experience: It becomes faster to experiment and develop applications, based on high fidelity branch of the production databases. For developers and AI agents, this means the database moves as fast as their code.
- Solves Extreme Vendor Lock-in: With data in open formats stored in cloud object stores, you are much less locked-in. You own your data, independent of the engine.
In many ways, a Lakebase is what you would build if you had to redesign OLTP databases today, now that cheap, reliable object storage and cloud elasticity are available. As organizations move faster by adopting cloud and AI, we expect this model to become a standard foundation for building transactional systems.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.