Anunciando Suporte Python para Pacotes de Recursos Databricks para Simplificar Implantações
Defina e implemente o ciclo de vida completo do desenvolvimento de pipeline em Python
por Gleb Kanterov, Lennart Kats, Julia Crawford e Saad Ansari
- Defina Pacotes de Ativos do Databricks em Python para maior flexibilidade, reutilização e fluxos de trabalho amigáveis para desenvolvedores.
- Personalize trabalhos e definições de pipeline com funções Python para adicionar automaticamente configurações como tags, notificações ou clusters padrão.
- Use o novo recurso "Ver como código" para visualizar trabalhos existentes em Python ou YAML, facilitando a inspeção, edição e reutilização de definições de trabalho.
Estamos felizes em anunciar que o suporte ao Python para Pacotes de Ativos do Databricks agora está disponível em Visualização Pública! Usuários do Databricks sempre puderam criar lógica de pipeline em Python. Com este lançamento, o ciclo de vida completo do desenvolvimento de pipeline - incluindo orquestração e agendamento - agora pode ser definido e implementado inteiramente em Python. Os Pacotes de Ativos do Databricks (ou "bundles") fornecem uma abordagem estruturada e orientada a código para definir, versionar e implementar pipelines em diferentes ambientes. O suporte nativo ao Python aumenta a flexibilidade, promove a reutilização e melhora a experiência de desenvolvimento para equipes que preferem Python ou requerem configuração dinâmica em vários ambientes.
Padronize as implementações de jobs e pipelines em larga escala
Equipes de engenharia de dados que gerenciam dezenas ou centenas de pipelines muitas vezes enfrentam desafios para manter práticas de implantação consistentes. A expansão das operações introduz uma necessidade de controle de versão, validação pré-produção e a eliminação de configurações repetitivas em projetos. Tradicionalmente, esse fluxo de trabalho exigia a manutenção de grandes arquivos YAML ou a realização de atualizações manuais através da interface do usuário do Databricks.
Python aprimora esse processo ao permitir a configuração programática de trabalhos e pipelines. Em vez de editar manualmente arquivos YAML estáticos, as equipes podem definir a lógica uma vez em Python, como definir clusters padrão, aplicar tags ou impor convenções de nomenclatura, e aplicá-la dinamicamente em vários deployments. Isso reduz a duplicação, aumenta a manutenibilidade e permite que os desenvolvedores integrem definições de implantação em fluxos de trabalho e pipelines CI/CD baseados em Python de forma mais natural.
"A configuração declarativa e a integração nativa com Databricks tornam os deployments simples e confiáveis. Os mutadores são um destaque, eles nos permitem personalizar trabalhos programaticamente, como auto-tagging ou definição de padrões. Estamos animados para ver os DABs se tornarem o padrão para deployment e mais." —Tom Potash, Gerente de Engenharia de Software na DoubleVerify
Deployments impulsionados por Python para Databricks Asset Bundles
A adição do suporte Python para Databricks Asset Bundles simplifica o processo de deployment. Trabalhos e pipelines agora podem ser totalmente definidos, personalizados e gerenciados em Python. Embora a integração CI/CD com Bundles sempre tenha estado disponível, o uso do Python simplifica a criação de configurações complexas, reduz a duplicação e permite que as equipes padronizem as melhores práticas programaticamente em diferentes ambientes.
Usando o recurso Ver como código nos trabalhos, você também pode copiar e colar diretamente em seu projeto (Saiba mais aqui):
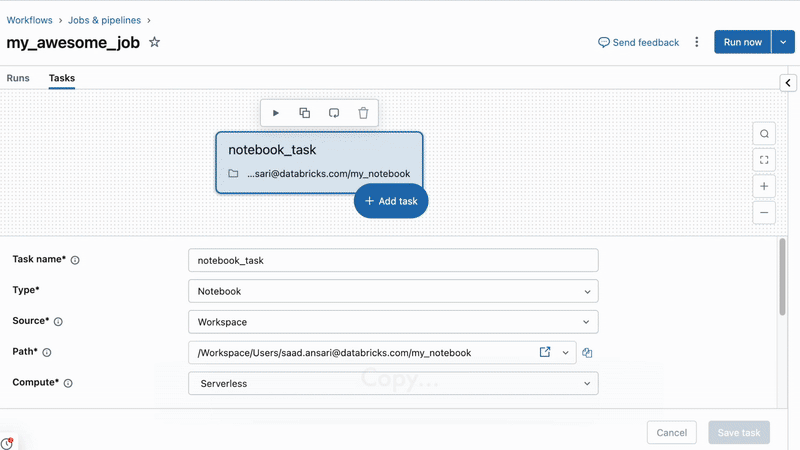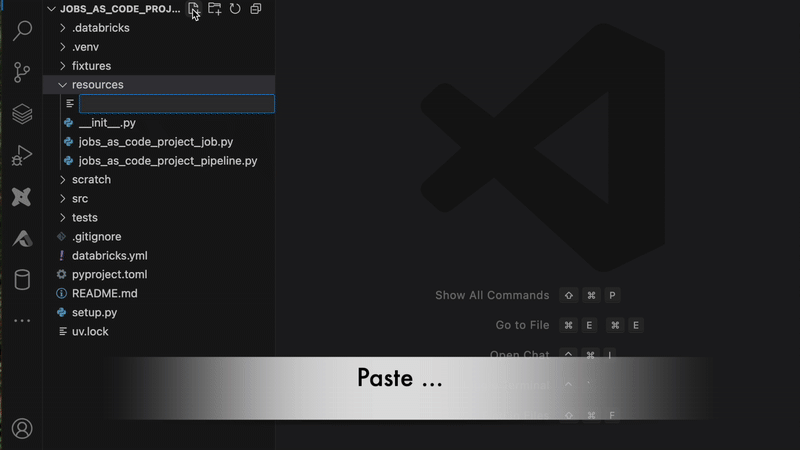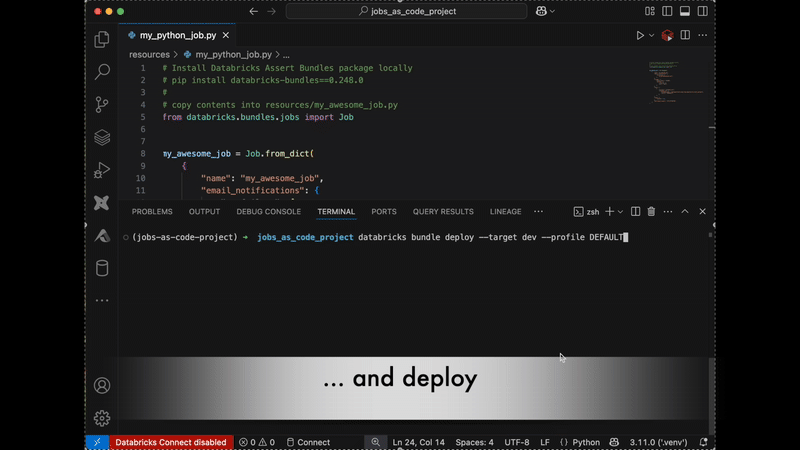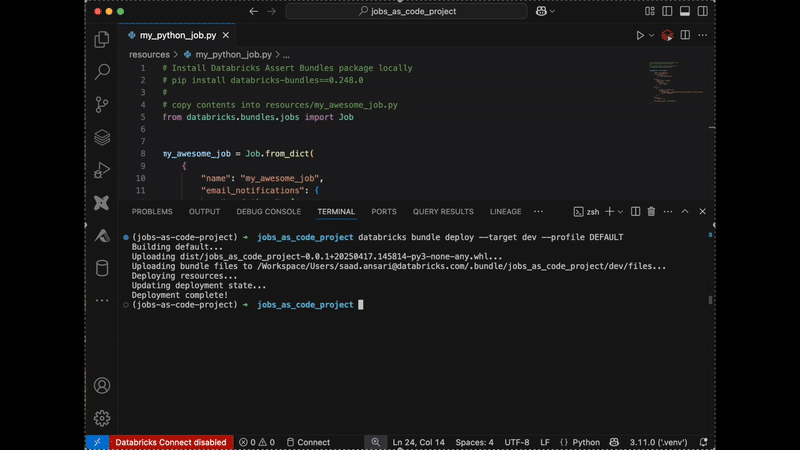
Capacidades avançadas: Geração e personalização de trabalhos programáticos
Como parte deste lançamento, apresentamos a função load_resources, que é usada para criar trabalhos programaticamente usando metadados. O CLI do Databricks chama essa função Python durante o deployment para carregar trabalhos e pipelines adicionais (Saiba mais aqui).
Outra capacidade útil é o padrão mutator, que permite validar configurações de pipeline e atualizar definições de trabalho dinamicamente. Com mutadores, você pode aplicar configurações comuns, como notificações padrão ou configurações de cluster, sem definições repetitivas de YAML ou Python:
Saiba mais sobre mutadores aqui.
Introdução
Mergulhe no suporte Python para Databricks Asset Bundles hoje! Explore a documentação para Pacotes de Ativos do Databricks bem como para Suporte Python para Pacotes de Ativos do Databricks. Estamos animados para ver o que você construirá com esses novos recursos poderosos. Valorizamos seu feedback, então, por favor, compartilhe suas experiências e sugestões conosco!
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.