Uma Nova Era de Bancos de Dados: Lakebase
por Ali Ghodsi, Stas Kelvich, Heikki Linnakangas, Nikita Shamgunov, Arsalan Tavakoli-Shiraji, Patrick Wendell, Reynold Xin e Matei Zaharia
- Bancos de dados operacionais não foram projetados para as aplicações orientadas a IA de hoje. Eles ficam fora da pilha de análise e IA, requerem integração manual e não têm a flexibilidade necessária para os fluxos de trabalho de desenvolvimento moderno.
- Lakebase introduz uma nova arquitetura para bancos de dados OLTP, que inclui a separação de computação e armazenamento para escalonamento independente e ramificação.
- Profundamente integrado com o lakehouse, o Lakebase simplifica os fluxos de trabalho de dados operacionais. Ele elimina pipelines ETL frágeis e infraestrutura complexa, permitindo que as equipes se movam mais rápido e entreguem aplicações inteligentes em uma plataforma de dados unificada
Por décadas, os bancos de dados têm sido a espinha dorsal do software: impulsionando silenciosamente tudo, desde fluxos de checkout de e-commerce até planejamento de recursos empresariais. Cada pedaço de software no mundo, cada aplicativo, cada fluxo de trabalho, cada linha de código gerada por IA, em última análise, depende de um banco de dados subjacente. Ao longo do caminho, reinventamos completamente como os aplicativos são construídos, mas os bancos de dados subjacentes mudaram muito pouco desde os anos 1980. Eles se baseiam em arquiteturas que precedem a nuvem moderna e sofrem com o seguinte:
- Operações frágeis e caras: Bancos de dados tradicionais são considerados uma das peças de infraestrutura mais delicadas, e operá-los de forma confiável geralmente requer um exército de especialistas para “andar em ovos”. Eles agrupam computação e armazenamento em uma unidade monolítica e rígida. Isso força as equipes a provisionar para capacidade máxima, levando a recursos ociosos caros. Quando a carga excede a capacidade provisionada, os bancos de dados podem ficar sem resposta. Pior ainda, tarefas de manutenção simples como tirar um snapshot de um banco de dados ou executar uma consulta de limpeza GDPR podem potencialmente derrubar todo o banco de dados.
- Experiência de desenvolvimento desajeitada: Bancos de dados tradicionais entram em conflito com os fluxos de trabalho de desenvolvimento modernos e ágeis. Para código, leva menos de um segundo para criar um branch git para desenvolvimento que é um clone totalmente isolado da base de código. Para bancos de dados, leva muitos minutos, senão horas, para provisionar um, e tirar um clone de alta fidelidade do banco de dados de produção é muito caro e arrisca derrubar o banco de dados de produção. O surgimento do desenvolvimento impulsionado por IA intensificou ainda mais essa pressão. Agentes de IA precisam iniciar ambientes temporários e isolados instantaneamente para experimentação.
- Bloqueio de fornecedor extremo: Migrações de banco de dados são um dos projetos técnicos mais assustadores em qualquer organização. A arquitetura monolítica significa que a única maneira de obter dados dentro ou fora é através do próprio mecanismo do banco de dados. Isso impõe um bloqueio de fornecedor significativo, tornando as organizações profundamente dependentes do fornecedor específico.
É hora dos bancos de dados evoluírem.
O que é um Lakebase?
Novos sistemas estão começando a surgir que abordam as limitações dos bancos de dados tradicionais. Um Lakebase é uma nova arquitetura aberta que combina os melhores elementos de bancos de dados transacionais com a flexibilidade e a economia do data lake. Os Lakebases são habilitados por um design fundamentalmente novo: separando computação de armazenamento e colocando os dados do banco de dados diretamente em armazenamento de baixo custo na nuvem (“lake”) em formatos abertos, enquanto permite que a camada de computação transacional seja executada independentemente por cima.
Essa separação é o avanço principal. Bancos de dados tradicionais agrupam CPU e armazenamento em um sistema monolítico que deve ser provisionado, gerenciado e pago como uma única máquina grande. Lakebase divide essas camadas. Os dados vivem abertamente no lake, enquanto o mecanismo do banco de dados se torna uma camada de computação totalmente gerenciada e sem servidor (por exemplo, Postgres) que pode escalar instantaneamente. Essa arquitetura elimina grande parte do custo, complexidade e bloqueio que definiram os bancos de dados por décadas, e é especialmente poderosa para cargas de trabalho modernas de IA e baseadas em agentes, onde os desenvolvedores querem lançar muitas instâncias, experimentar livremente e pagar apenas pelo que usam.
Um Lakebase tem os seguintes recursos principais:
Armazenamento separado da computação: Os dados são armazenados de forma barata em armazenamentos de objetos na nuvem (“lake”), enquanto a computação é executada de forma independente e elástica. Isso permite escala massiva, alta concorrência e a capacidade de escalar até zero em menos de um segundo (algo não possível em sistemas de banco de dados legados), eliminando a necessidade de manter máquinas de banco de dados caras ociosas.
Armazenamento ilimitado, de baixo custo e durável: Com os dados residindo no lake, o armazenamento se torna essencialmente infinito e dramaticamente mais barato do que os sistemas de banco de dados tradicionais que exigem infraestrutura de capacidade fixa. E seu armazenamento é suportado pela durabilidade do armazenamento de objetos na nuvem (por exemplo, S3), oferecendo 99,999999999% de durabilidade por padrão. Isso é muito superior à configuração tradicional de banco de dados de ter réplicas para redundância de armazenamento (na maioria das vezes atualizadas assincronamente, o que significa que há chance de perda de dados em muitas configurações em caso de falhas duplas).
Computação Postgres elástica e sem servidor: Lakebase fornece Postgres totalmente gerenciado e sem servidor que escala instantaneamente com a demanda e reduz quando ocioso. Os custos se alinham diretamente com o uso, tornando-o ideal para cargas de trabalho intermitentes, ambientes de desenvolvimento e agentes de IA que iniciam instâncias temporárias.
Ramificação, clonagem e recuperação instantâneas: Bancos de dados podem ser ramificados e clonados da maneira que os desenvolvedores ramificam código. Mesmo bancos de dados em escala de petabytes podem ser copiados em segundos, permitindo experimentação rápida, rollbacks seguros e restauração instantânea sem sobrecarga operacional.
Cargas de trabalho transacionais e analíticas unificadas: Lakebase se integra perfeitamente com o Lakehouse, compartilhando a mesma camada de armazenamento para OLTP e OLAP. Isso permite executar análises em tempo real, machine learning e otimização impulsionada por IA diretamente em dados transacionais sem movê-los ou duplicá-los.
Aberto e multicloud por design: Dados armazenados em formatos abertos evitam o bloqueio proprietário e permitem portabilidade real entre AWS, Azure e outros. A flexibilidade multicloud integrada suporta recuperação de desastres, liberdade de longo prazo e melhores economias ao longo do tempo.
Esses são os atributos-chave do Lakebase. Sistemas transacionais de nível empresarial exigem recursos adicionais como segurança, governança, auditoria e alta disponibilidade — mas com um Lakebase, esses recursos só precisam ser implementados e gerenciados uma vez, em uma única fundação aberta. Lakebase representa a próxima evolução dos bancos de dados: sistemas transacionais reconstruídos para a nuvem, para desenvolvedores e para a era da IA.
Evolução da Arquitetura de Banco de Dados
Para entender por que uma nova era é necessária, é útil observar como a arquitetura de banco de dados evoluiu nos últimos cinquenta anos. Vemos essa evolução em três gerações distintas:
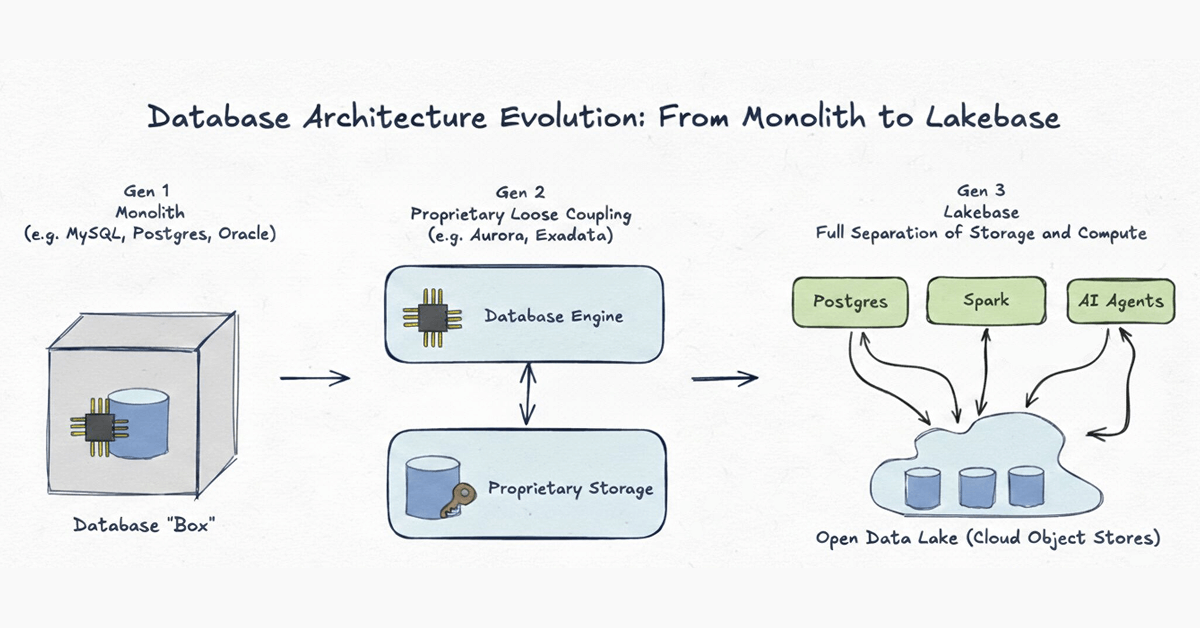
Geração 1: Monolito
Exemplos: MySQL, Postgres, Oracle clássico
Os sistemas de banco de dados começaram como monolitos absolutos. Na era pré-nuvem, a rede era a parte mais lenta de qualquer sistema. A única maneira de projetar um banco de dados de alto desempenho era vincular firmemente a computação (CPU/RAM) e o armazenamento (disco) dentro de uma única máquina física. Embora isso fizesse sentido para as limitações de hardware dos anos 1980, criou uma gaiola rígida onde os dados ficavam presos em formatos proprietários e escalar significava comprar uma caixa maior.
Geração 2: Acoplamento Solto Proprietário de Armazenamento
Exemplos: Aurora, Oracle Exadata
À medida que a infraestrutura de nuvem melhorou, os fornecedores separaram fisicamente o armazenamento da computação, movendo o armazenamento para camadas de backend proprietárias. Esses sistemas foram maravilhas de engenharia que expandiram os limites de throughput. No entanto, eles não foram longe o suficiente. A separação foi puramente uma otimização interna. Como os dados permanecem trancados dentro de um formato proprietário acessível apenas por um único mecanismo, os sistemas Gen 2 sofrem de becos sem saída estruturais:
- Gargalo de mecanismo único: Os dados são acessíveis apenas através do mecanismo de banco de dados principal, que se torna o gargalo. É difícil para agentes de IA ou mecanismos analíticos acessarem os dados em escala.
- Fricção analítica: Como você não pode ter mecanismos OLAP separados acessando os arquivos do banco de dados diretamente em escala, a execução de consultas analíticas continua difícil e geralmente requer ETL complexo para mover os dados.
- Bloqueio na nuvem: A camada de armazenamento geralmente está intimamente acoplada à infraestrutura proprietária do provedor de nuvem específico. Isso torna a interoperabilidade multicloud difícil e impossibilita a Alta Disponibilidade e Recuperação de Desastres (HADR) entre nuvens. Se a região do fornecedor falhar, seus dados ficam presos.
Achamos que esses sistemas estão em um estado de transição para a terceira geração definitiva.
Geração 3: Lakebase - Armazenamento Aberto no Lake
Um Lakebase leva a arquitetura desacoplada à sua conclusão lógica definitiva. Como a Geração 2, ele separa a computação do armazenamento, mas com uma diferença crítica: tanto a infraestrutura de armazenamento quanto os formatos de dados são completamente abertos.
Construindo sobre essa arquitetura, ele pode resolver os 3 desafios mencionados anteriormente:
- Maior confiabilidade e menor custo com operações mais simples: Operações comuns como provisionamento, escalonamento (aumento e diminuição), branching, snapshotting e recuperação podem ser concluídas em segundos. Consultas caras podem ser executadas em diferentes instâncias de computação elástica sem impactar o tráfego de produção.
- Experiência de Desenvolvedor semelhante ao Git: Fica mais rápido experimentar e desenvolver aplicações, com base em um branch de alta fidelidade dos bancos de dados de produção. Para desenvolvedores e agentes de IA, isso significa que o banco de dados se move tão rápido quanto o código deles.
- Resolve o Extremo Vendor Lock-in: Com dados em formatos abertos armazenados em object stores na nuvem, você fica muito menos preso. Você é dono dos seus dados, independentemente do engine.
De muitas maneiras, um Lakebase é o que você construiria se tivesse que redesenhar bancos de dados OLTP hoje, agora que o armazenamento de objetos barato e confiável e a elasticidade da nuvem estão disponíveis. À medida que as organizações se movem mais rápido ao adotar a nuvem e a IA, esperamos que este modelo se torne uma base padrão para a construção de sistemas transacionais.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.